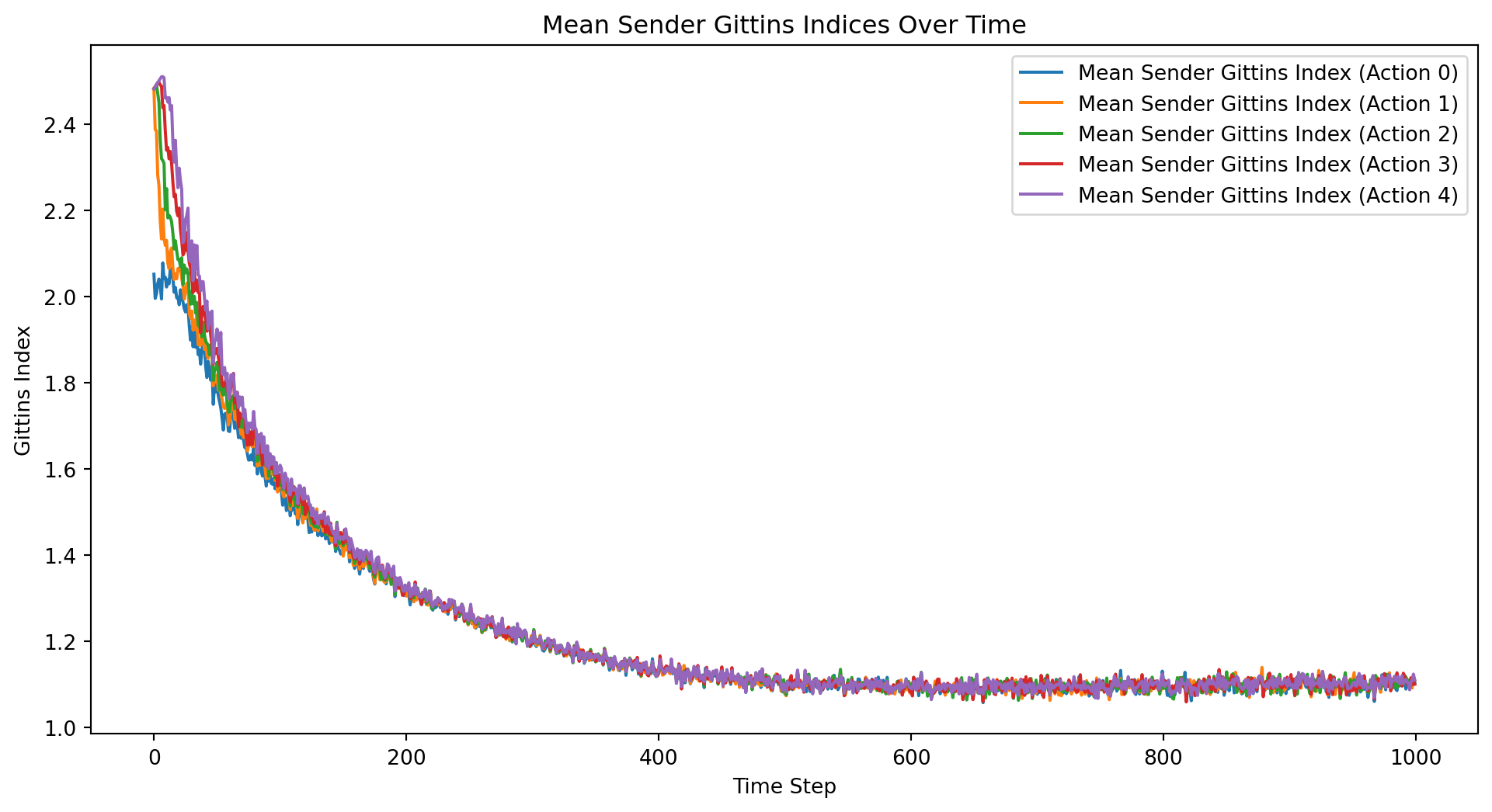
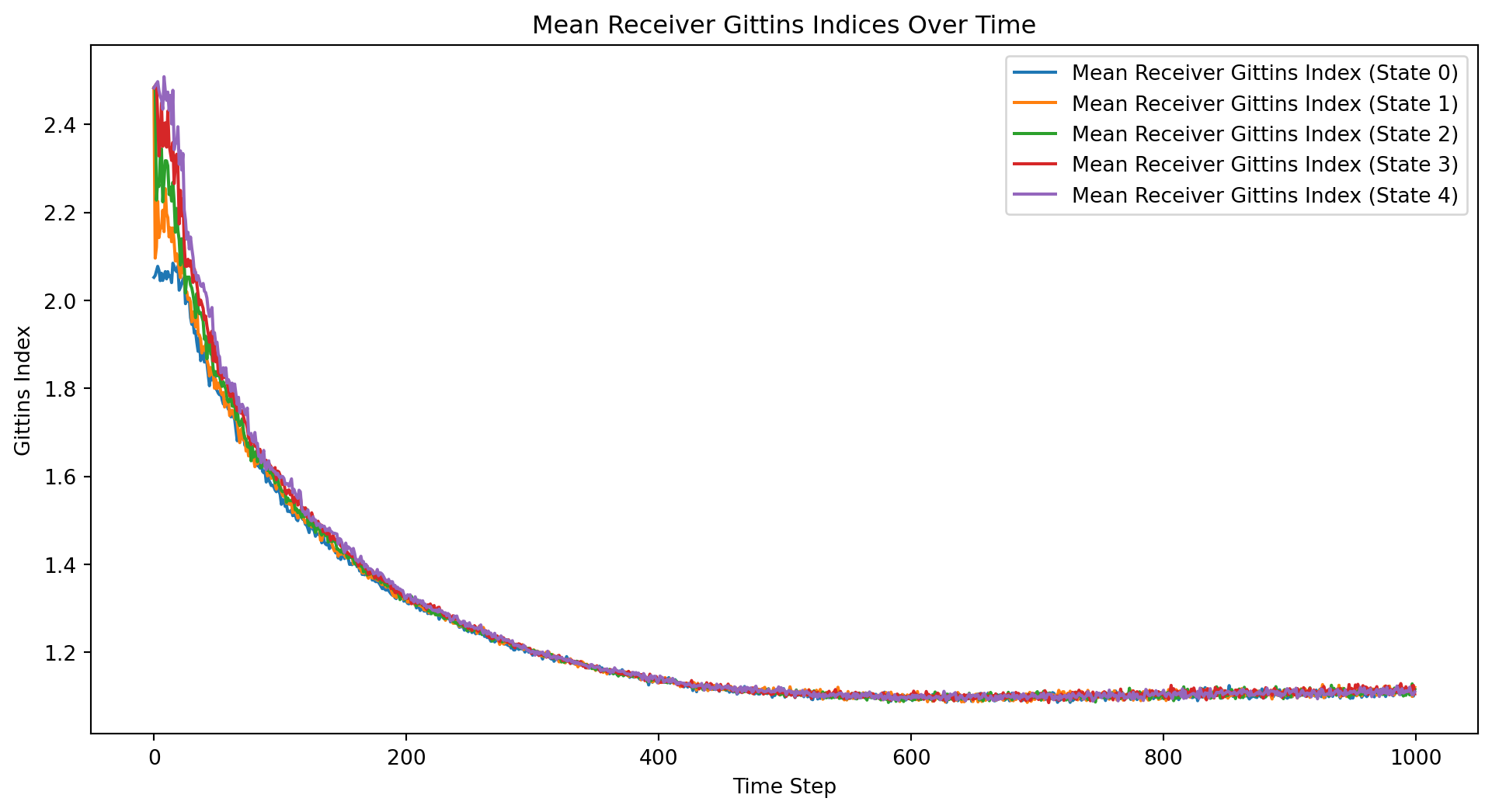
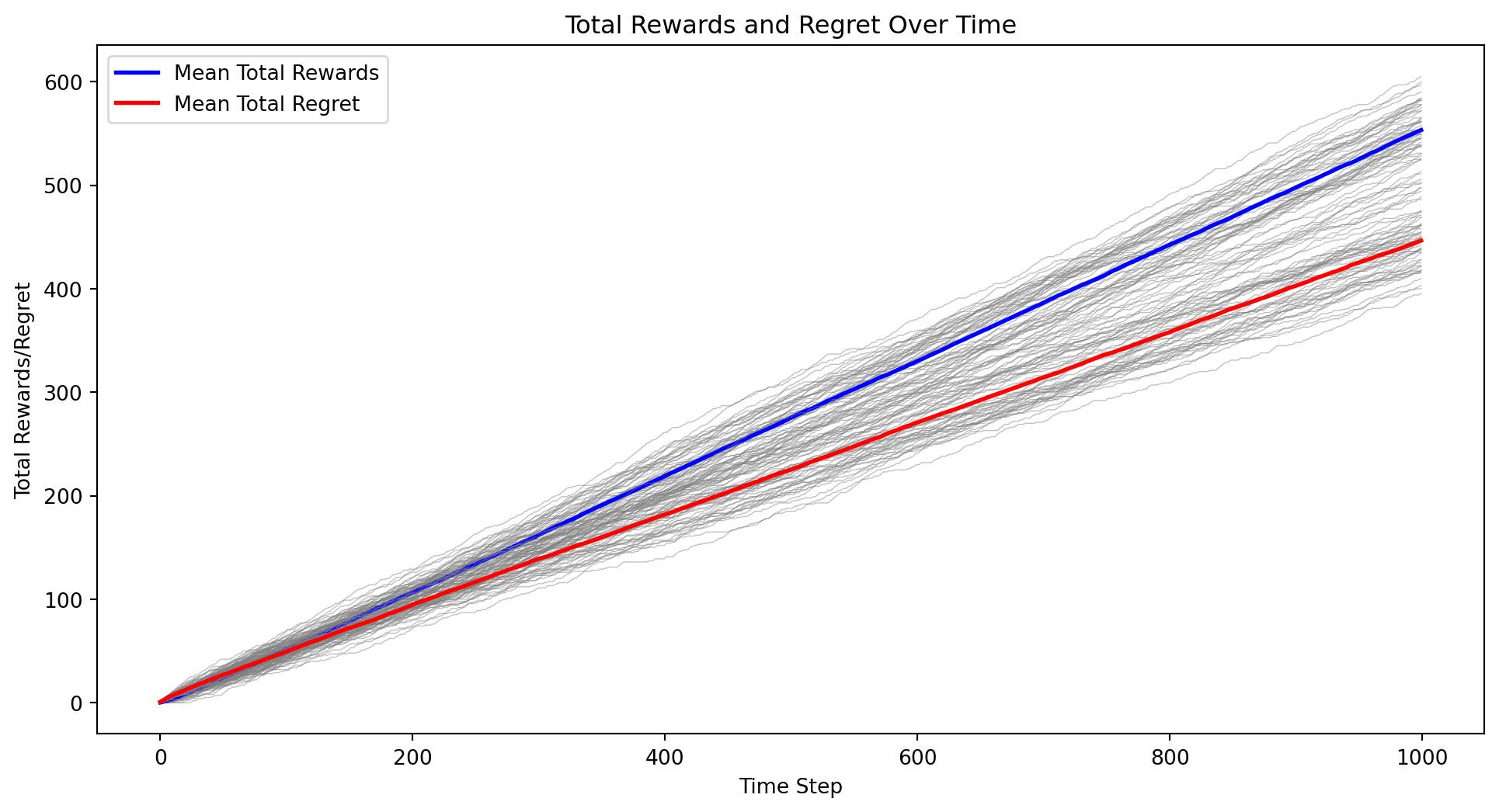
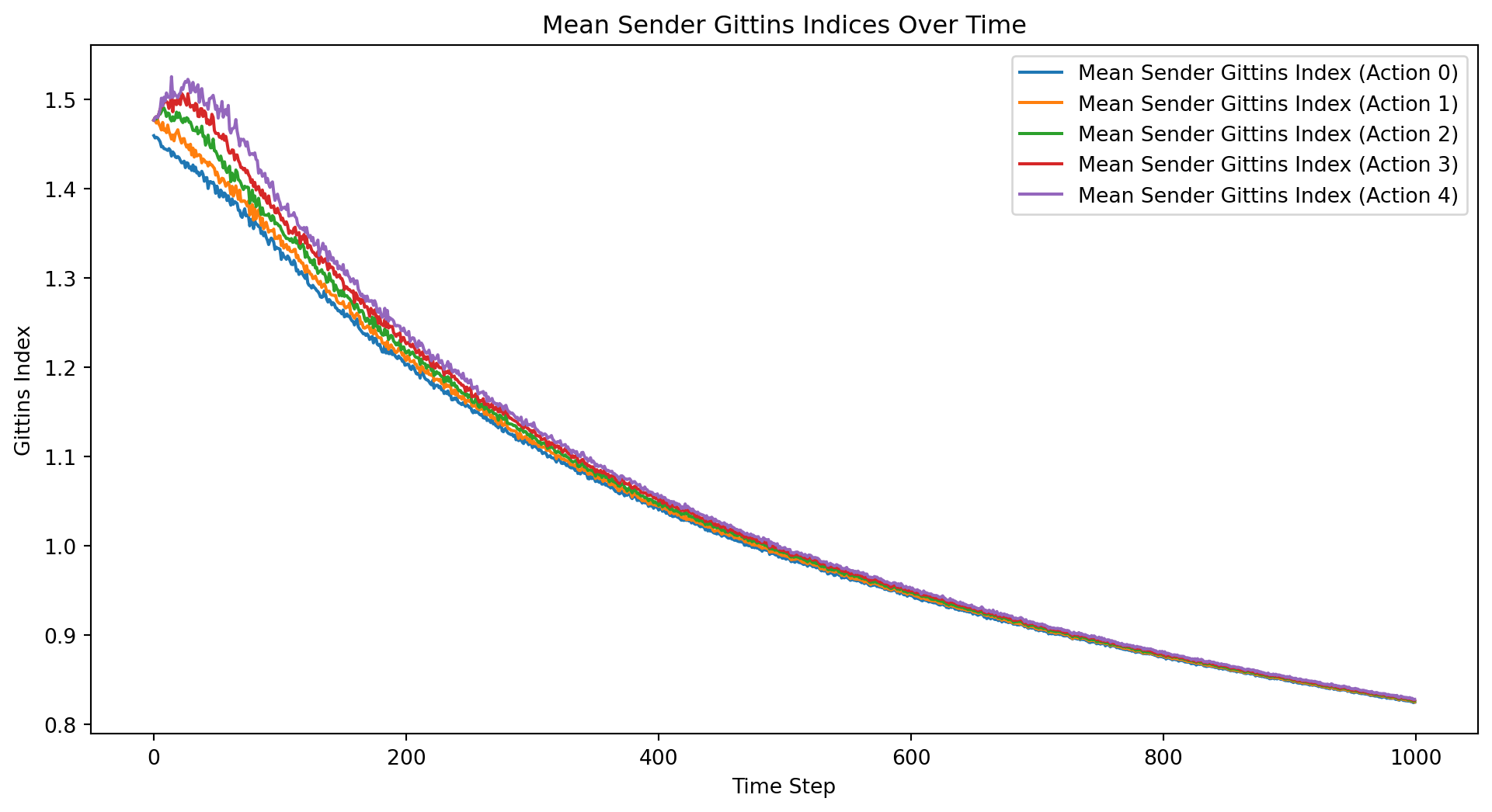
from mesa import Agent, Model
from mesa.time import StagedActivation
import random
import numpy as np
import matplotlib.pyplot as plt
from abc import ABC, abstractmethod
# let's define a lambda to take a list of options and intilize the weights uniformly
uniform_init = lambda options, w : {option: w for option in options}
random_init = lambda options, w : {option: random.uniform(0,1) for option in options}
# lets make LeaningRule an abstract class with all the methods that are common to all learning rules
# then we can subclass it to implement the specific learning rules
class LearningRule(ABC):
def __init__(self, options, learning_rate=0.1,verbose=False,name='LearningRule',init_weight=uniform_init):
self.verbose = verbose
self.name=name
self.learning_rate = learning_rate
if self.verbose:
print(f'LearningRule.__init__(Options: {options})')
self.options = options
self.weights = init_weight(options,1.0) # Start with one ball per option
def get_filtered_weights(self, filter):
if self.verbose:
print(f'get_filtered_weights({filter=})')
# if filter is int convert to string
if isinstance(filter, int):
filter = str(filter)
filter_keys = [k for k in self.weights.keys() if k.startswith(filter)]
weights = {opt: self.weights[opt] for opt in filter_keys}
return weights
@abstractmethod
def choose_option(self,filter):
pass
@abstractmethod
def update_weights(self, option, reward):
pass
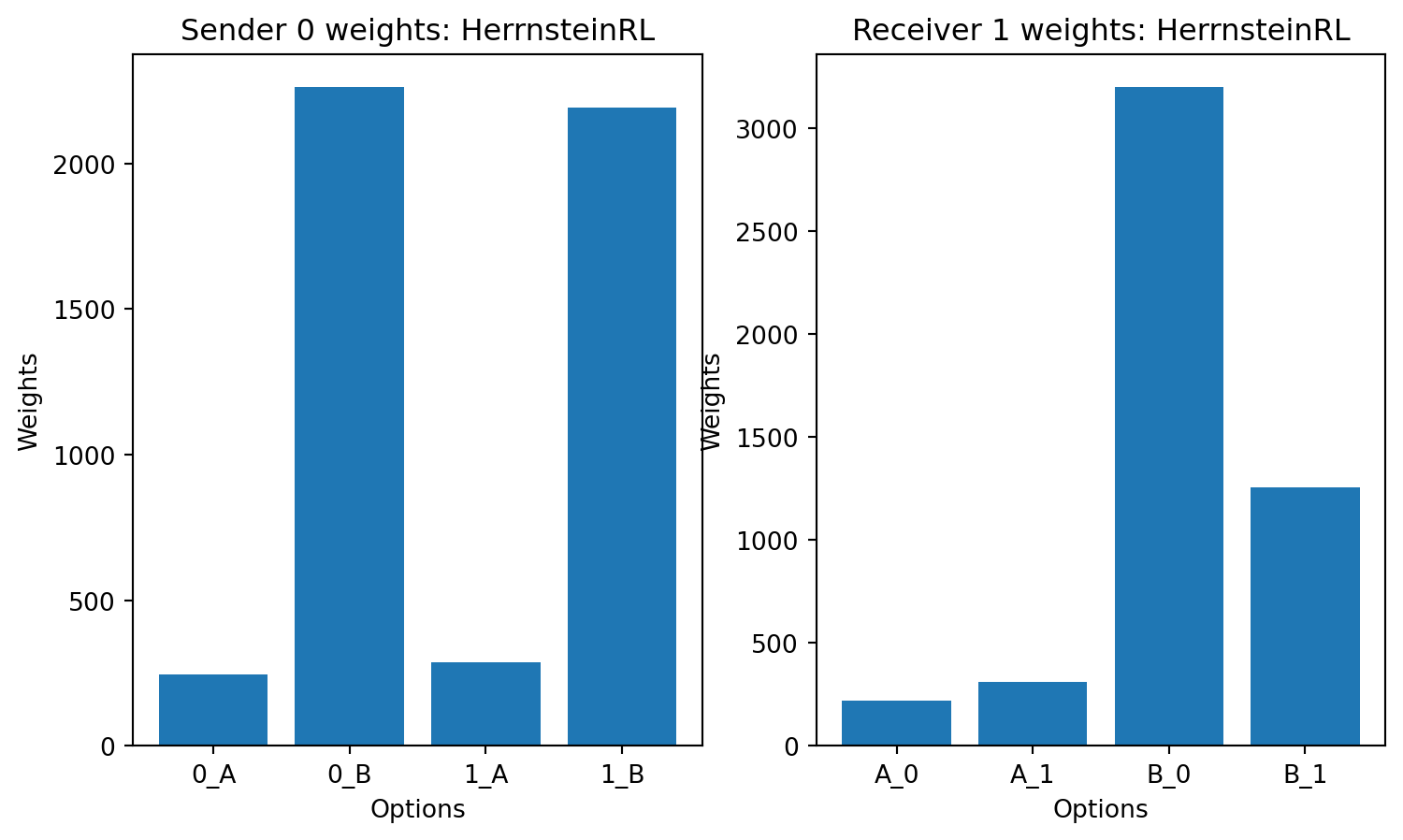
class HerrnsteinRL(LearningRule):
'''
The Urn model
nature sender reciever reward
| (0) | --{0}--> | (0_a) | --{a}--> | (a_0) | --{0}--> 1
| | | (0_b) | --{b} | (a_1) | --{1}--> 0
| | +--------+ | +-->+-------+
| | +-|-+
| (1) | --{1}--> | (1_a) | --{a}+ +>| (b_0) | --{1}--> 1
| | | (1_b) | --{b}--->| (b_1) | --{0}--> 0
+-----+ +--------+ +-------+
Herrnstein urn algorithm
------------------------
1. nature picks a state
2. sender gets the state, chooses a signal by picking a ball in choose_option() from the stat'es urn
3. reciver gets the action, chooses an actuion by picking a ball in choose_option()
4. the balls in the urns are incremented if action == state
5. repeat
'''
def __init__(self, options, learning_rate=1.0,verbose=False,name='Herrnstein matching law'):
super().__init__(verbose = verbose, options=options, learning_rate=learning_rate,name=name)
def update_weights(self, option, reward):
old_weight = self.weights[option]
self.weights[option] += self.learning_rate * reward
if self.verbose:
print(f"Updated weight for option {option}: {old_weight} -> {self.weights[option]}")
def choose_option(self,filter):
'''
'''
# subseting the weights by the filter simulates different urns per state or signal
weights = self.get_filtered_weights(filter)
# calculate their probabilities then
total = sum(weights.values())
assert total > 0.0, f"total weights is {total=} after {filter=} on {self.weights} "
probabilities = [weights[opt] / total for opt in weights]
# then drawn an option from the filtered option using the probabilities
return np.random.choice(list(weights.keys()), p=probabilities)
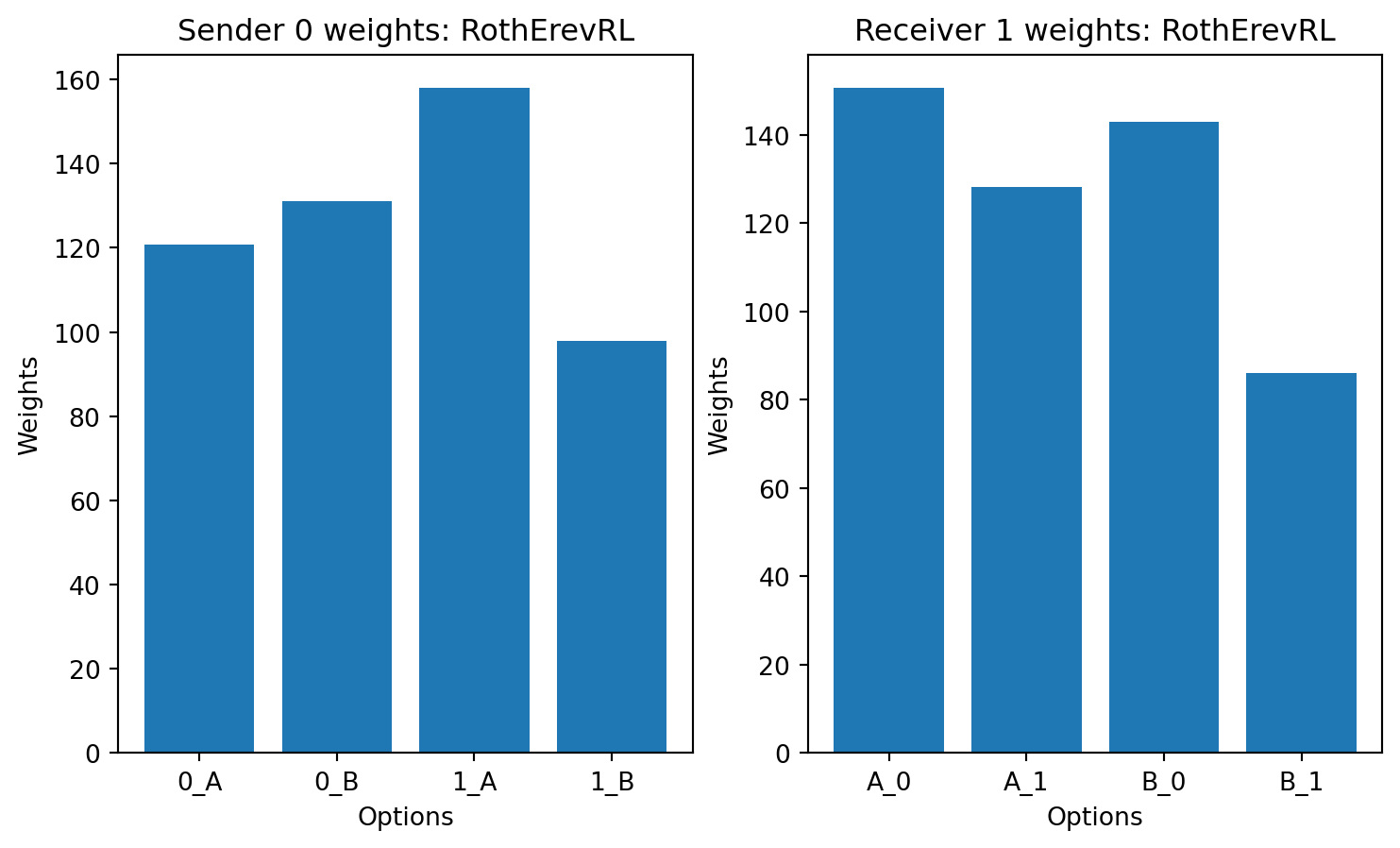
class RothErevRL(LearningRule):
def __init__(self, options, learning_rate=0.1,verbose=False,name='Roth Erev RL'):
super().__init__(verbose = verbose, options=options, learning_rate=learning_rate,name=name)
def update_weights(self, option, reward):
old_weight = self.weights[option]
if reward == 1:
self.weights[option] += self.learning_rate * reward
if self.verbose:
print(f"Updated weight for option {option}: {old_weight} -> {self.weights[option]}")
def choose_option(self,filter):
# we subset the weights by the filter, calculate their probabilities then
# then drawn an option from the filtered option using the probabilities
weights = self.get_filtered_weights(filter)
total = sum(weights.values())
probabilities = [weights[opt] / total for opt in weights]
return np.random.choice(list(weights.keys()), p=probabilities)
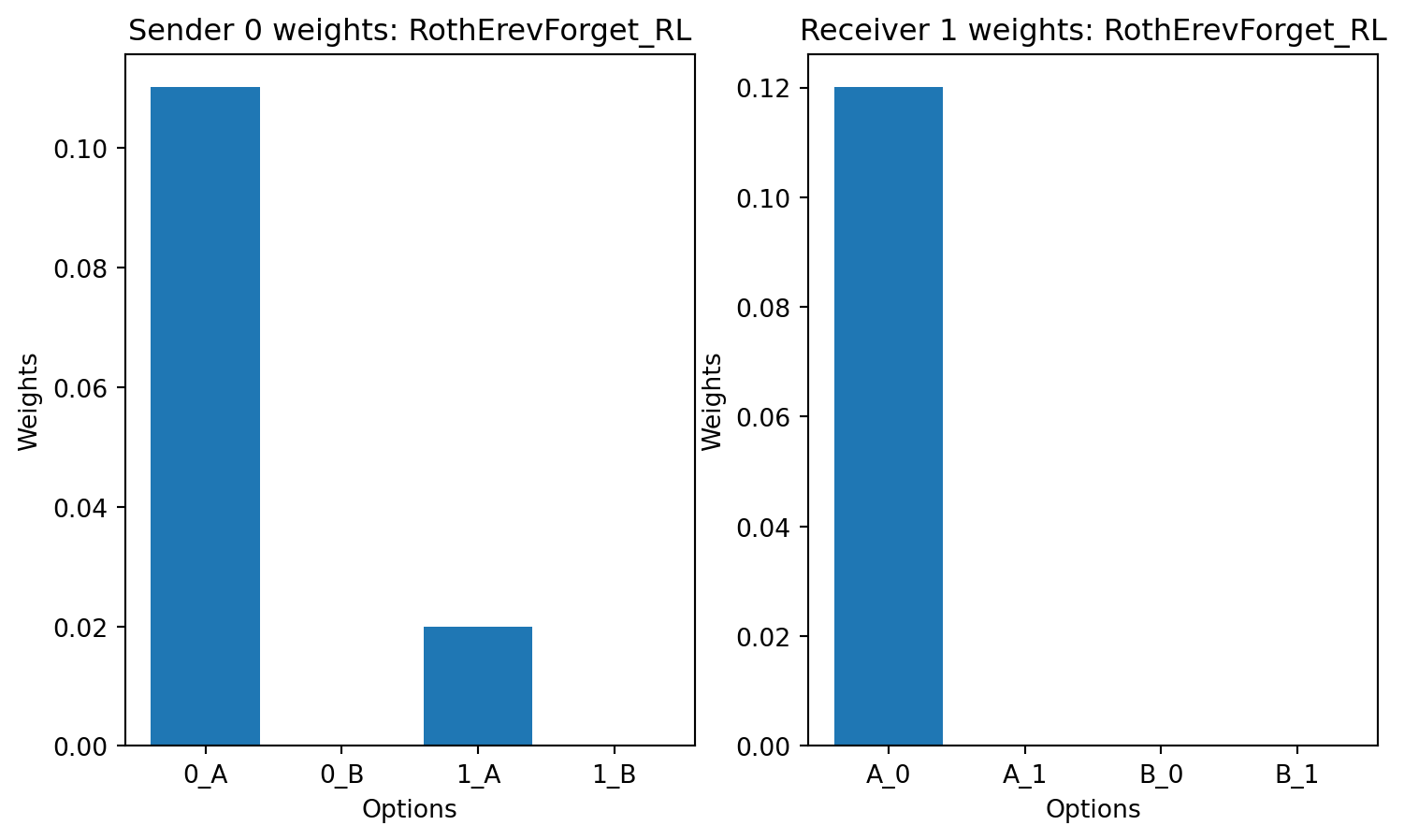
class RothErevForget_RL(LearningRule):
def __init__(self, options, learning_rate=0.1,verbose=False,name='Roth Erev with forgetting'):
super().__init__(verbose = verbose, options=options, learning_rate=learning_rate,name=name)
def update_weights(self, option, reward):
old_weight = self.weights[option]
if reward == 1:
self.weights[option] += self.learning_rate * reward
else:
self.weights[option] *= self.learning_rate
if self.verbose:
print(f"Updated weight for option {option}: {old_weight} -> {self.weights[option]}")
def choose_option(self,filter):
weights = self.get_filtered_weights(filter)
total = sum(weights.values())
probabilities = [weights[opt] / total for opt in weights]
return np.random.choice(list(weights.keys()), p=probabilities)
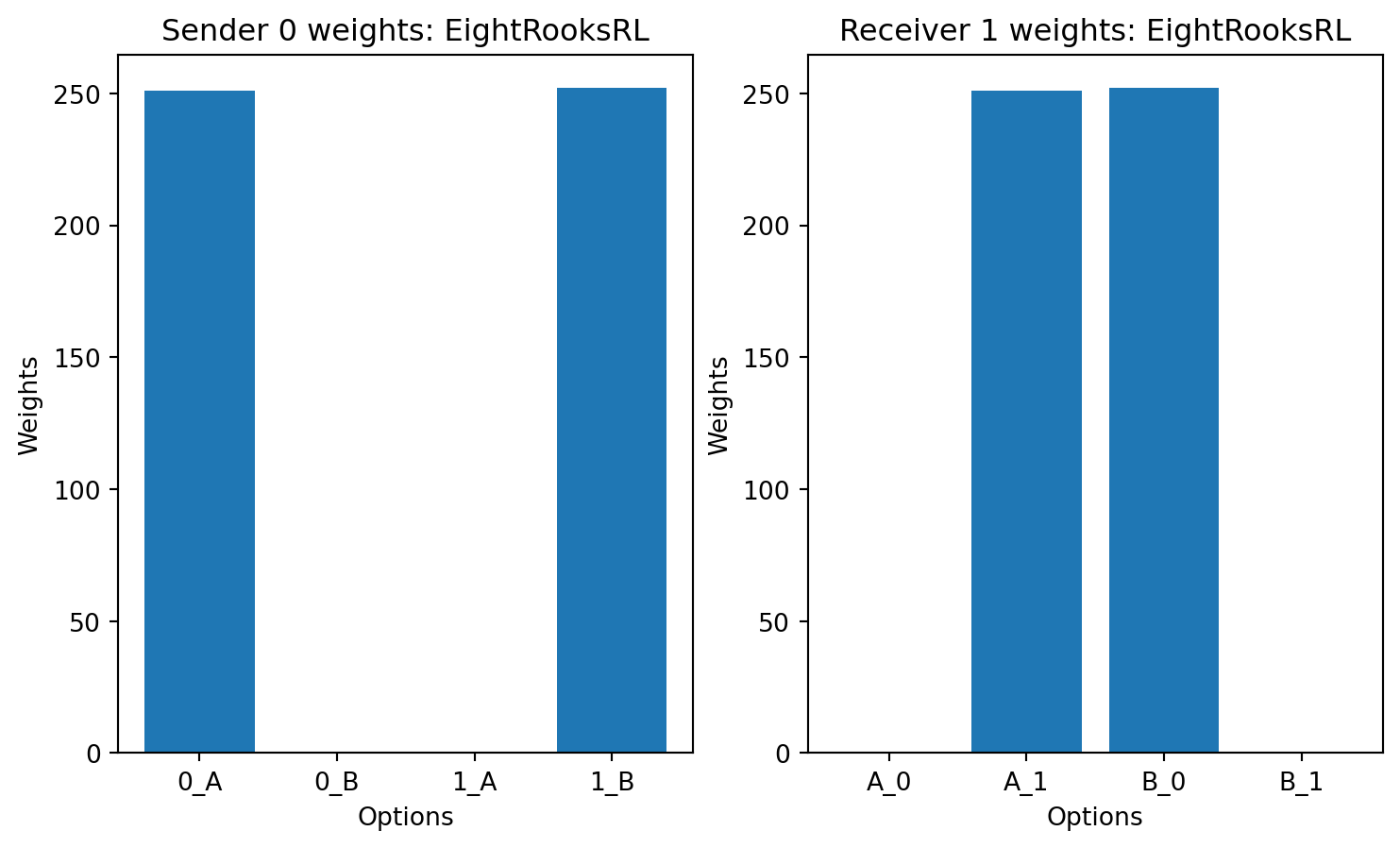
class EightRooksRL(LearningRule):
def __init__(self, options, learning_rate=0.1,verbose=False,name='Eight Rooks RL'):
super().__init__(verbose = verbose, options=options, learning_rate=learning_rate,name=name)
def update_weights(self, option, reward):
self.prefix = option.split('_')[0]
self.suffix = option.split('_')[1]
old_weights=self.weights.copy()
for test_option in self.options:
if reward == 1:
if test_option == option:
# increment the weight of the good option
self.weights[test_option] += self.learning_rate * reward
elif test_option.startswith(self.prefix) or test_option.endswith(self.suffix) :
# decrement all other options with same prefix or suffix
# if self.weights[test_option] < 0.000001:
# self.weights[test_option] = 0.0
# else:
self.weights[test_option] *= self.learning_rate
# elif test_option == option:
# # decrement the weights of the bad option combo
# self.weights[option] *= self.learning_rate
if self.verbose:
print()
for option in self.options:
if old_weights[option] != self.weights[option]:
print(f"{option}: weight {old_weights[option]} -> {self.weights[option]}")
#print(f"Updated weight {old_weights} -> {self.weights}")
def choose_option(self,filter):
weights = self.get_filtered_weights(filter)
total = sum(weights.values())
probabilities = [weights[opt] / total for opt in weights]
# if there is a max weight return it otherwise return a random option from the max wights
if len([opt for opt in weights if weights[opt]==max(weights.values())]) == 1:
return max(weights, key=weights.get)
else:
return np.random.choice([opt for opt in weights if weights[opt]==max(weights.values())])
class LewisAgent(Agent):
def __init__(self, unique_id, model, learning_options, learning_rule, verbose=False):
super().__init__(unique_id, model)
self.message = None
self.action = None
self.reward = 0
self.learning_rule = learning_rule
self.verbose = verbose
def send(self):
return
def receive(self):
return
def calc_reward(self):
return
def set_reward(self):
self.reward = self.model.reward
if self.verbose:
print(f"Agent {self.unique_id} received reward: {self.reward}")
def update_learning(self):
self.learning_rule.update_weights(self.option, self.reward) # Update weights based on signals and rewards
class Sender(LewisAgent):
def send(self):
state = self.model.get_state()
#self.message = self.learning_rule.choose_option(filter=state) # Send a signal based on the learned weights
self.option = self.learning_rule.choose_option(filter=state) # Send a signal based on the learned weights
self.message = self.option.split('_')[1]
if self.verbose:
print(f"Sender {self.unique_id} sends signal for state {state}: {self.message}")
class Receiver(LewisAgent):
def receive(self):
self.received_signals = [sender.message for sender in self.model.senders] # Receive signals from all senders
#print(f"Receiver {self.unique_id} receives signals: {self.received_signals}")
if self.received_signals:
for signal in self.received_signals:
self.option = self.learning_rule.choose_option(filter=signal) # Choose an action based on received signals and learned weights
self.action = int(self.option.split('_')[1])
if self.verbose:
print(f"Receiver {self.unique_id} receives signals: {self.received_signals} and chooses action: {self.action}")
def calc_reward(self):
correct_action = self.model.current_state
self.model.reward = 1 if self.action == correct_action else 0
if self.verbose:
print(f"Receiver {self.unique_id} calculated reward: {self.reward} for action {self.action}")
class SignalingGame(Model):
def __init__(self,
senders_count=1,
receivers_count=1, k=3,
learning_rule=LearningRule,
learning_rate=0.1,
verbose=False):
super().__init__()
self.verbose = verbose
self.k = k
self.current_state = None
self.learning_rate=learning_rate
# Initialize the states, signals, and actions mapping
self.states = list(range(k)) # States are simply numbers
self.signals = list(chr(65 + i) for i in range(k)) # Signals are characters
self.actions = list(range(k)) # Actions are simply numbers
# generate a list of state_signal keys for the sender's weights
self.states_signals_keys = [f'{state}_{signal}' for state in self.states for signal in self.signals]
# generate a list of signal_action keys for the receiver's weights
self.signals_actions_keys = [f'{signal}_{action}' for signal in self.signals for action in self.actions]
self.senders = [Sender(i, self, learning_options=self.states_signals_keys,
learning_rule=learning_rule(self.states_signals_keys, self.learning_rate,verbose=self.verbose)
) for i in range(senders_count)]
self.receivers = [Receiver(i + senders_count, self, learning_options=self.signals_actions_keys,
learning_rule=learning_rule(self.signals_actions_keys, self.learning_rate,verbose=self.verbose)
) for i in range(receivers_count)]
self.schedule = StagedActivation(self,
agents = self.senders + self.receivers,
stage_list=['send', 'receive', 'calc_reward', 'set_reward', 'update_learning'])
def get_state(self):
return random.choice(self.states)
def step(self):
self.current_state = self.get_state()
if self.verbose:
print(f"Current state of the world: {self.current_state}")
self.schedule.step()
# function to plot agent weights side by side
def plot_weights(sender,reciver,title='Agent'):
fig, ax = plt.subplots(1,2,figsize=(9,5))
weights = sender.learning_rule.weights
ax[0].bar(weights.keys(), weights.values())
ax[0].set_xlabel('Options')
ax[0].set_ylabel('Weights')
ax[0].set_title(f'Sender {sender.unique_id} weights: {title}')
weights = reciver.learning_rule.weights
ax[1].bar(weights.keys(), weights.values())
ax[1].set_xlabel('Options')
ax[1].set_ylabel('Weights')
ax[1].set_title(f'Receiver {reciver.unique_id} weights: {title}')
plt.show()
# Running the model
k=2
verbose = False
for LR in [HerrnsteinRL,
RothErevRL,
RothErevForget_RL,
EightRooksRL
]:
print(f"--- {LR.__name__} ---")
if LR == HerrnsteinRL:
learning_rate=1.
else:
learning_rate=.1
model = SignalingGame(senders_count=1, receivers_count=1, k=k, learning_rule=LR,learning_rate=learning_rate,verbose=verbose)
for i in range(10000):
if verbose:
print(f"--- Step {i+1} ---")
model.step()
#
#print the agent weights
#print('Sender weights:',model.senders[0].learning_rule.weights)
# plot weights side by side
plot_weights(model.senders[0],model.receivers[0],title=LR.__name__)
#print('Receiver weights:',model.receivers[0].learning_rule.weights)
#plot_weights(model.receivers[0],title=LR.__name__)