![]()
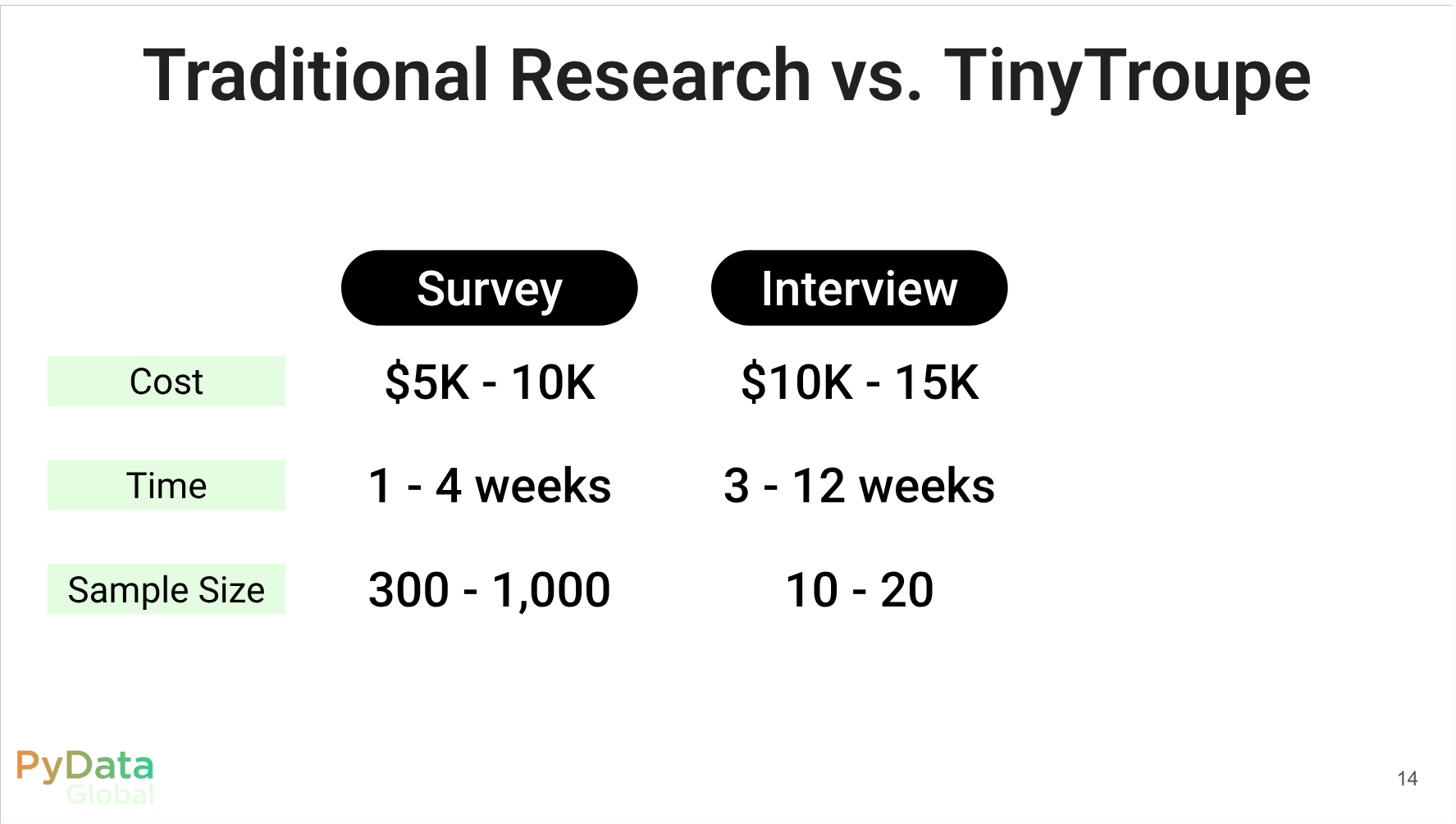
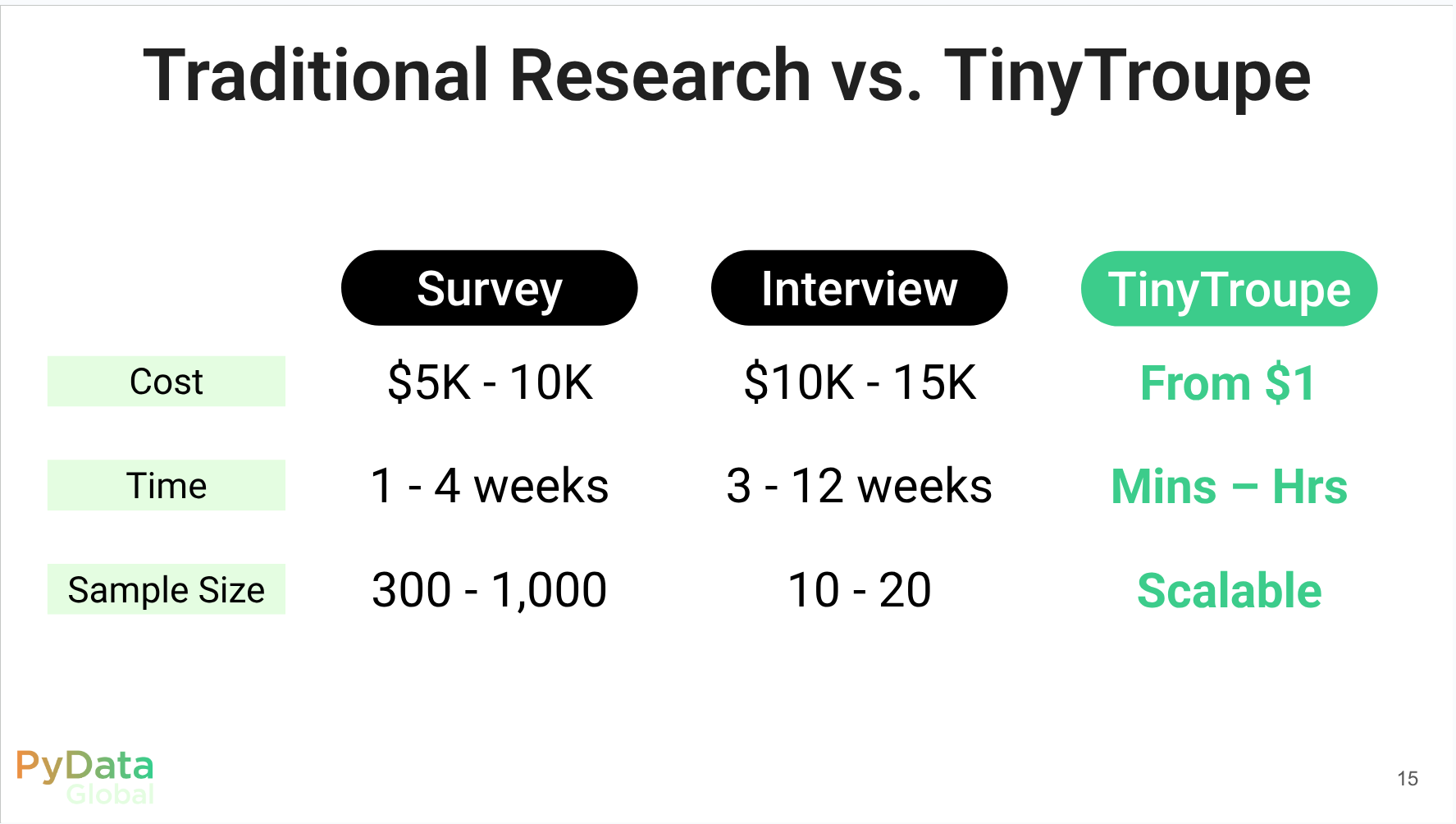
Understanding customer behavior is essential in marketing. Traditionally, marketers rely on methods such as surveys, customer interviews, and focus groups to gather insights. However, these approaches can be expensive, time-consuming, and limited in scale and diversity. Recently, multi-agent simulation powered by Large Language Models (LLMs) is emerging as an innovative technique. TinyTroupe, for example, enables the creation of different personas (e.g., budget‑minded Gen‑Z shoppers, premium‑seeking parents), allowing marketers to predict and optimize advertising effectiveness or replace time-consuming interviews rapidly. In this talk, I will introduce the key concepts of LLM-powered multi-agent simulations, demonstrate their practical application in marketing through TinyTroupe, and share actionable insights and recommendations.
Transformers power modern large language models, but their inner workings are often buried under complex libraries and unreadable abstractions. In this talk, we’ll peel back the layers and build the original Transformer architecture (Vaswani et al., 2017) step by step in PyTorch, from input embeddings to attention masks to the full encoder-decoder stack.
This talk is designed for attendees with a basic understanding of deep learning and PyTorch who want to go beyond surface-level blog posts and get a hands-on, conceptual grasp of what happens under the hood. You’ll see how each part of the transformer connects back to the equations in the original paper, how to debug common implementation pitfalls, and how to avoid getting lost in tensor dimension hell.
- Understand the core concepts and advantages of LLM-powered multi-agent persona simulation. Learn how to leverage TinyTroupe for efficient and insightful marketing analytics.
- A walkthrough of key components: attention, positional encoding, encoder/decoder stack
- Data analysts and data scientists interested in customer analytics and marketing.
- Marketers, business analysts, and executives seeking innovative approaches to understanding customer behavior and optimizing marketing strategies.
- IT specialists and developers interested in applying LLM and multi-agent simulation technologies to real-world business scenarios.
Hajime Takeda
Hajime is a data professional with 8+ years of expertise in marketing, retail, and eCommerce, working in New York.
Outline
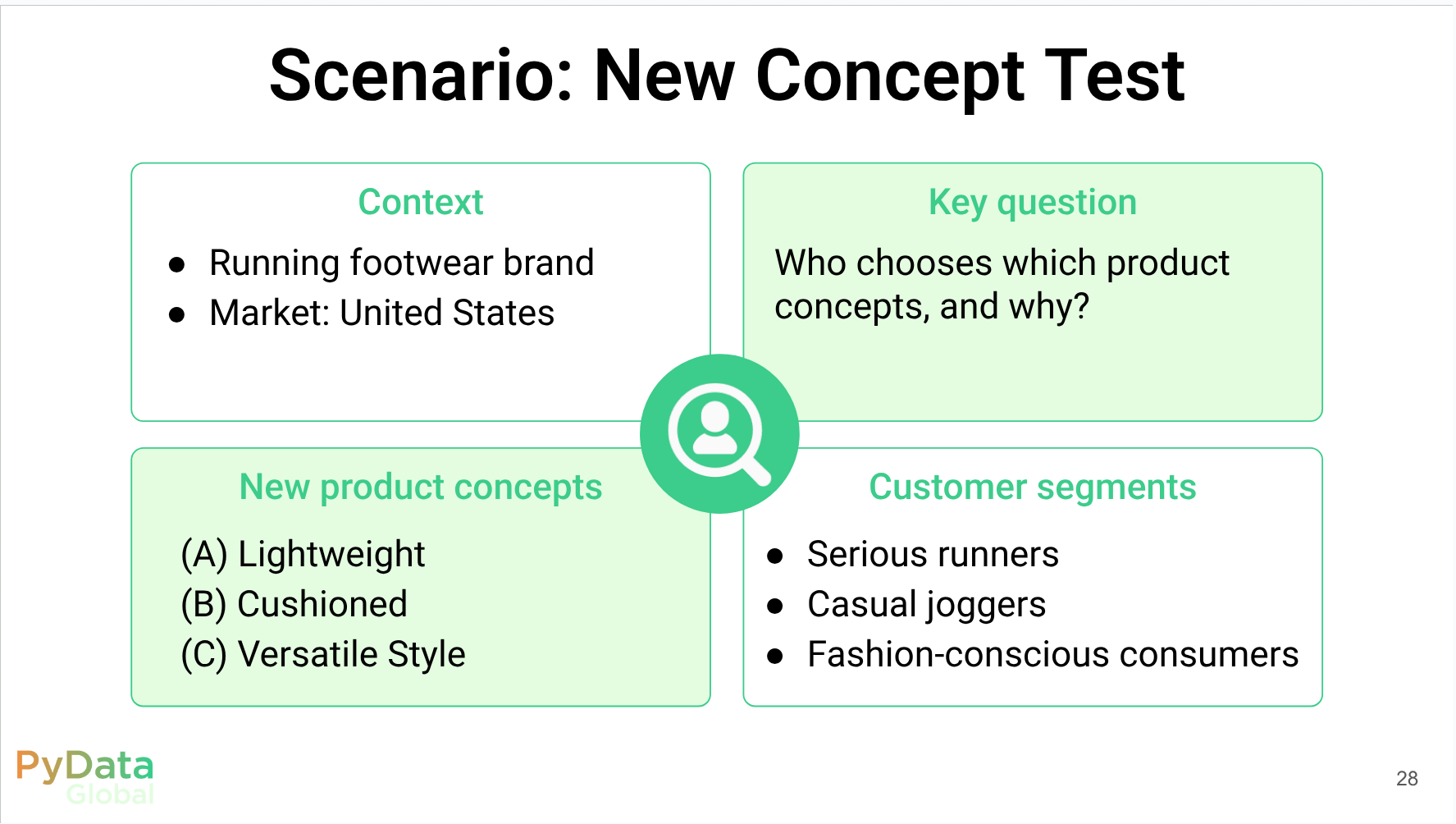
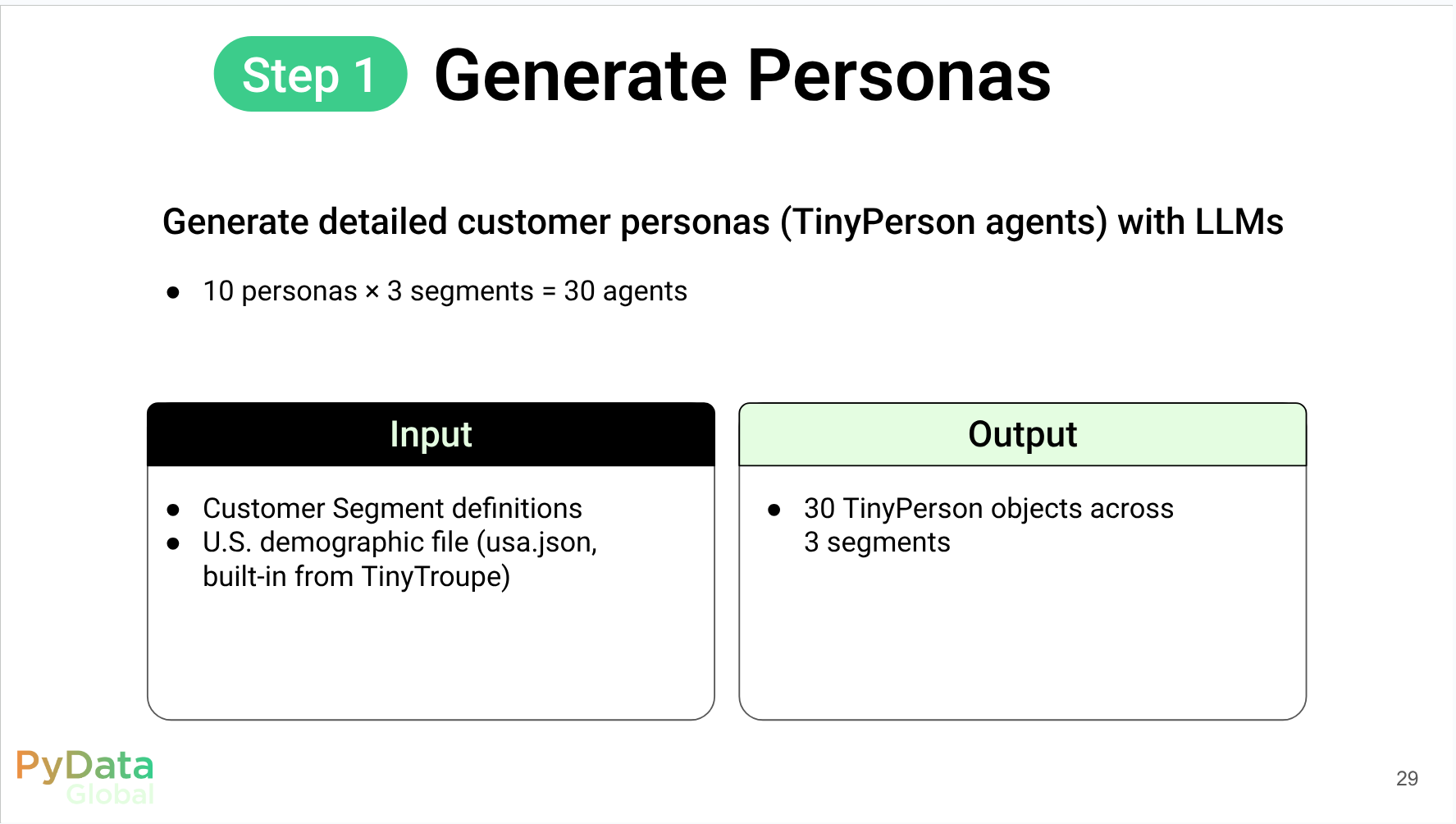
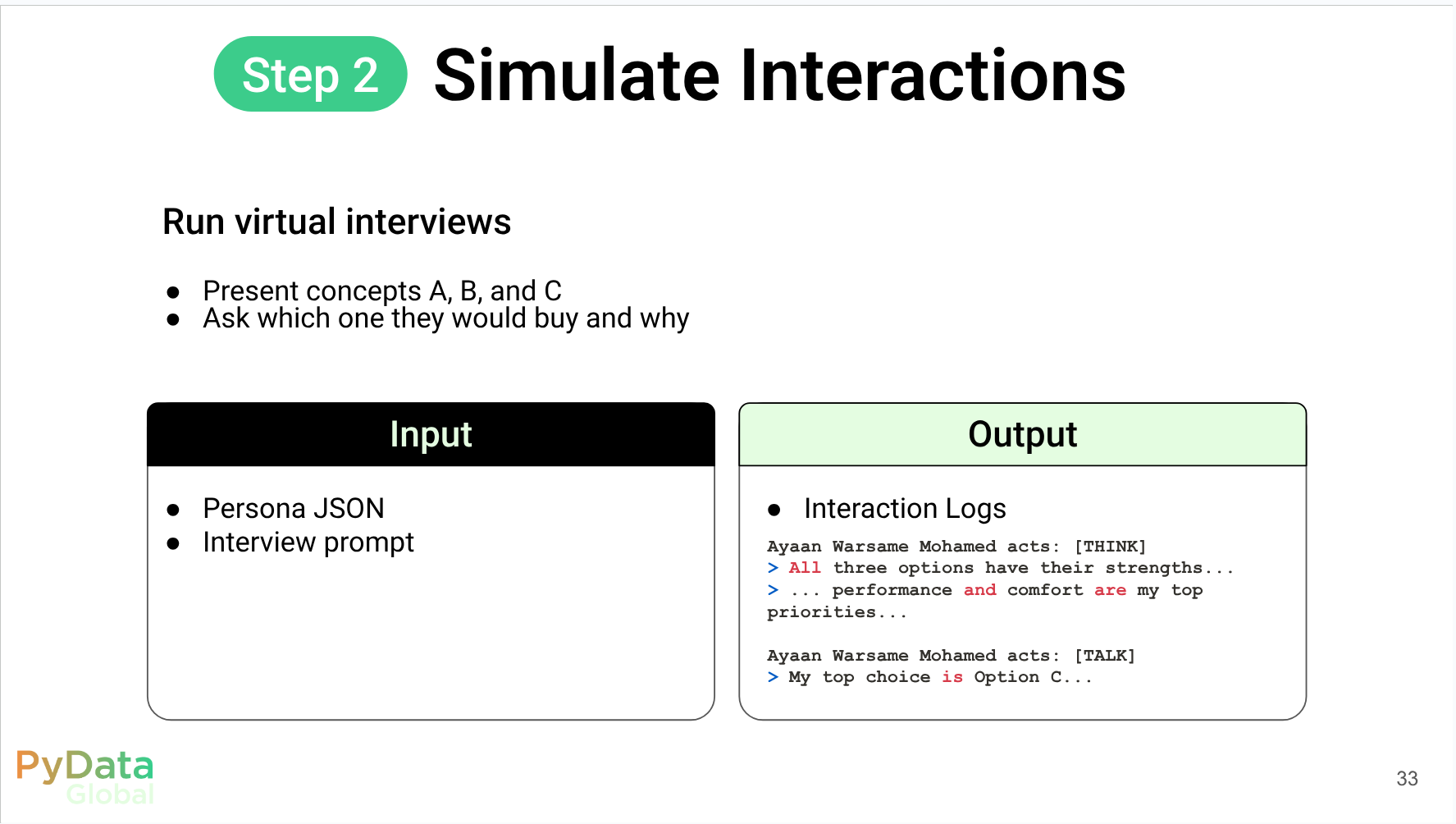
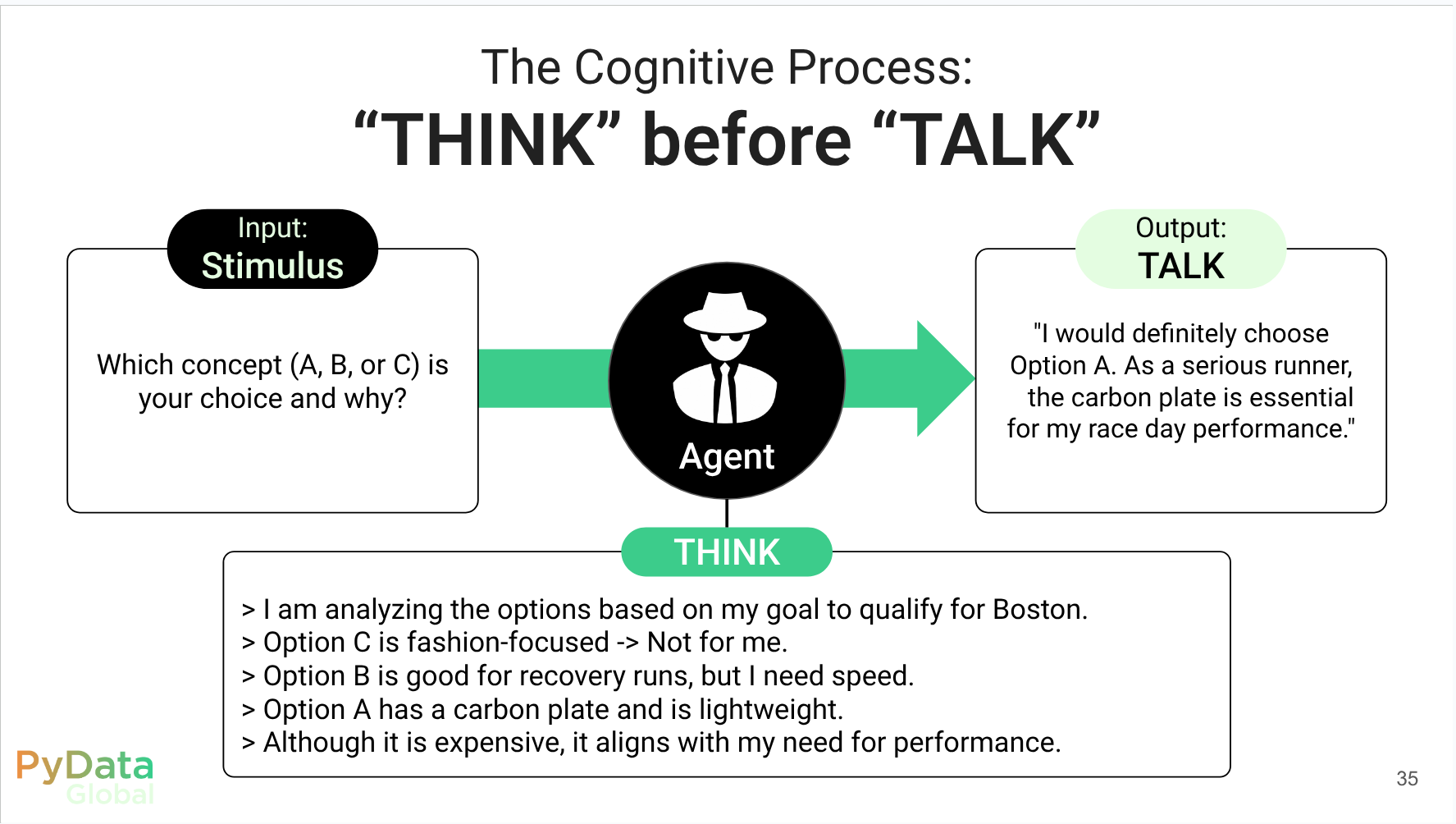
Introduction Business Context: customer understanding & traditional research The Challenge: “Can’t we just use ChatGPT?” TinyTroupe: LLM-powered multi-agent persona simulation Code Walkthrough: end-to-end concept-test demo (running-shoe example) Summary & practical tips Code Walkthrough Part















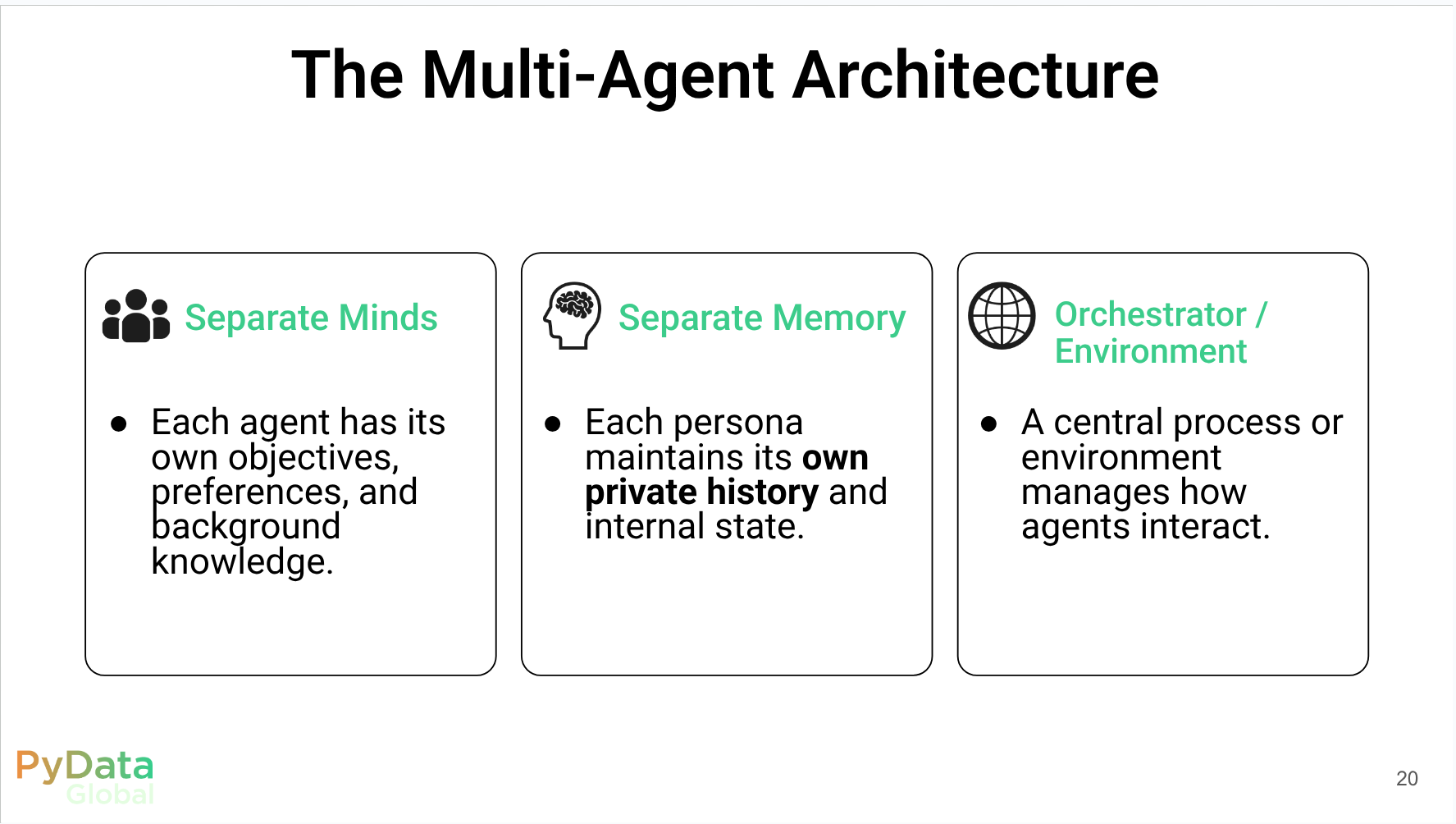


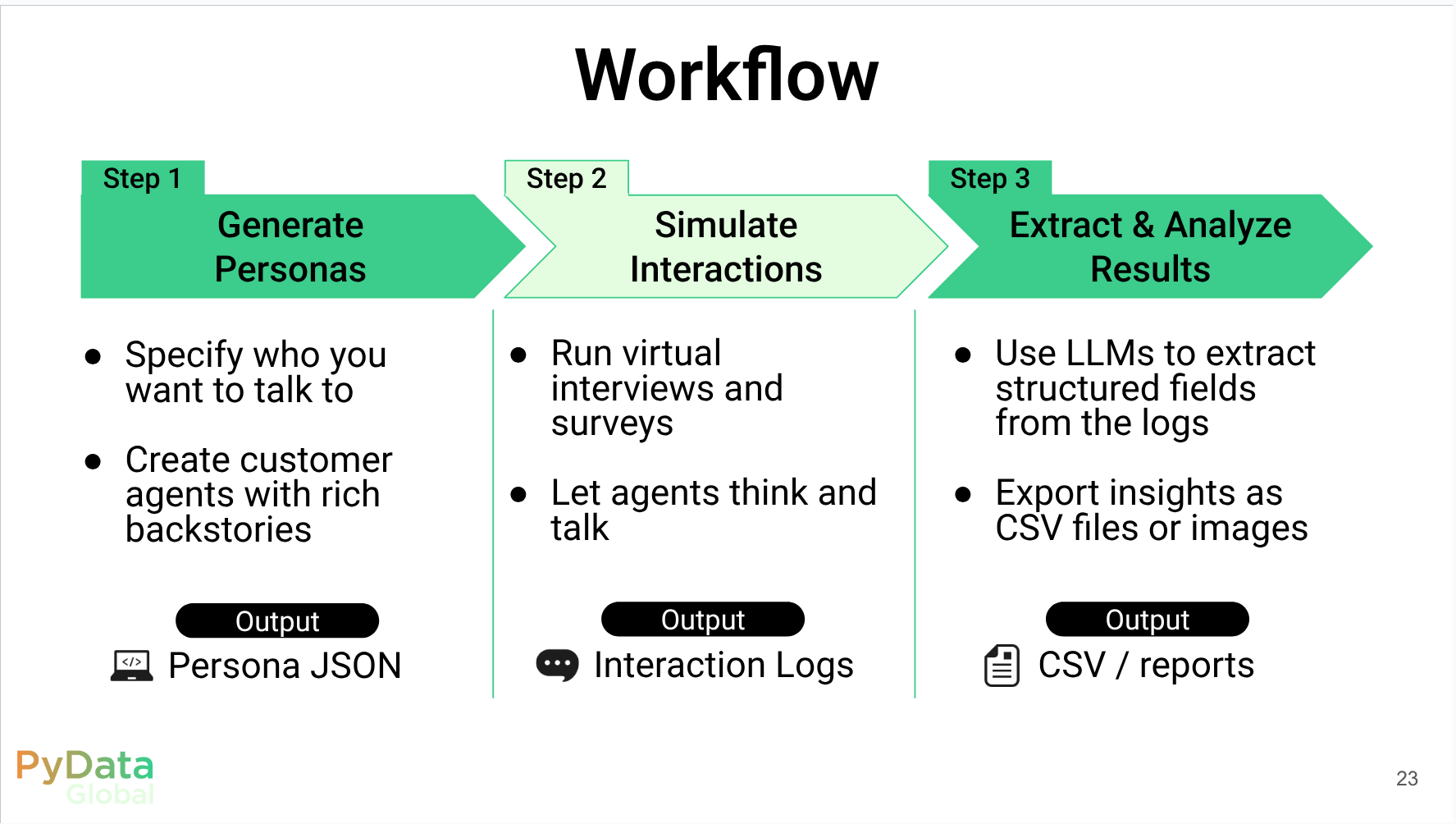
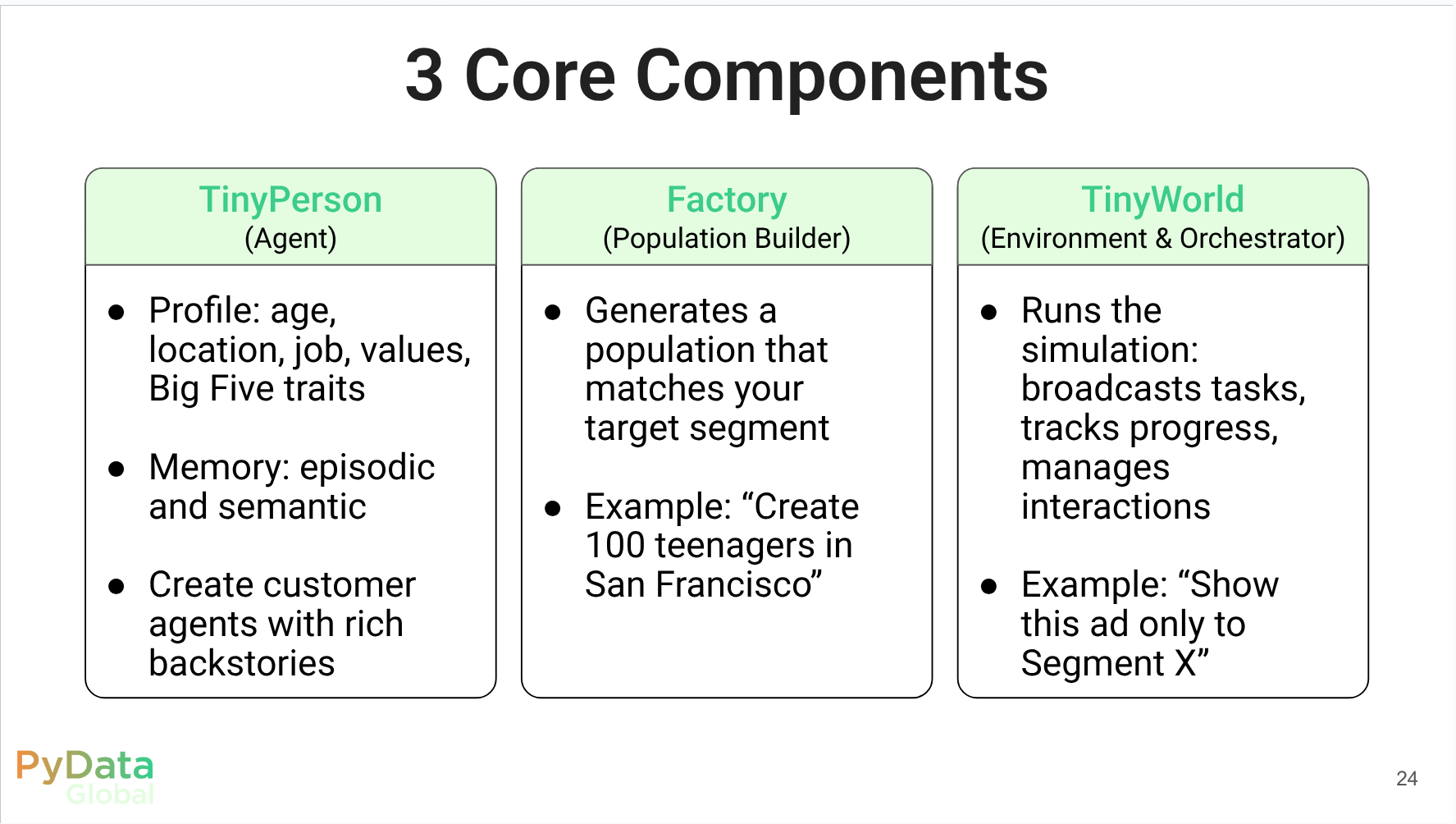
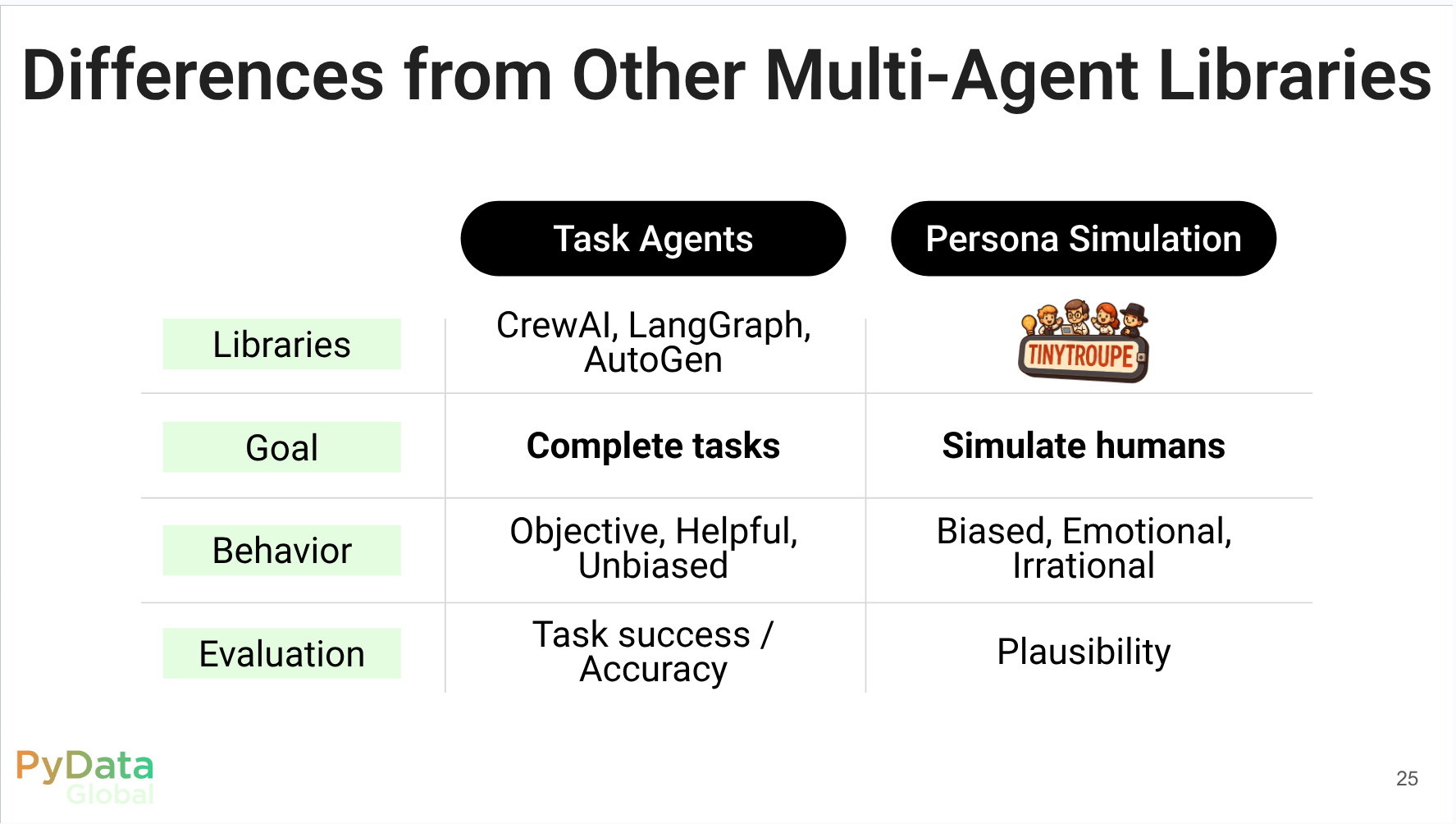
















Reflections
Lets start with a small confession. I miss very much a number of people whithom I lost touch over the years. In some cases I could create a chat bot that would simulates some of the idiosyncrasies of how these people used to communicate. However this was long before LLM became available. At this point I think that it should be possible to create a more realistic simulation of these people using LLM based chat bots.
Lots of the early propmt engineering tricks peple shared were along the lines of “You are X, a person who does Y and thinks Z”. This is fine for a superficial session but the chat bot quickly drift away to its own personality.
One of the first thing I did when I got access to chat GPT was a vibe coding project to simulate a personality construct - that was meant to simulate the changing emotional states of a person over time.
A second aspect of this project was to load the personality construct with a non trivial amount of information about the person.
When it became possible to create Chat GPT variants I created on that was based on the legendary advertising executive. Suplying a large number of his quotes as context.
I have to admit that this did not pan out as well as I hoped. I think that the idea is good but there are lots of implementation details that should be worked out.
Now this project of TinyTroupe seems to retrieve this old ideas as well as a couple others that could be combined in the mix.
Ideas
Tenenbaum priors suggests that we can use a Bayesian approach to speed up machine learning - in which different priors are used to guide the learning process. The priors Josh Tenenbaum suggests are very different from the idea of a prior we learned about in statistics. Anyhow the idea of constructing a prior for this work seems to be very productive even if we don’t neccessarily spell out how it is constructed over a some probability space. (In many cases this prior is a hyper prior that is learend from data.) Infact in the session led by Dawny, he demonstrates how we constuct a hierarchial model and then once we train it on the data we can query it to generate data point for a “typical future case” e.g. get stats about a typical bater’s hitting average.
Keeping the persona on track is a challenge that the prior can address. We can further refine the basic notion to one which is more specific to non-parametric models. This being the idea of how strongly we want the model to stick to the prior (or to the based measure associated with the personality.) This is somewhat analogous to the temperature parameter in LLMs. As a hint here we might draw tokens from the LLM and then pass then use a rejection sampling method, importance sampling or bayesian updating to nudge the response towards the personality’s corpus and then use that in out beam search to generate the final response….
One type of prior that seems to be of some use in a persona simulation is to give it emotional latitude. I envision this as a Markov model that can jump ergodically between different emotional states. The current emotional state is then added to the prompt and the response is then used to determine the next emotional state.
For marketing applications, one idea that I was introduced to by Mike Ferry when I worked in sales and that strikes me as powerful is to endow personas with affinity to one of four personality types. These are matched to genders using the Merrill-Reid Personality Styles personality model. This idea can be further extended by adding more or even less personality types though they should be orthogonal to each other - which makes other choices more challenging to setup.
Another approach is based on using reinforcement learning approach to keep the PC on track. (Exploration v.s. Exploitation trade off). In the following sense:
- Exploitation: draw from the personality’s corpus when there is a good quote or opinion in the RAG and then reuse it when appropriate.
- Exploration: let the PC use the LLM’s default response when RAG does not yield good results or is out of distribution. The rub is that we need a reward or utility as feedback to the model to let it know how well it is doing. One idea is to use sentiment analysis to see if the response is useful or not. However not all is lost - if we follow the Mike Ferry he suggest that we can classify personality by prequalifing using a short survey.
Technically it would seem that one could build a transformer with two attention heads - one charged with generating responses from the corpus of the persona while the other is charged with generating responses that are general purpose. (common sense and general knowledge).
Citation
@online{bochman2025,
author = {Bochman, Oren},
title = {TinyTroupe: {Enhancing} {Marketing} {Insights} Through
{LLM-Powered} {Multiagent} {Persona} {Simulation}},
date = {2025-12-12},
url = {https://orenbochman.github.io/posts/2025/2025-12-11-pydata-tiny-troupe/},
langid = {en}
}