![]()
The zarr-python 3.0 release includes native support for device buffers, enabling Zarr workloads to run on compute accelerators like NVIDIA GPUs. This enables you to get more work done faster.
This talk is primarily intended for people who are at least somewhat familiar with Zarr and are curious about accelerating their n-dimensional array workload with GPUs. That said, we will start with a brief introduction to Zarr and why you might want to consider it as a storage format for the n-dimensional arrays (commonly seen in geospatial, microscopy, or genomics domains, among others). We’ll see what factors affect performance and how to maximize throughput for your data analysis or deep learning pipeline. Finally, we’ll preview the future improvements to GPU-accelerated Zarr and the packages building on top of it, like xarray and cubed.
After attending this talk, you’ll have the knowledge needed to determine if using zarr-python’s support for device buffers can help accelerate your workload.
This talk is targeted at users who have at least heard of zarr, but we will give a brief introduction of the basics. The primary purpose is to spread knowledge about zarr-python’s recently added support for device (GPU) buffers and arrays, and how it can be used to speed up your array-based workload.
We will introduce you to certain modern frameworks in the workshop but the emphasis be on first principles and using vanilla Python and LLM calls to build AI-powered systems.
Tom Augspurger
Tom Augspurger is a software engineer at NVIDIA working on GPU-accelerated ETL tools as part of the RAPIDS team. He has helped maintain several libraries in the scientific python and geospatial stacks.
- Contact:
Outline
- Introduction
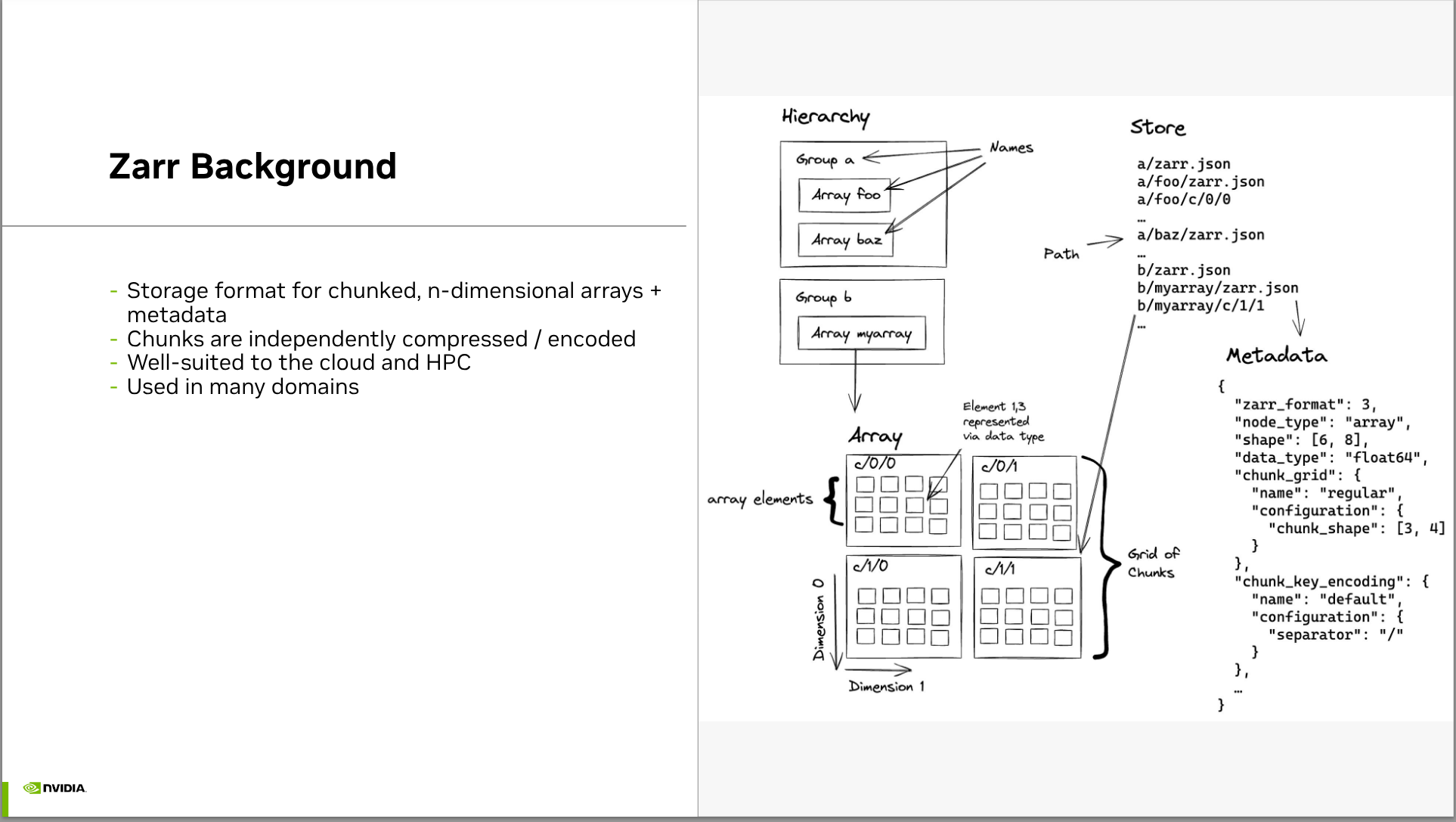
- Brief overview of zarr (cloud-native format for storing chunked, n-dimensional arrays)
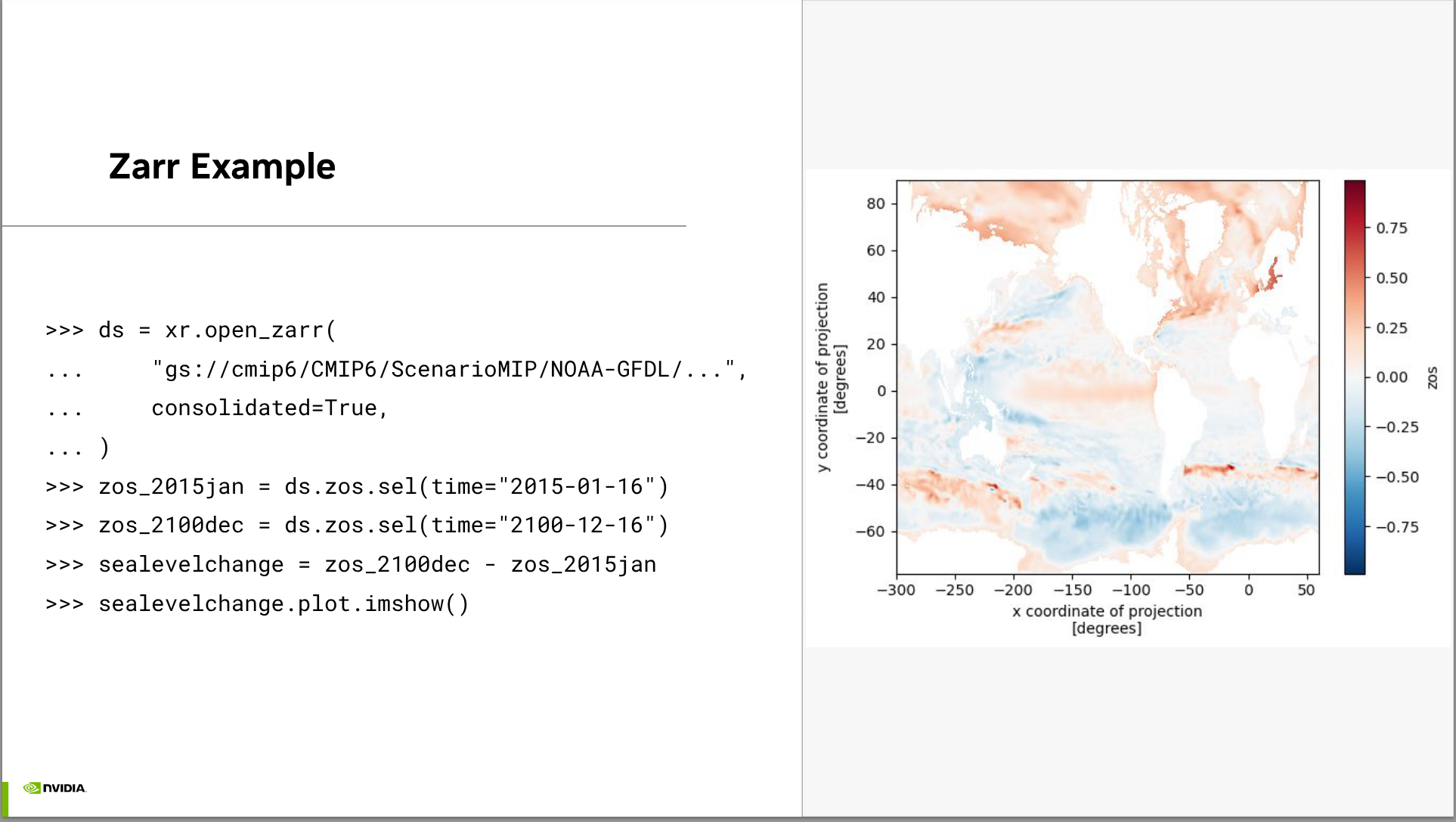
- Brief example of how easy it is to use zarr-python’s native support for device arrays
- Overview of GPU-accelerated Zarr workloads
- We’ll some high-level examples of how Zarr fits into larger workloads (e.g. analyzing climate simulations, as part of a deep learning pipeline)
- We’ll discuss the key factors to think about when trying to maximize performance
- Overview of how it works
- Show zarr’s configuration options for selecting between host and device buffers
- An overview of the Zarr codec pipeline
- Show how on-device decompression can be used, to accelerate decompression if that’s a bottleneck in your workload
- Benchmarks showing the speedup users can expect to see from GPU acceleration
- Preview of future work
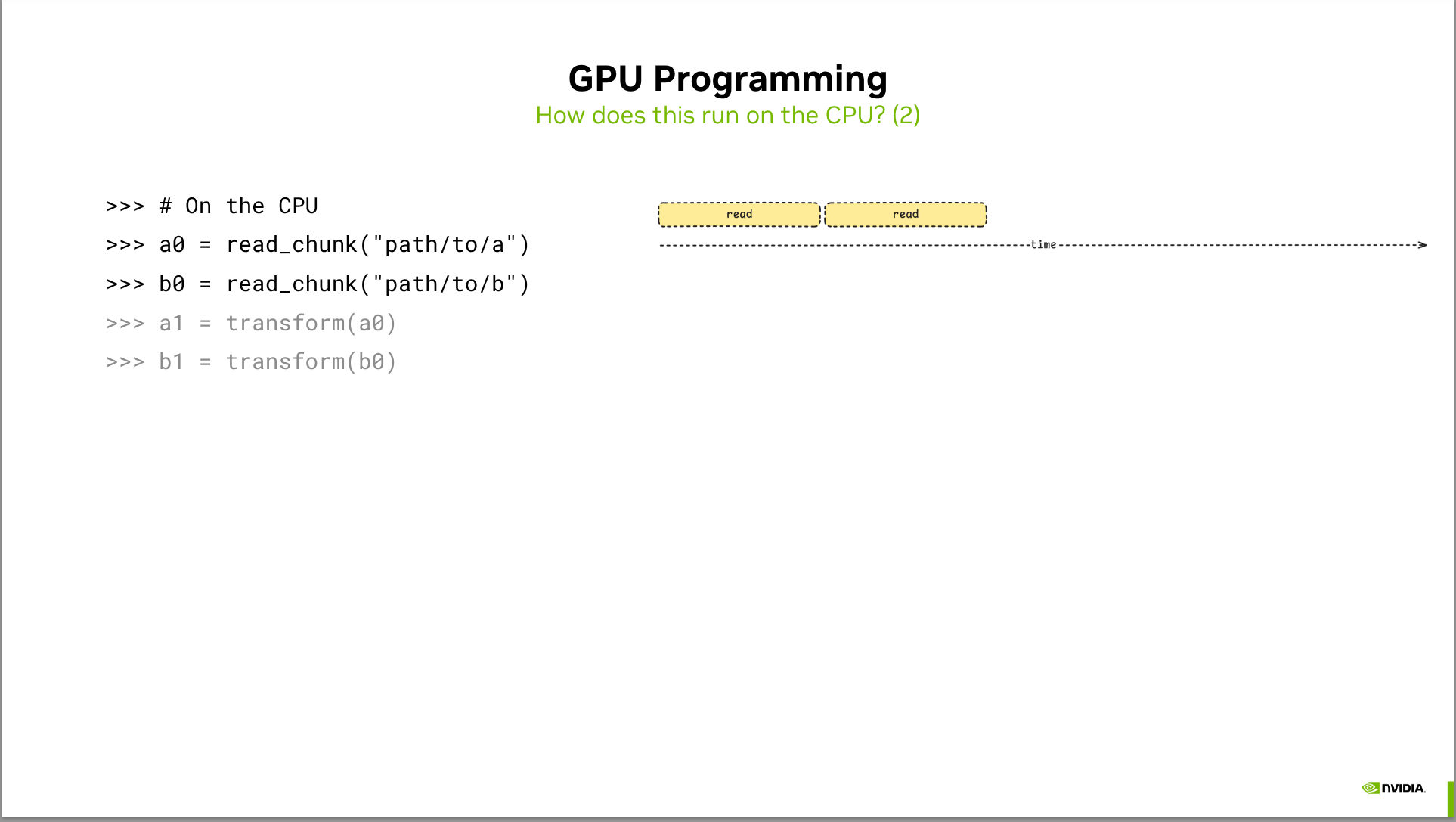
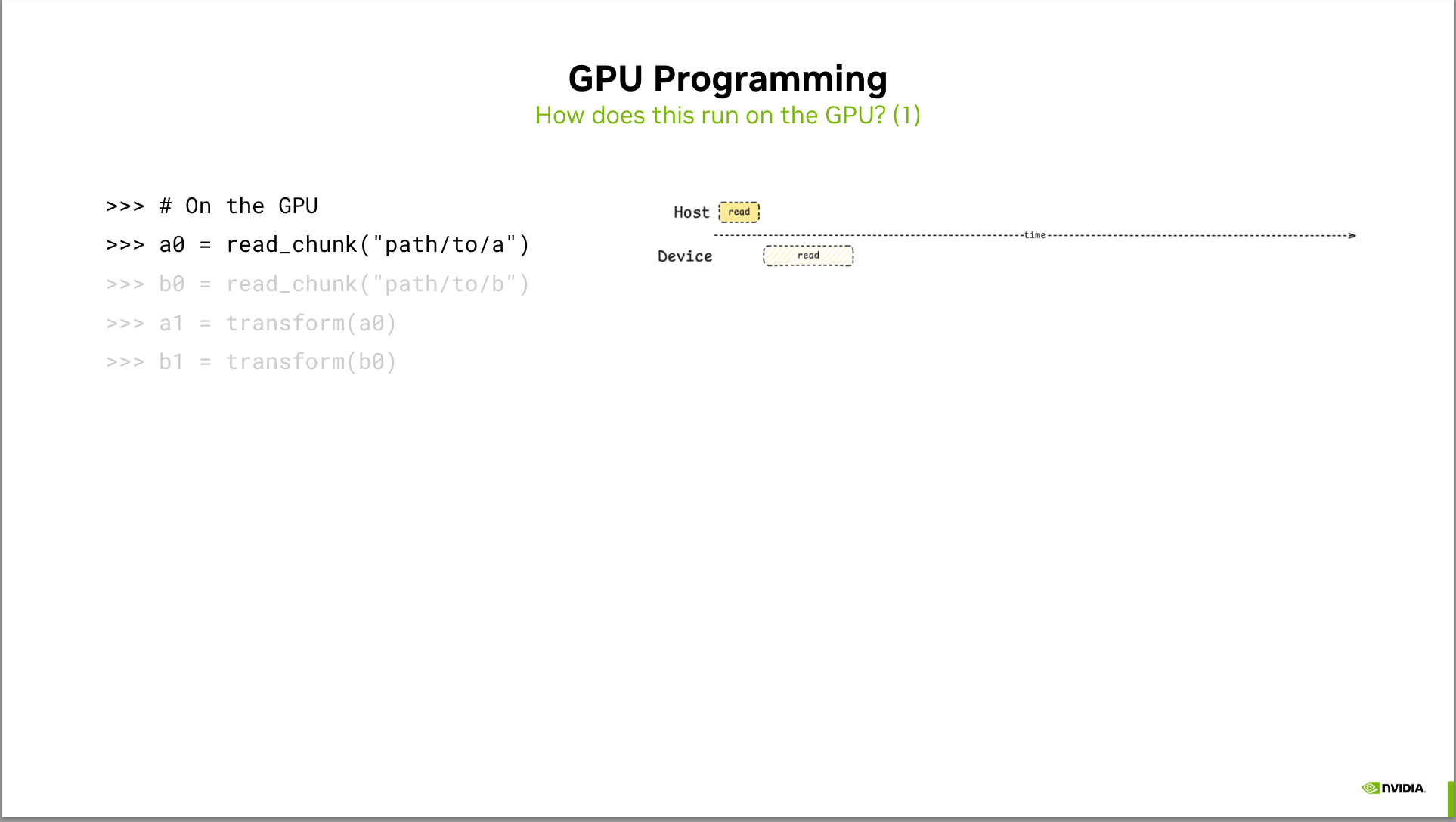
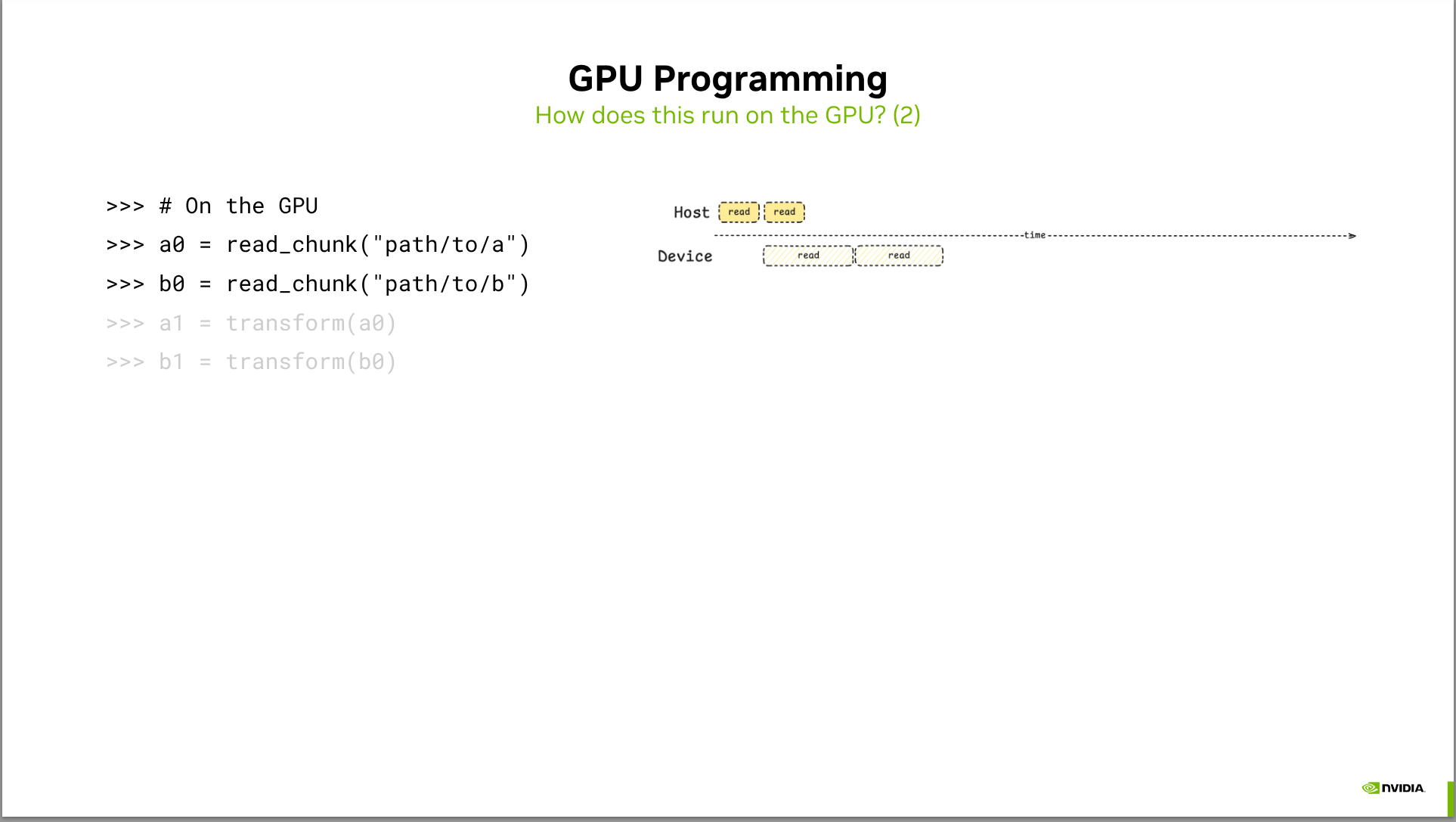
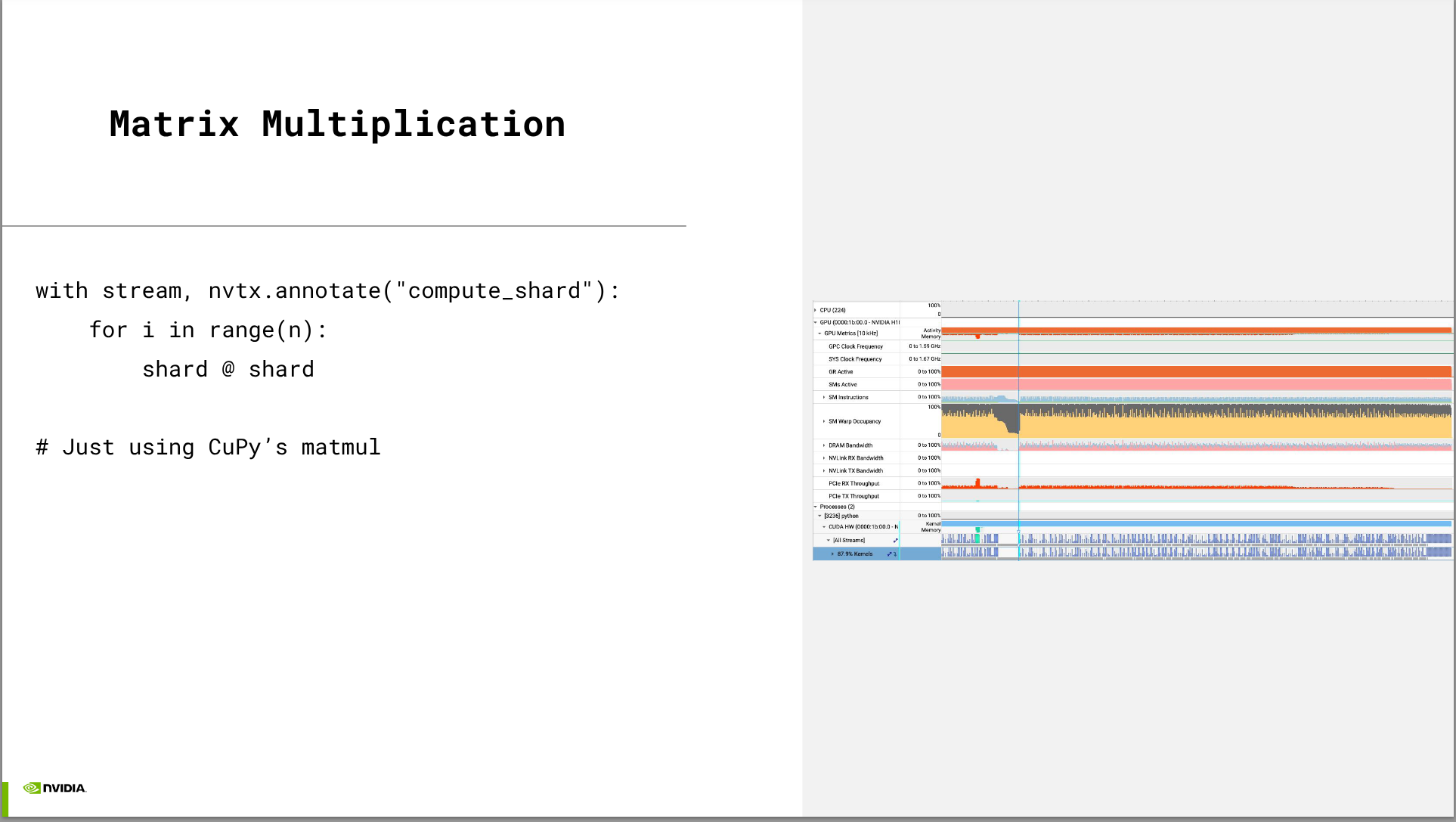
- Zarr-python currently only uses a single GPU, and doesn’t use any features like CUDA Streams. https://github.com/zarr-developers/zarr-python/issues/3271 tracks possible improvements for exposing additional parallelism.
- We’ll look at a prototype of how CUDA streams enable asynchronous host-to-device memory copies, enabling you to start computing on one chunk of data while another chunk is being copied to the device.




















Reflections
The main point is that Zarr now supports GPU device buffers, enabling accelerated workloads on NVIDIA GPUs. The talk covers the basics of Zarr, performance factors, and future improvements.
I did not really know about Zarr before this talk, so it was a great introduction to the format and its benefits for n-dimensional array storage. The explanation of how GPU acceleration works with Zarr was clear and informative.
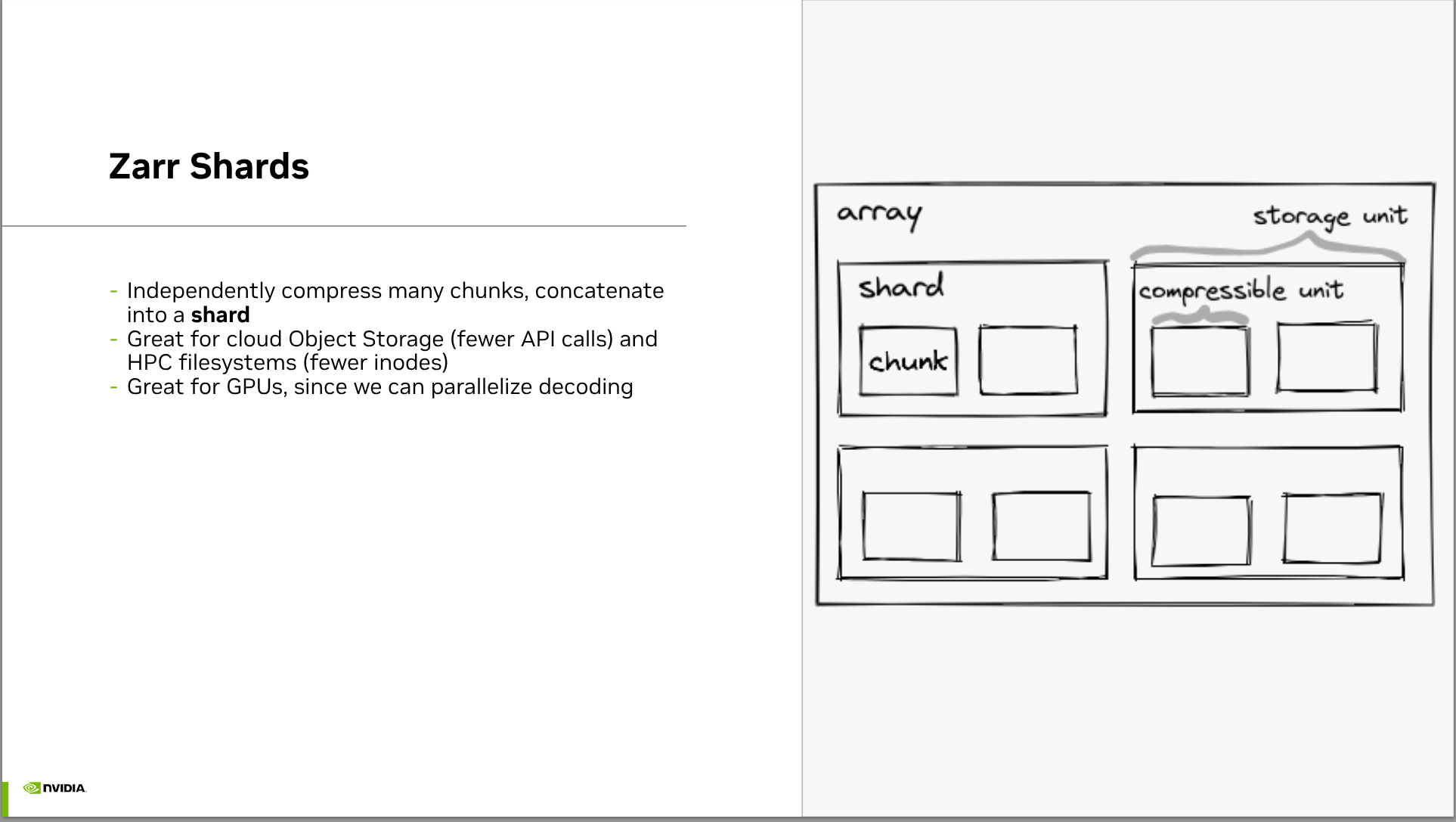
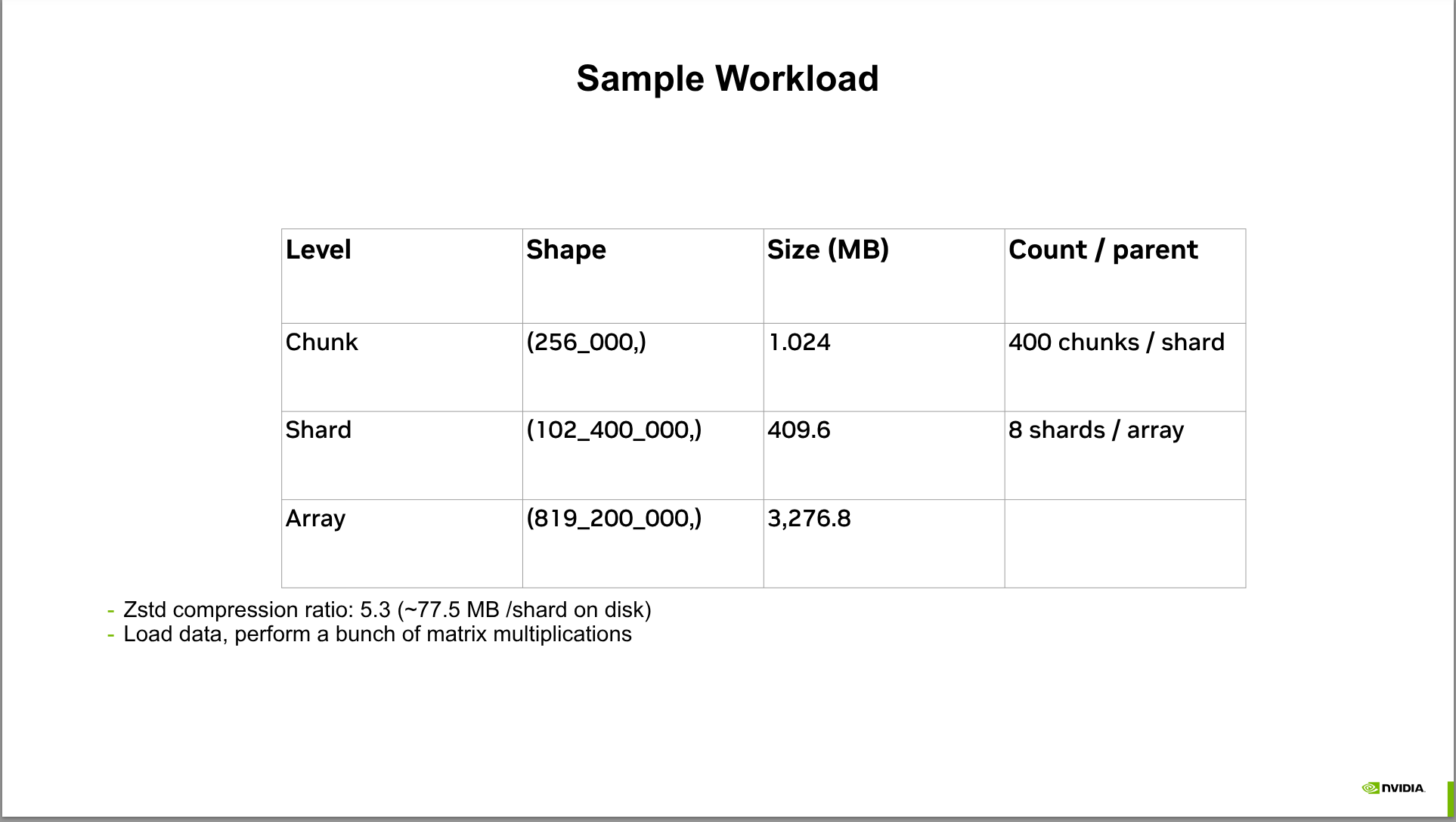
A quick breakdown is that n-dimensional arrays are common abstraction, similar to NumPy arrays but designed for larger datasets that don’t fit in memory. Zarr allows chunked storage of these arrays. Sharding allows putting chunks into different files to facilitate parallel access. Sharding is familiar from formats like HDF5 and TIFF but also from Lucene’s index files where search indices can then be searched in parallel and the results merged and ranked.
Tom does a great job of breaking down complex concepts into digestible pieces. The visual aids and step-by-step explanations really help in understanding how transformers work under the hood.
I particularly appreciated the focus on common pitfalls and debugging strategies, as these are often overlooked in more theoretical presentations.
Note: while I reproduced the slide decks this talk is highly technical and challenging to understand and summarize in the first viewing.
The best way to dive deeper is to check out the blog post where Tom has a great writeup with code examples: https://tomaugspurger.net/posts/gpu-accelerated-zarr/
I hope to revisit and review this talk again in the near future after I have had more time to digest the material and find a suitable project to apply these concepts.
I think a that large scale geo-temporal model of demand might be a good fit for Zarr and GPU acceleration.
Note: that blosc_2 is a fast compression codec that works well with GPU acceleration and can be used with zarr-python.
Resources
Packages and Documentation:
- Zarr-Python¶
- Icechunk Package
- Xarray
- Quick start guide: Getting Started with Zarr on GPUs
- Virtualizarr - Zarr on Virtual Devices
Blog Posts & Presentations:
The Beauty of Zarr an introduction by Sanket Verma
Citation
@online{bochman2025,
author = {Bochman, Oren},
title = {GPU {Accelerated} {Zarr}},
date = {2025-12-12},
url = {https://orenbochman.github.io/posts/2025/2025-12-09-pydata-gpu-acc-zarr/},
langid = {en}
}