![]()
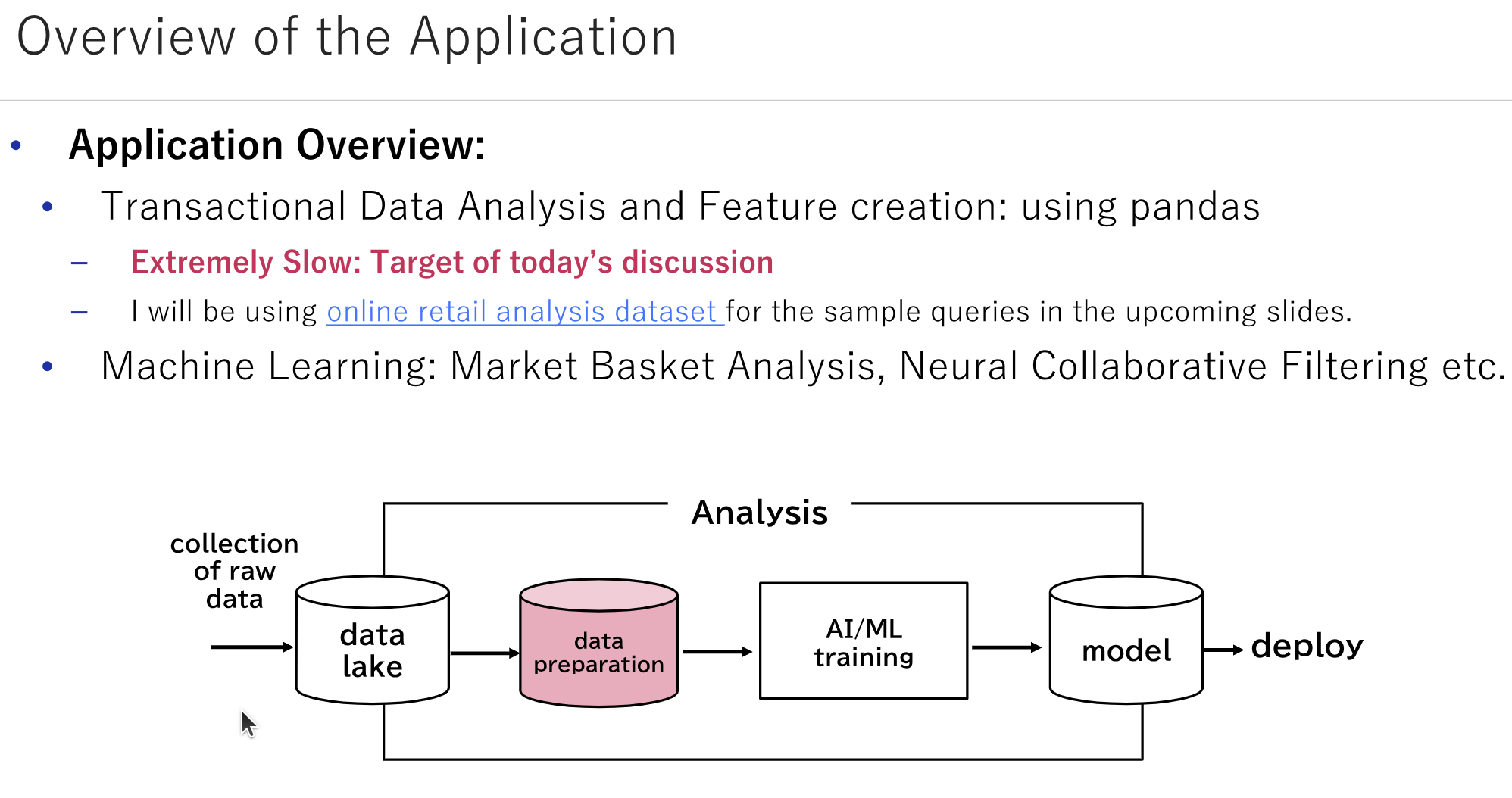
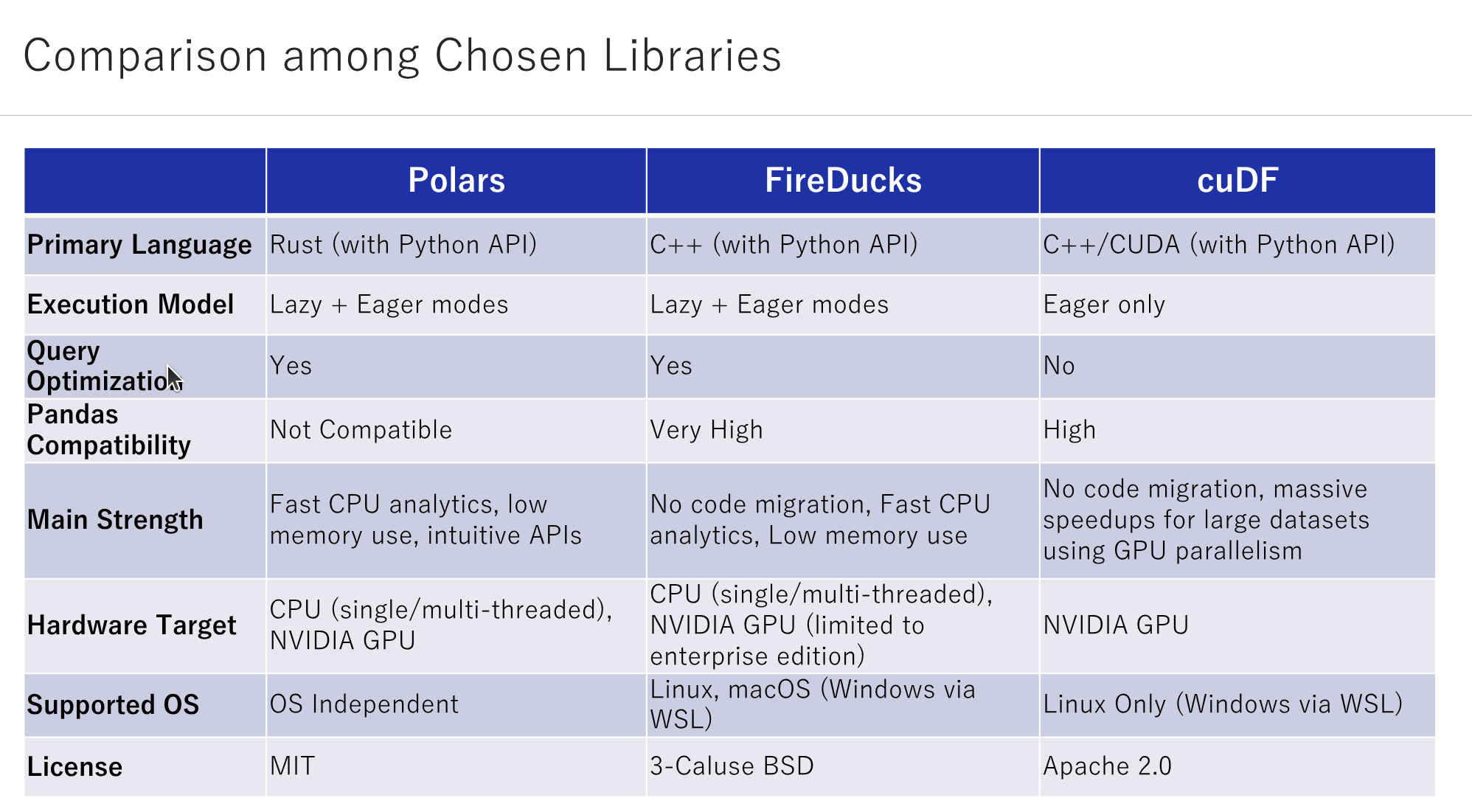
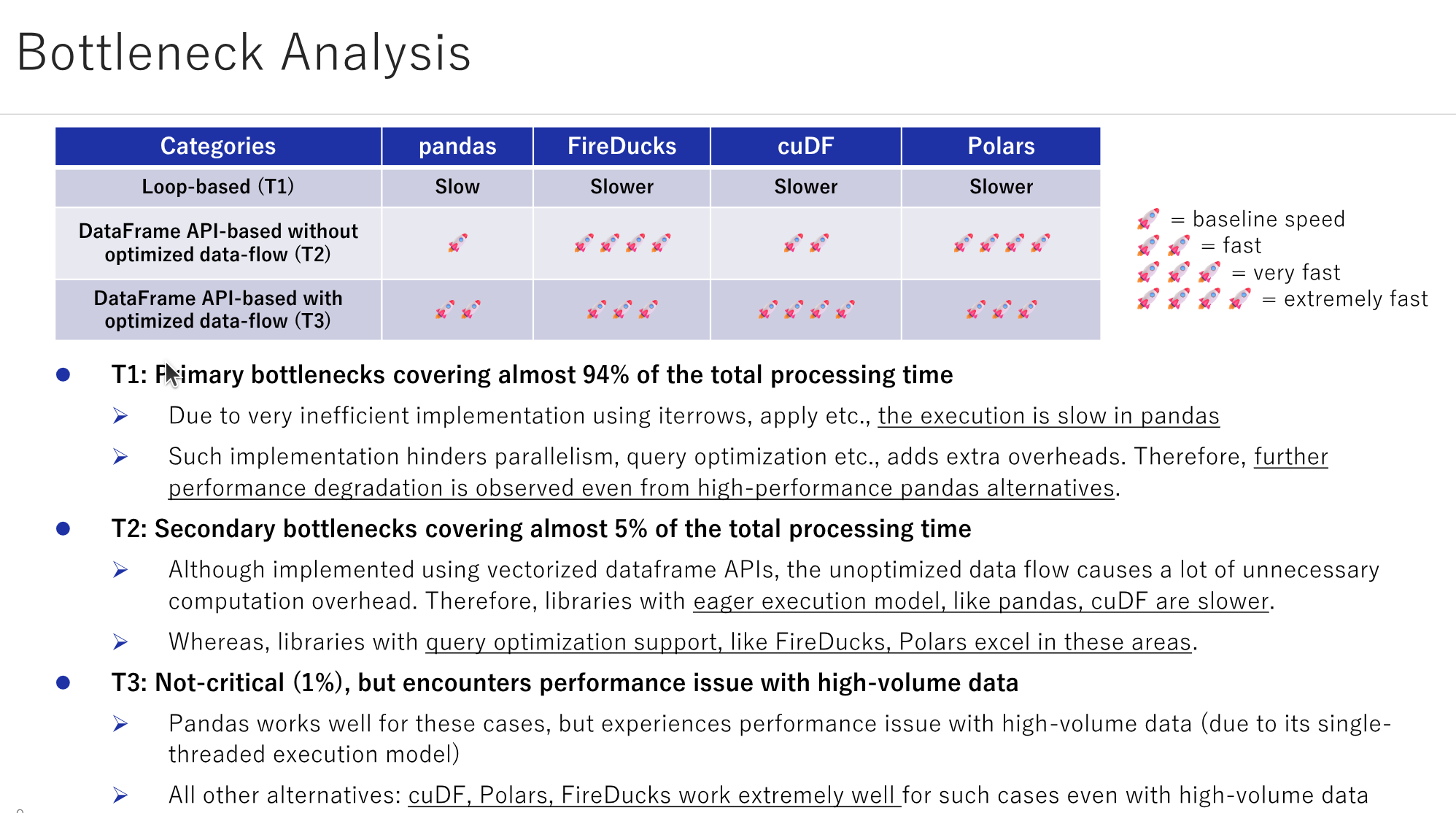
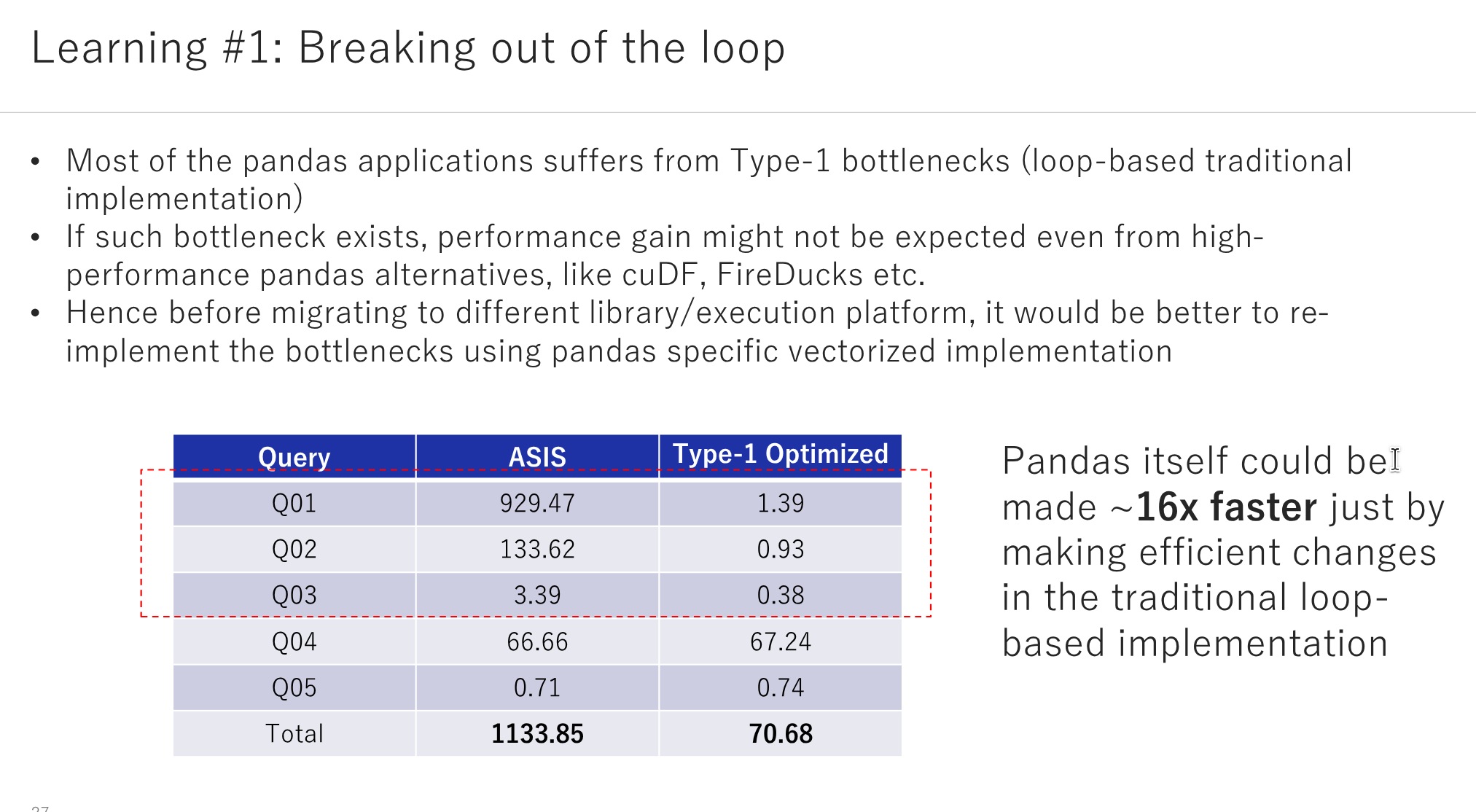
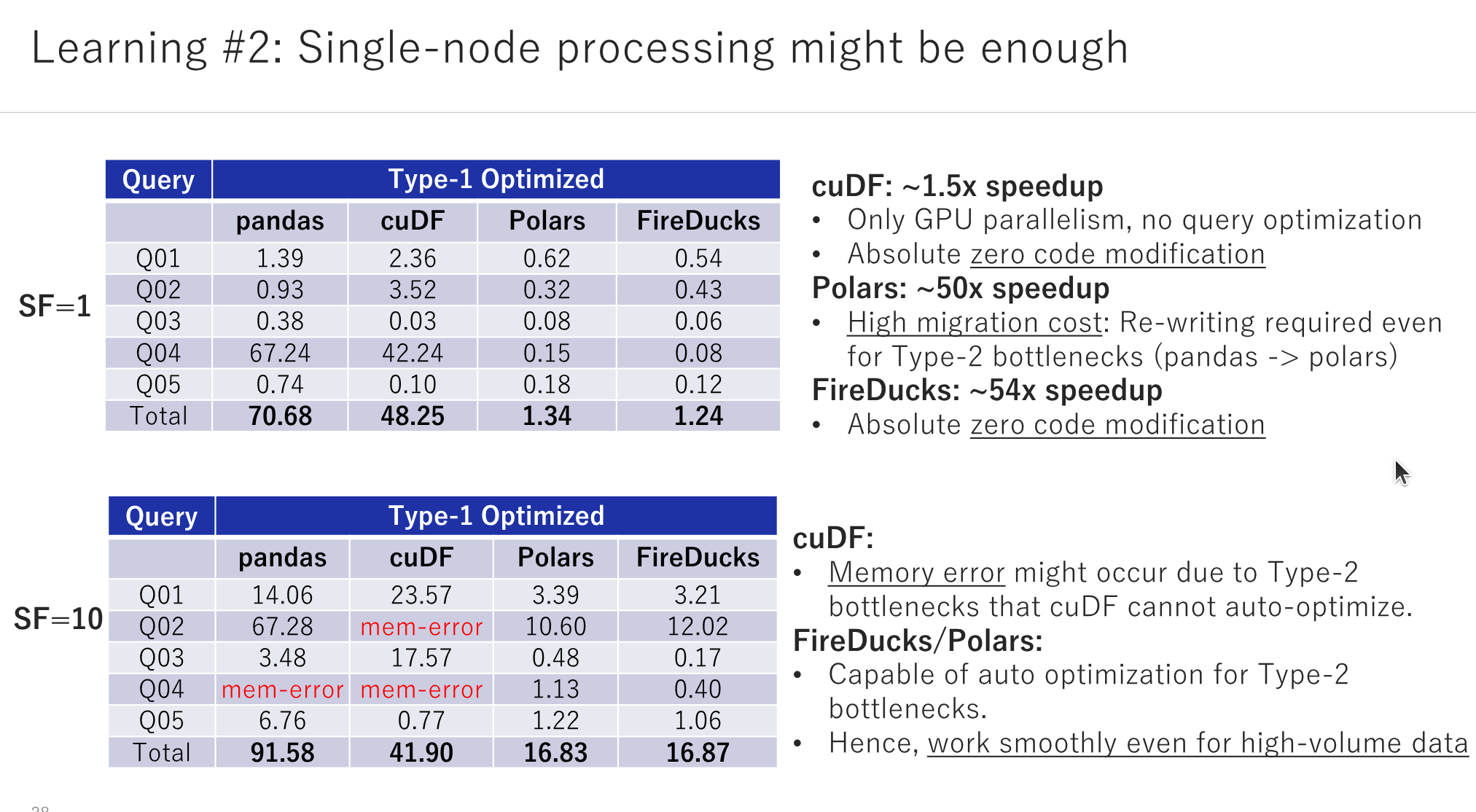
In general, a Data Scientist spends significant efforts in transforming the raw data into a more digestible format before training an AI model or creating visualisations. Traditional tools such as pandas have long been the linchpin in this process, offering powerful capabilities but not without limitations. With numerous possible ways to write the same thing in pandas, often a user ends up selecting the uneconomical, inefficient ones, leading to large computational costs with the growth in data size. We introduce a couple of frequently occurring intricate performance issues in pandas, and what we have learnt in solving the same using popular high-performance pandas alternatives: Polars, FireDucks and cuDF. The talk intends to highlight one of the best practices (breaking out of the loops) that one should follow while dealing with large-scale data analysis, while demonstrating the key advantages of the high-performance pandas alternatives based on different scenarios.
- How the choice and execution order of API calls in writing an data-related application impacts its performance.
- How to stop thinking the loop-based approach and design the algorithms using DataFrame APIs.
- How the internal query optimizers in libraries like Polars, FireDucks etc, can be useful to bring SQL-like optimizations at python-level.
- Whether to pay a large migration cost for optimizing an existing pandas-based application or to go smart with some minor modifications and save more operational cost.
- Basic Python and PyTorch
- Some familiarity with neural networks (e.g., feedforward, softmax)
- No need for prior experience in building models from scratch
Tools and Frameworks:
We will introduce you to certain modern frameworks in the workshop but the emphasis be on first principles and using vanilla Python and LLM calls to build AI-powered systems.
Sourav Saha
Sourav has 12+ years of professional experience at NEC Corporation in the diverse fields of High-Performance Computing, Distributed Programming, Compiler Design, and Data Science. Currently, his team at NEC R&D Lab, Japan, is researching various data processing-related algorithms. Blending the mixture of different niche technologies related to compiler framework, high-performance computing, and multi-threaded programming, they have developed a Python library named FireDucks with highly compatible pandas APIs for DataFrame-related operations. In his previous engagements, he has worked in research and development of performance-critical AI and Big Data solutions, optimization of several legacy applications related to weather prediction, earth-quake simulation, etc., written in C++ and Fortran. He has been speaking at several meetups and technical conferences related to HPC and Data Science.
Outline







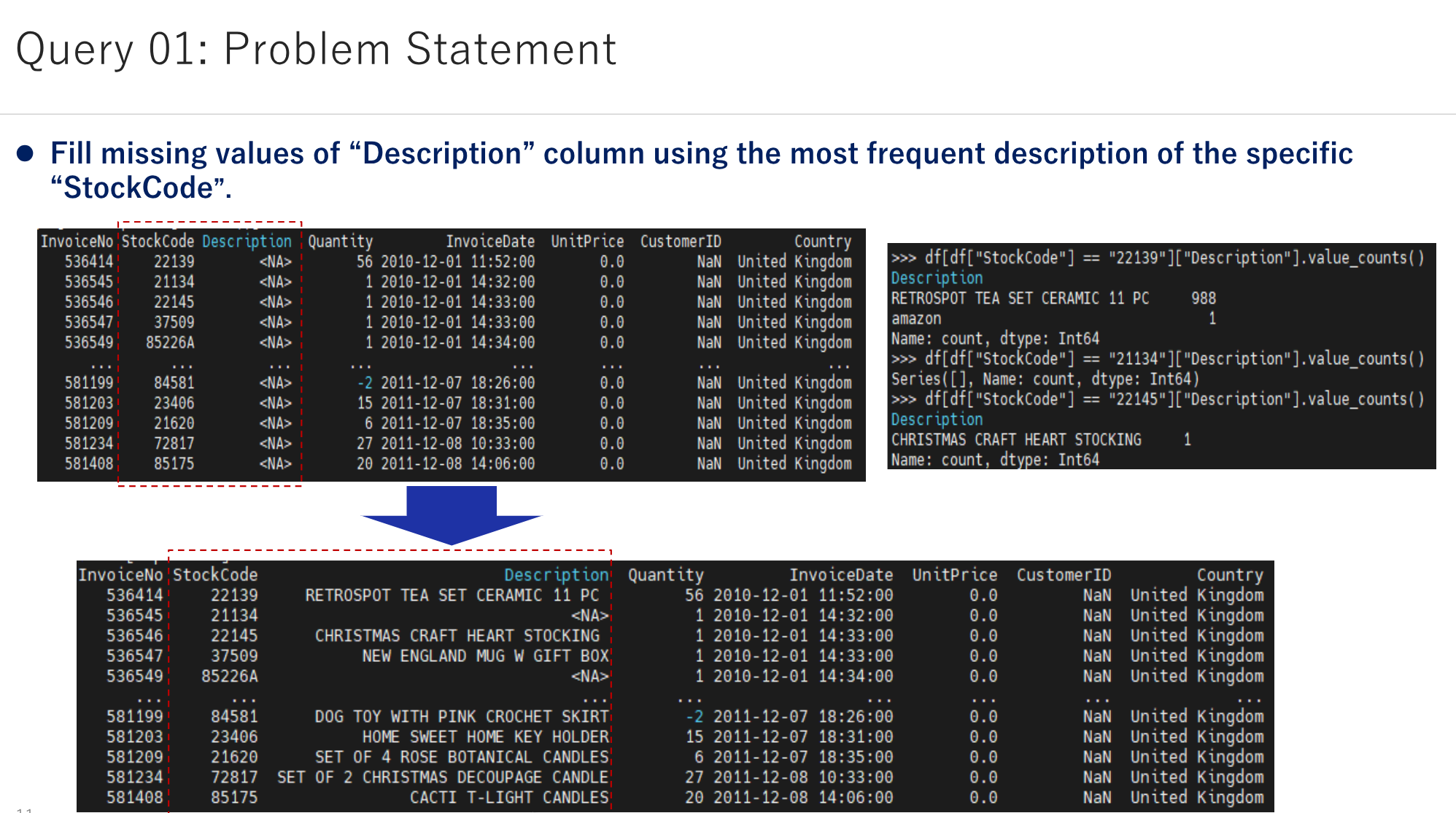
- Fill missing values of “Description” column using the most frequent description of the specific “StockCode”.


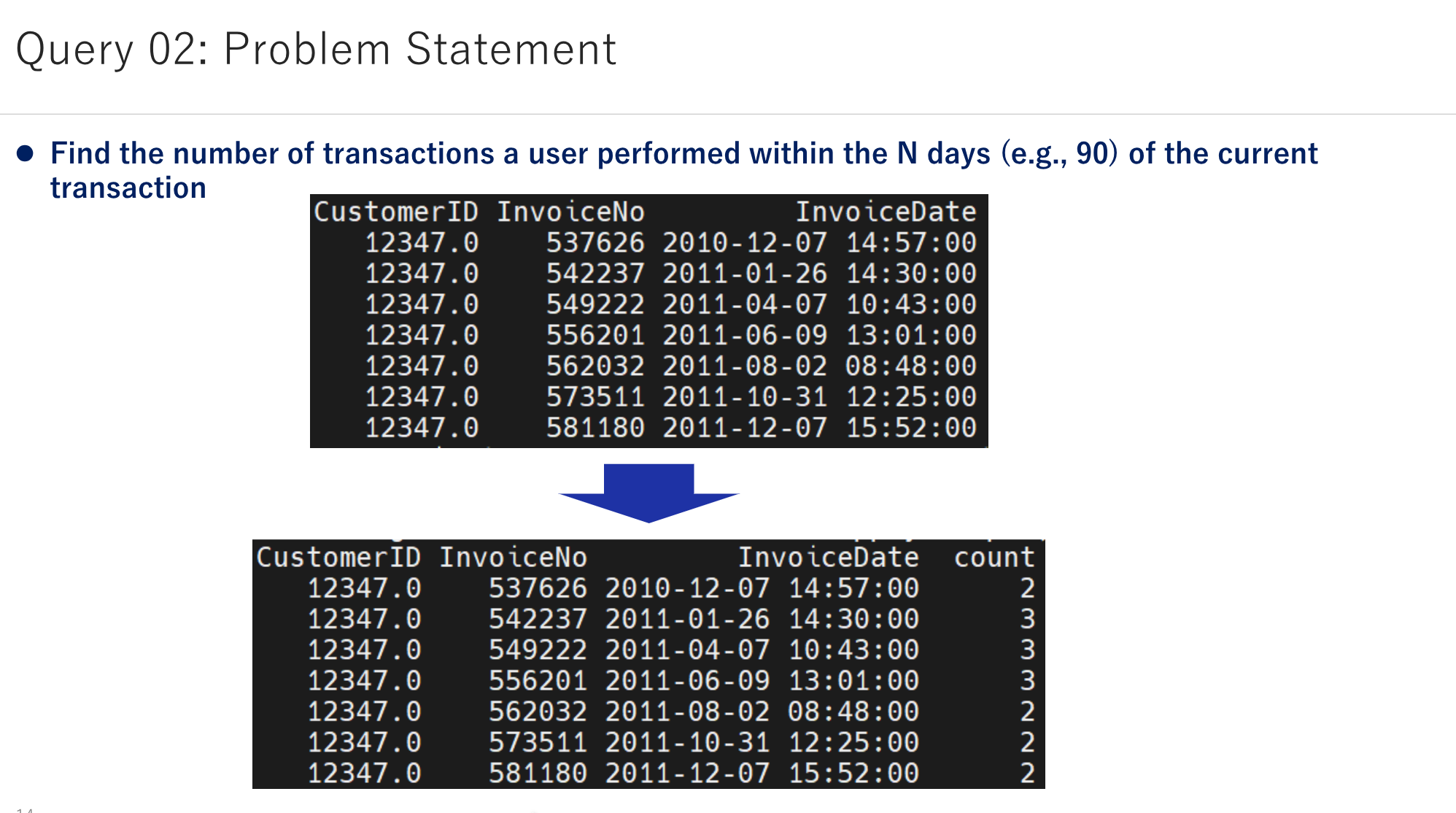
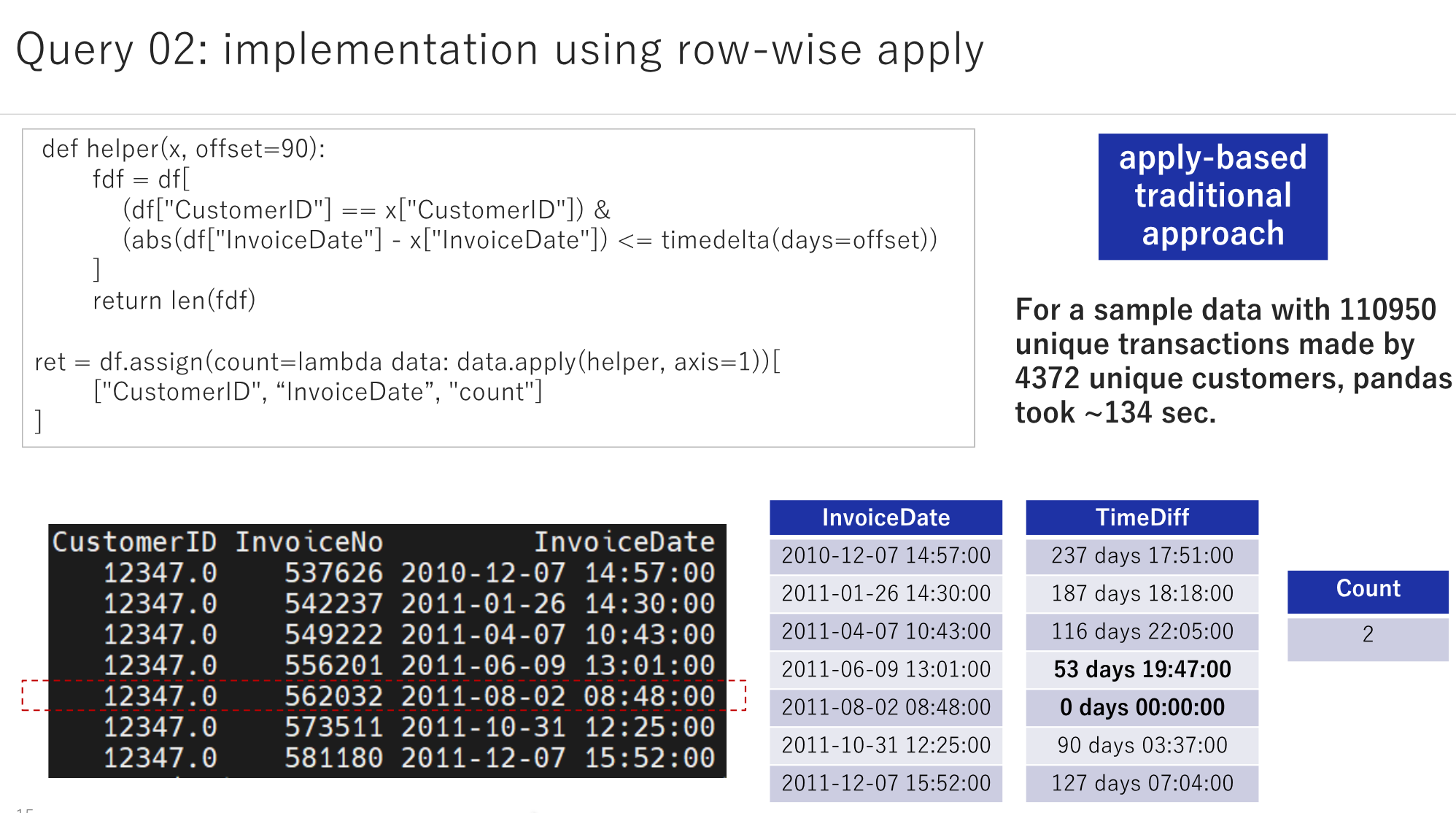
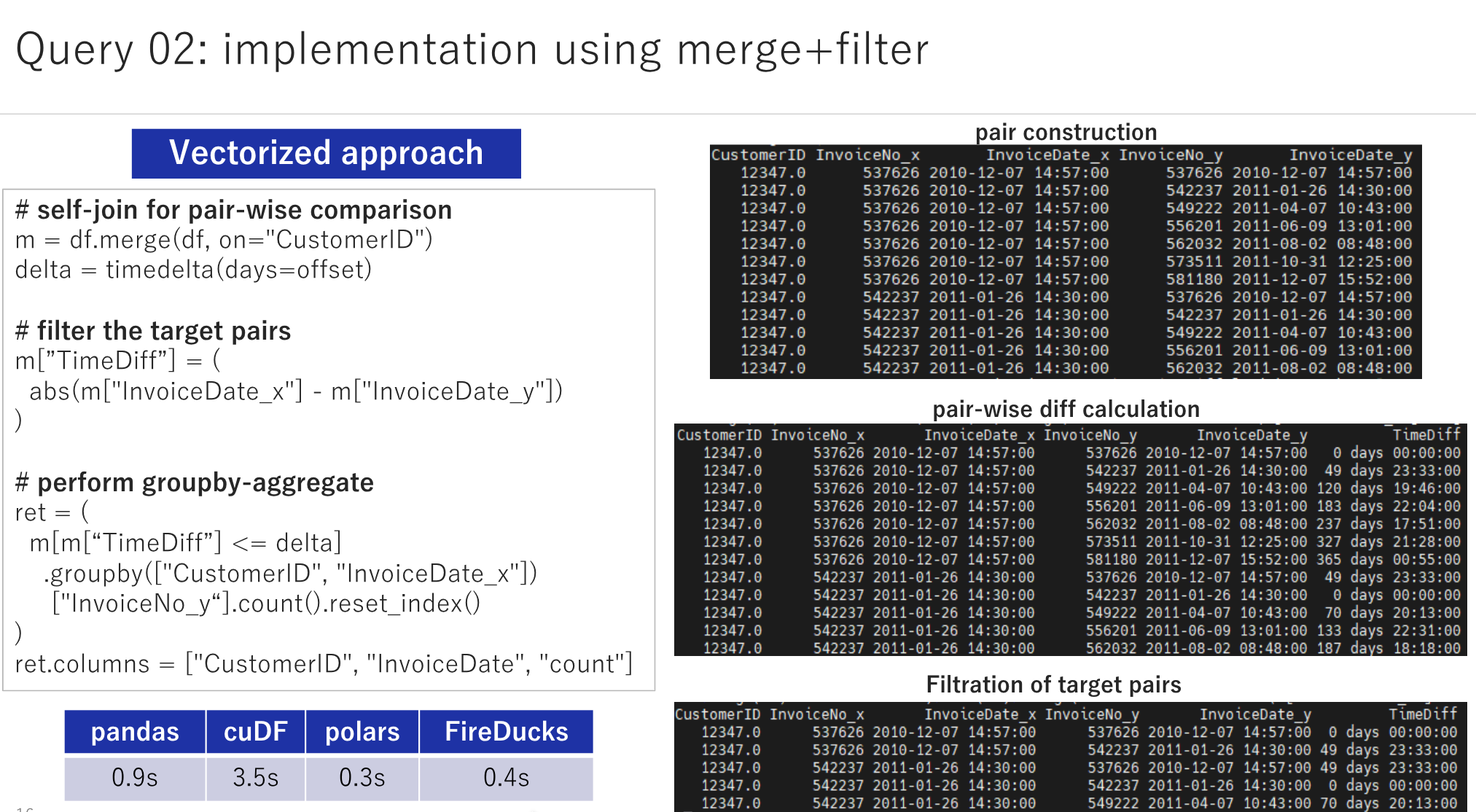
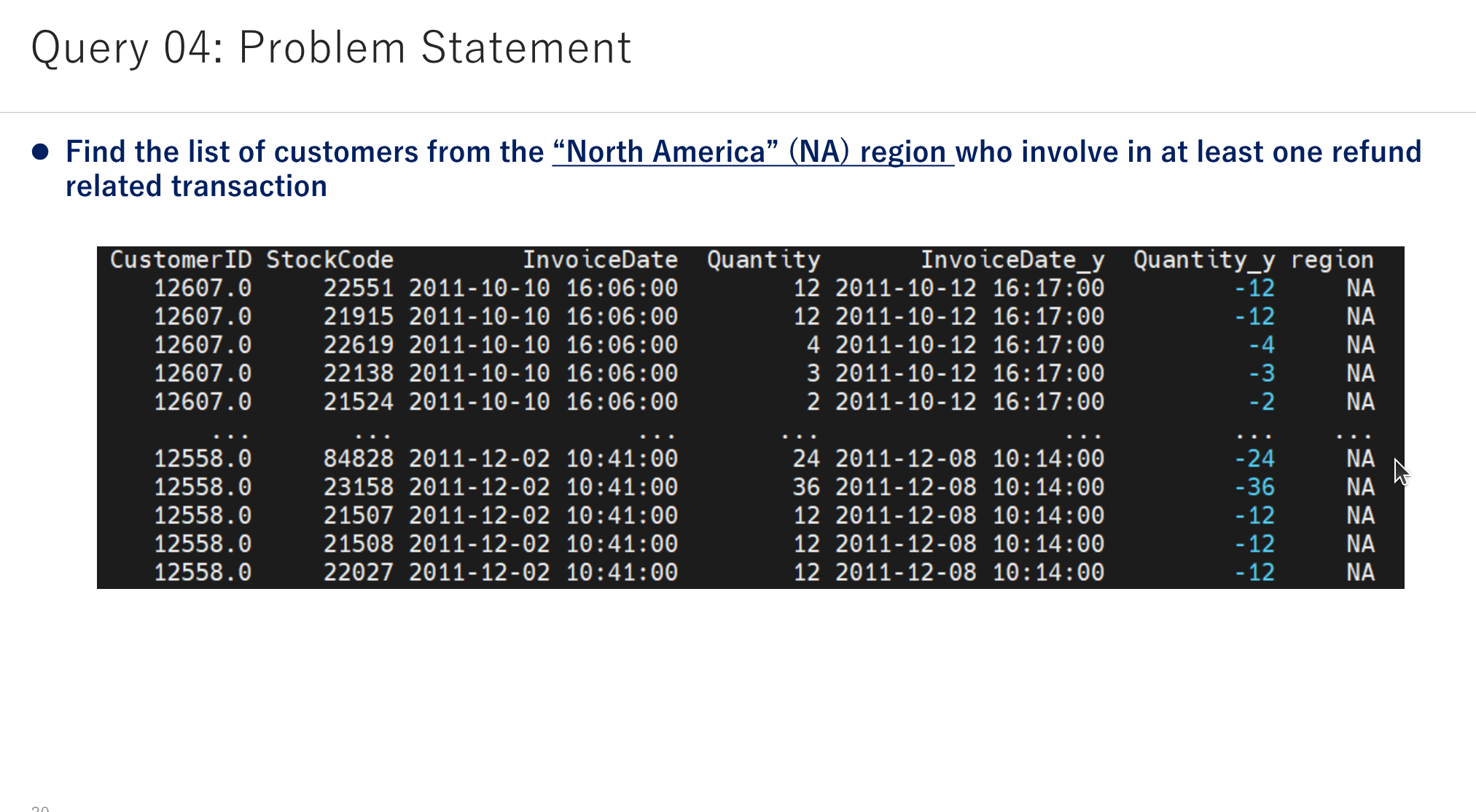
Find the number of transactions a user performed within the N days (e.g., 90) of the current transaction
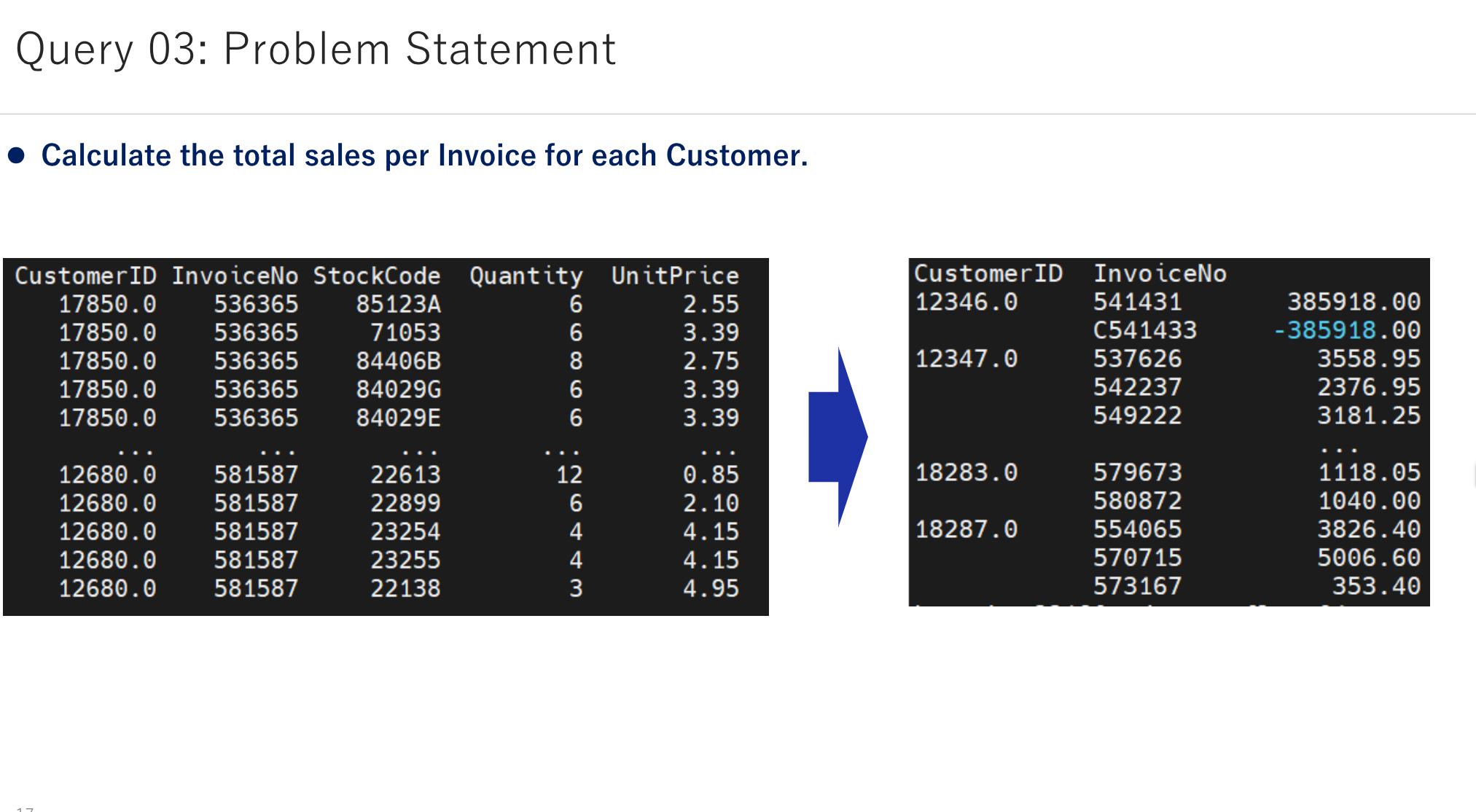
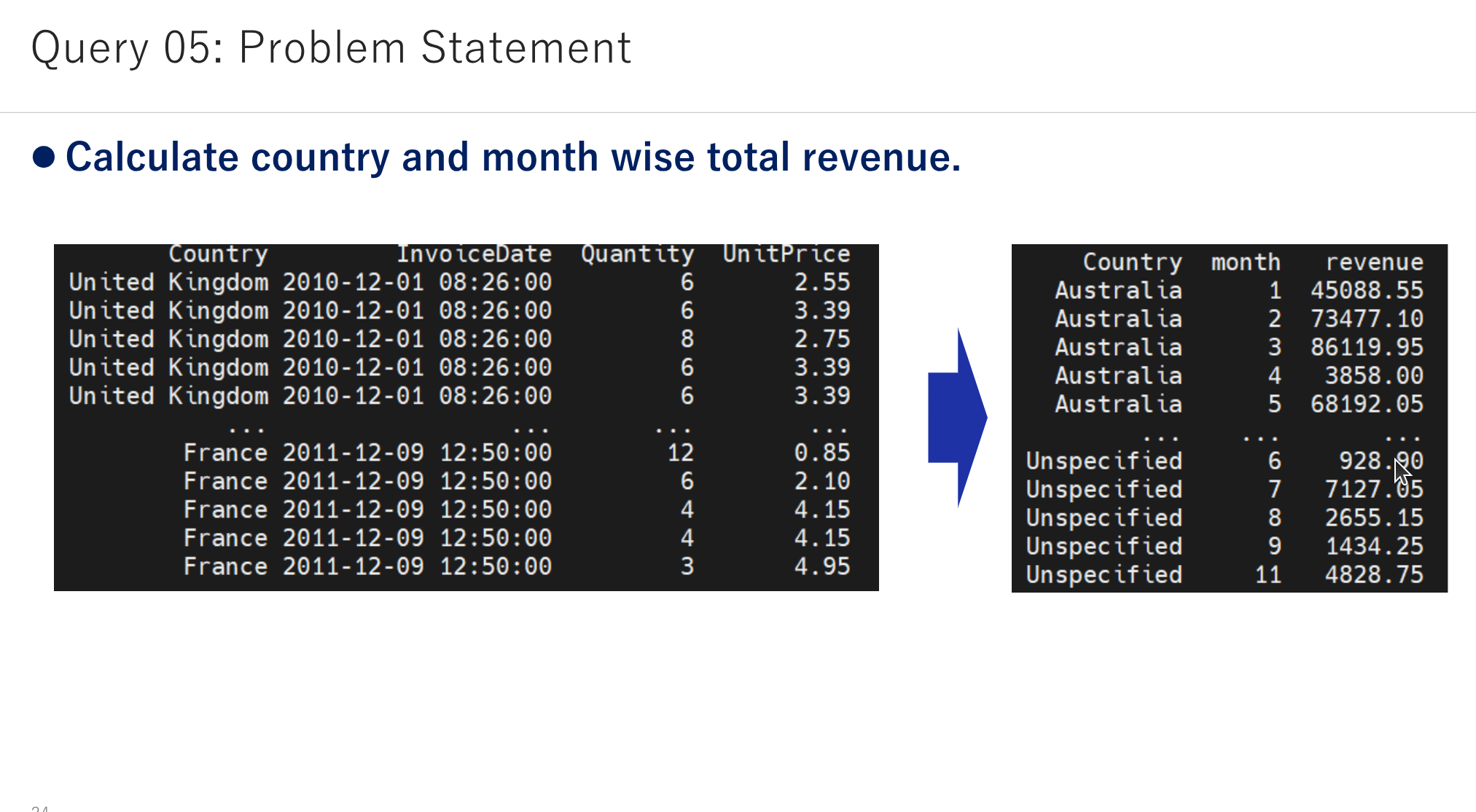
- Calculate total sales per Invoice for each Customer









https://github.com/qsourav/PyData-Global-2025
Citation
@online{bochman2025,
author = {Bochman, Oren},
title = {Lessons Learnt in Optimizing a Large-Scale Pandas Application
Using {Polars,} {FireDucks} and {cuDF:} {Go} {Smart} and {Save}
{More!}},
date = {2025-12-09},
url = {https://orenbochman.github.io/posts/2025/2025-12-09-pydata-optimizing-pandas-using-polars-cuDf-and-FireDucks/},
langid = {en}
}