Get a firsthand look at how we built a lightweight feature store to accelerate electricity grid forecasting. We’ll cover our decision process, design choices, and implementation using Polars and Google Cloud Storage. Expect lessons learned, real-world bumps, and a clear view of the costs, trade-offs and benefits of our solution.
In this talk, we’ll share how we built a lightweight, production-ready feature store to support electricity grid forecasting. You’ll hear a firsthand account of our journey—from identifying the need to accelerating model prototyping through feature standardization and flexibility.
We’ll start with a high-level overview of our decision-making process: why we chose to build rather than buy, and the trade-offs we considered. Then, we’ll dive into the architecture of our custom feature store, detailing how we leveraged Polars for fast processing and Google Cloud Storage as a scalable backend.
Expect an honest look at the challenges we faced, the benefits we gained, and the costs we encountered along the way. Whether you’re considering building your own feature store or just curious about scaling ML for time series problems, this session will offer practical insights and real-world lessons.
Robin Troesch
Data Engineer trying to reduce the impact of computing on the climate and helping the energy transition.
Working at Electricity Maps in Copenhagen (DK) since 2022 first in the data platform team responsible for acquiring grid data.
Joined the grid forecast team in 2023.
Outline
Building a Lightweight Feature Store For Electricity Grid Forecasts with Polars

Who’s talking?
- Hey, I’m Robin!
- Joined Electricity Maps in 2022 as a data engineer. Originally in the Data Platform team, now in the Grid Forecasts team.
- My mission: making sure our models get all the features they need to produce forecasts and distributing forecasts to customers.

Today’s agenda:
- Forecasting at Electricity Maps
- Why we needed a feature store
- Breaking down our feature store
- A few learnings

Forecasting at Electricity Maps

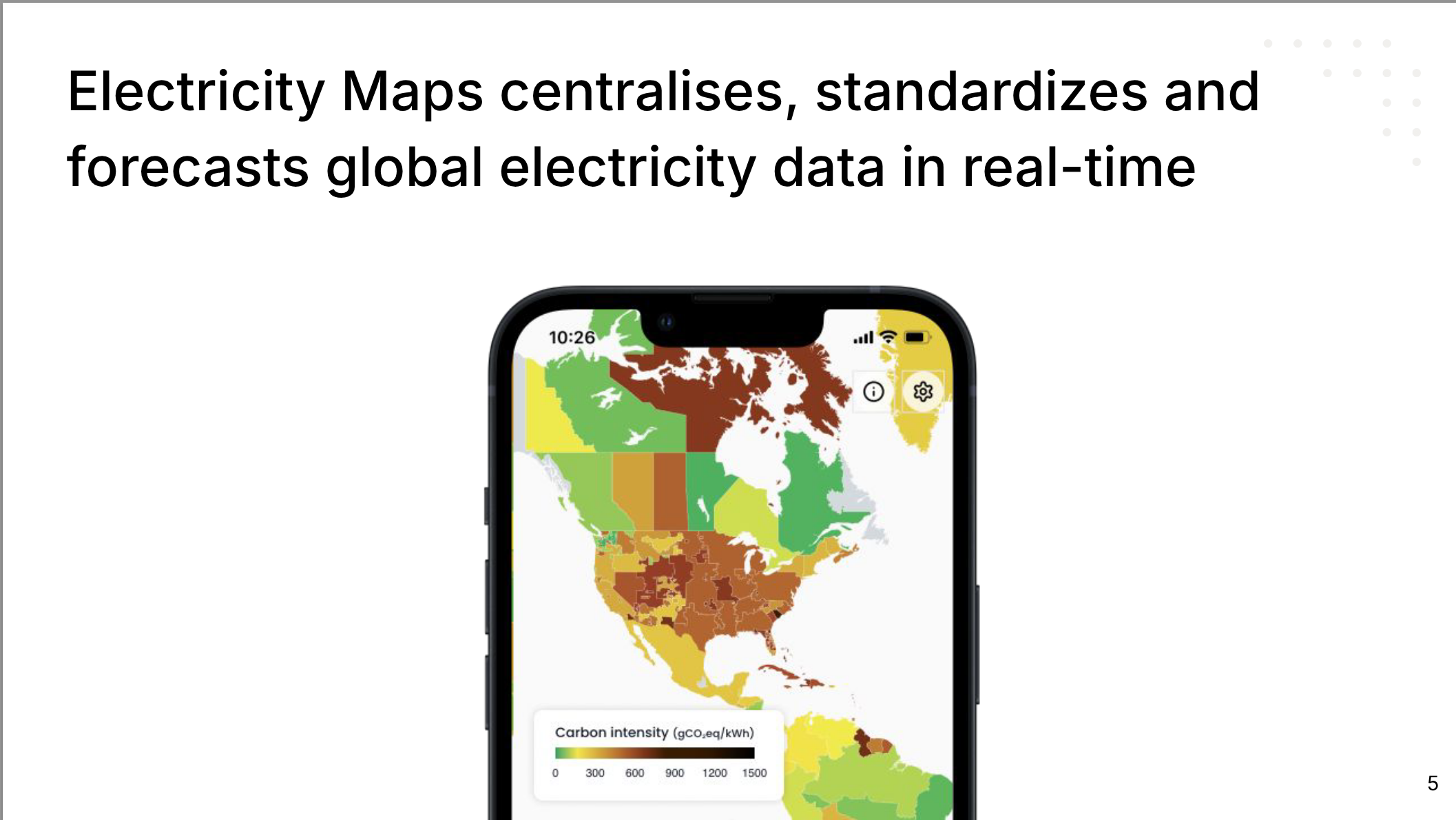
Electricity Maps centralises, standardizes and forecasts global electricity data in real-time
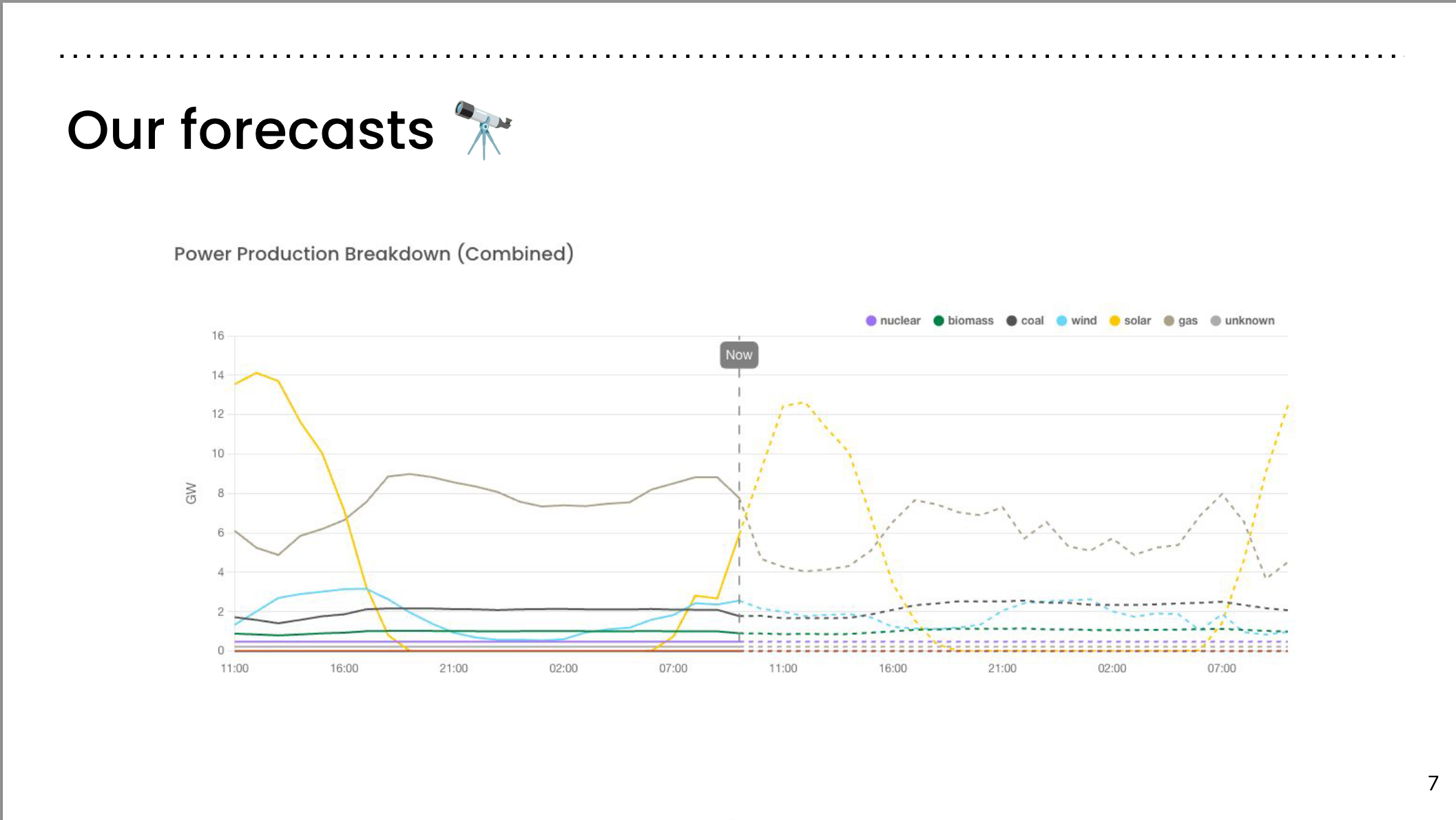
Our forecasts
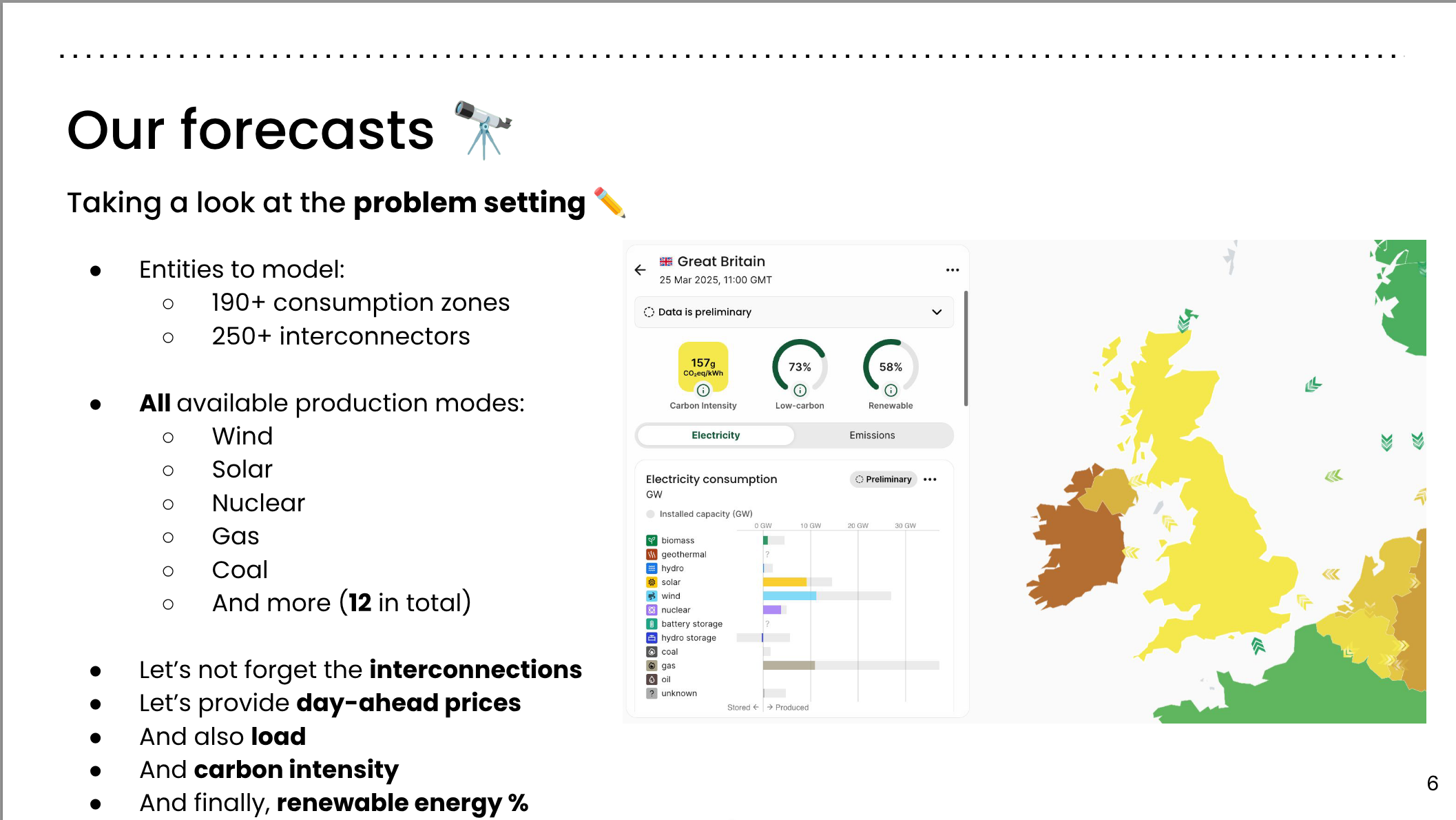
Taking a look at the problem setting ✏️
- Entities to model:
- 190+ consumption zones
- 250+ interconnectors
- All available production modes:
- Wind
- Solar
- Nuclear
- Gas
- Coal
- And more (12 in total)
- Let’s not forget the interconnections
- Let’s provide day-ahead prices
- And also load
- And carbon intensity
- And finally, renewable energy %
Our forecasts
The features behind our forecasts: Stateful time series features
Target Time: 2025-12-03 13:00:00
Reference Time: 2025-12-01 13:00:00
Target Time: 2025-12-03 13:00:00
Reference Time: 2025-12-02 13:00:00

Why we need a feature store
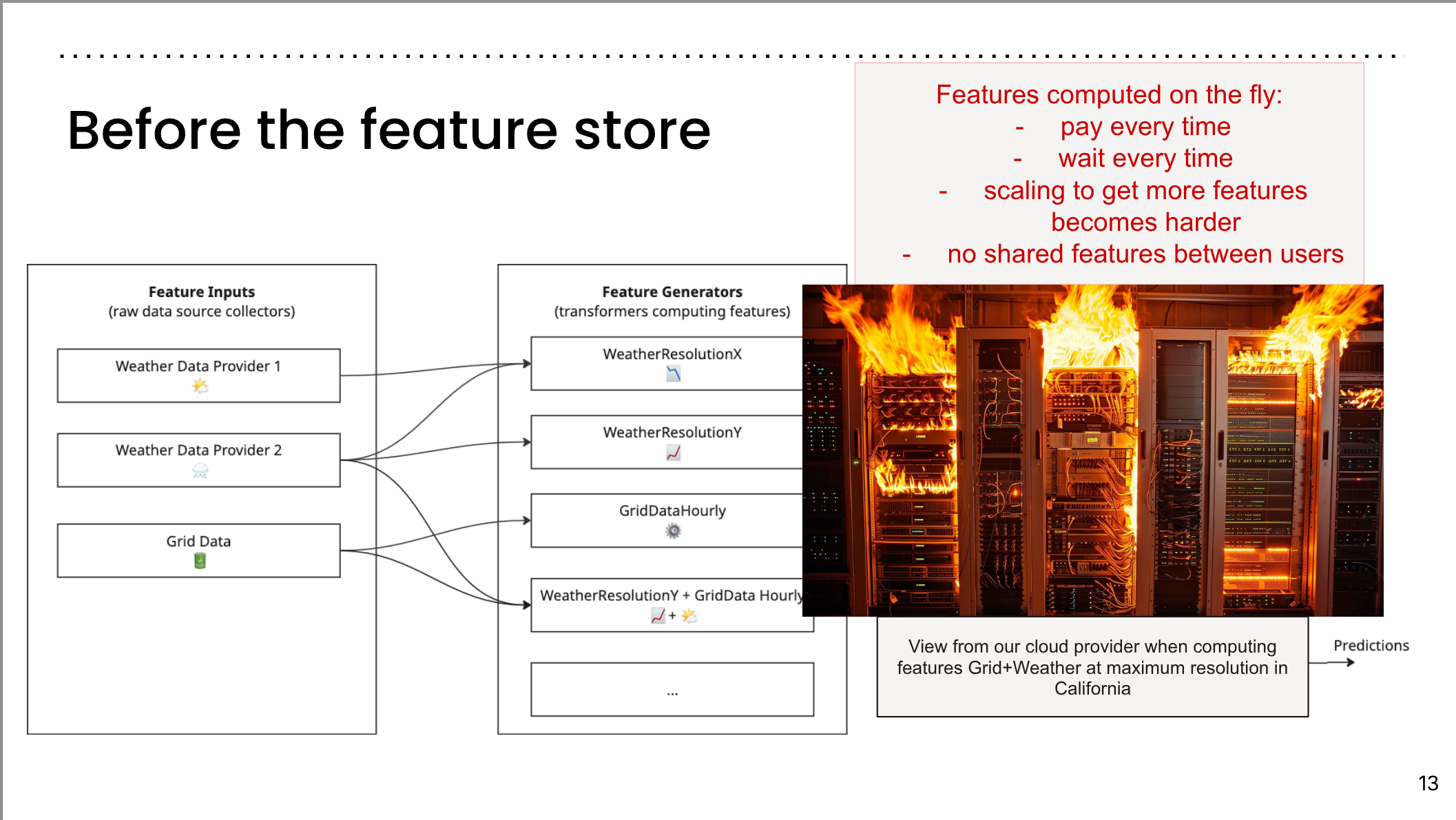
Before the feature store I
- pay every time they run a forecast
- wait every time they want to run a forecast
- doesn’t scale with the number of features.
- no shared features across users.
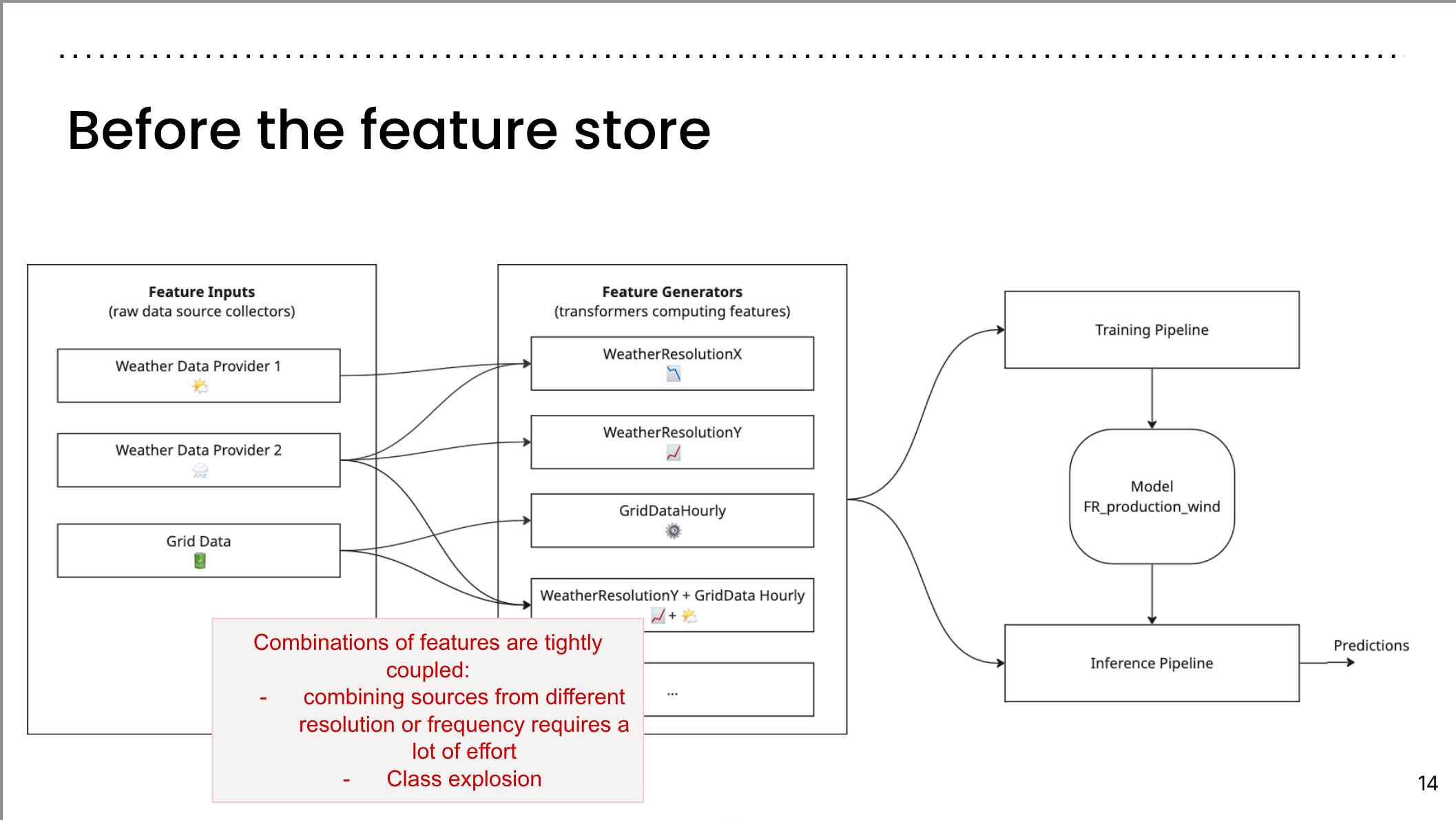
Before the feature store II
- combos of features are tightly coupled
- combining features from different scales is very hard
- combinatorial class number explosion …
Before the feature store III
- 🐢 Experimentation is slow: building a new combination of features + computing ~days.
- 🔥 Cloud costs are exploding the more we scale our forecast systems to train on longer horizons and on longer training sets (yearly).
- 😡 A lot of frustration with memory errors due to memory spikes and large parquet files that can’t load (30GB for a single zone).

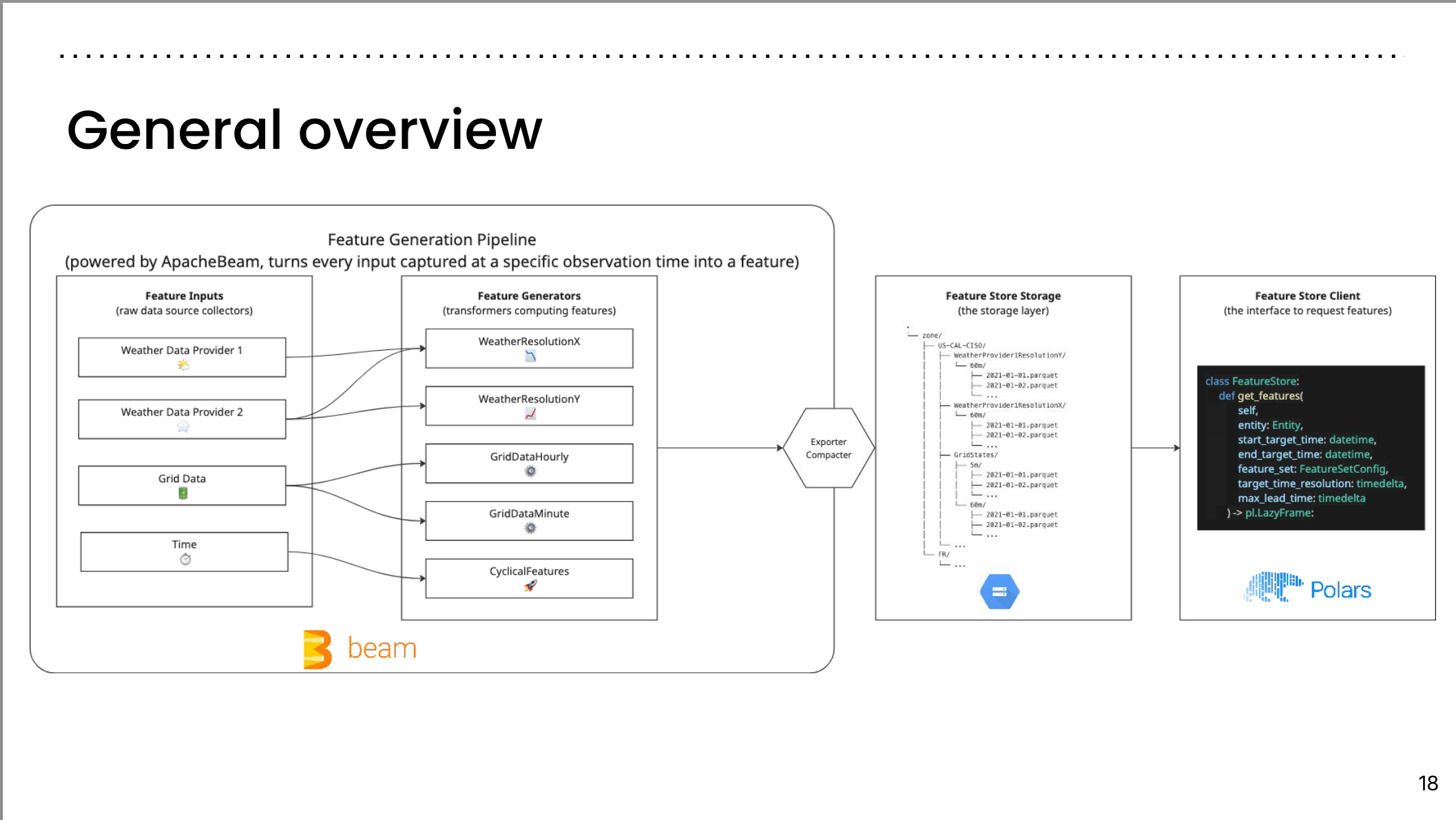
Powering the Feature Store: GCS and Polars

General Overview
Lazy Queries

The Querying process
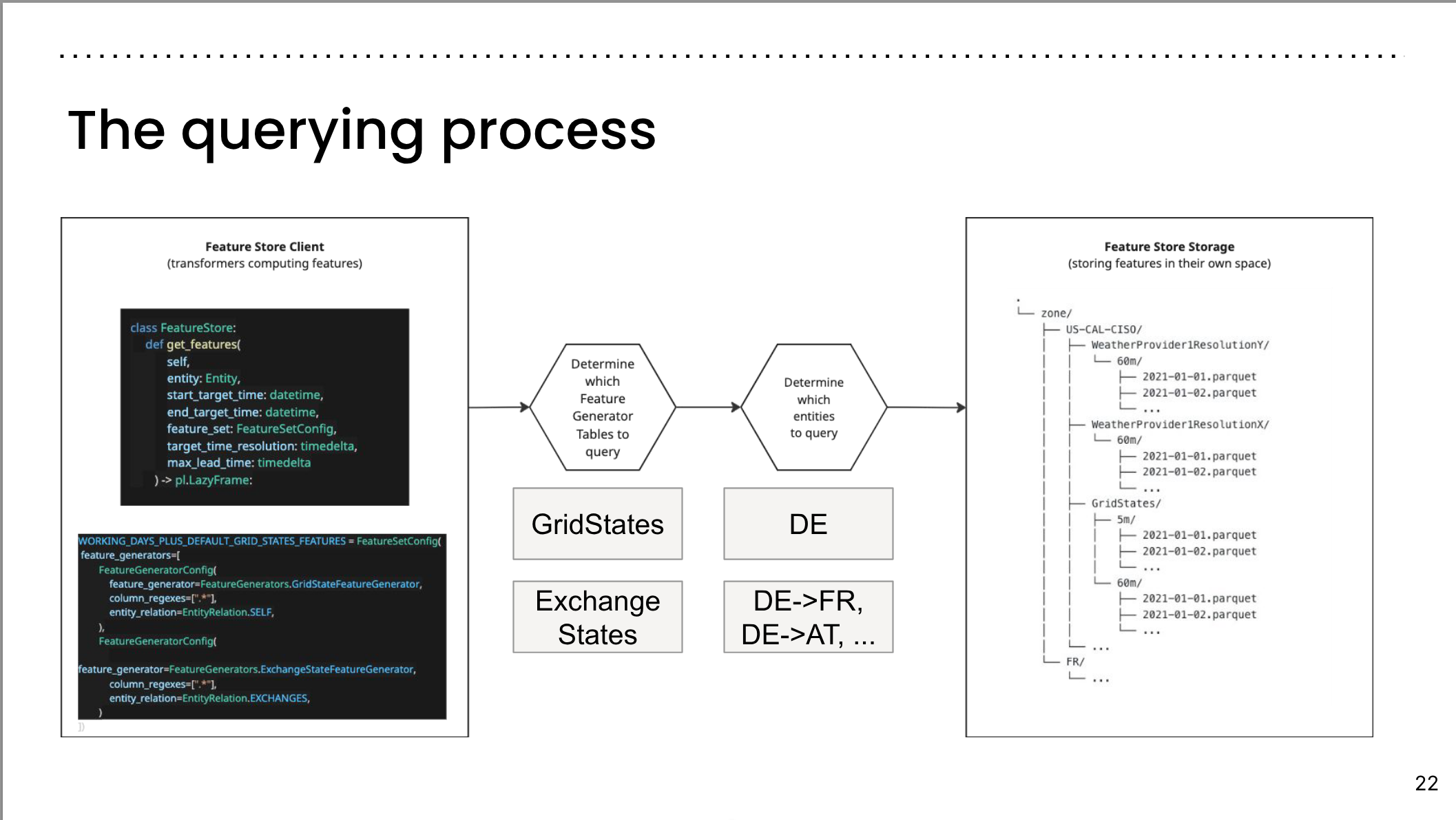
Lazy read query

Aligning time dimensions
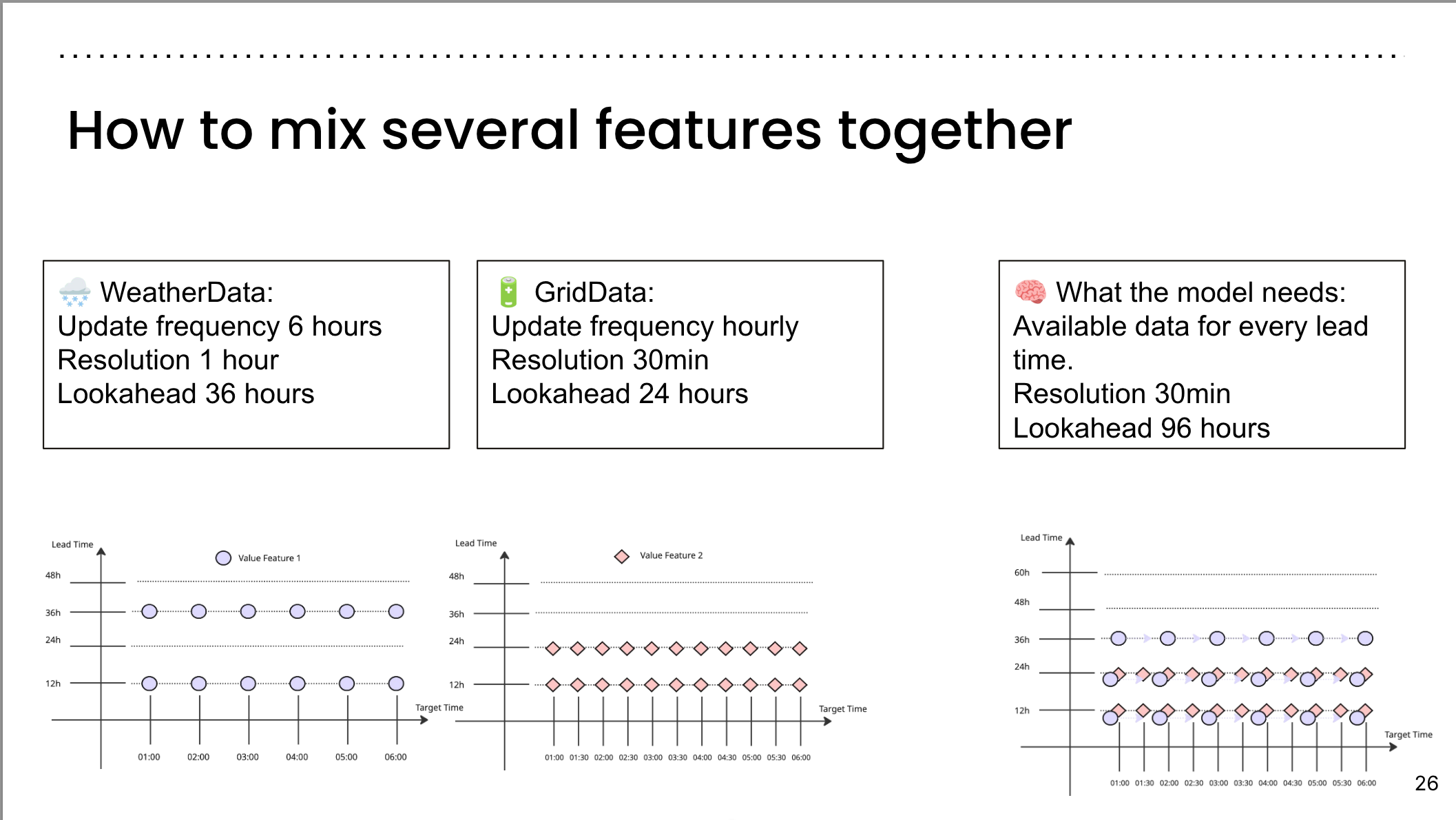
How to mix several features together?
- 🌧️ WeatherData:
- Update frequency 6 hours
- Resolution 1 hour
- Lookahead 36 hours
- 🔋 GridData:
- Update frequency hourly
- Resolution 30min
- Lookahead 24 hours
- 🧠 What the model needs:
- Available data for every lead time
- Resolution 30min
- Lookahead 96 hours
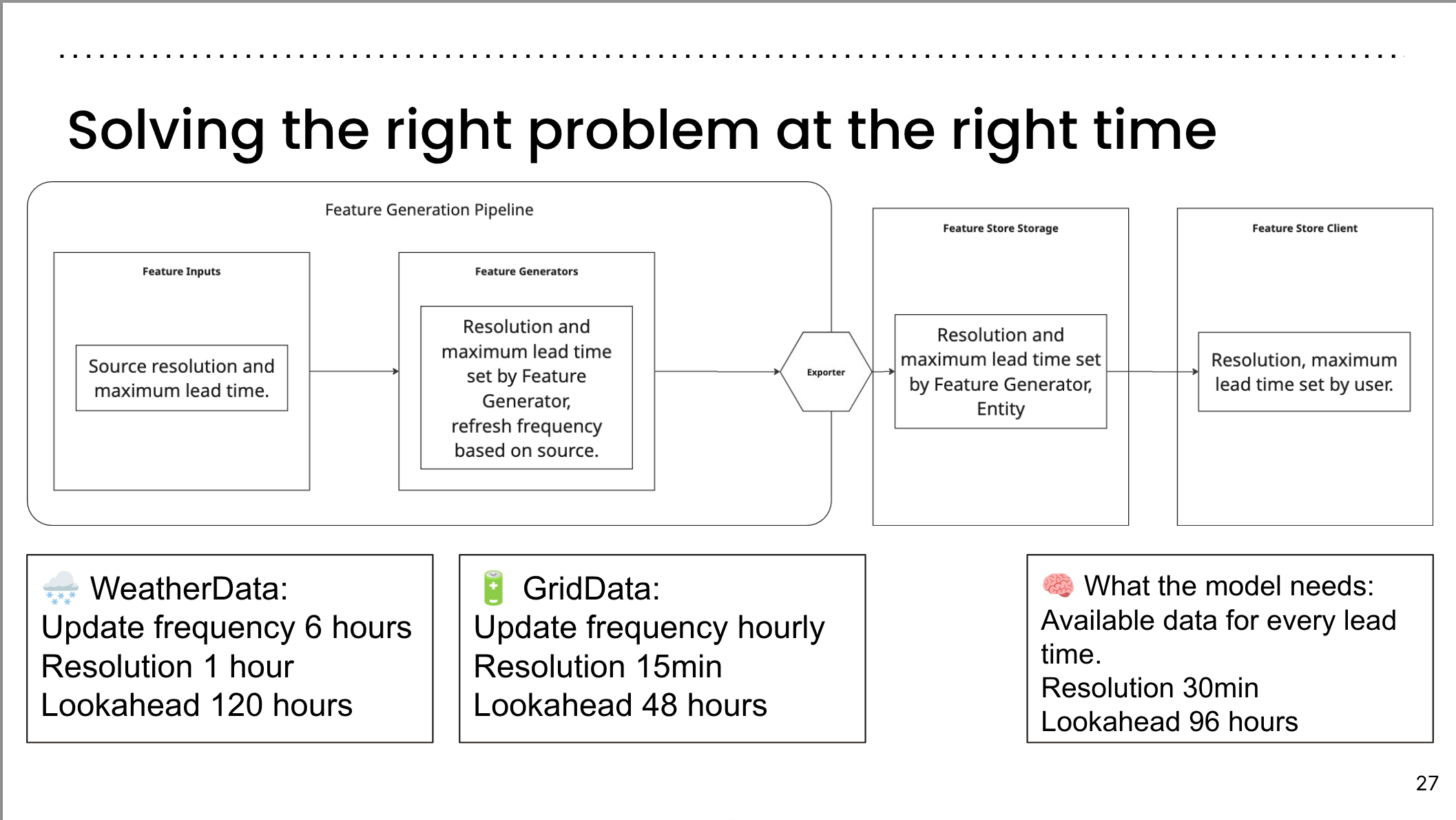
Solving the right problem at the right time
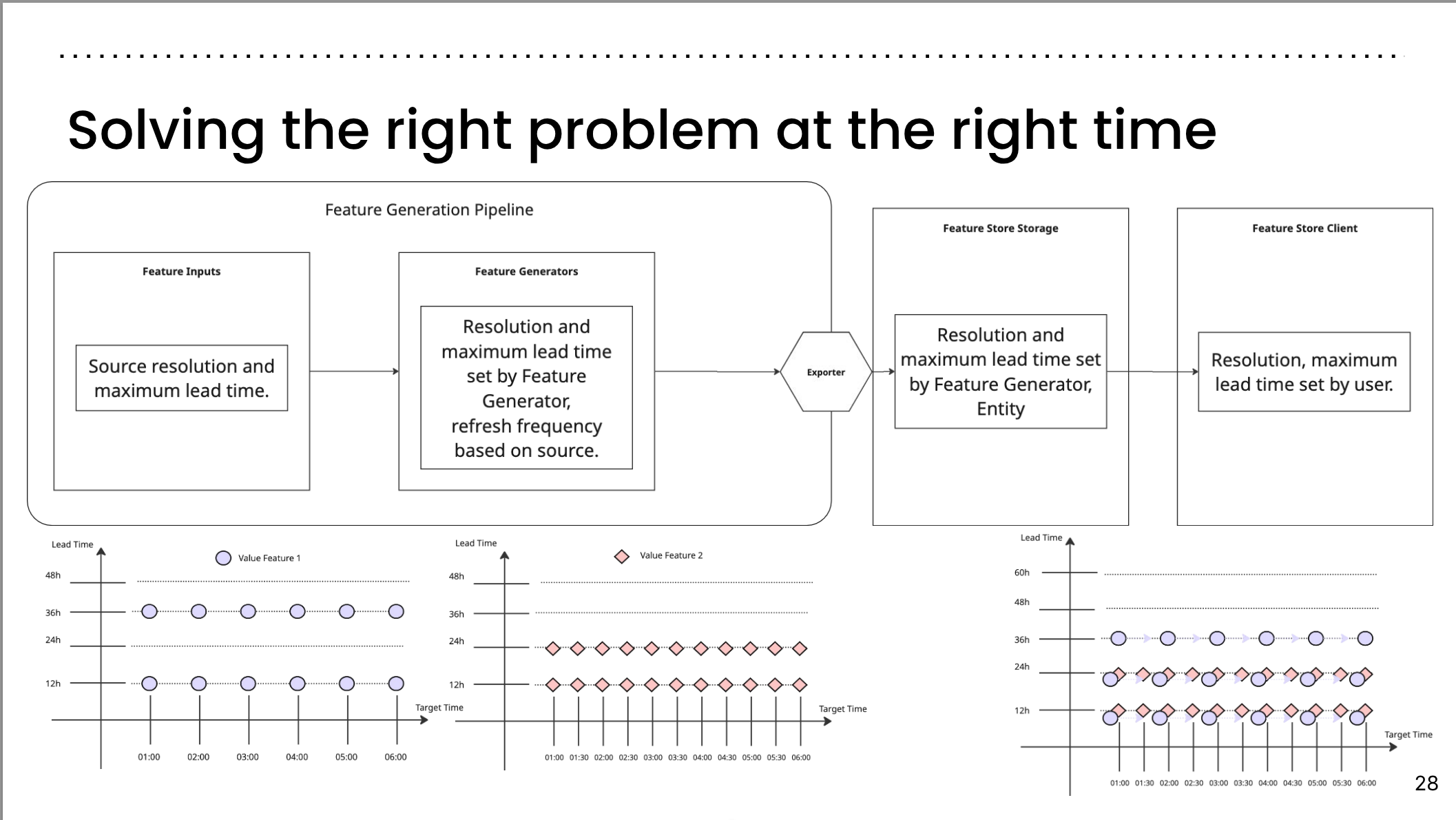
Feature Generation Pipeline:
- Feature Inputs: Source resolution and maximum lead time.
- Feature Generators: Resolution and maximum lead time set by Feature Generator, refresh frequency based on source.
- Feature Store Storage: Resolution and maximum lead time set by Feature Generator, Entity.
- Feature Store Client: Resolution, maximum lead time set by user.
Examples:
- 🌧️ WeatherData:
- Update frequency: 6 hours
- Resolution: 1 hour
- Lookahead: 120 hours
- 🔋 GridData:
- Update frequency: Hourly
- Resolution: 15 minutes
- Lookahead: 48 hours
- 🧠 What the model needs:
- Available data for every lead time
- Resolution: 30 minutes
- Lookahead: 96 hours
Solving the right problem at the right time II
Binding everything together
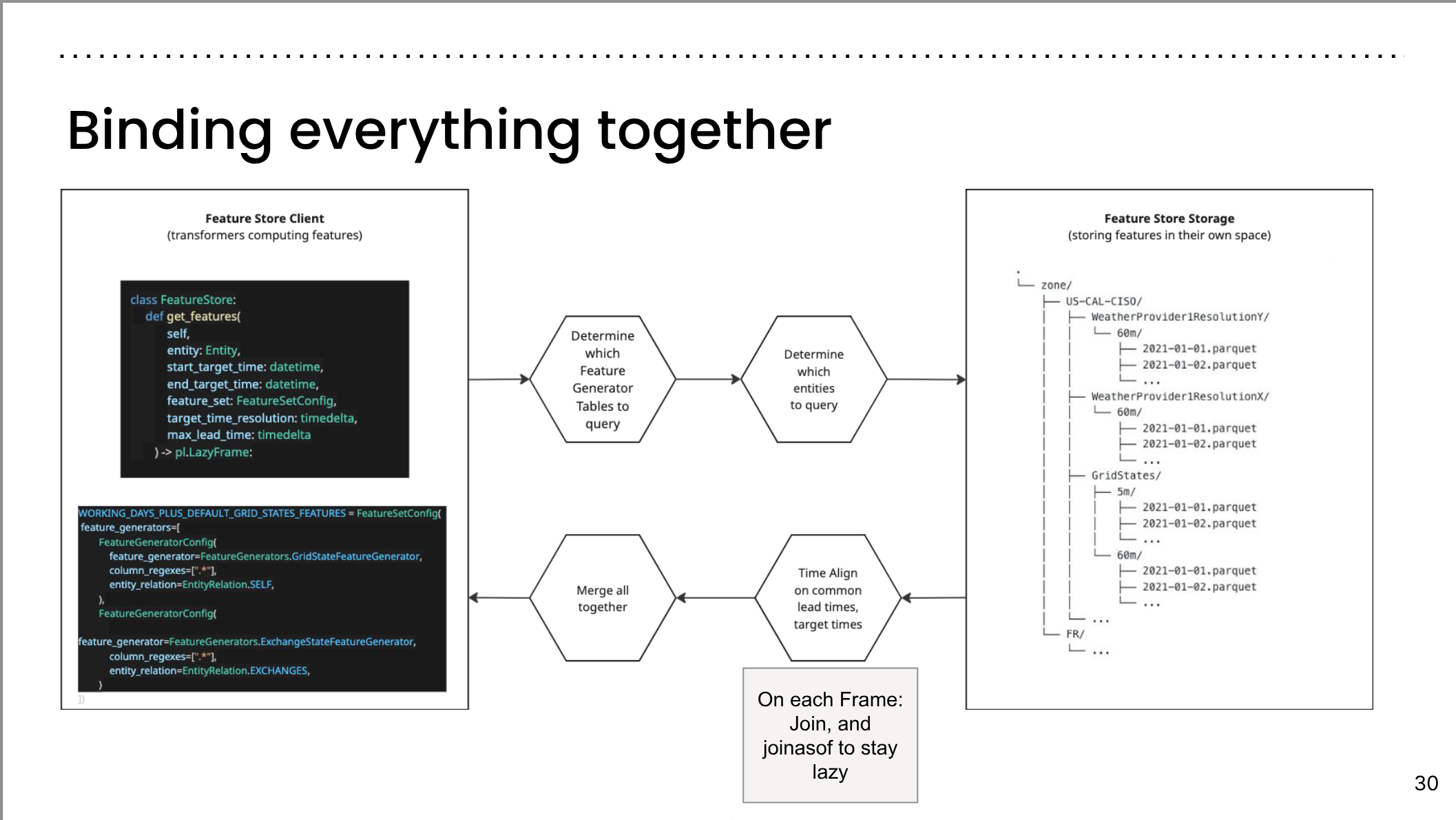
Binding everything together II
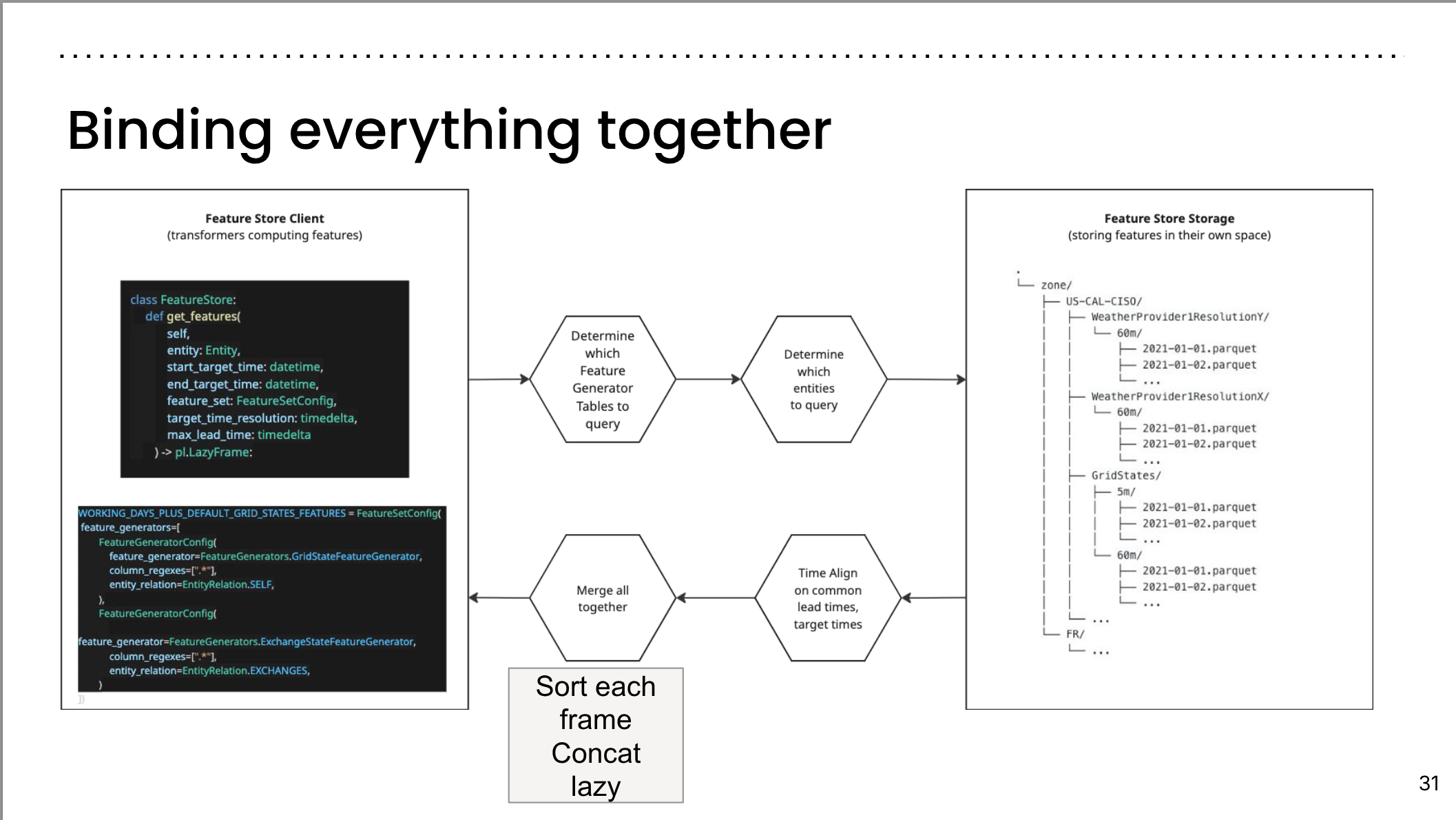
Binding everything together III
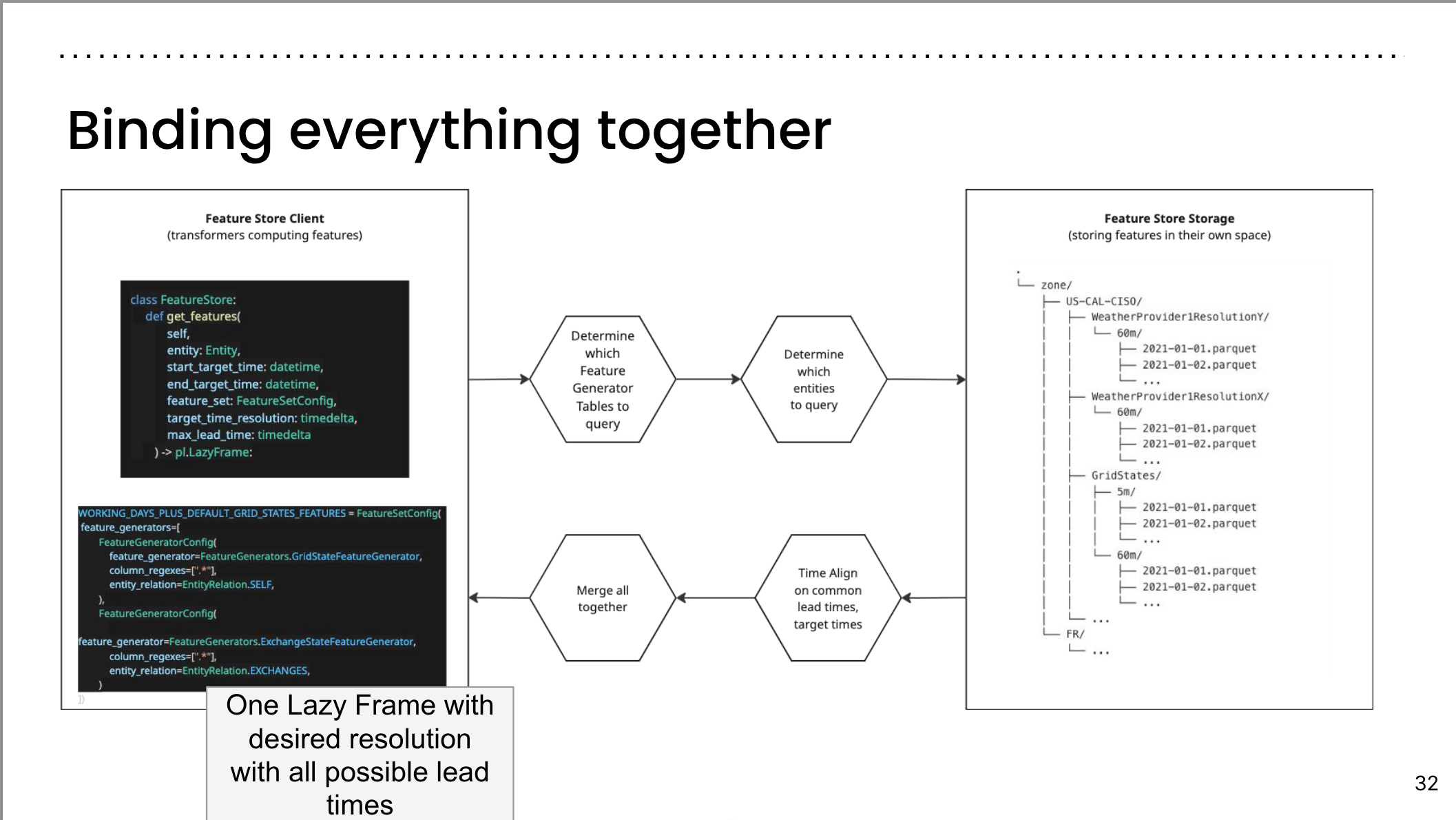
Slide 28

Slide 29

Slide 30
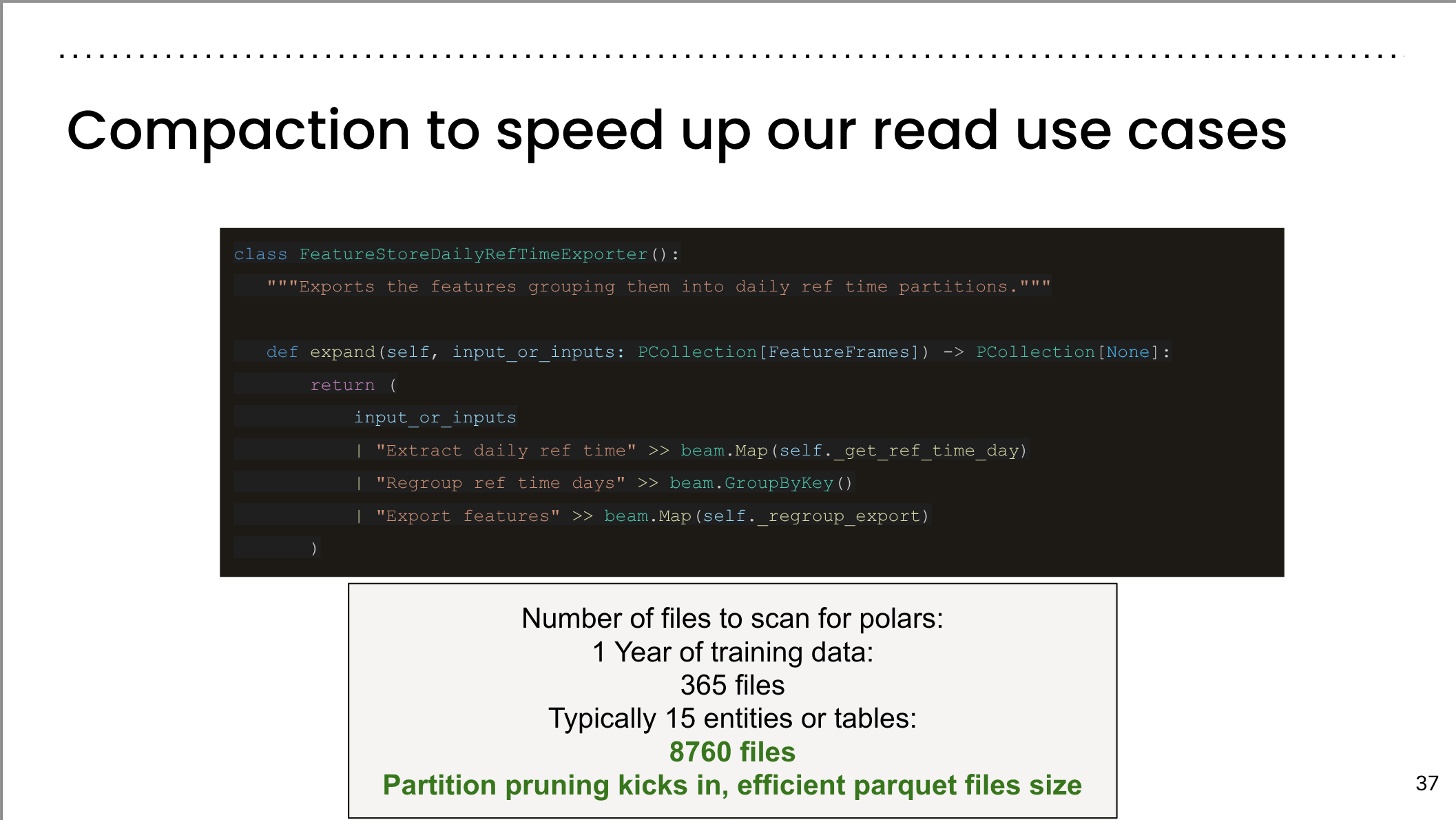
Slide 31

Slide 32

Slide 33

Slide 34

Slide 35

THank You + Contact
Reflections
People often say that data science is 90% data cleaning and 10% modeling.
This war story is a great example of this. The only time we heard about data science was when we talked about the feature aggregation. P.s. this should be a one liner.
However for the one liner to actually work they had to iterate and do some data engineering work. The data engineering is trivial from a data science perspective however it takes a lot of time and effort to get it right. And data scientist are not dev ops. So there are often a few iterations.
Another well known secret is even when it comes together the client etc will change thier api, data scheme or requirements and you have to iterate again.
Citation
@online{bochman2025,
author = {Bochman, Oren},
title = {Building a {Lightweight} {Feature} {Store} for {Electricity}
{Grid} {Forecasts} with {Polars}},
date = {2025-12-12},
url = {https://orenbochman.github.io/posts/2025/2025-12-11-pydata-lightweight-feat-store/},
langid = {en}
}