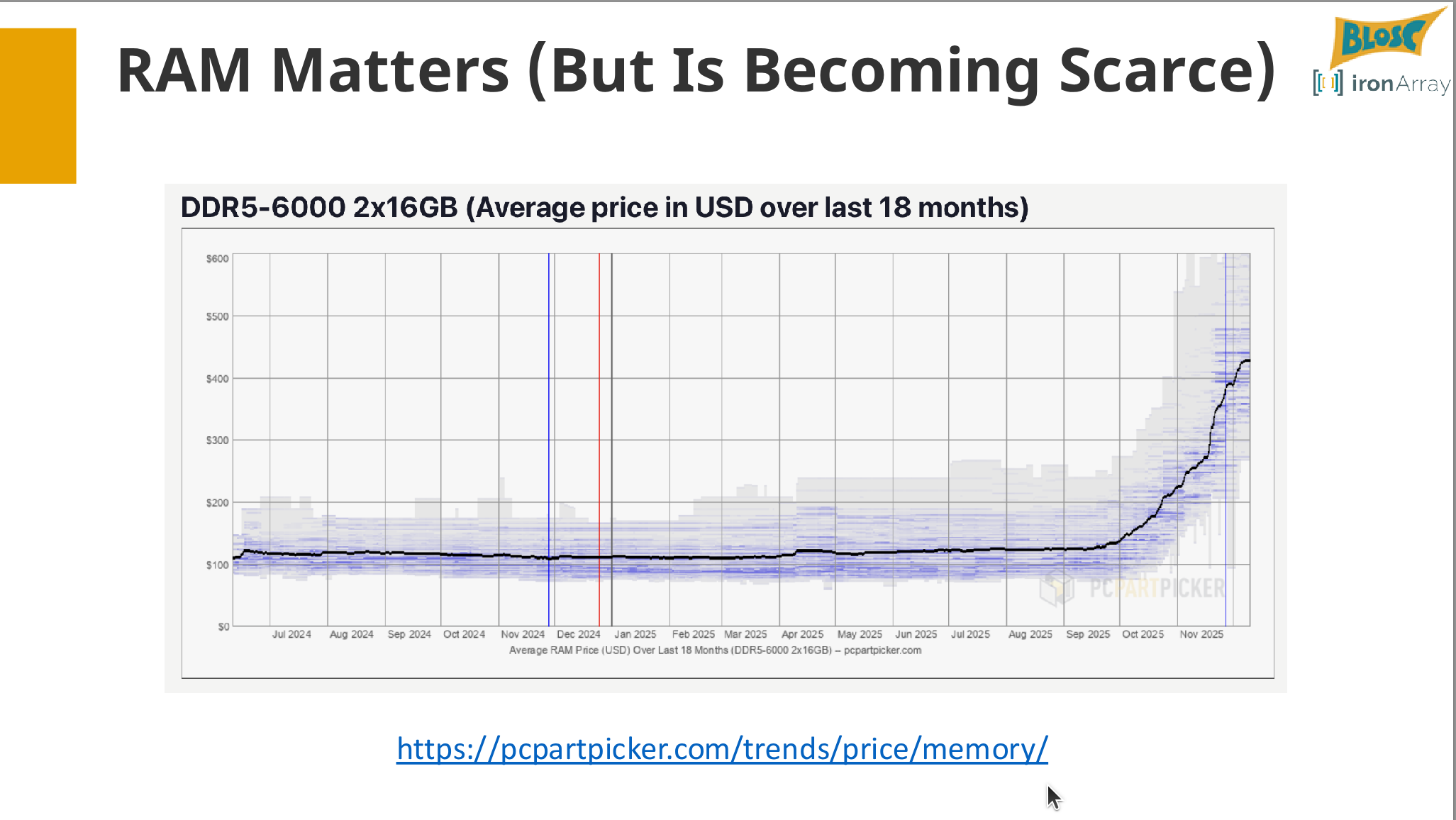
As datasets grow, I/O becomes a primary bottleneck, slowing down scientific computing and data analysis. This tutorial provides a hands-on introduction to Blosc2, a powerful meta-compressor designed to turn I/O-bound workflows into CPU-bound ones. We will move beyond basic compression and explore how to structure data for high-performance computation.
Participants will learn to use the python-blosc2 library to compress and decompress data with various codecs and filters, optimizing for speed and ratio.
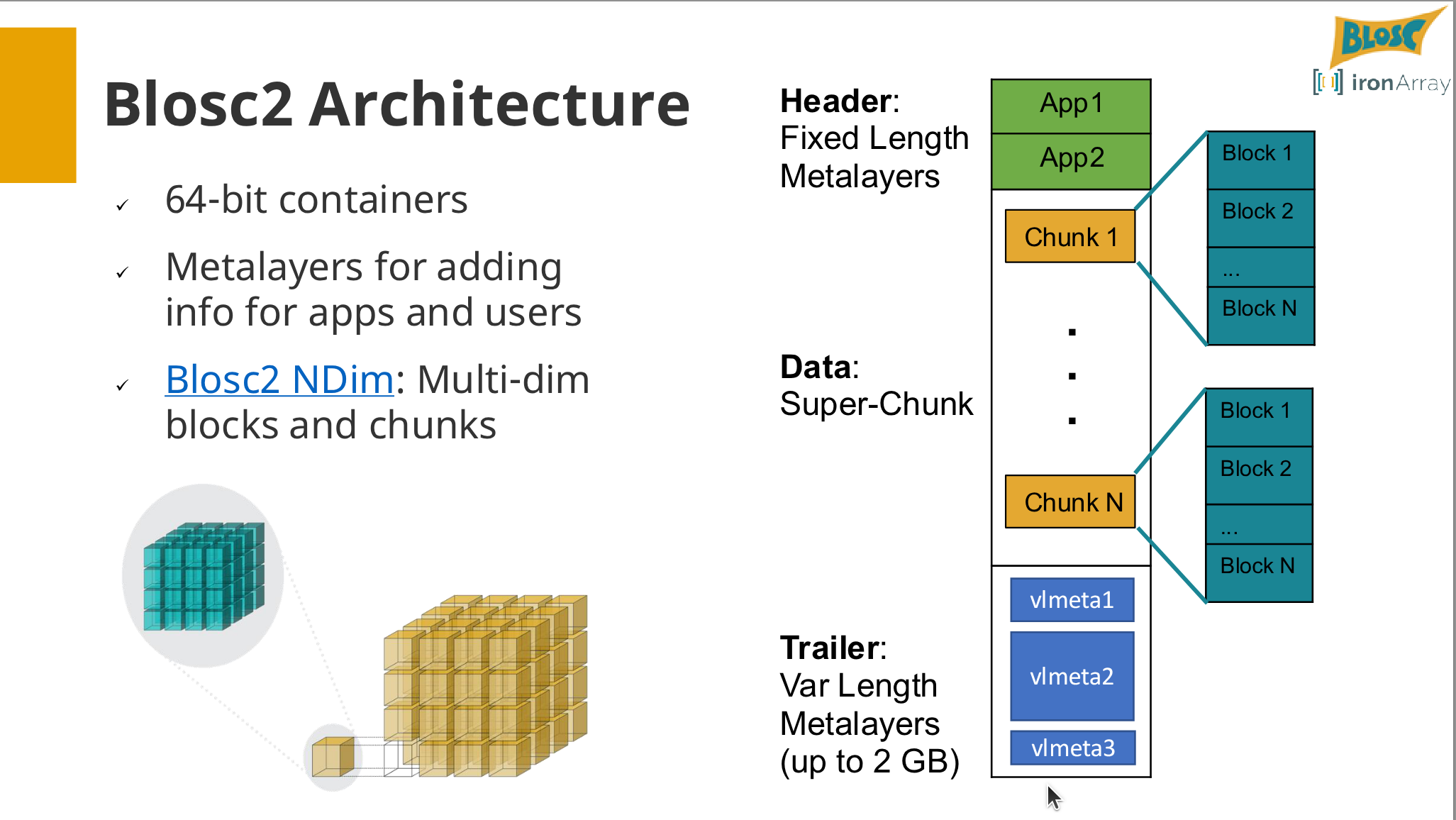
The core of the tutorial will focus on the Blosc2 NDArray object, a chunked, N-dimensional array that lives on disk or in memory.
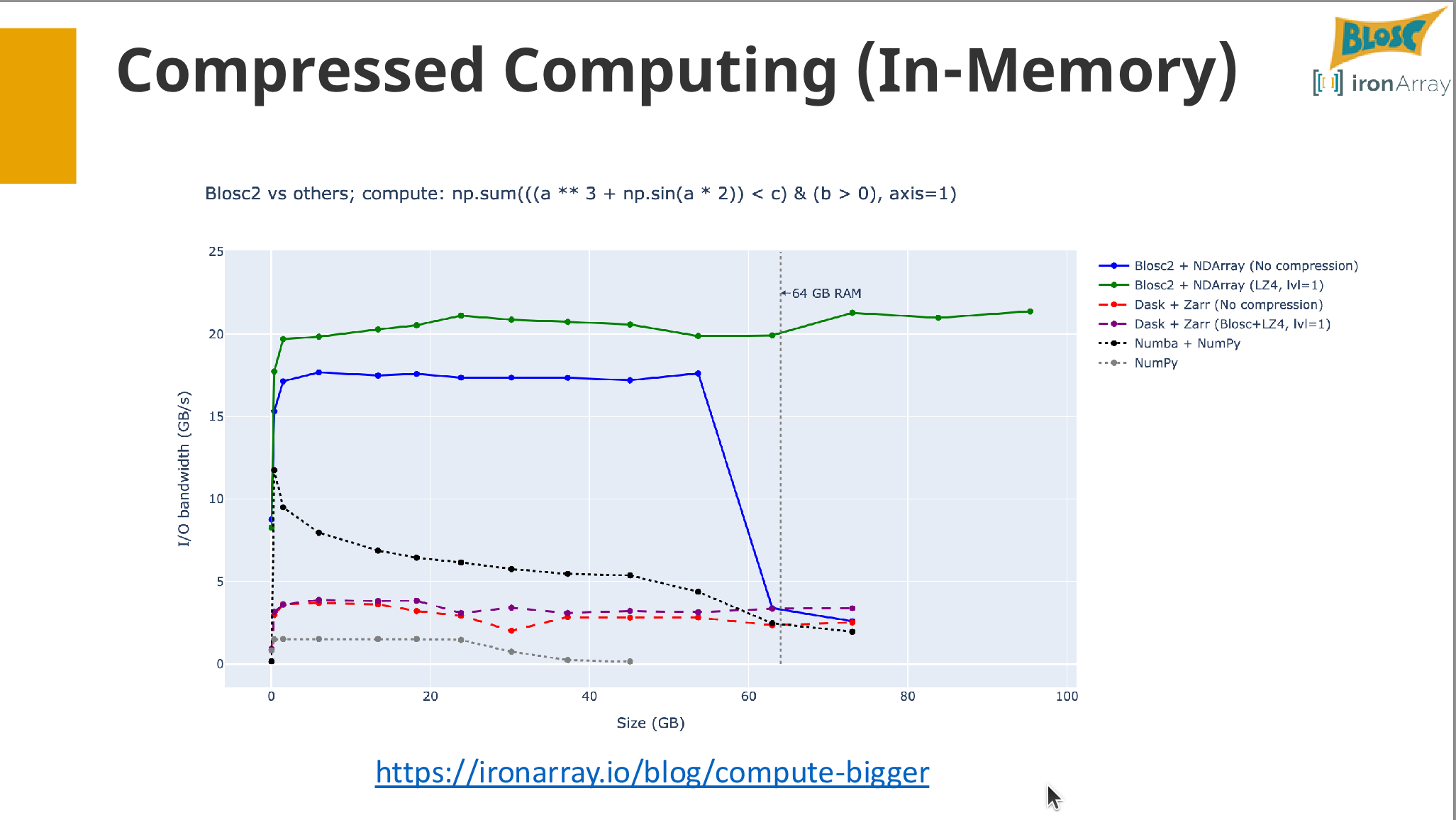
Through a series of interactive exercises, you will learn how to perform out-of-core mathematical operations and analytics directly on compressed arrays, effectively handling datasets larger than available RAM.
We will also cover practical topics like data storage backends, two-level partitioning for faster data slicing, and how to integrate Blosc2 into existing NumPy-based workflows. You will leave this session with the practical skills needed to significantly accelerate your data pipelines and manage massive datasets with ease.
- Understand the core concepts behind the Blosc2 meta-compressor.
- Compress and decompress NumPy arrays, tuning parameters for optimal performance.
- Create, manipulate, and slice Blosc2 NDArray objects for out-of-core processing.
- Perform efficient mathematical computations directly on compressed data.
- Store and retrieve compressed datasets using different storage backends.
- Integrate Blosc2 into their existing data analysis workflows to mitigate I/O bottlenecks.
This tutorial is for data scientists, engineers, and researchers who work with large numerical datasets in Python.
Prerequisites: Attendees should have intermediate Python programming skills and be comfortable with the basics of NumPy arrays. No prior experience with Blosc2 is necessary.
Setup: Participants will need a laptop and can follow along using a provided cloud-based environment (e.g., Binder) or a local installation of Python, Jupyter, and the python-blosc2 library.
Tools and Frameworks:
We will introduce you to certain modern frameworks in the workshop but the emphasis be on first principles and using vanilla Python and LLM calls to build AI-powered systems.
Francesc Alted
I am a curious person who studied Physics (BSc, MSc) and Applied Maths (MSc). I spent over a year at CERN for my MSc in High Energy Physics. However, I found maths and computer sciences equally fascinating, so I left academia to pursue these fields. Over the years, I developed a passion for handling large datasets and using compression to enable their analysis on commodity hardware accessible to everyone.
I am the CEO of ironArray SLU and also leading the Blosc Development Team, and currently interested in determining, ahead of time, which combinations of codecs and filters can provide a personalized compression experience. I am also very excited in providing a way for sharing Blosc2 datasets in the network in an easy and effective way via Caterva2, and Cat2Cloud, a software as a service for handling and computing with datasets directly in the cloud.
As an Open Source believer, I started the PyTables project more than 20 years ago. After 25 years in this business, I started several other useful open source projects like Blosc2, Caterva2 and Btune; those efforts won me two prizes that mean a lot to me:
2023: NumFOCUS Project Sustainability Award 2017: Google’s Open Source Peer Bonus You can know more on what I am working on by reading my latest blogs.
Luke Shaw
- Degree in Physics, Princeton University, 2019
- Masters in Applied Mathematics, University of Edinburgh, 2020
- PhD in Applied Mathematics, Universitat Jaume I 2024
- Working at ironArray as engineer and product owner since 2025.
Outline
- Introduction & Setup (10 mins)
- The I/O Bottleneck Problem.
- Core Concepts: What are meta-compressors, chunks, and blocks?
- Tutorial environment setup (Jupyter notebooks).
- Part 1: Compression Fundamentals (20 mins)
- Hands-on: Using blosc2.compress() and blosc2.decompress().
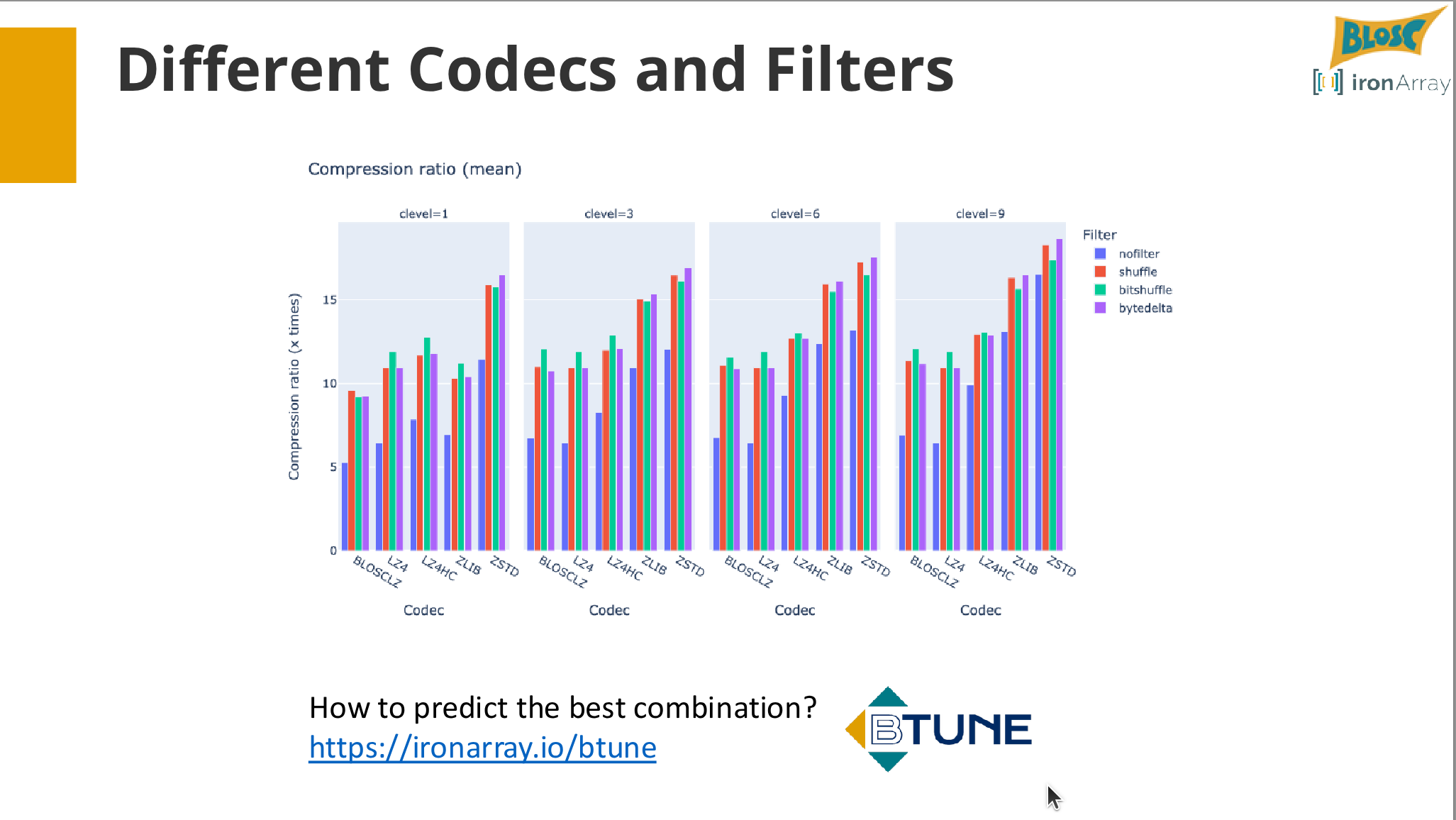
- Exploring codecs (lz4, zstd), compression levels, and filters (shuffle, bitshuffle).
- Exercise: Compressing a sample dataset and analyzing the trade-offs between speed and ratio.
- Part 2: The NDArray - Computing on Compressed Data (35 mins)
- Hands-on: Creating NDArray objects from scratch and from NumPy arrays.
- Storing arrays on-disk vs. in-memory.
- Exercise: Slicing and accessing data from an on-disk NDArray.
- Performing mathematical operations (arr * 2 + 1) and reductions (arr.sum()) on compressed data.
- Exercise: Analyzing a dataset larger than RAM.
- Part 3: Advanced Features & Integration (20 mins)
- Hands-on: Using two-level partitioning (meta-chunks) for faster slicing.
- Brief overview of Caterva2 for sharing compressed data via an API.
- Recap and Q&A.





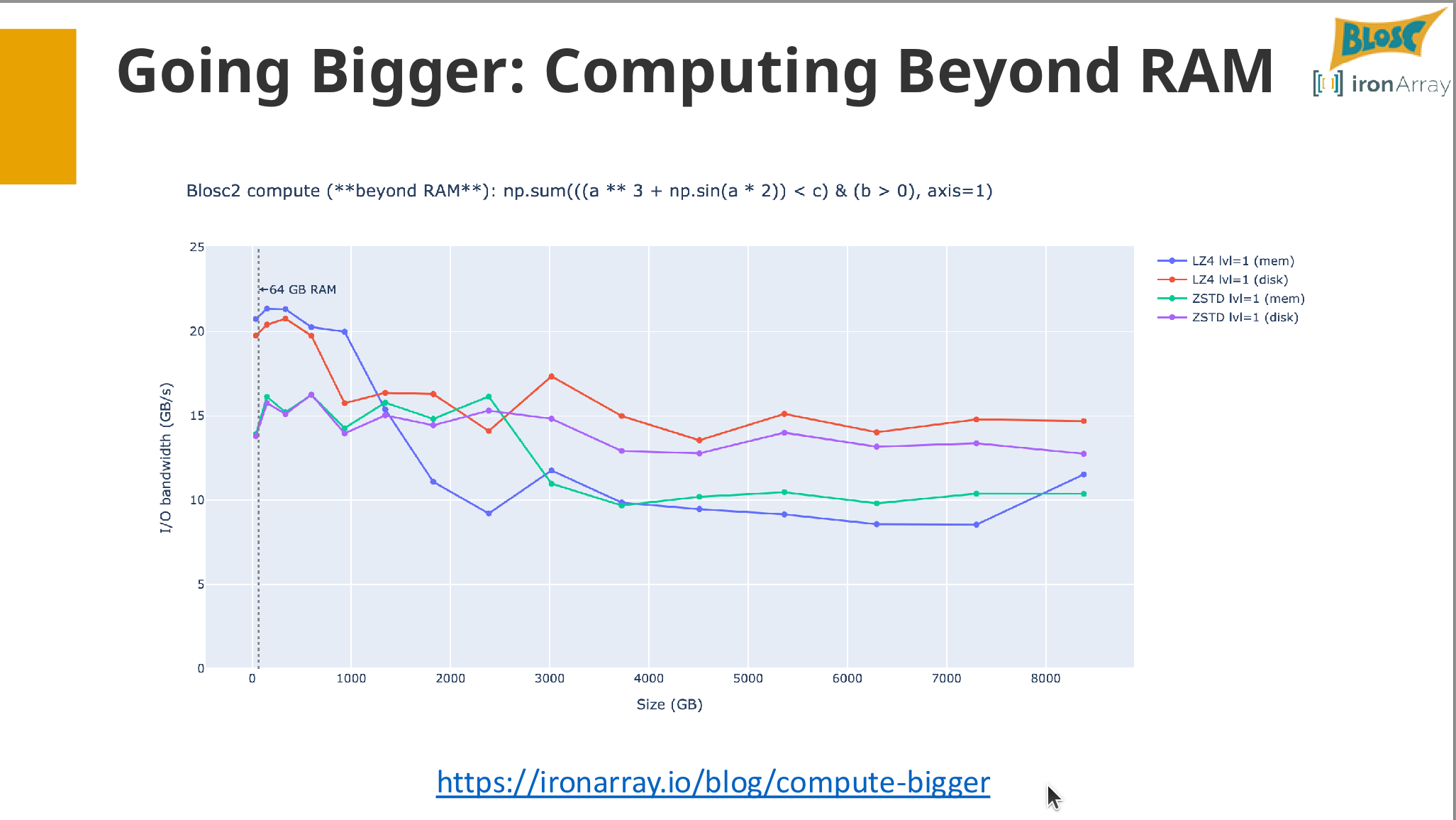

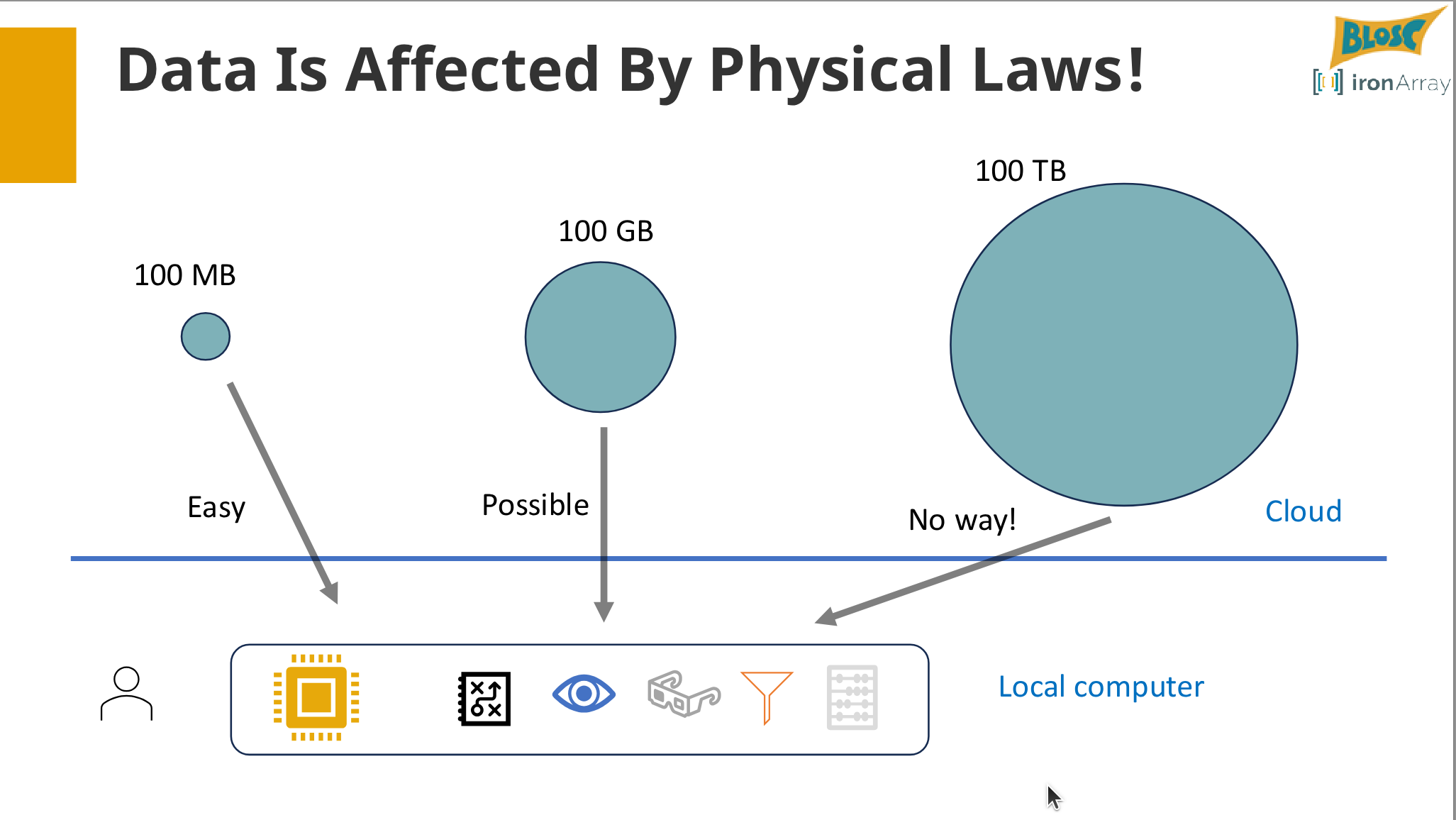
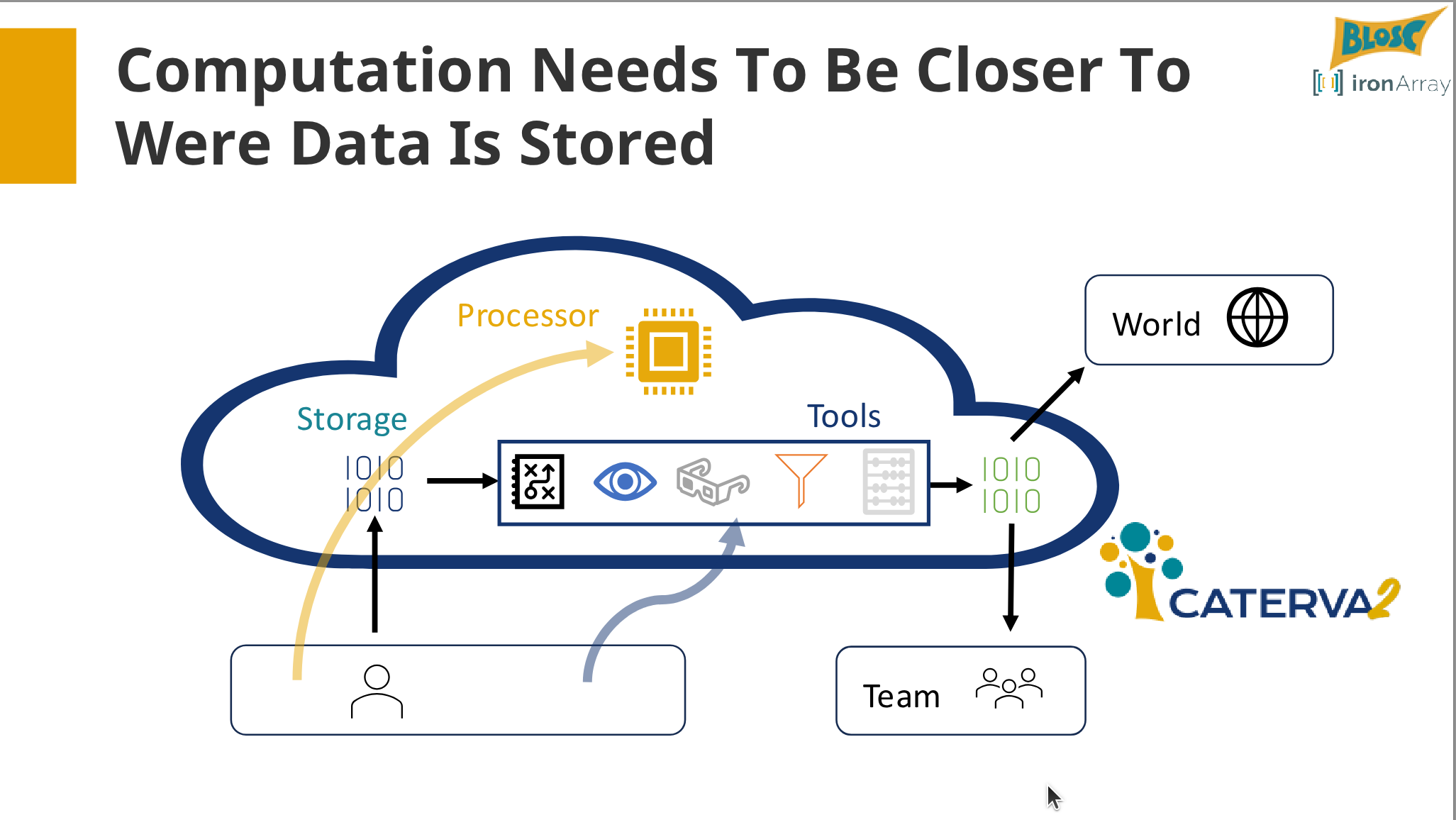
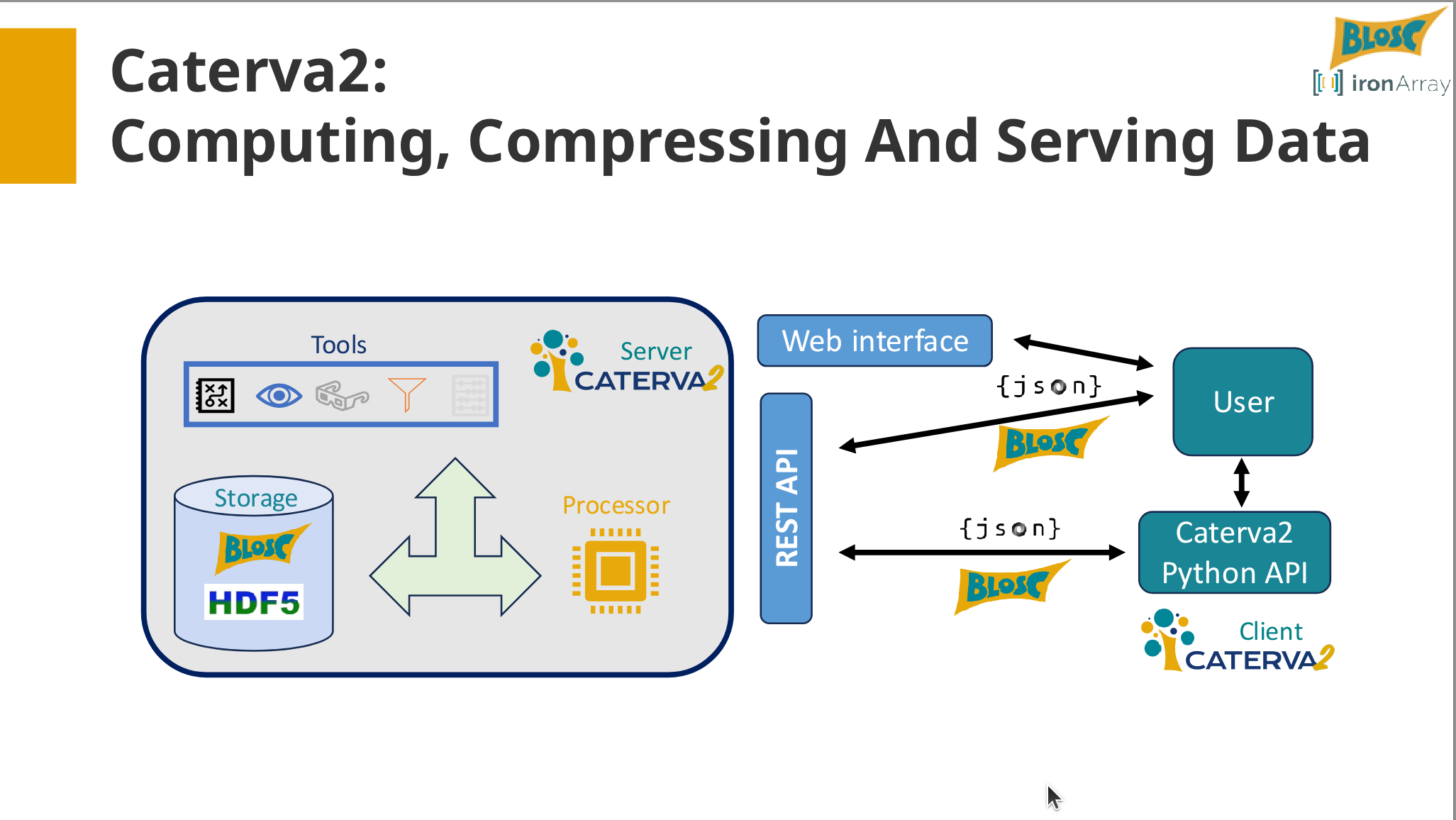



Reflections:
- can we add code snippets from the tutorial here?
- why blosc_2 and not say zarr or other solutions?
Citation
@online{bochman2025,
author = {Bochman, Oren},
title = {Hands-on with {Blosc2:} {Accelerating} {Your} {Python} {Data}
{Workflows}},
date = {2025-12-10},
url = {https://orenbochman.github.io/posts/2025/2025-12-10-pydata-blosc2/},
langid = {en}
}