![]()
Informed Consent Forms (ICFs) are critical documents in clinical trials. They are the first, and often most crucial, touchpoint between a patient and a clinical trial study. Yet the process of developing them is laborious, high-stakes, and heavily regulated. Each form must be tailored to jurisdictional requirements and local ethics boards, reviewed by cross-functional teams, and written in plain language that patients can understand. Producing them at scale across countries and disease areas demands manual effort and creates major operational bottlenecks. We used a combination of traditional AI and large language models to autodraft the ICF across clinical trial types, across countries and across disease areas at scale. The build, test, iteration and deployment offers both technical and non technical lessons learned for generative AI applications for complex documents at scale and for meaningful impact.
Informed Consent Forms are highly complex documents that require high precision and quality. A phase 2 / 3 clinical trial can have almost 1000 different forms that takes considerable time to complete. We identified this challenge that directly impacts trial timelines and patient engagement.
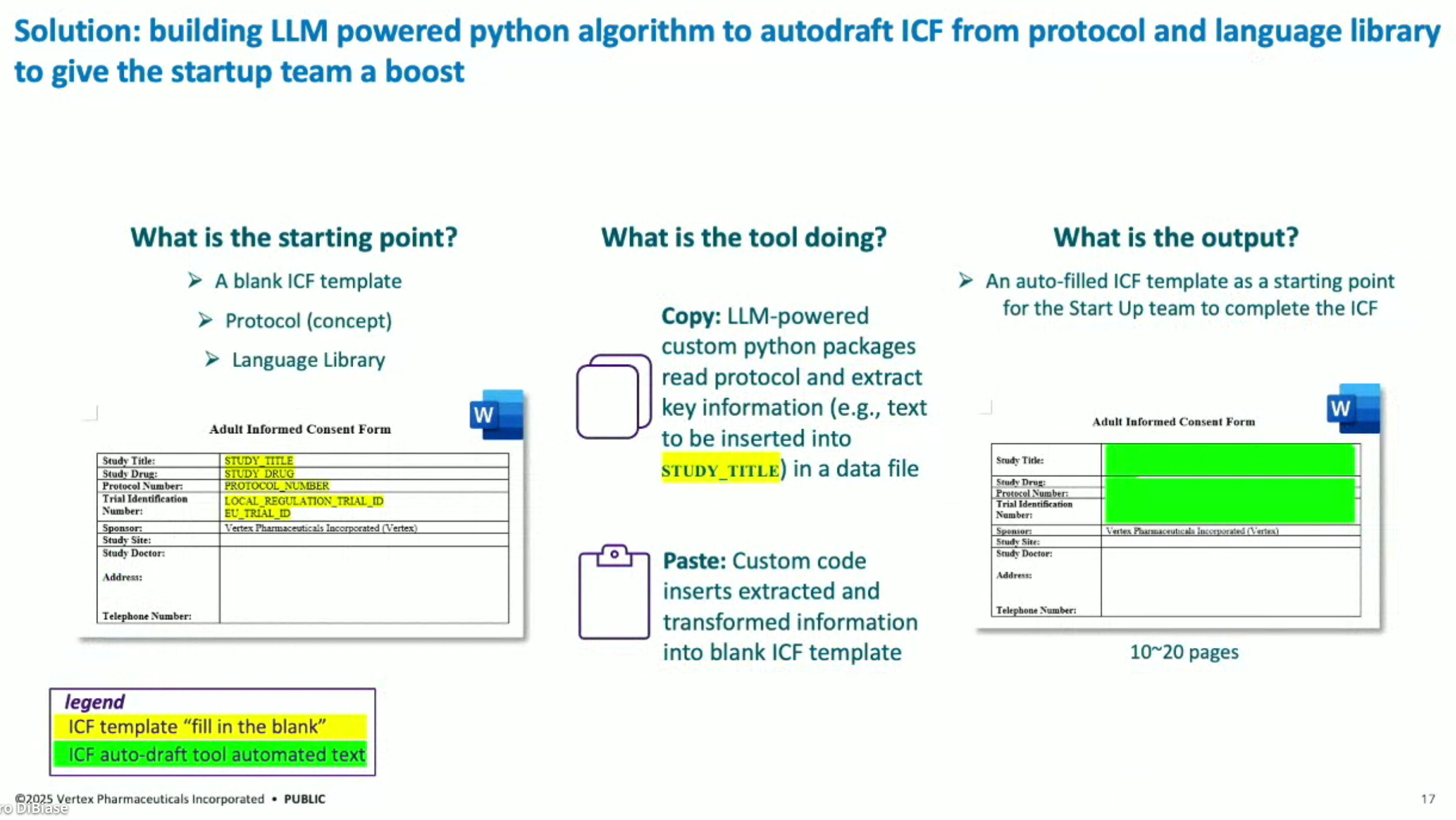
The automated AI solution: the “ICF Autodrafter”, a custom LLM-powered application that automates the drafting of ICFs. This tool ingests a clinical trial protocol and ICF template and outputs a complete draft in minutes, cutting document preparation time by 90%.
This solution is not generic automation. The backend logic parses highly structured protocol documents, segments them, and feeds the relevant content into a carefully fine-tuned LLM that maps text to specific ICF fields. The front-end is designed for usability by clinical trial managers, with human-in-the-loop reviews.
This system has already supported ICF creation for more than ten trials and has achieved near-perfect consistency (97%) with human-generated content, underscoring the speed, quality, and robustness of the solution.
We rigorously test version with A/B comparisons, iterated with feedback from end-users, and anchored all development within regulatory and ethical guardrails. The impact extends beyond efficiency.
By standardizing and accelerating ICF production, we can reduce delays in trial start-up and potentially get medicines to patients faster, without compromising safety, compliance, or clarity.
Furthermore, it also lays down a scalable model for future AI-driven document workflows across other parts of life sciences and healthcare.
Lily Xu

Outline
Vertex’s Data Strategy and Solutions team uses AI, including traditional AI and large language models (LLMs), to automate complex and critical documents in healthcare, specifically focusing on Informed Consent Forms (ICFs) for clinical trials.

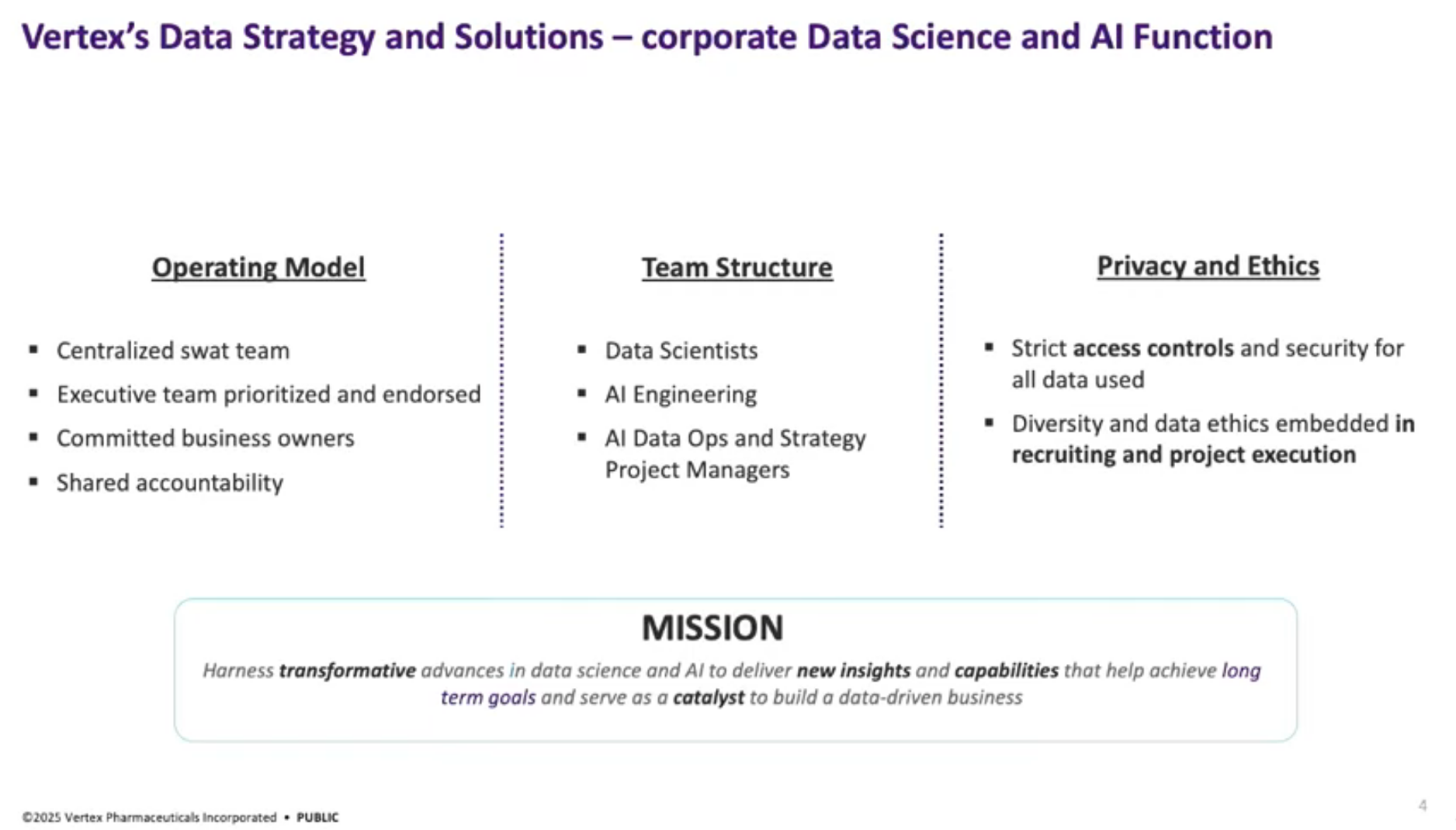
Team Overview: Lily Xu introduces the Data Strategy and Solutions team at Vertex, which functions as a “SWAT team” to address high-impact projects. The team emphasizes close collaboration with business partners and measures the impact of their solutions.

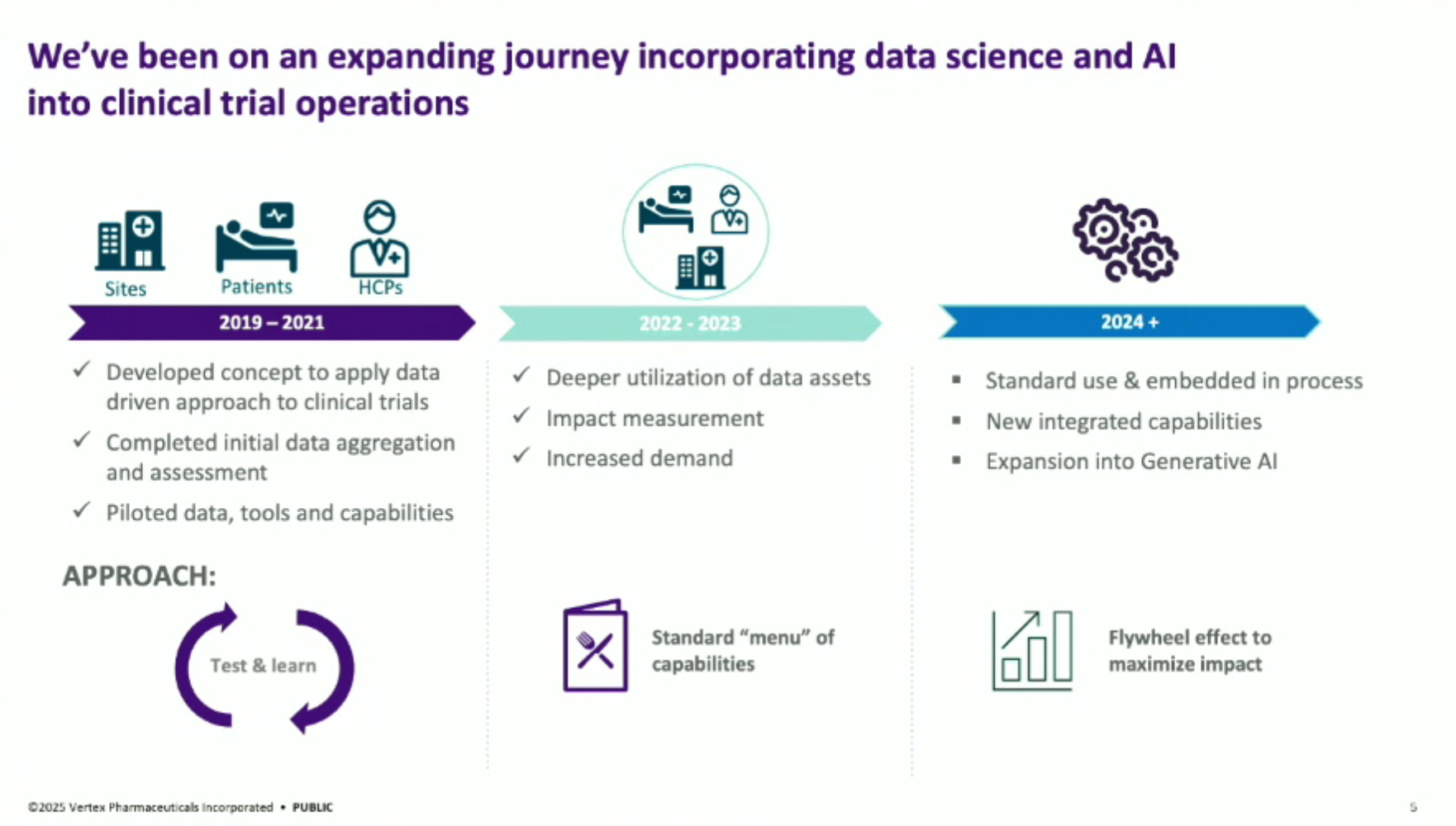
Clinical Trial Operations: The speaker provides context on clinical trial operations, highlighting the significant financial and operational complexities involved, such as patient recruitment, site selection, and investigator collaboration. They discuss the team’s evolution from piloting small solutions in 2019 to standardizing offerings and expanding into generative AI in 2024.
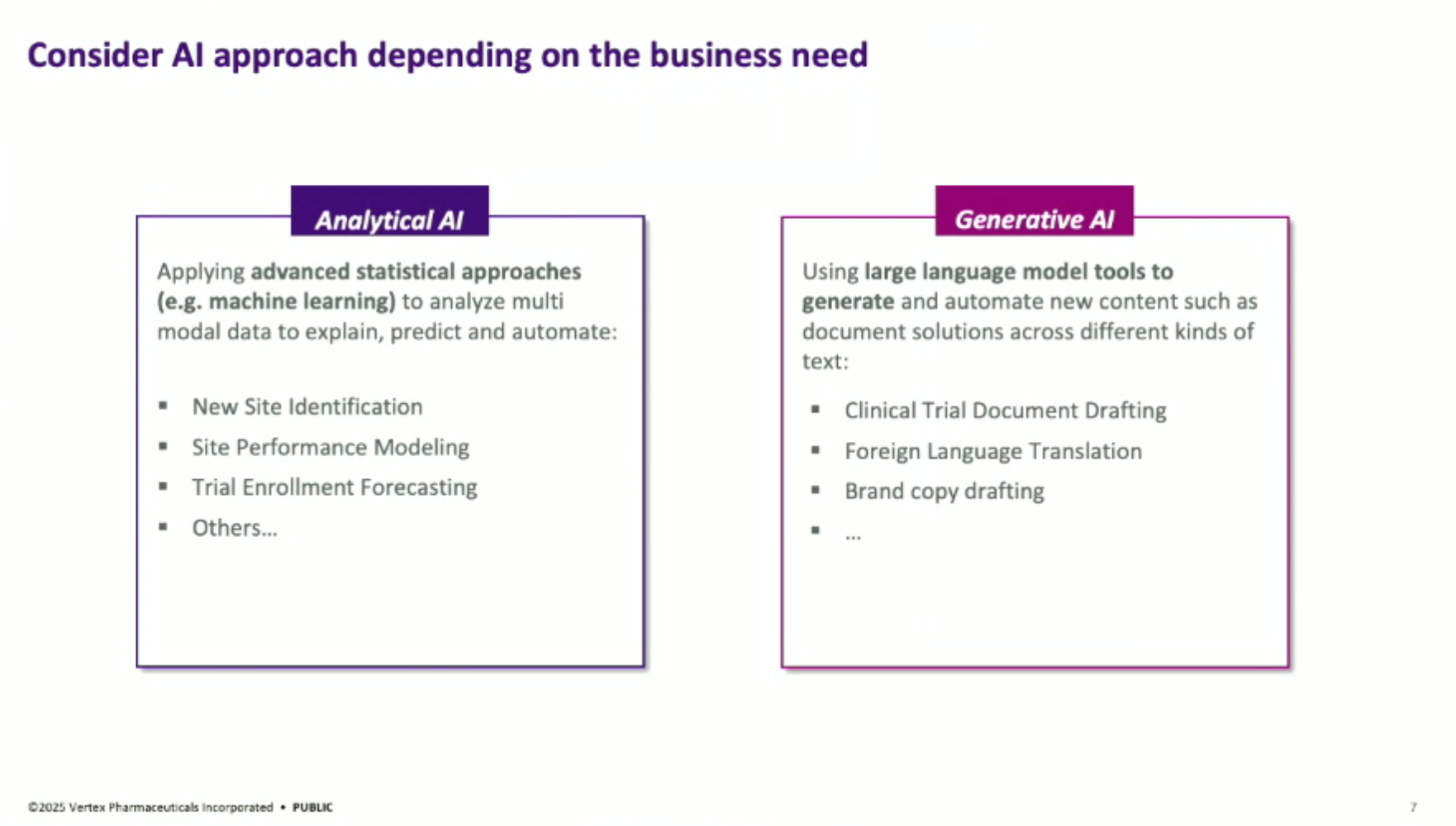
Analytical AI vs. Generative AI: The presentation distinguishes between analytical AI (e.g., site identification, trial performance prediction) and generative AI (e.g., generating document first drafts, brand copy). The team aims to educate business partners on when to apply each technology for problem-solving.
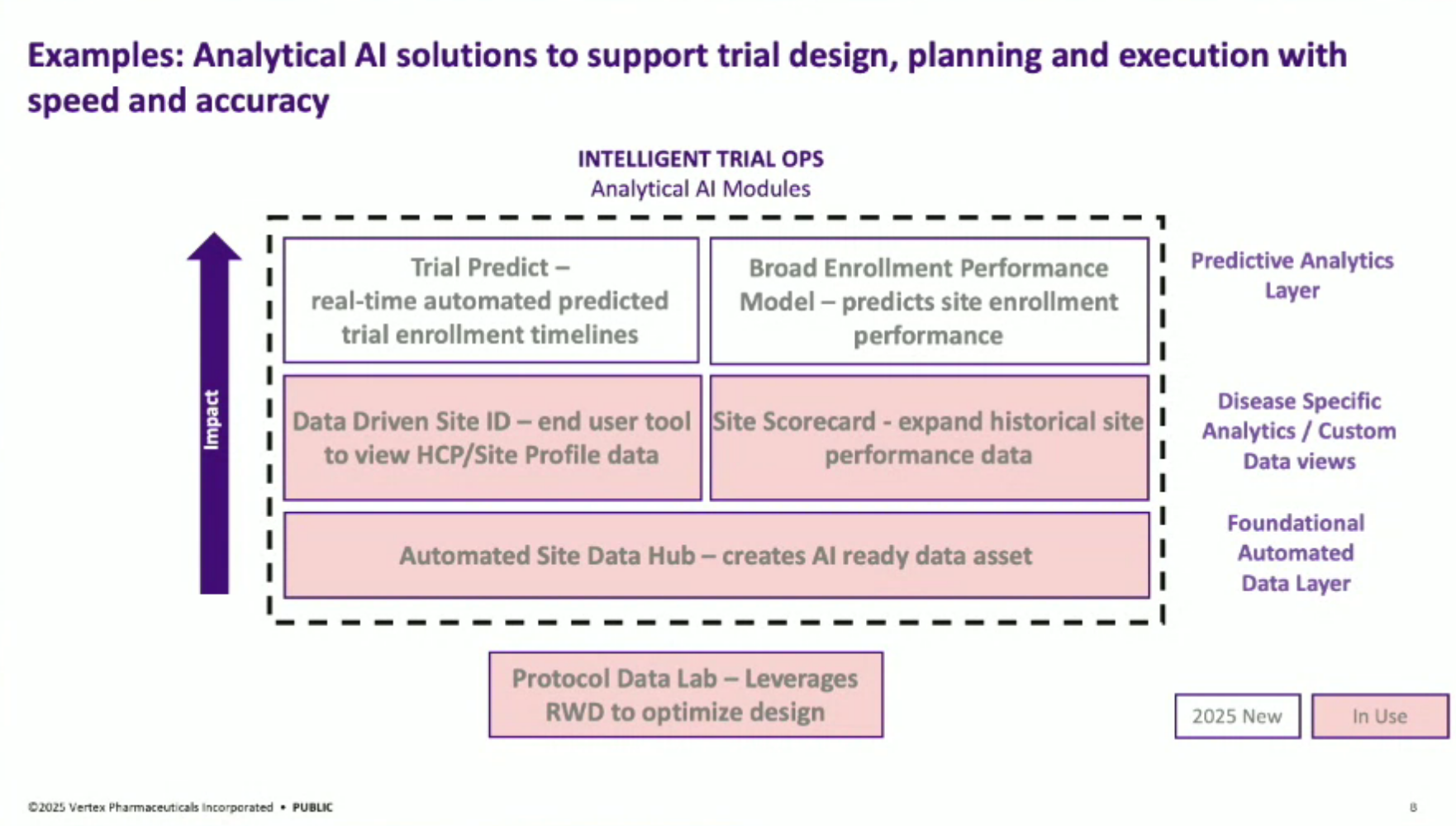
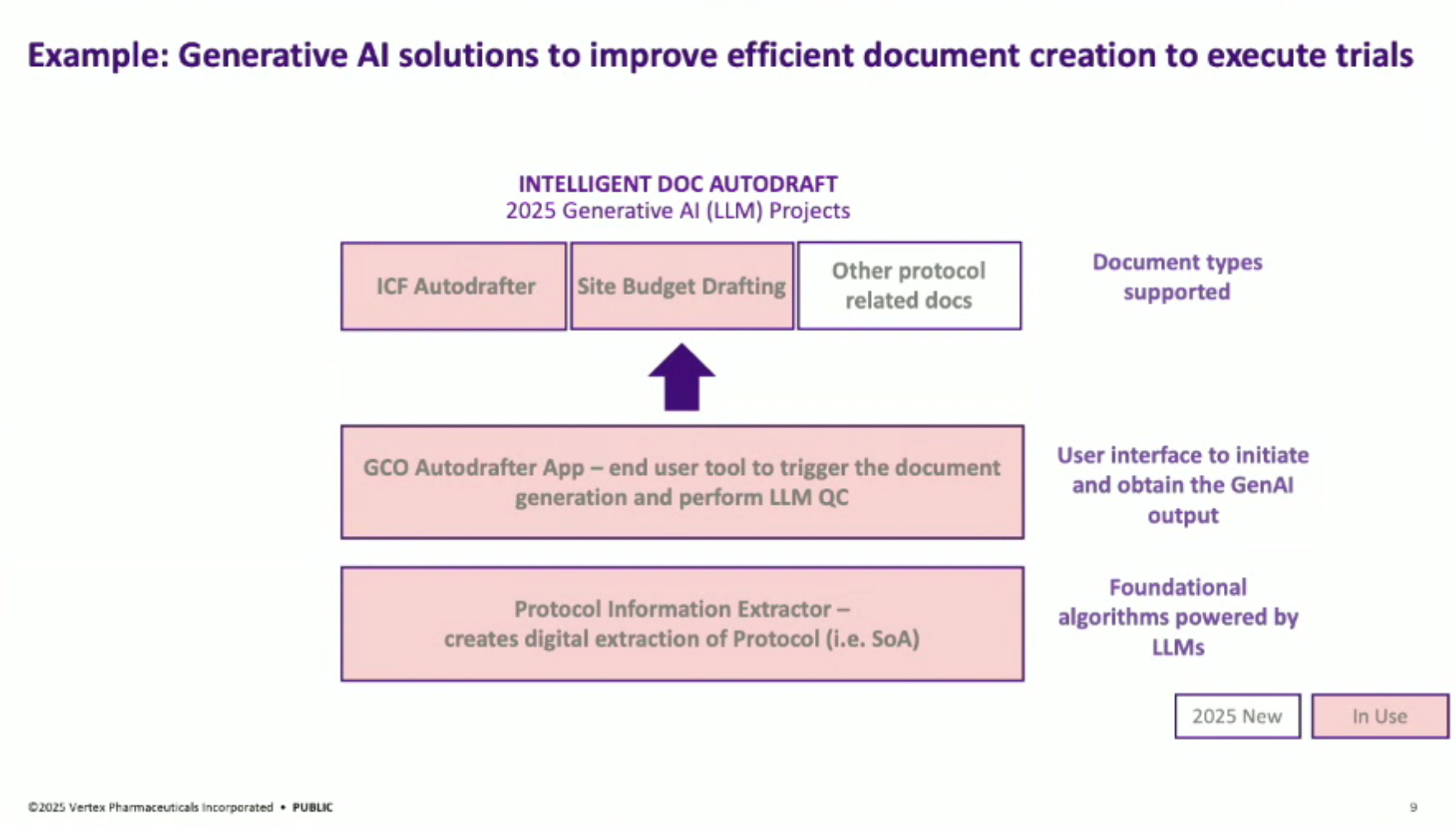
Solution Architecture: The general architecture of their AI solutions involves foundational automated data layers, disease-specific analytics, and predictive layers. For generative AI, it focuses on extracting information from complex documents like clinical trial protocols, implementing a user interface with a crucial QC piece to minimize hallucination risks, and automating document generation.
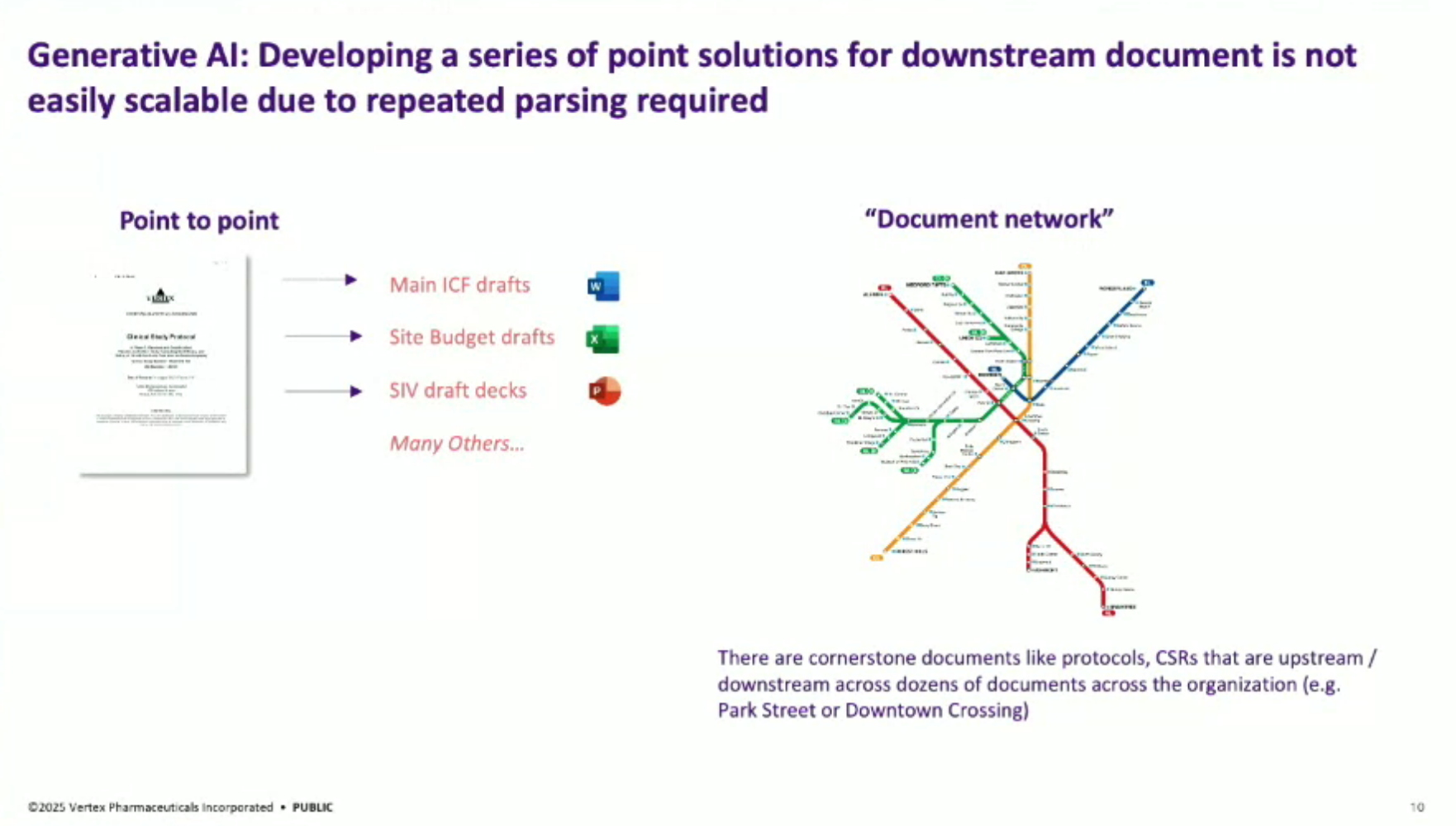
Document Autodrafting Map: The team developed a “document network” approach to map out clinical trial documents, identifying cornerstone documents like clinical trial protocols and clinical study reports that can maximize synergy and impact when automated.
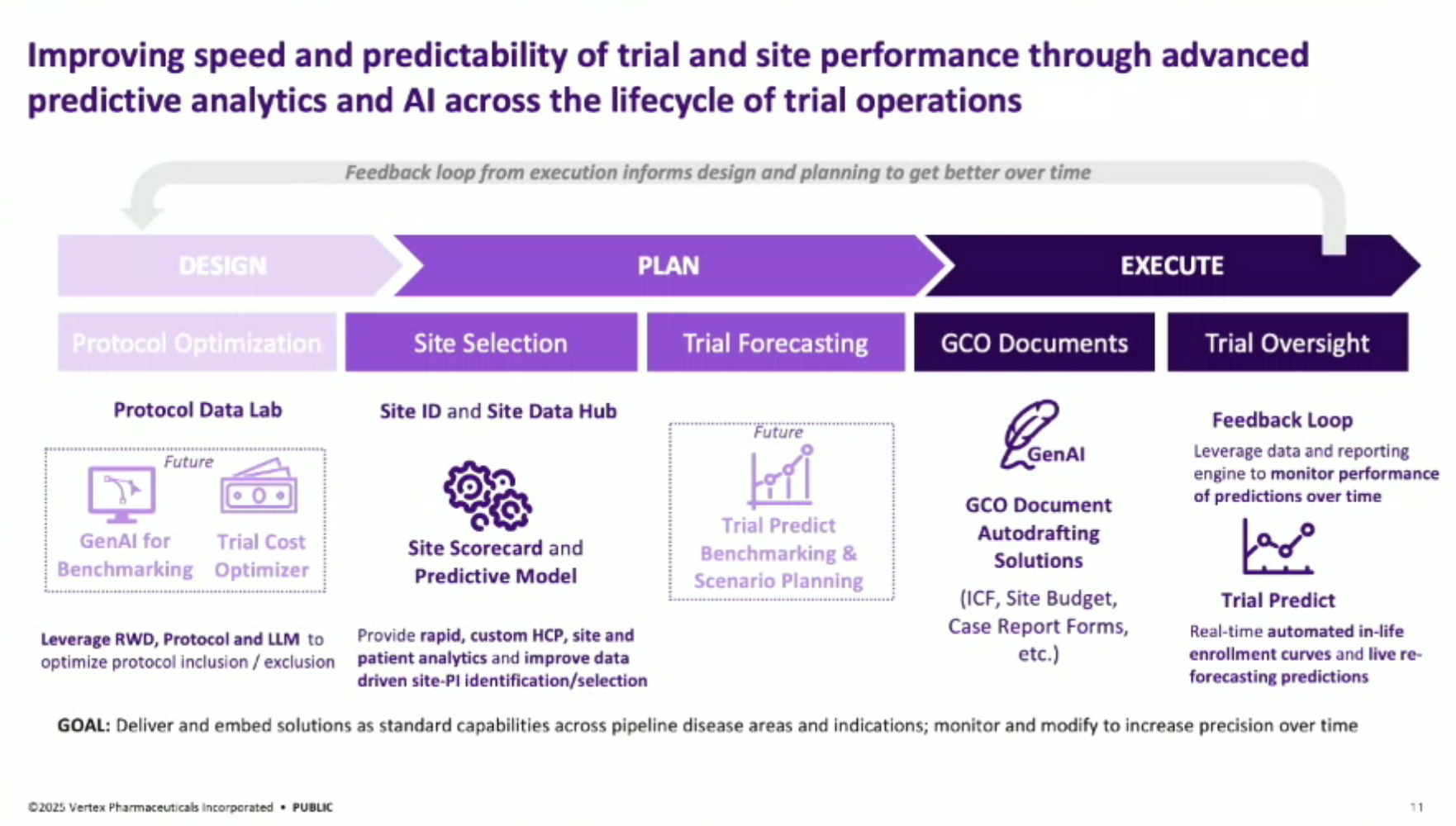
Clinical Trial Life Cycle: The speaker describes the entire life cycle of clinical trial operations, from design (optimizing protocols), planning (site selection), and execution (document autodrafting) to monitoring.

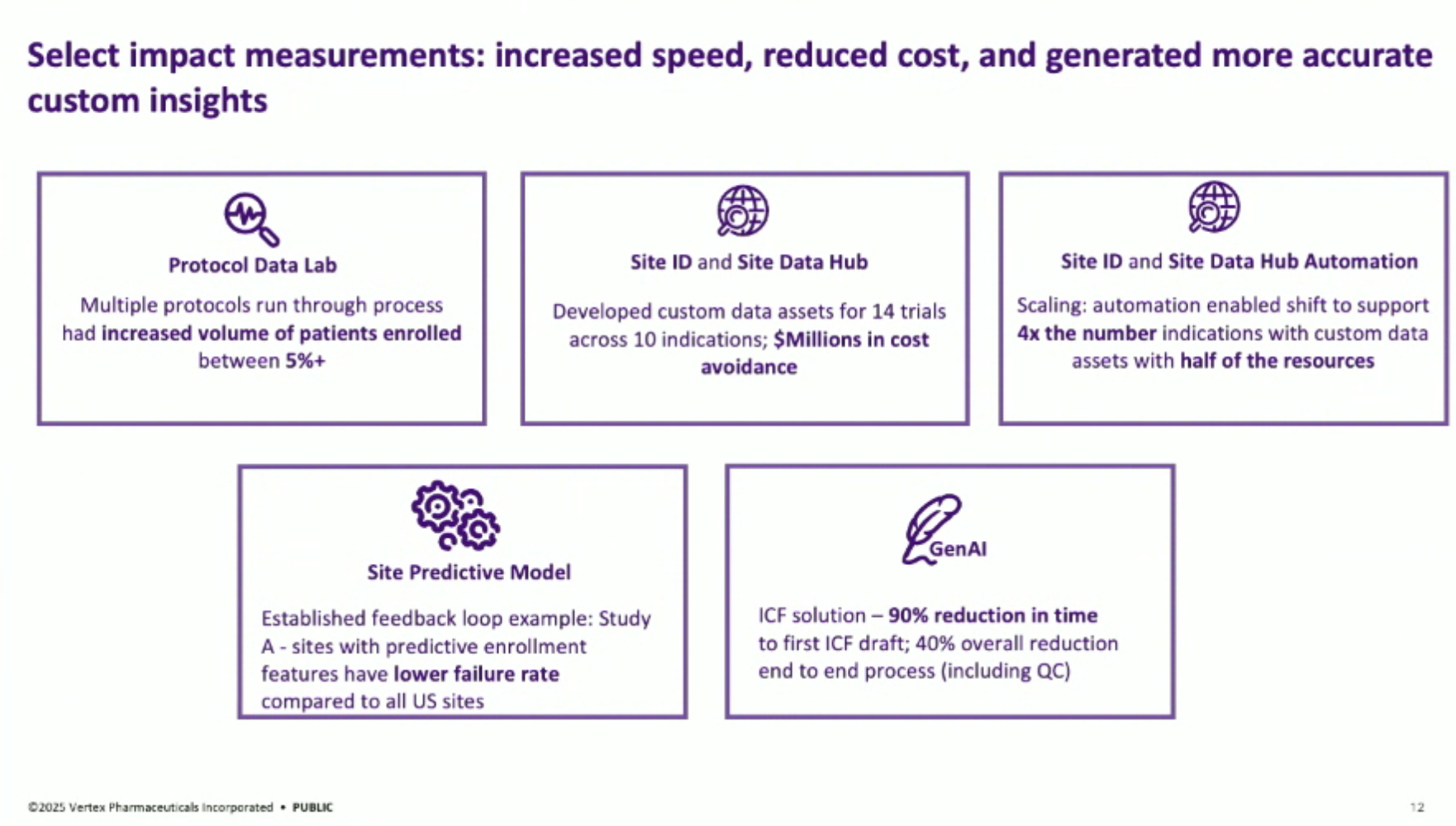
Measuring Impact: A core focus of the team is measuring the impact of their solutions, using metrics such as increased patient enrollment, cost avoidance, and efficiency gains.
Case Study: Automating ICFs: The main case study focuses on automating the drafting of Informed Consent Forms (ICFs). The importance of ICFs is highlighted due to their patient-facing nature, regulatory requirements, site-specific variations, and impact on approval timelines.
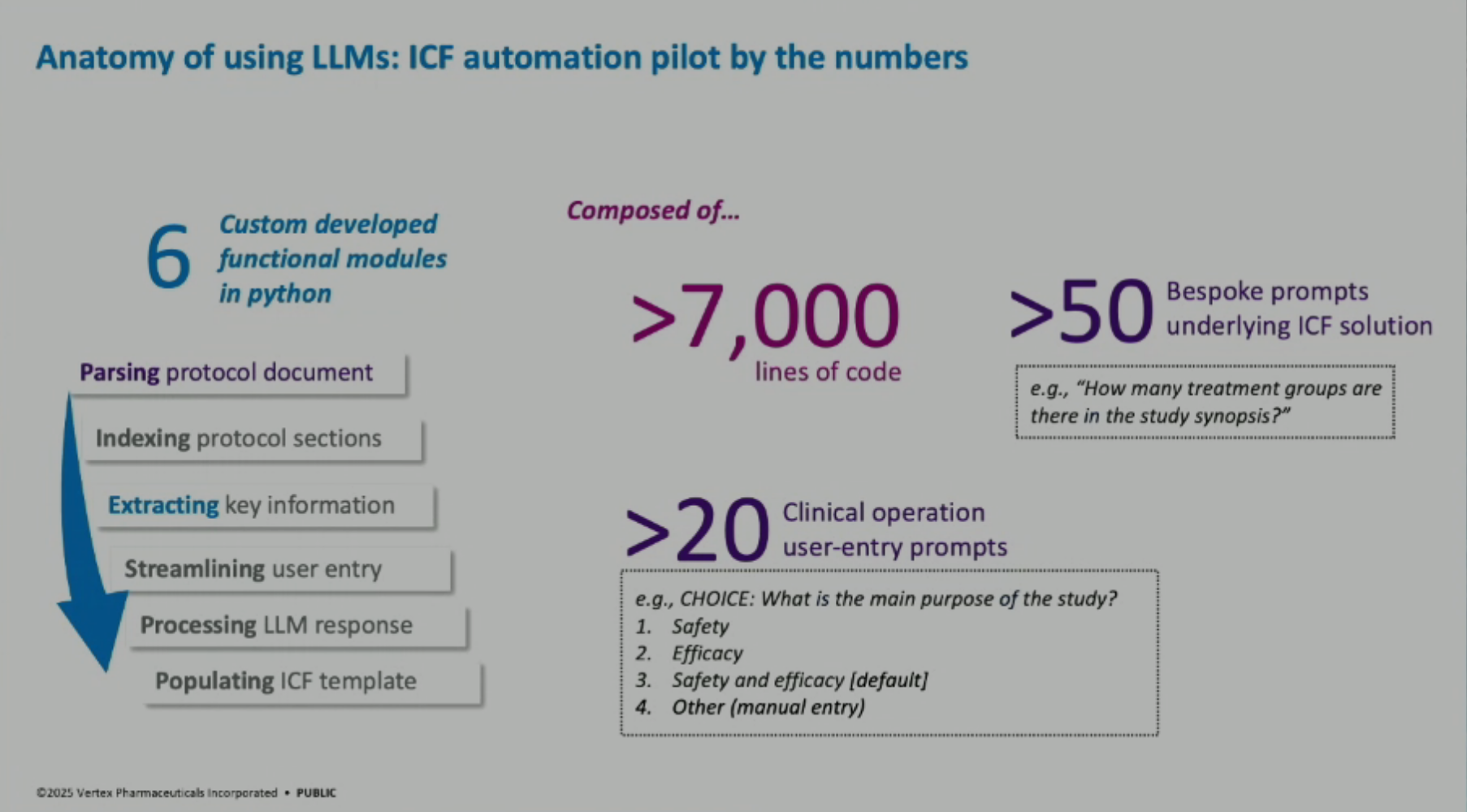
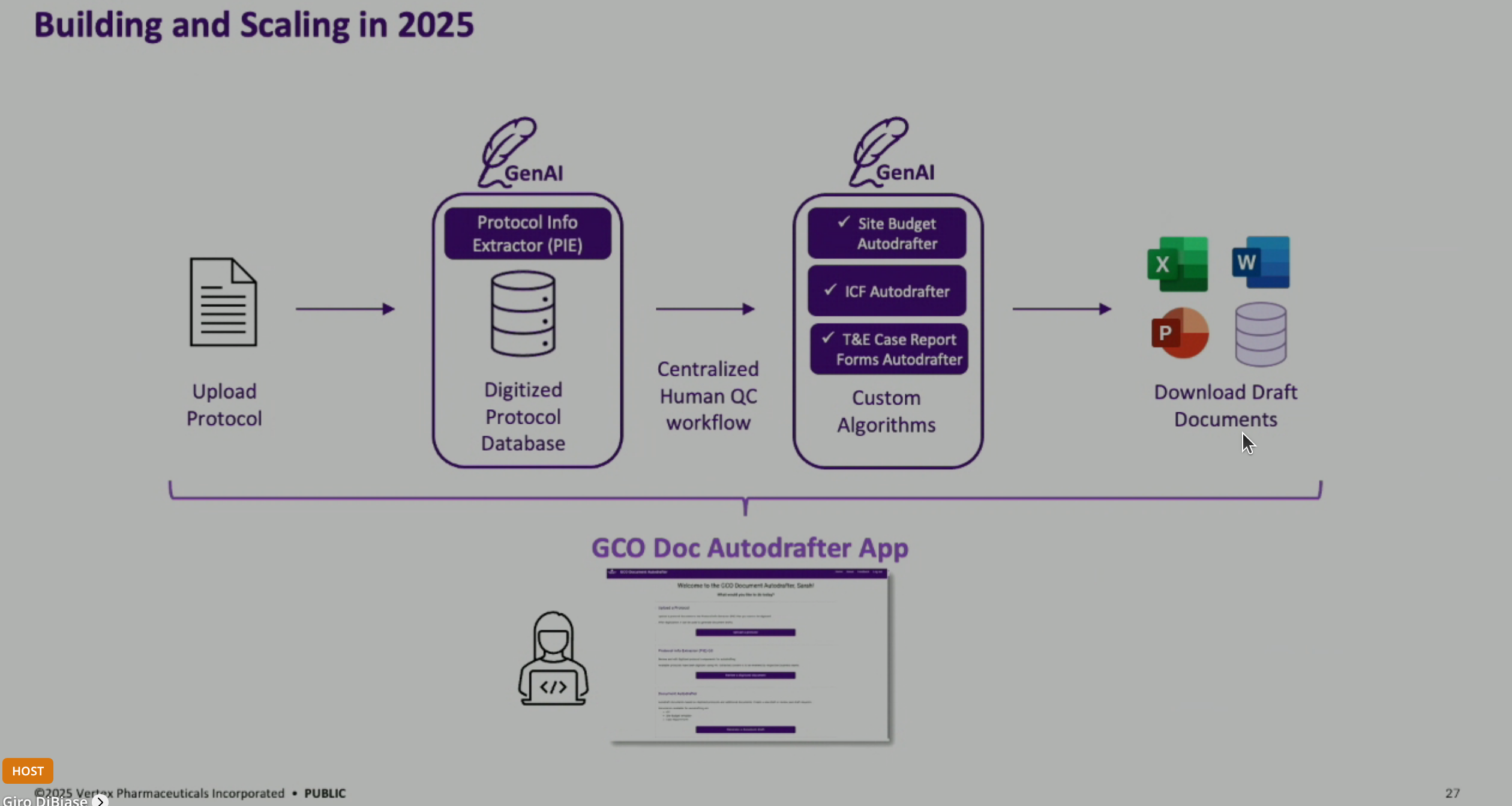
ICF Autodrafting Process: The solution involves an LLM-powered series of Python algorithms that draft ICFs from protocols and language libraries. The process extracts information from a protocol, integrates it with approved language snippets, and populates a blank ICF template to produce a first draft.
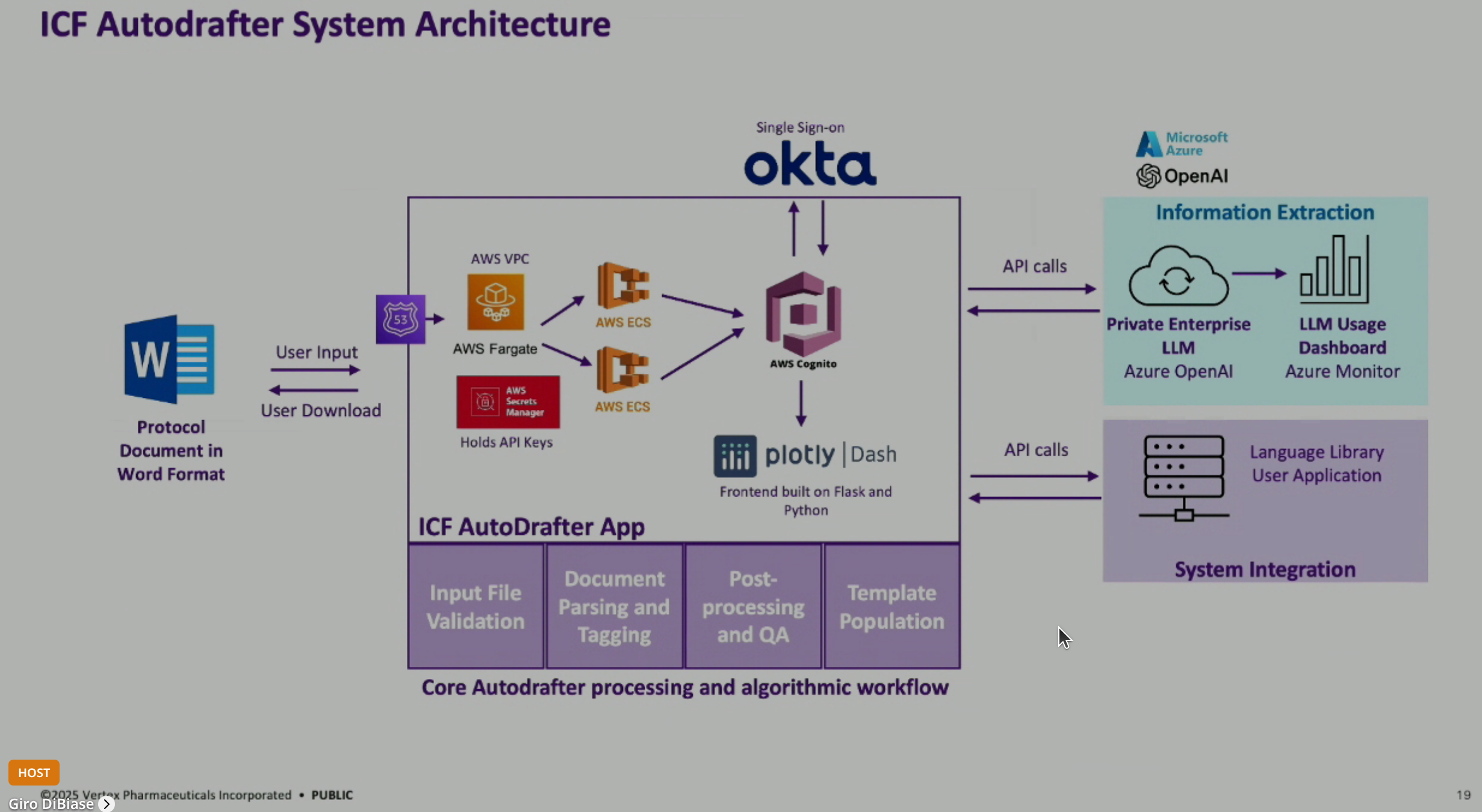
Technical Architecture of LLM Solutions: The LLM solutions are primarily built with Python programming and software engineering, with a smaller portion dedicated to LLM prompting. The application is built on Flask and Python Dash, hosted on AWS, and integrates with Microsoft OpenAI’s private LLM and a custom language library system.
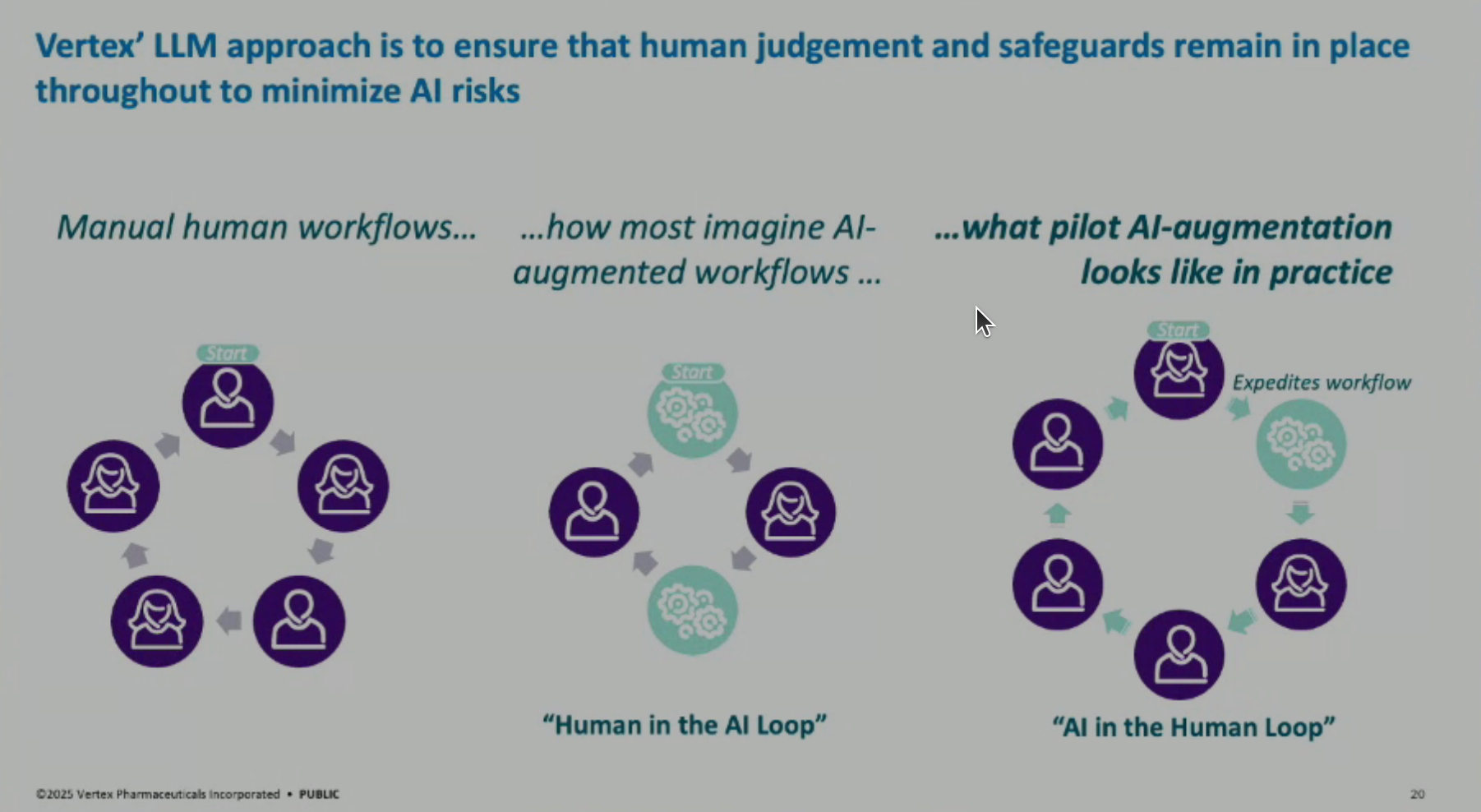
AI in the Human Loop: Vertex emphasizes an “AI in the human loop” approach for pharmaceutical companies, where AI accelerates specific bottlenecks in a human-centric, highly regulated workflow, rather than a fully automated “human in the AI loop.”
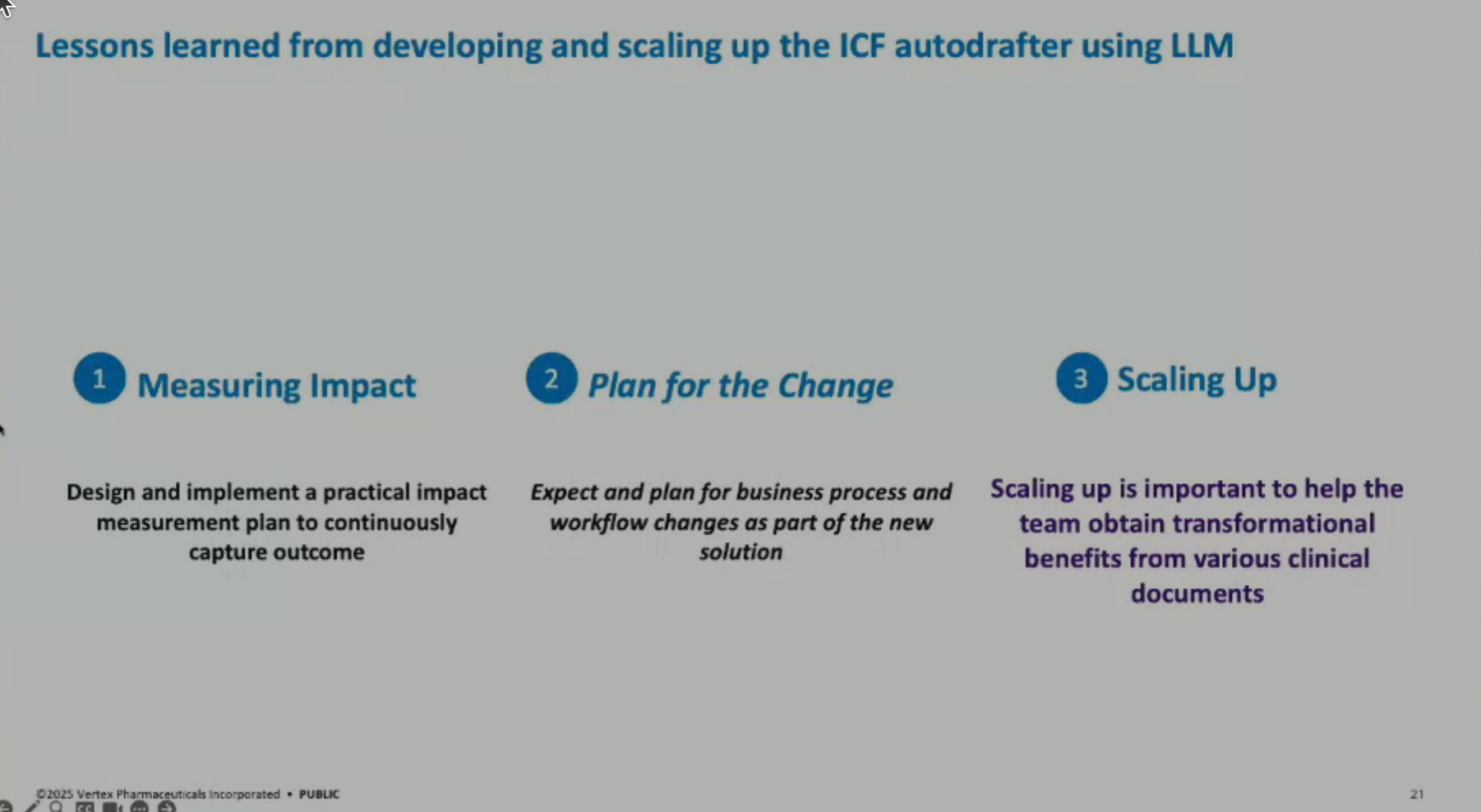
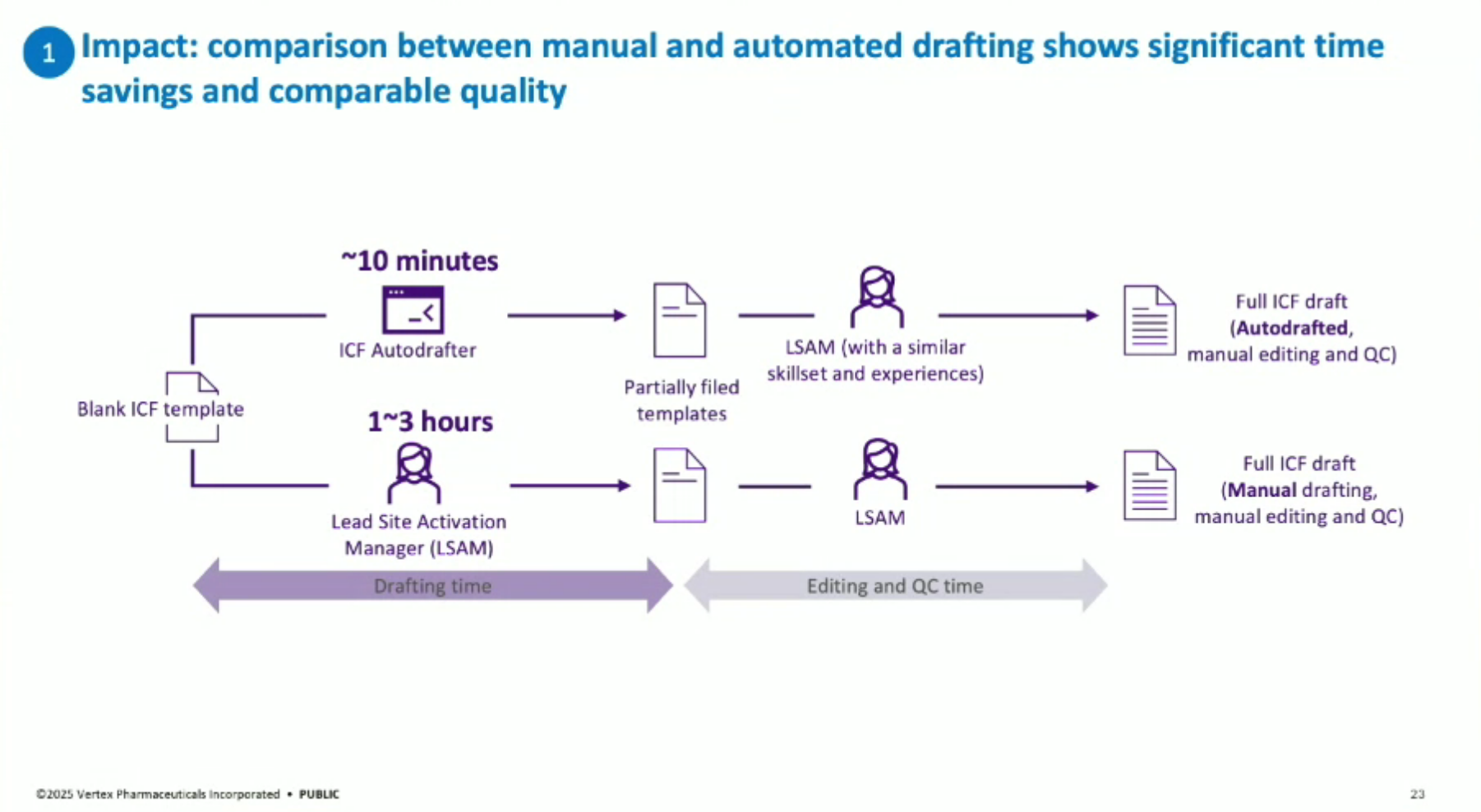
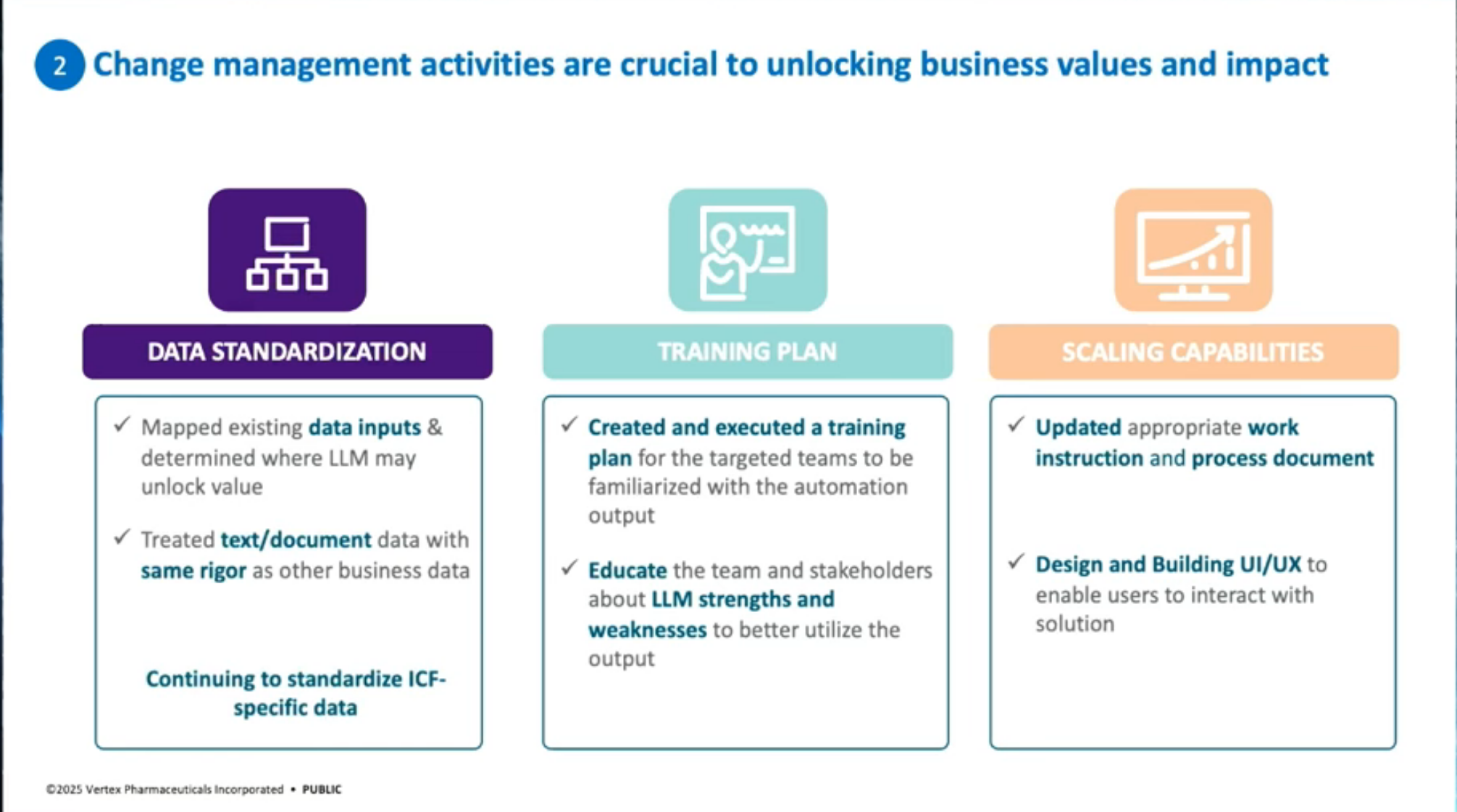
Lessons Learned: Key lessons include the importance of measuring impact (demonstrating 90% time savings in drafting and 40% end-to-end time savings with editing and QC), and emphasizing change management through data standardization, training plans, and scaling up solutions across multiple documents and countries.
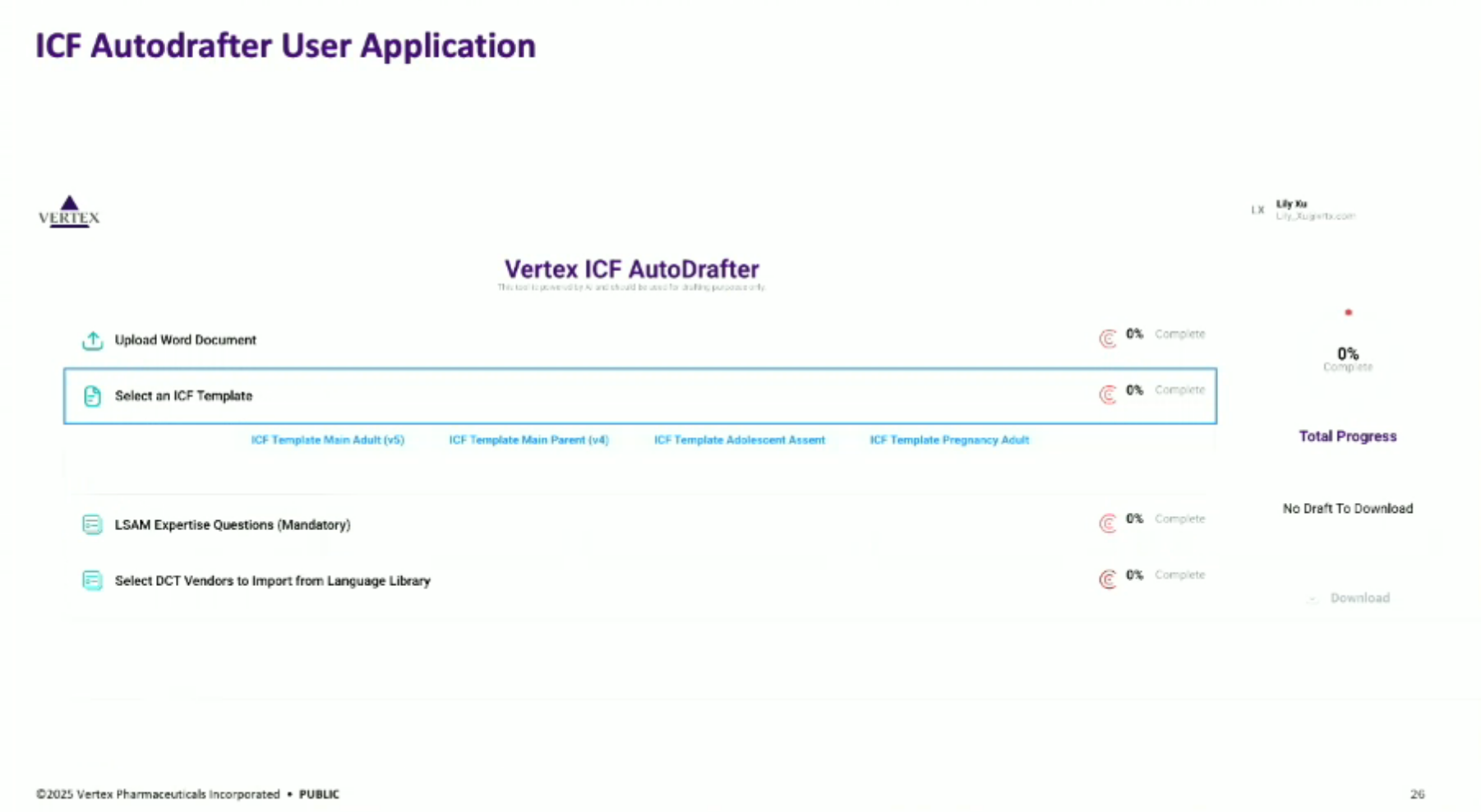
Showcasing the user application, which allows users to upload documents, select templates, and generate multiple drafts for different countries simultaneously, aiming for a more general document autodrafting application.
Reflections and Lessons Learned
Some interesting insights about handling critical documents in regulated environments using AI. It can speed up the process significantly while maintaining high quality.
Perhaps the main point is that LLM are used to reduce work load but a human is kept in the loop to ensure quality and compliance. The real question is if all AI errors and biases can be mitigated by this human.
Citation
@online{bochman2025,
author = {Bochman, Oren},
title = {Using {Traditional} {AI} and {LLMs} to {Automate} {Complex}
and {Critical} {Documents} in {Healthcare}},
date = {2025-12-09},
url = {https://orenbochman.github.io/posts/2025/2025-12-09-pydata-automate-complex-and-critical-docs-in-healthcare/},
langid = {en}
}