Session Video
Efficient Long-Text Understanding with Short-Text Models
Paper
Abstract:
Transformer-based pretrained language models (LMs) are ubiquitous across natural language understanding, but cannot be applied to long sequences such as stories, scientific articles and long documents, due to their quadratic complexity. While a myriad of efficient transformer variants have been proposed, they are typically based on custom implementations that require expensive pre-training from scratch. In this work, we propose SLED: SLiding-Encoder and Decoder, a simple approach for processing long sequences that re-uses and leverages battle-tested short-text pretrained LMs. We find that SLED is competitive with specialized models that are up to 50x larger and require a dedicated and expensive pre-training step.
Speaker
- Maor Ivgi
- PhD candidate in Tel Aviv university,
- Maor is an NLP researcher and entrepreneur. He has vast experience in implementing state-of-the-art deep learning models for real-world use cases. He received his masters in Computer Science at Tel-Aviv University advised by Prof. Jonathan Berant, focusing on NLP models’ Robustness. As a Ph.D. candidate at Prof. Berant’s lab, his research is focused on long-range reasoning in large language models.
Slides


- NLP seems to have reached new level of maturity for use in Industry
- c.f. Attention is all you need
- c.f. BERT pre-training of deep bidirectional transformers for language understanding
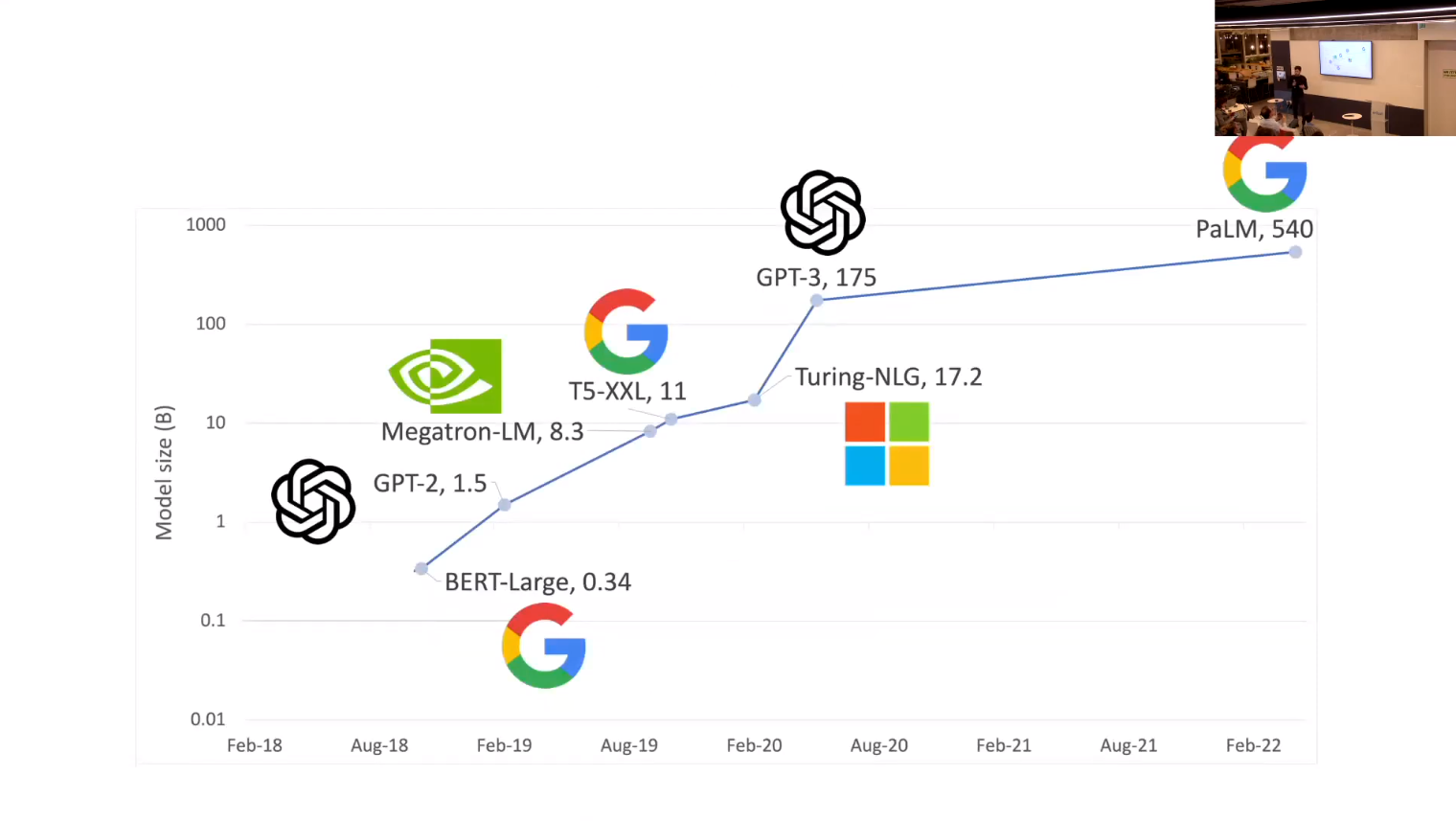





- Transformers have issues with long texts:
- self attention is O(n^2)
- cross attention is O(nk)
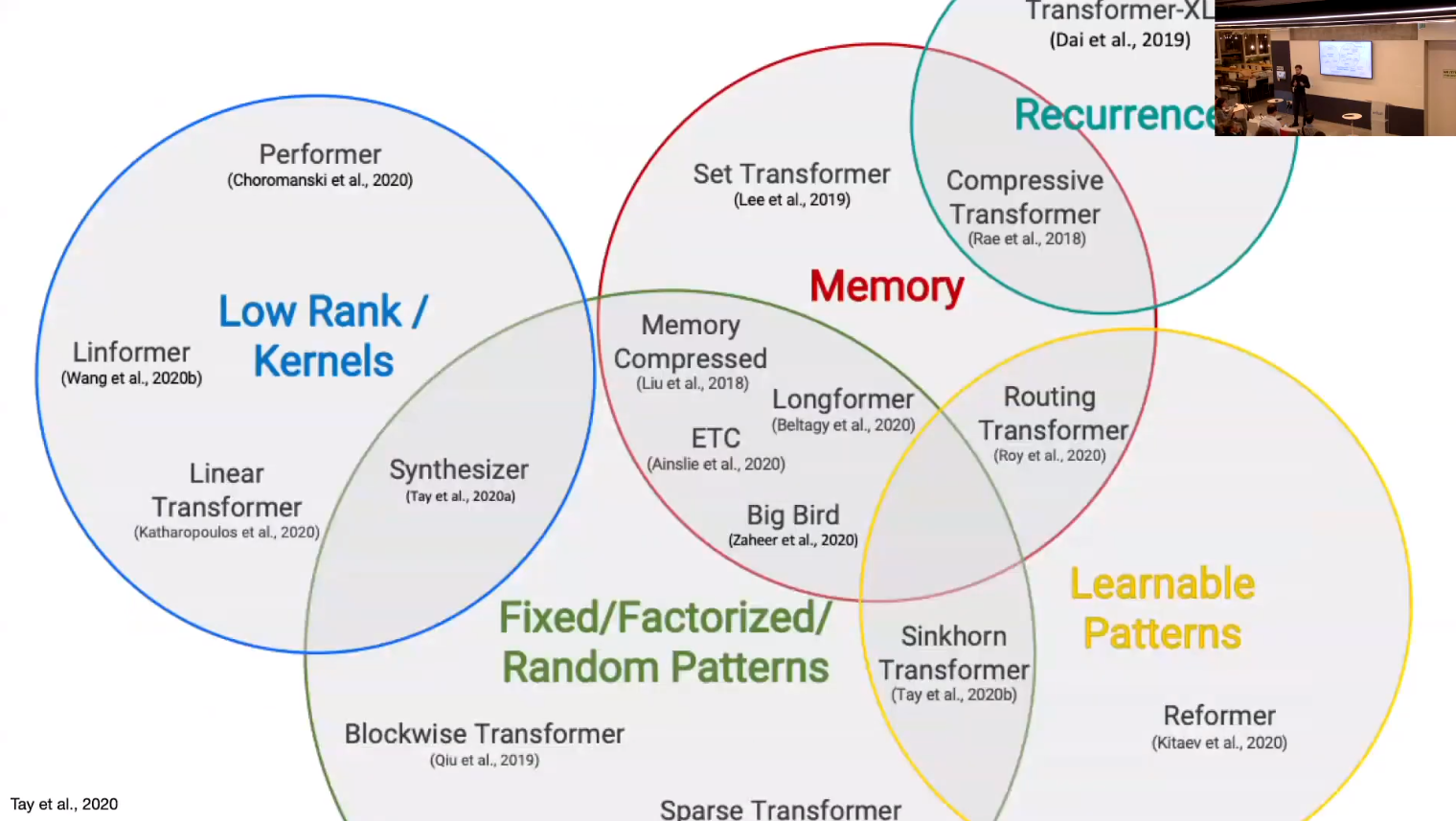
- Efficient LLM papers are:
- Hard to understand,
- Hard to generalize (due to platform specific engineering tricks)
- Expensive to reproduce
- Inference run into Memory is an issue
- Training is often on beginning of document so does not see the end
- Self Attention is has a limited window size.

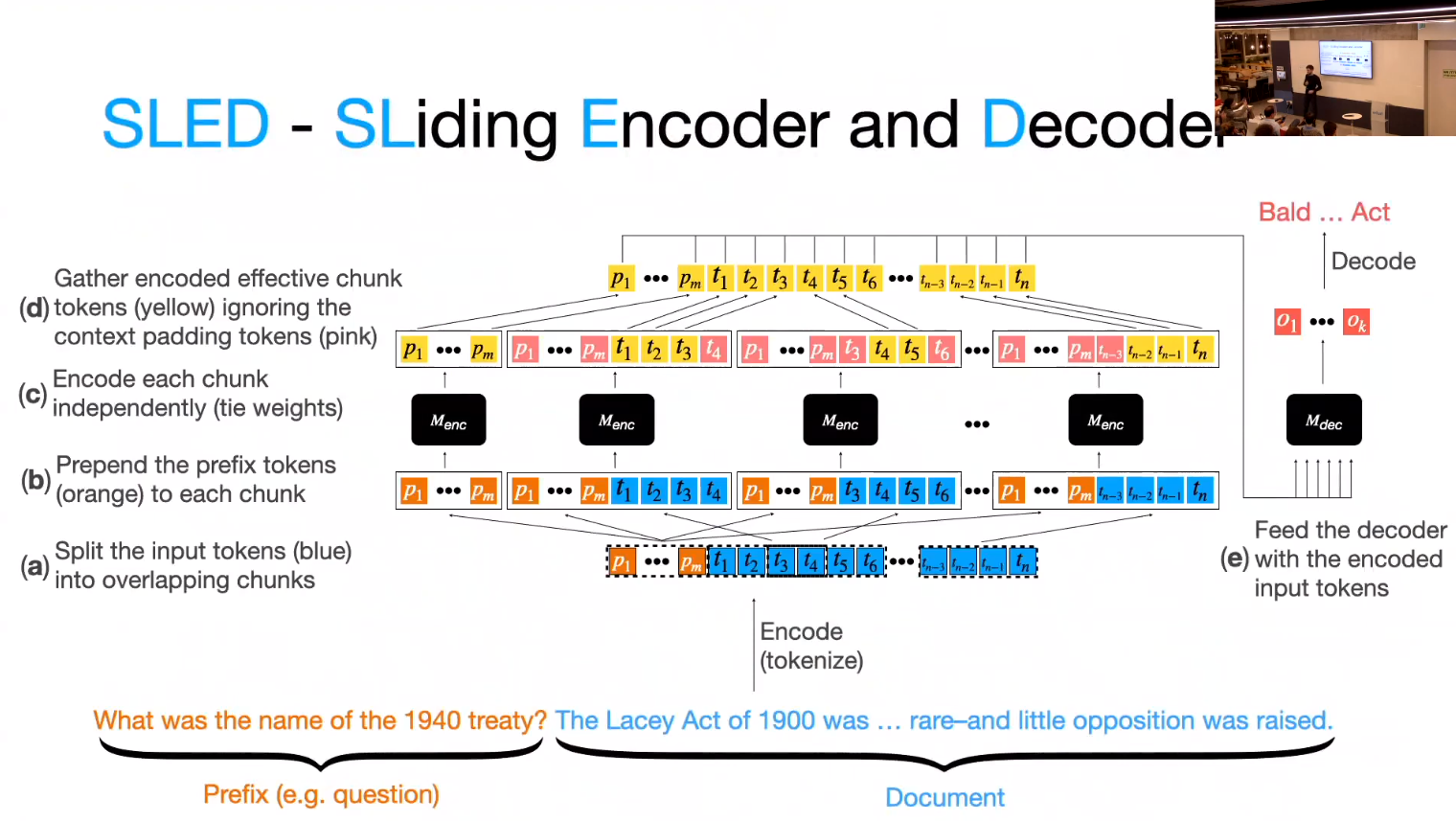
- SLED’s Approach
- Assume locality of information: “In an encoder-decoder architecture, the encoder can effectively contextualize input tokens with local context only, leaving long range dependency to be handled by the decoder.”
- Split text into short fixed length overlapping chunks of text (short contexts).
- Prepend the
prefix/promptto each chunk - The decoder will need to put it all together.

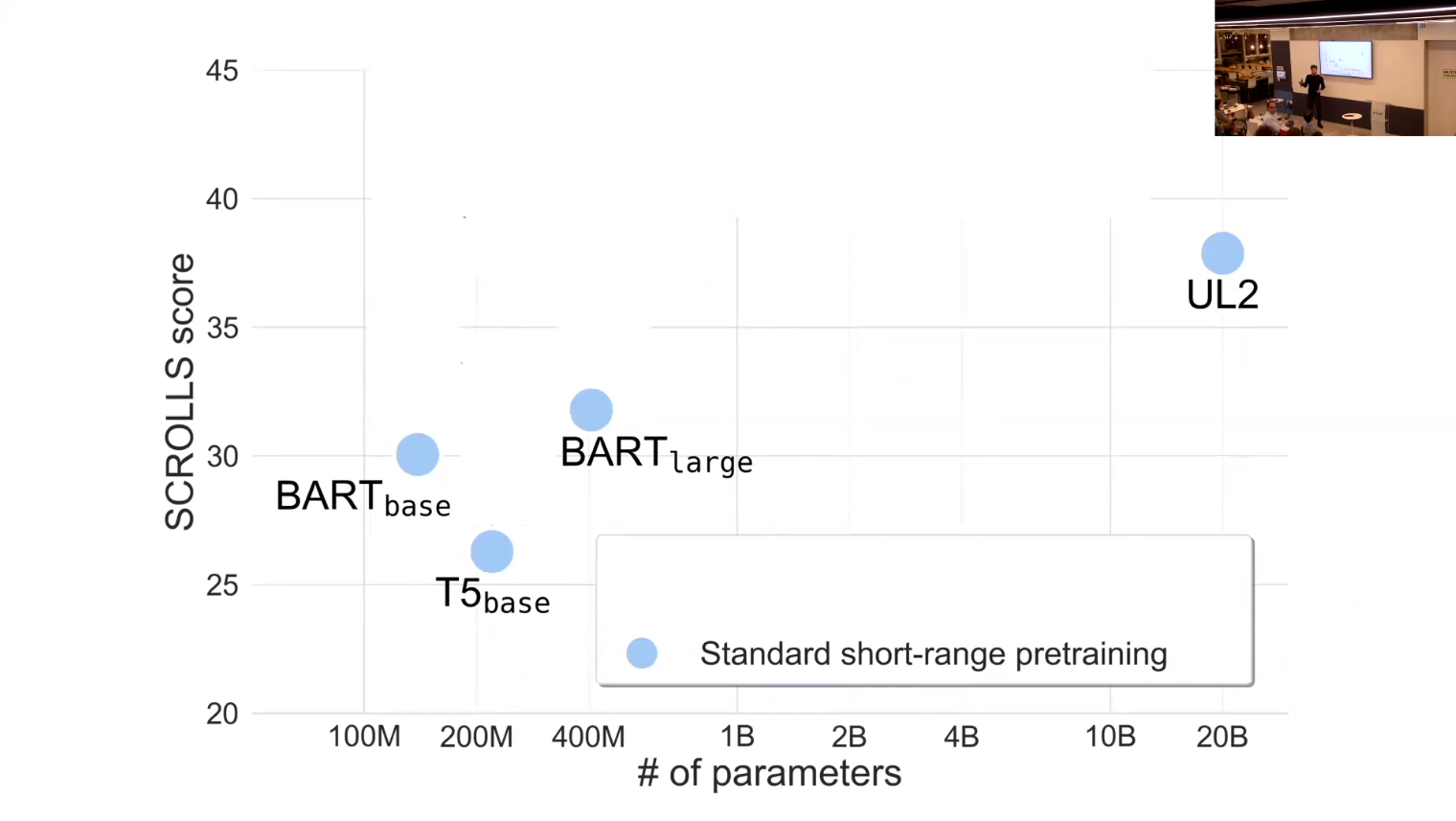
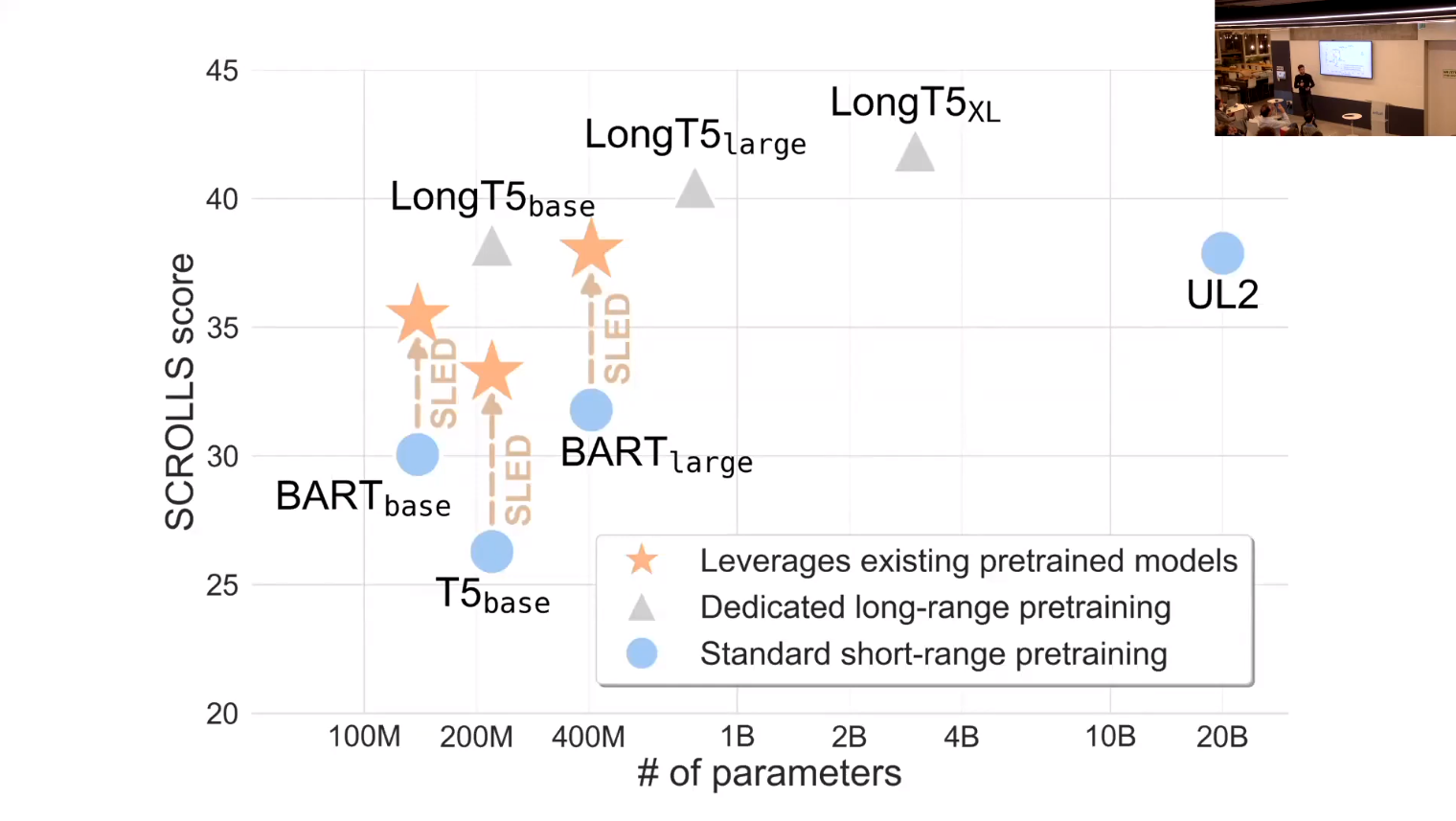


- this is a great slide!
- it summarizes lots of info
- SLED’s Analysis
- Contextual encoding is crucial
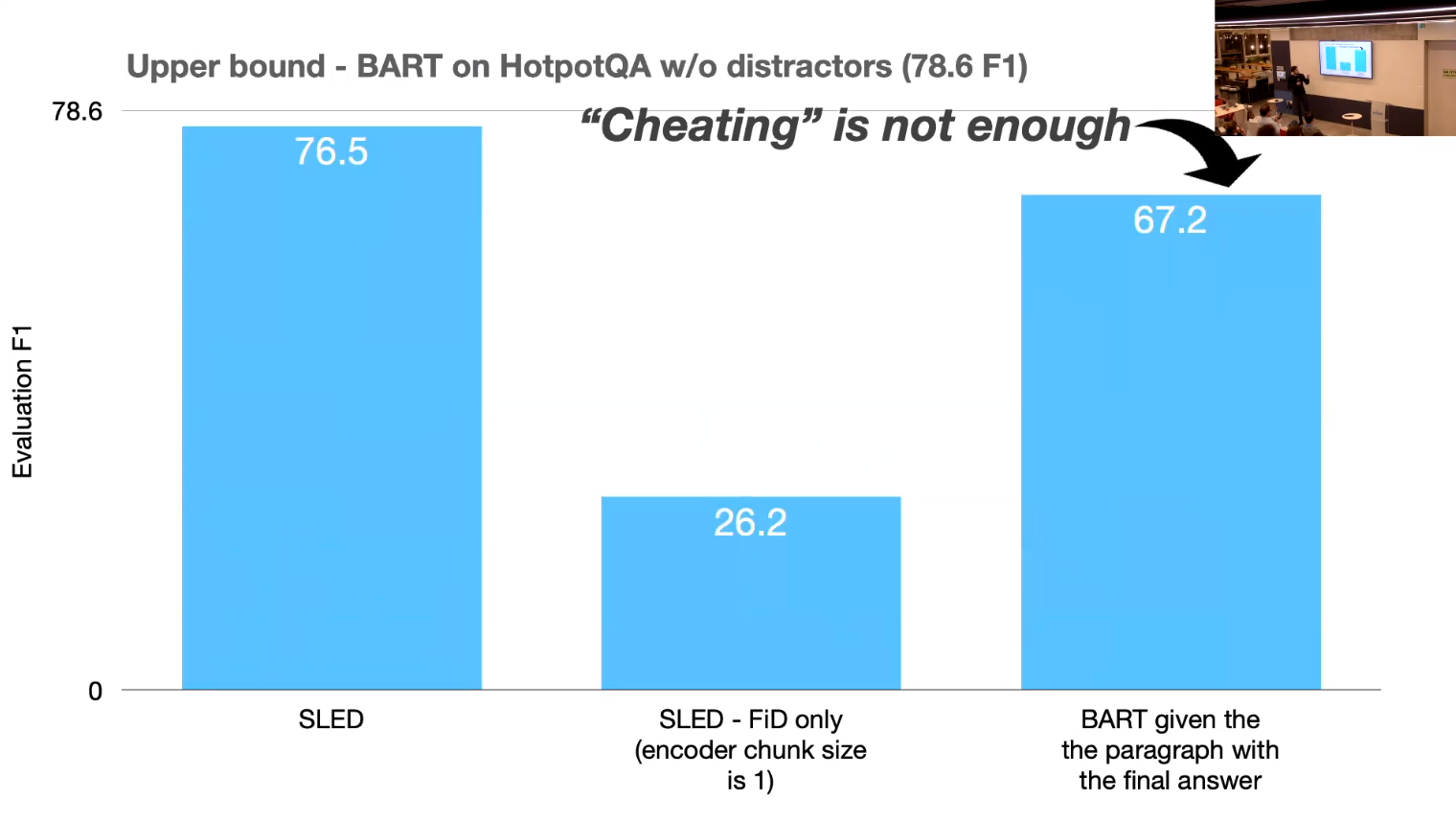
- Cheating is not enough
- The is real benefit in fusion

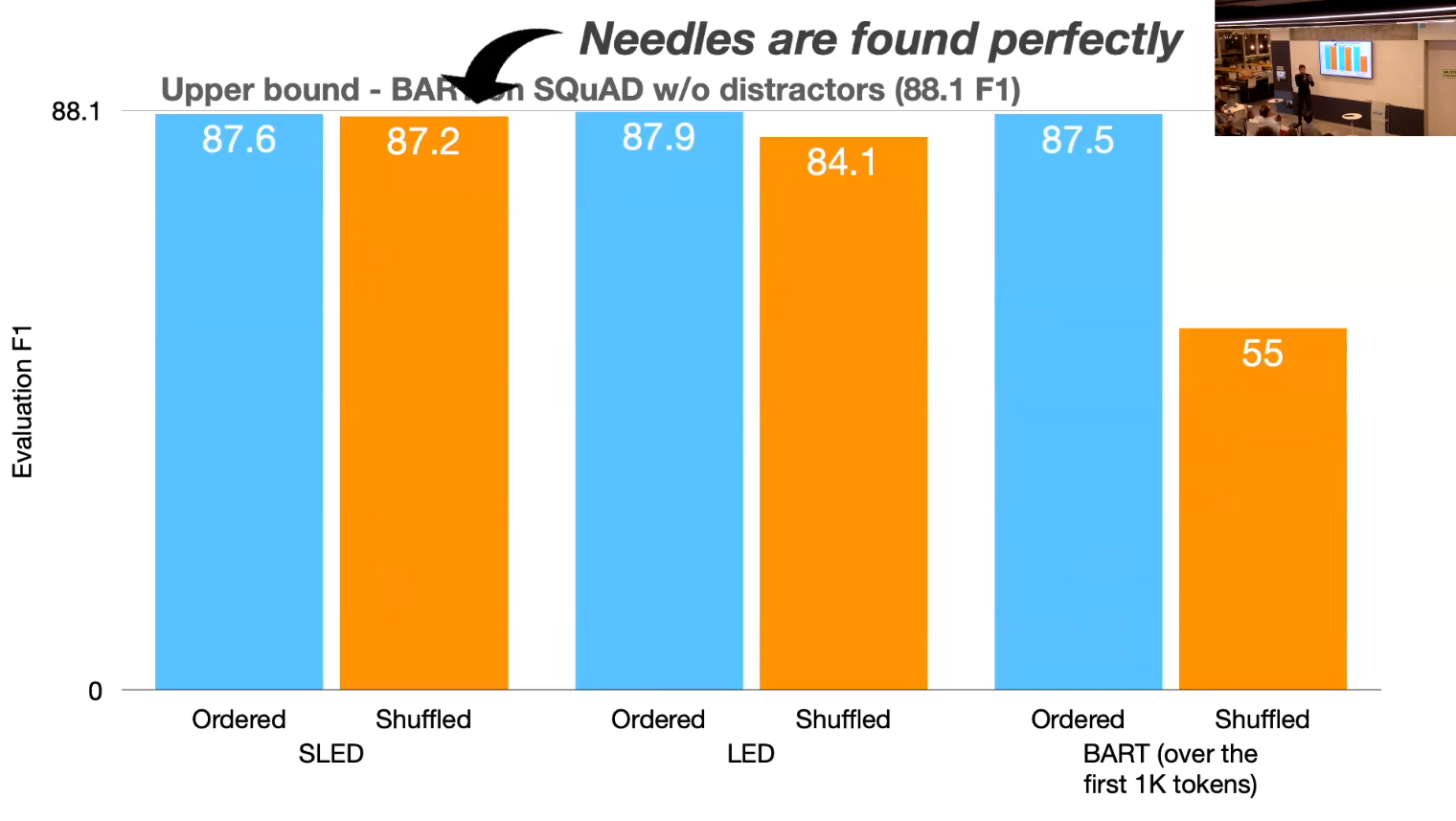

- what is Cheating?
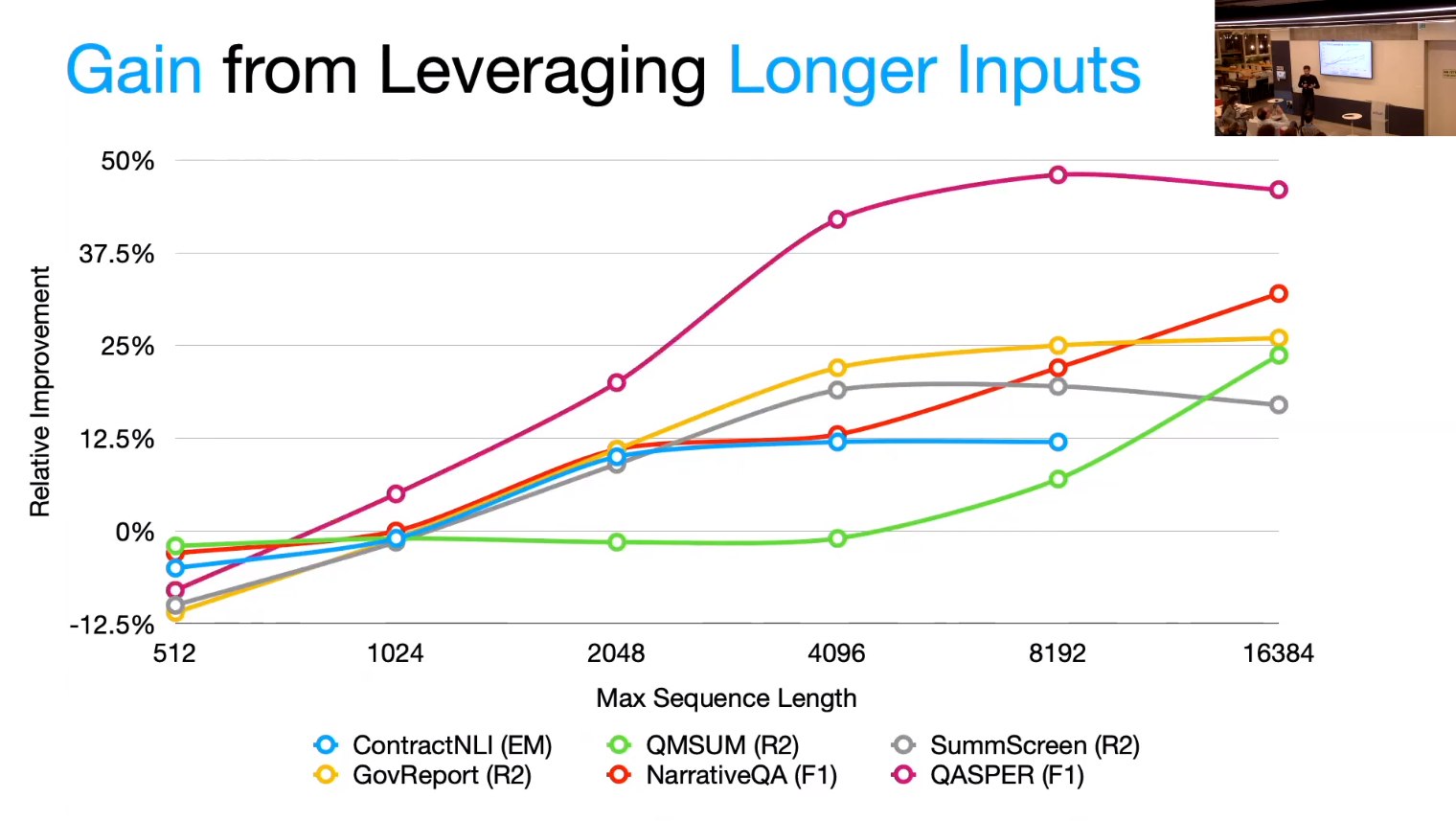
- Quantifying SLED’s benefits using relative improvement.
\text{Relative Improvement} = \frac{Score(SLED)-Score(Bart)}{Score(Bart)}


- Limits & Future Work
- Long outputs are still a constraint
- No explicit global contextualization
- No explicit global positional information
- No applicable for decoder-only architecture
- (Corrective) pre-training is expected to help

- Takeaways
- Individual pieces of information are localized
- Fusioin in decoder works
- SLED does well on long range tasks.

- Main points
They point out that the encoder can usually do a adequate job of understanding the input by looking at local context. Mostly a window with a few surrounding sentences. It uses this to create encode the input into a compact representation we call the state. The decoder will then be leverage the compression with “adaquate” encodings to efficently retrieve results from much longer contexts during inference on different tasks.
Citation
@online{bochman2015,
author = {Bochman, Oren},
title = {Efficient {Long-Text} {Understanding} with {Short-Text}
{Models}},
date = {2015-11-01},
url = {https://orenbochman.github.io/posts/2023/01-11-nlp-il-meetup-intuit/talk2.html},
langid = {en}
}