![]()
Discover how Insee (French National Statistics Institute) transitioned from fastText to a PyTorch-based model for text classification by developing and open-sourcing the torchTextClassifiers python package. This presentation will cover the creation, deployment, and practical applications of torchTextClassifiers in modernizing automatic coding systems, benefiting Insee and other European National Statistical Institutes (NSIs).
- The rationale for moving from fastText to a PyTorch-based model in production
- Packaging a PyTorch-based model architecture and open-source collaboration
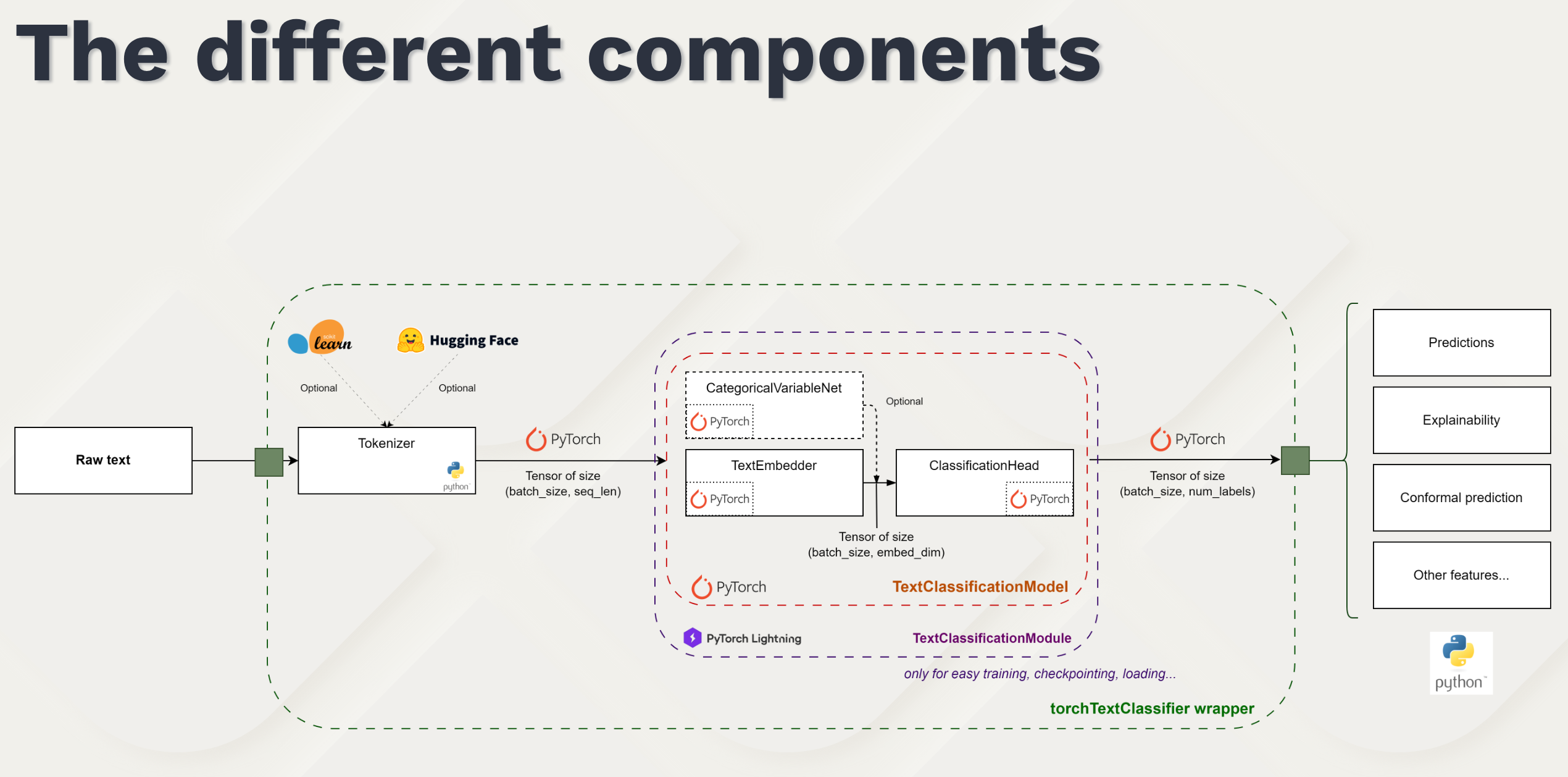
- Key features and architecture of torchTextClassifiers
- Deployment strategies within a public administration (MLOps, cloud native tools, security)
- Lessons learned and best practices for similar transitions
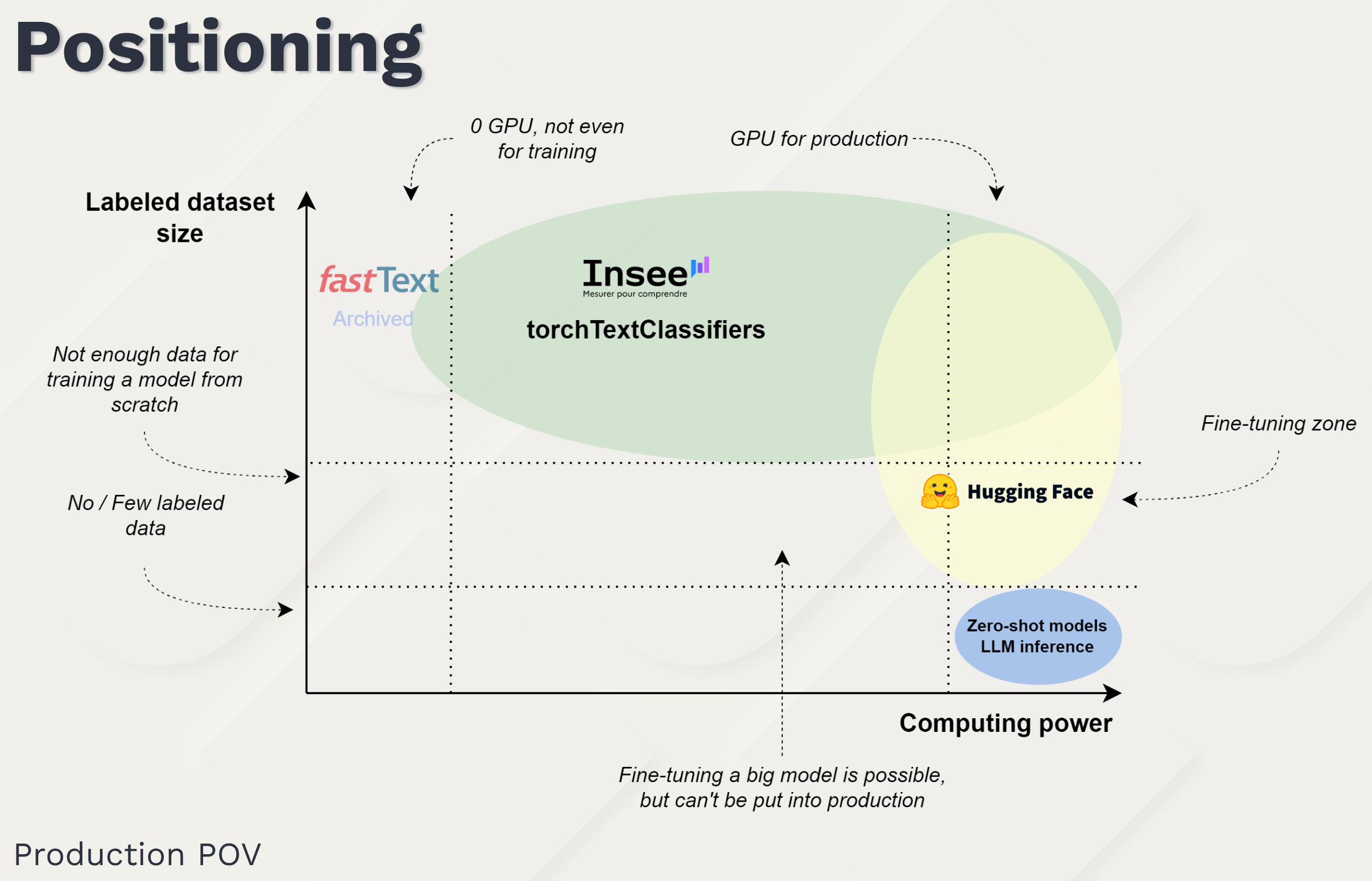
Insee, France’s National Institute of Statistics and Economic Studies, has long relied on fastText for automatic coding tasks. Recognizing the need to modernize and future-proof this critical functionality, we developed torchTextClassifiers — an open-source Python package that enables easy training and deployment of a PyTorch-based model for text classification, paving the way for further innovation in this domain.
This session will delve into the motivations behind replacing the archived fastText package, the design and implementation of torchTextClassifiers , and its integration into Insee’s production environment. We’ll discuss the challenges faced during this transition, including model compatibility, performance optimization, and user adoption.
Cédric Couralet
Cédric Couralet, Data Scientist at Insee, is an open-source enthusiast, with expertise in software architecture and secure system design.
Meilame Tayebjee
As a Data Scientist at the Innovation Lab of the French National Institute of Statistics and Economic Studies (Insee), I focus on the deployment of machine learning models, the enhancement of MLOps best practices, and the development of torchTextClassifiers, a PyTorch package designed to streamline the training of deep learning models for text classification.
I am also pursuing a PhD in Computer Science jointly at CREST and Inria, where my research centers on foundational Transformer-based models for the analysis of healthcare pathways.
Outline:
- Introduction to hallucinations in LLMs
- Common causes behind hallucinated outputs
- Impact on production applications
- Techniques for detecting and evaluating hallucinations
- Strategies to reduce hallucinations
- Best practices for building trustworthy AI products
- Key takeaways

This is a classifier for documents in terms of economic activity (NAF codes) based on their textual description.


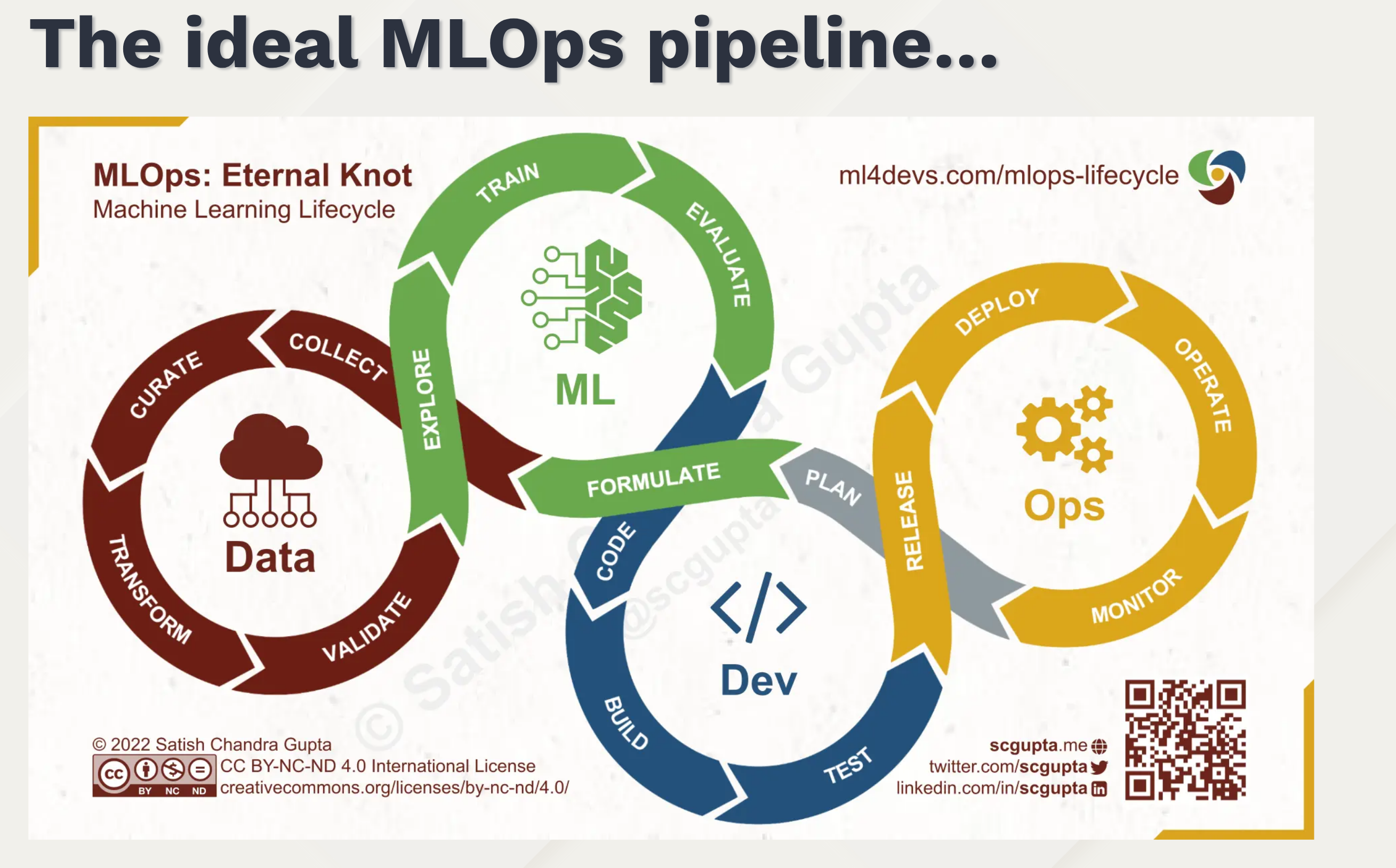
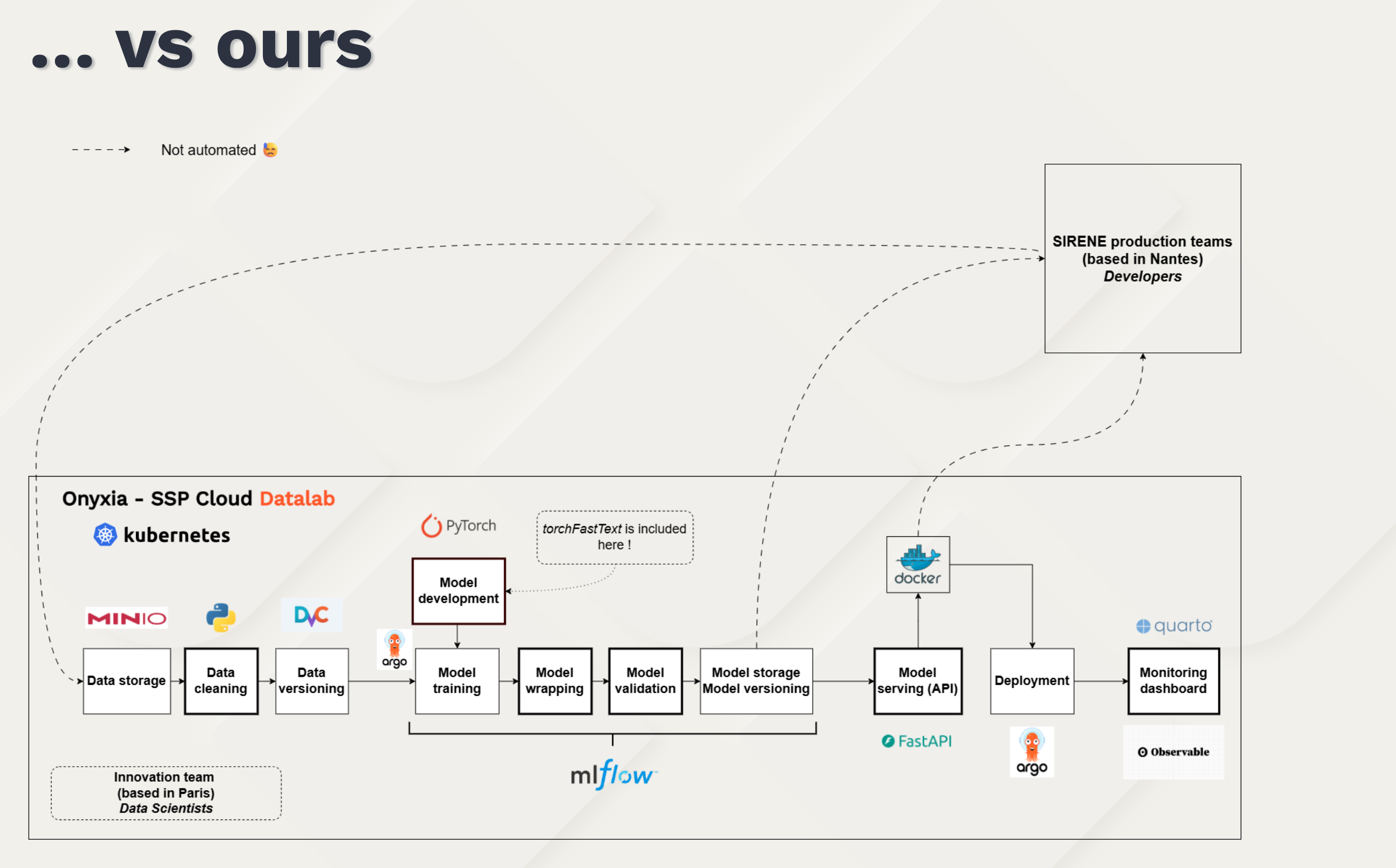

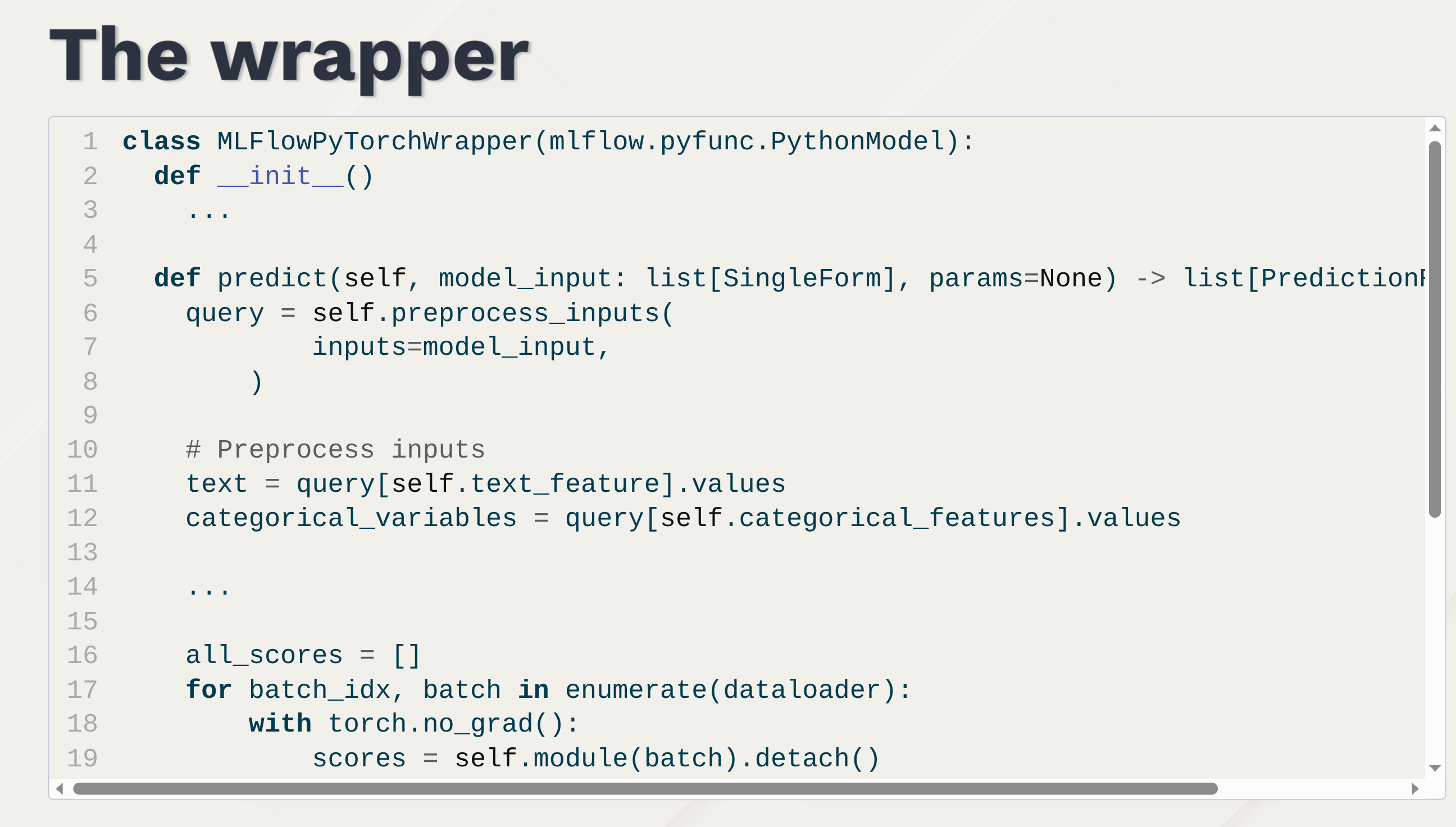

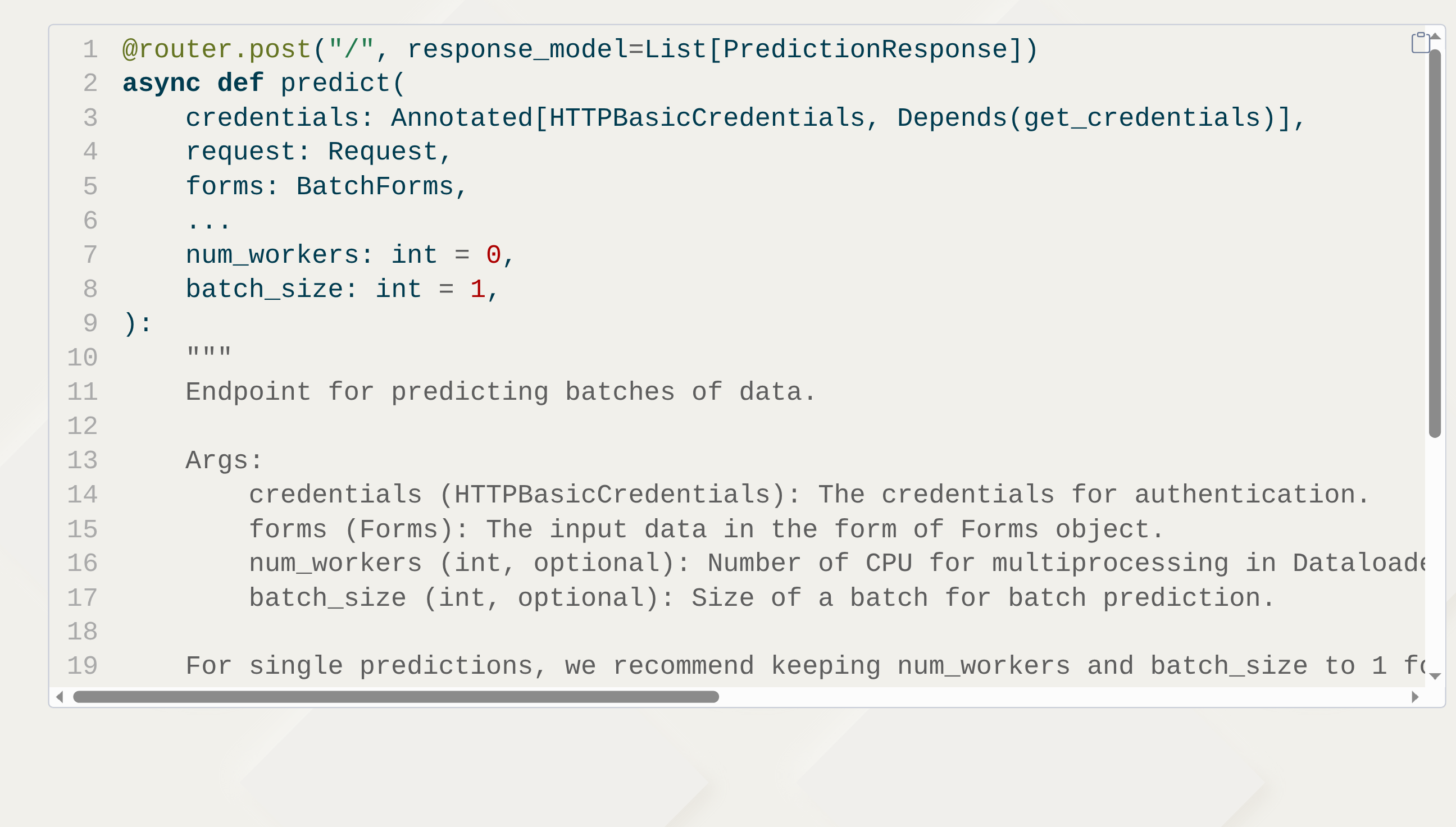
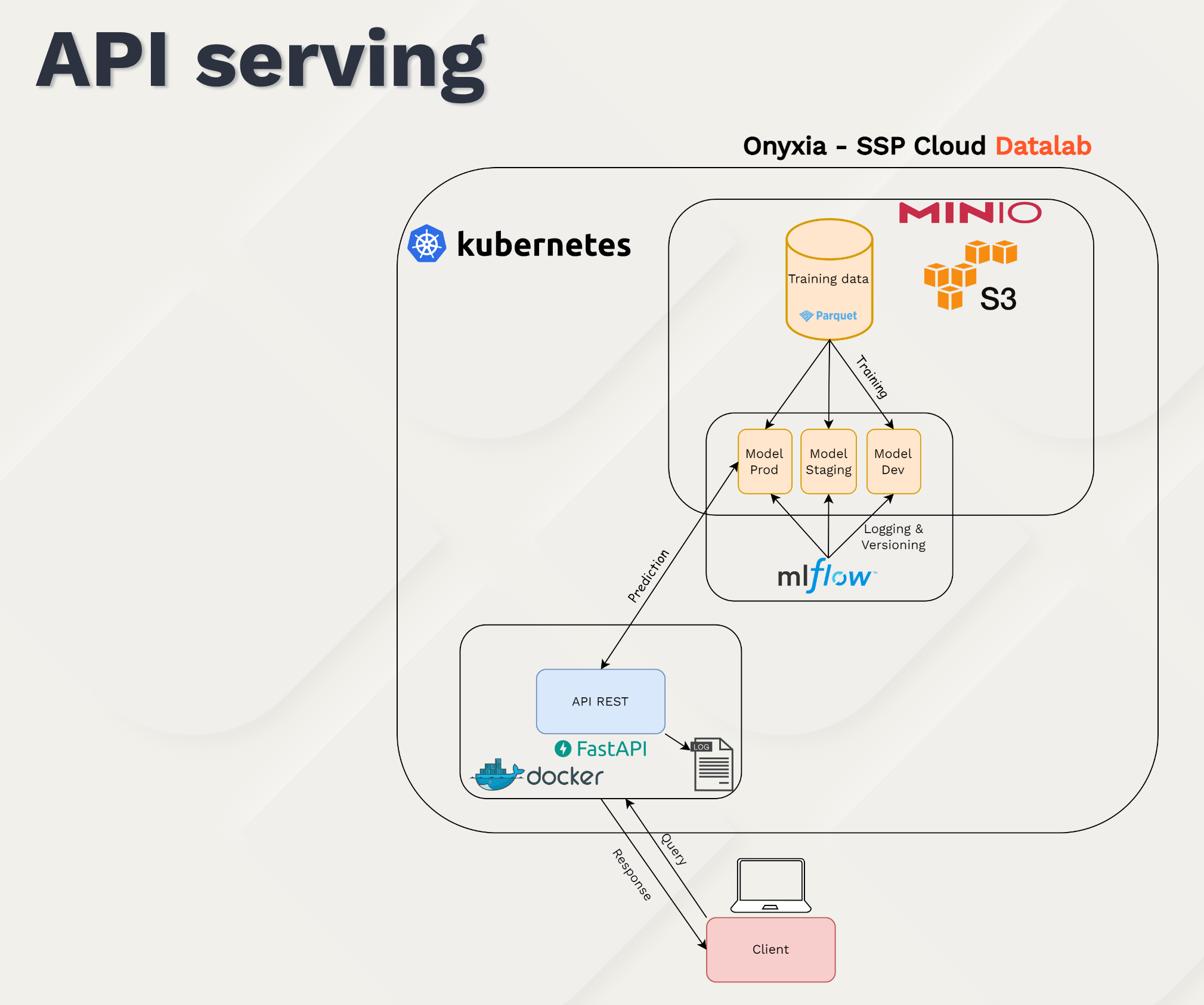




https://github.com/InseeFrLab/torchTextClassifiers




Citation
@online{bochman2025,
author = {Bochman, Oren},
title = {torchTextClassifiers : {Modernizing} {Text} Classification
for {French} {National} {Statistics}},
date = {2025-12-09},
url = {https://orenbochman.github.io/posts/2025/2025-12-09-pydata-torchTextClassifiers/},
langid = {en}
}