Scientific Python Ecosystem offers a wide variety of numerical packages, such as NumPy, CuPy, or JAX. One of the domains that also captures a lot of attention in the community is sparse computing.
In this talk, we will present the current landscape of sparse computing in the Python ecosystem and our efforts to revive/expand it.
Our main contributions to the Python ecosystem cover:
- making a novel
Finchsparse tensor compiler and Galley scheduler available for the community, - standardizing various aspects of sparse computing.
We will show how to use the Finch compiler with the PyData/Sparse package and how it outperforms well-established alternatives for multiple kernels, such as [MTTKRP](http://tensor-compiler.org/docs/data_analytics.html) or [SDDMM](http://tensor-compiler.org/docs/machine_learning.html).
Real-world use-cases will show you how, step-by-step, Python practitioners can migrate their code to an Array API compatible version and benefit from tensor operator fusion and autoscheduling capabilities offered by the Finch compiler.
Apart from the existing Julia implementation, the number of sparse backends offered by PyData/Sparse will grow in the future to provide a Python-native alternatives for scipy.sparse and Numba solutions. One of them that is currently under development is finch-tensor-lite, a pure Python rewrite of Finch.jl compiler, meant to make the solution lightweight by dropping Julia runtime dependency while providing the majority of features.
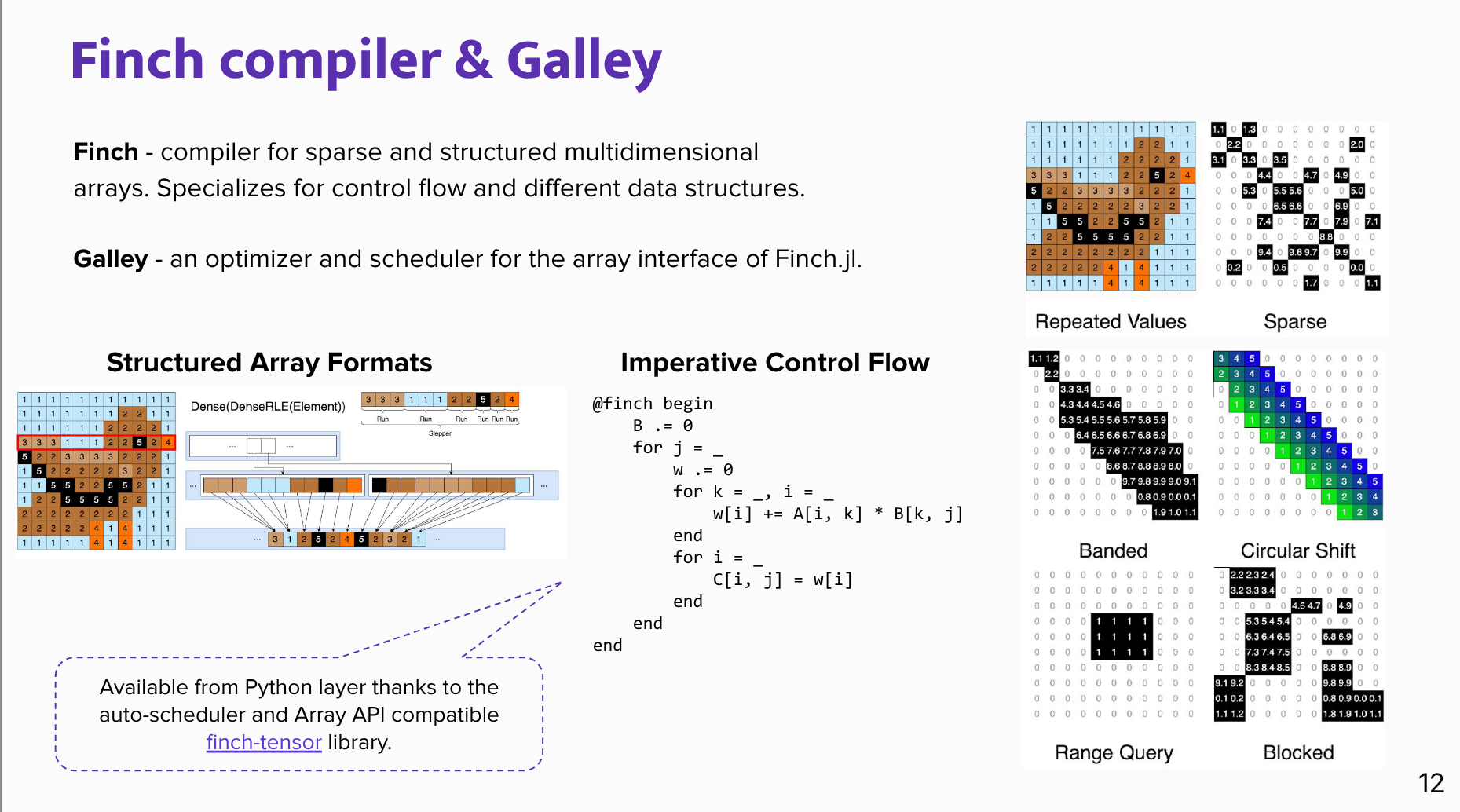
In this talk we’re going to understand the current landscape of sparse computing in the Python ecosystem first. Then a high-level overview of the Finch technology and compiler’s architecture will be presented together with other solutions vital for the project: Array API Standard and binsparse format.
Next, we’re going to present a selected set of benchmarks - also focusing on real world use-cases: how Finch impacts users’ experience when writing sparse programs in Python. Last but not least a showcase of the current development will be shown - pure Python rewrite of Finch compiler.
- Mateusz Sokół
- is a Software Engineer at Quansight, working on multitude of open source projects in the Scientific Python Ecosystem.
- His GitHub profile here: https://github.com/mtsokol
- Willow Marie Ahrens
- is assistant professor in the School of Computer Science at Georgia Tech. She is inspired to make programming high-performance computers more productive, efficient, and accessible. Her research focuses on using compilers to accelerate productive programming languages with state-of-the-art data structures, algorithms, and architectures, bridging the gap between program flexibility and performance. She’s the author of the Finch sparse tensor programming language. Finch supports general programs on general tensor formats, such as sparse, run-length-encoded, banded, or otherwise structured tensors. Please reach out if you are interested in doing research at Georgia Tech!
- talk repo https://sparse.pydata.org/en/stable/
- slide deck
Outline
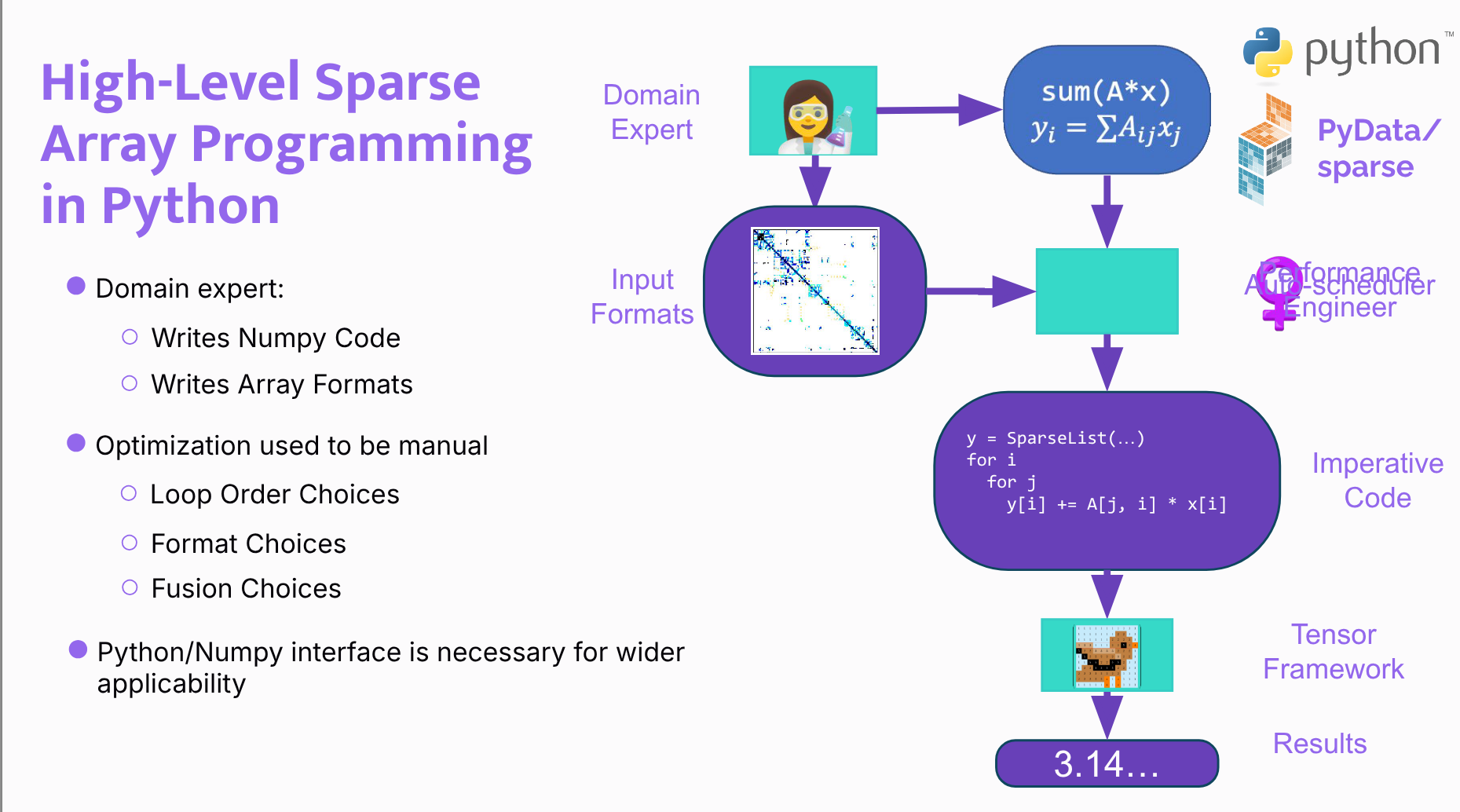
High-level user model:
- Domain users should be able to write NumPy-like array code.
- They should specify whether inputs are dense or sparse, but not manually decide loop order, fusion strategy, or format-specific traversal.
- Finch’s auto-scheduler is meant to replace the human performance engineer in that optimization step.
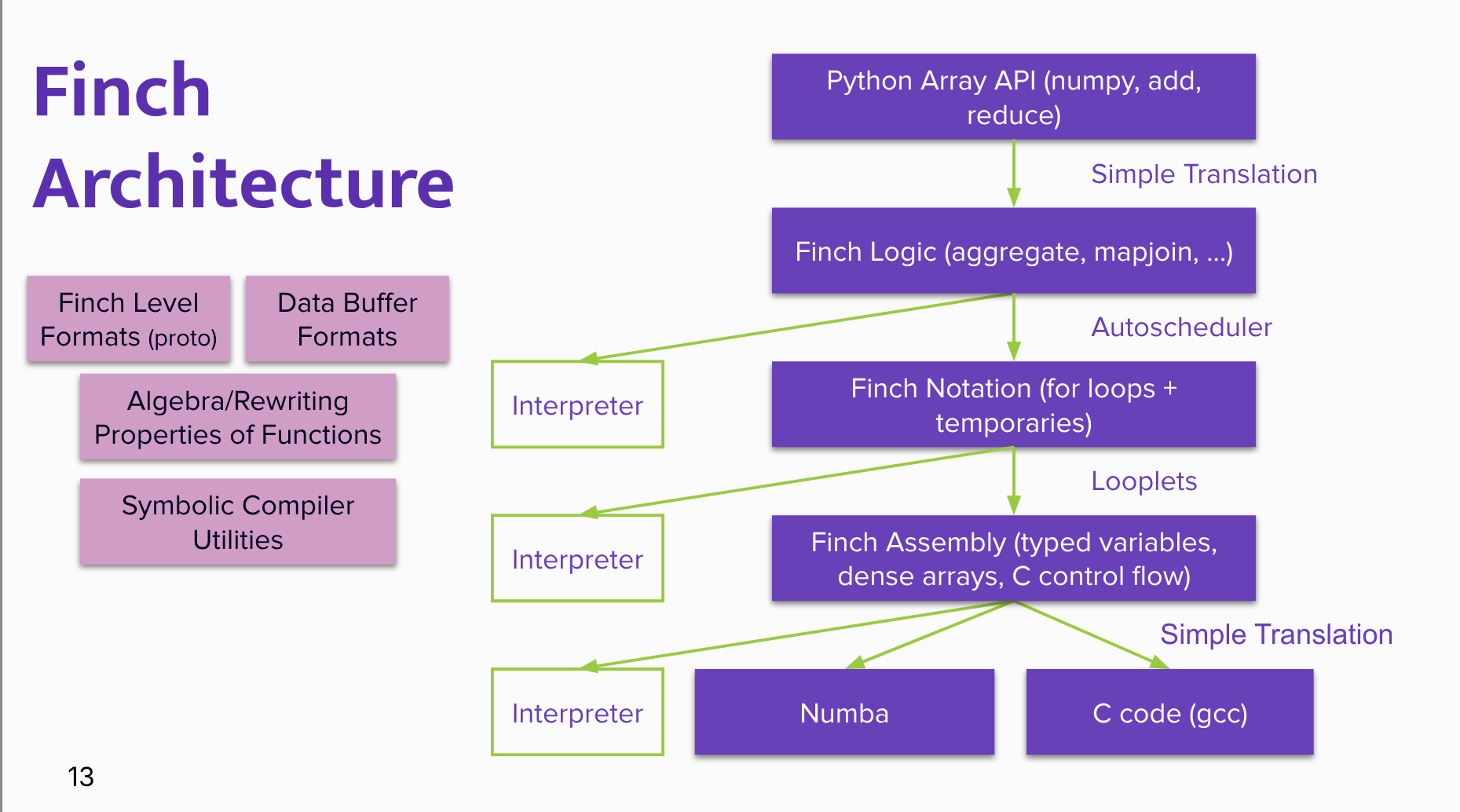
Project architecture:
- The Python-facing layer uses the Array Application Programming Interface standard so code can be written against a common array interface.
- Finch lowers code through several stages: Python Array API → Finch Logic → Finch Notation → Finch Assembly → backend code such as Numba or C.
- The speakers emphasize that each stage has interpreters/tests to validate correctness.
Compilation example:
- The example multiplies two tensors where one input is lower triangular.
- Finch represents the triangular mask in its internal logic.
- During lowering, it generates loops that only traverse the lower triangular part.
- Algebraic simplification then removes useless work, such as multiplying by zero or keeping empty loops.
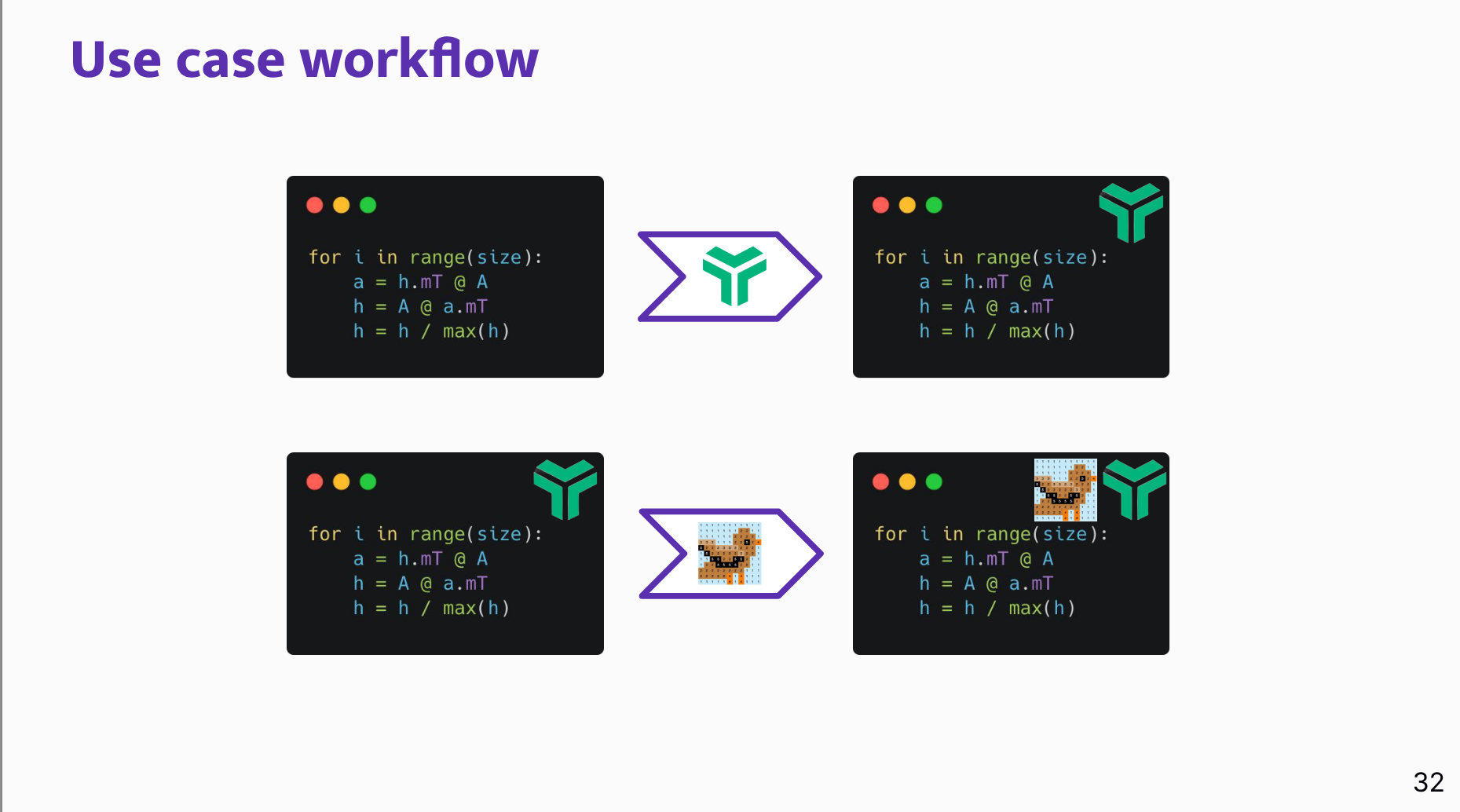
Use-case workflow:
- Start with NumPy-like numerical code.
- Rewrite it to be Array API-compatible.
- Isolate the computationally expensive loop.
- Add a sparse compile decorator and wrap inputs in appropriate tensor formats.
- Finch then Just-in-Time compiles the sparse kernel.
Examples shown:
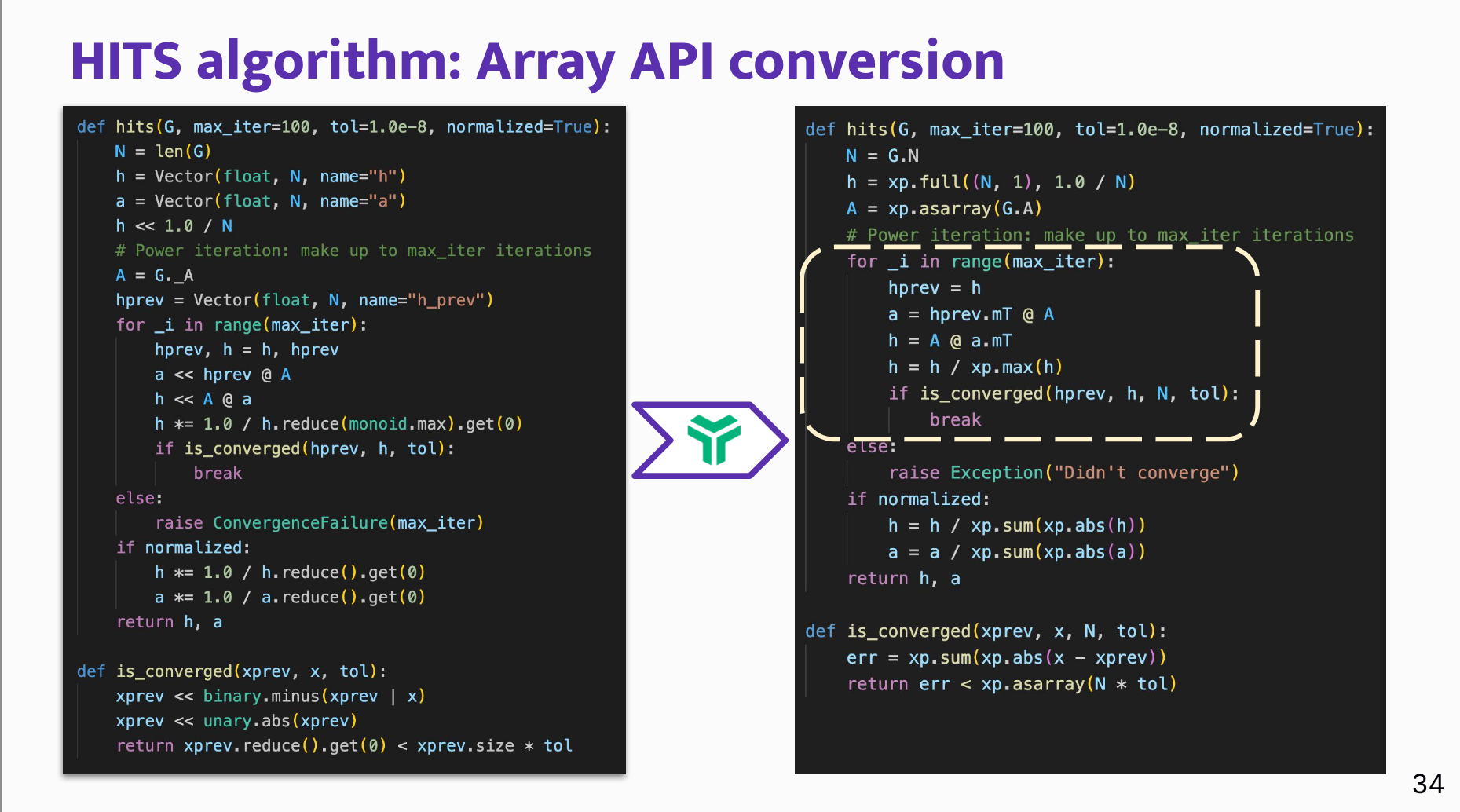
- Hyperlink-Induced Topic Search (HITS): A graph link-analysis algorithm was rewritten from GraphBLAS-style code into Array API-compatible code, then the power-iteration kernel was compiled.
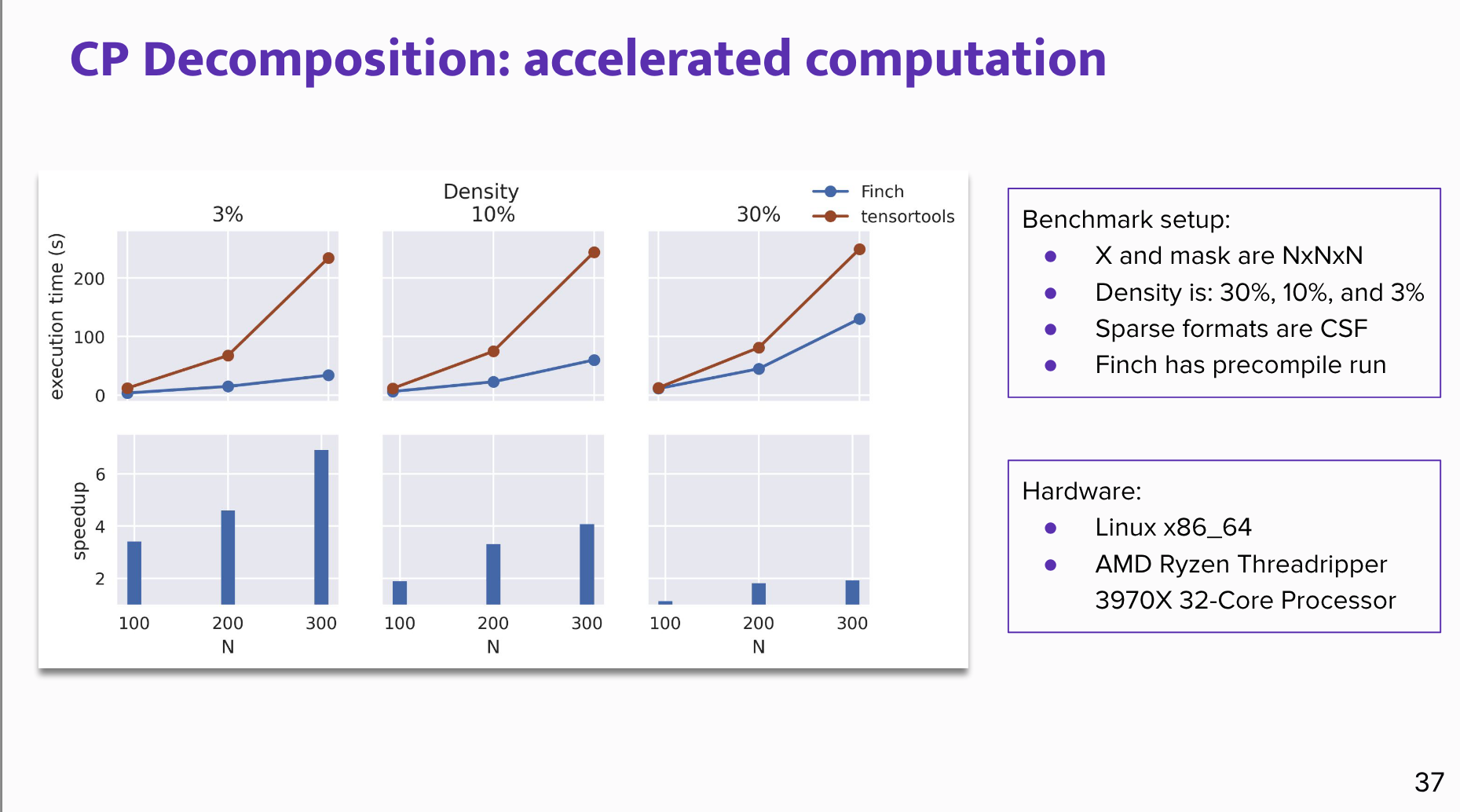
- Canonical Polyadic (CP) decomposition: A masked tensor decomposition routine from
tensortoolswas adapted with relatively small code changes and compiled with Finch.
Benchmark result:
- For Canonical Polyadic decomposition at low density, around 3%, the speakers report more than a sevenfold speedup on their test infrastructure.
Ecosystem direction:
finch-tensoris available as a Python package, currently using JuliaCall to access the Julia implementation.- The project is also working on a pure Python compiler path using Numba as a backend.
- The 2026 goal is to push “Finch Light” toward an initial community release.
Standardization angle:
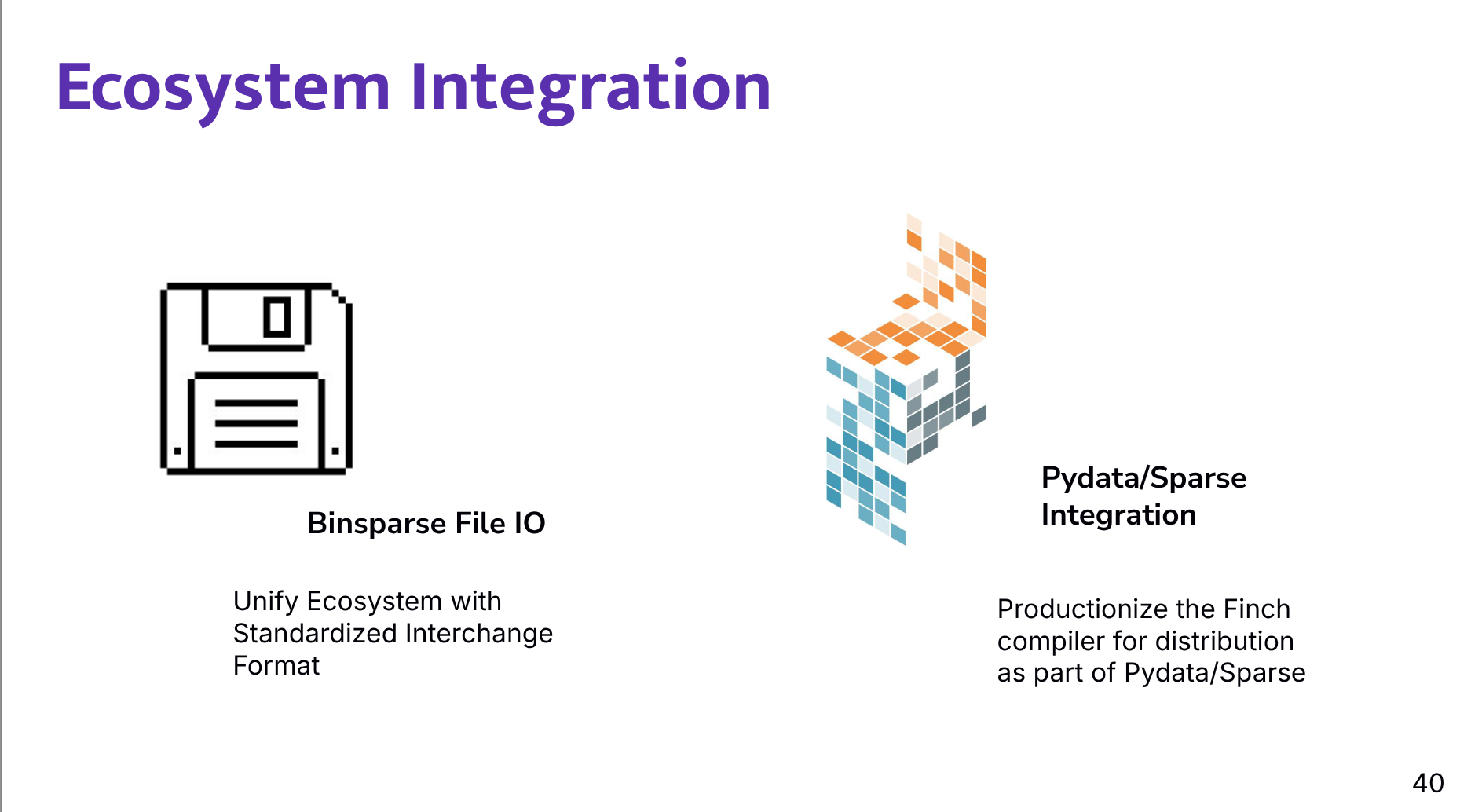
- The speakers also discuss
binsparse, a binary sparse storage/interchange format intended to standardize sparse array exchange across formats and platforms. - The goal is broader PyData/Sparse integration, including Finch as a selectable backend.
- The speakers also discuss
Talk:
- PyData/Sparse and Finch, PyData Global 2025.
Main thesis:
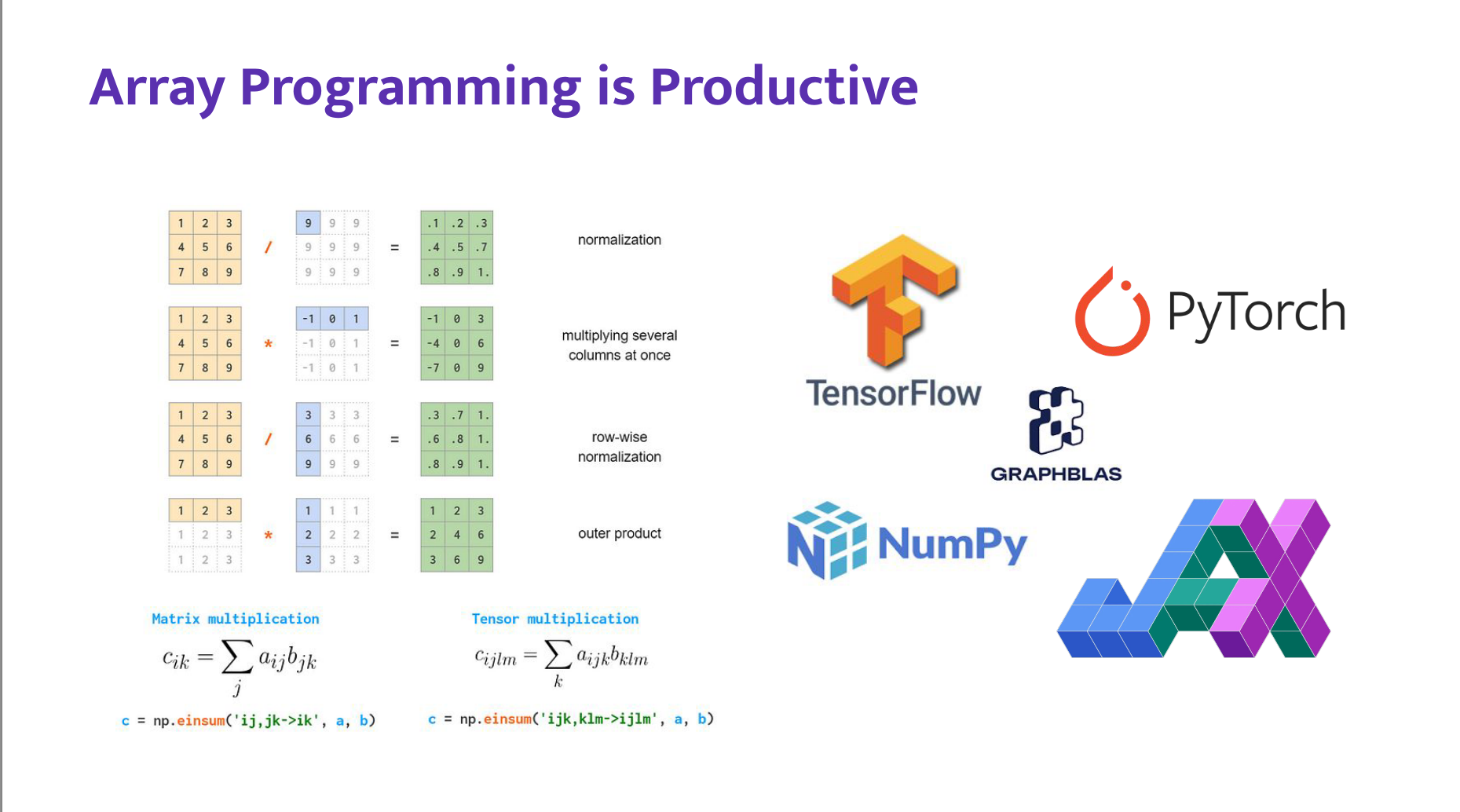
Array programming is highly productive, but sparse arrays are still hard to use efficiently in Python.
The speakers argue that sparse tensor compilers can unify sparse computation by translating high-level array code into efficient kernels for many formats and backends.

Problem being addressed:
- Sparsity appears in scientific computing, social networks, machine learning, and image processing.
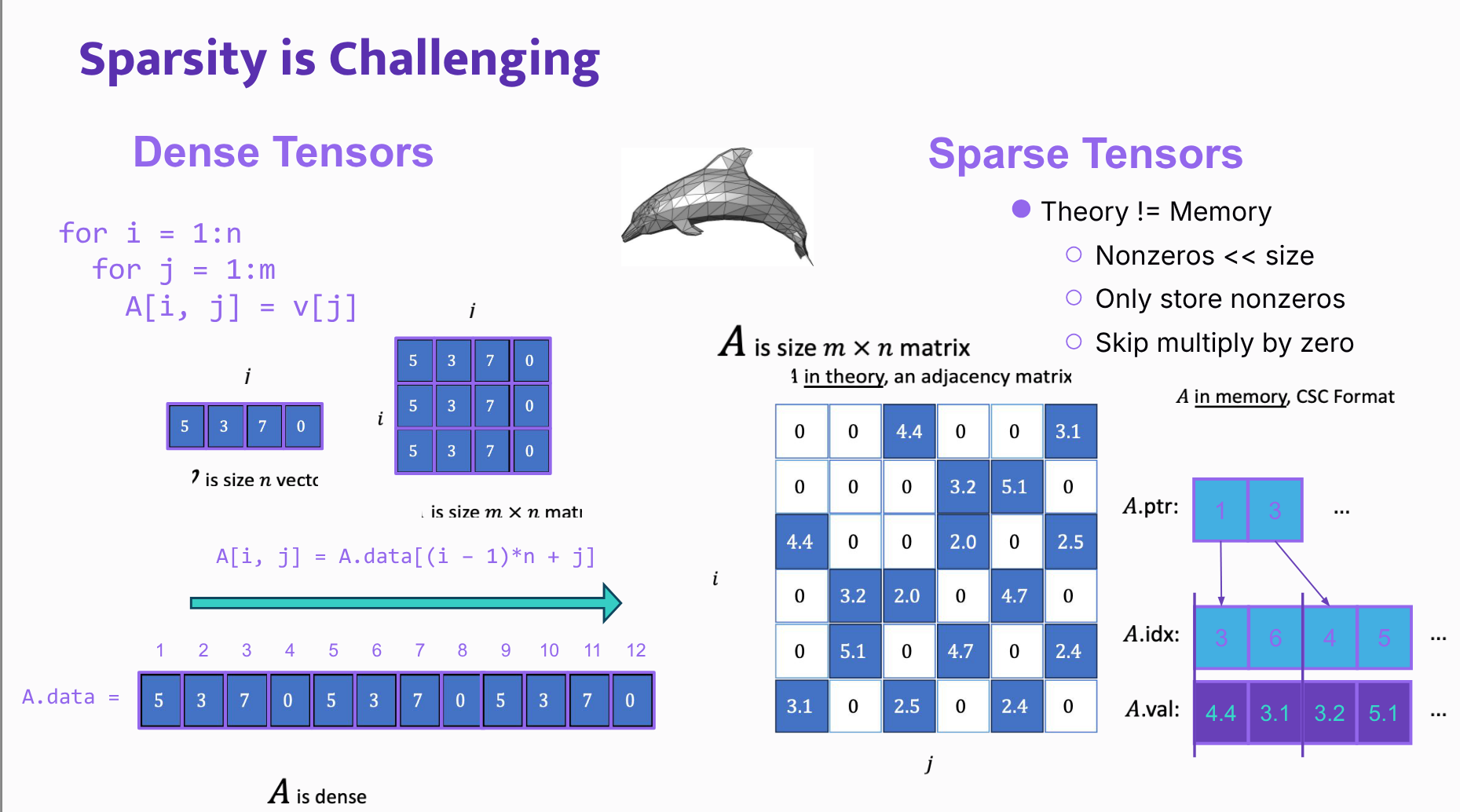
- Dense arrays have a simple relationship between mathematical indexing and memory layout.
- Sparse arrays break that simplicity because formats such as Compressed Sparse Column store only nonzero values, plus index and pointer arrays.
- Efficient sparse algorithms must avoid multiplying by zero and must traverse sparse data structures correctly.
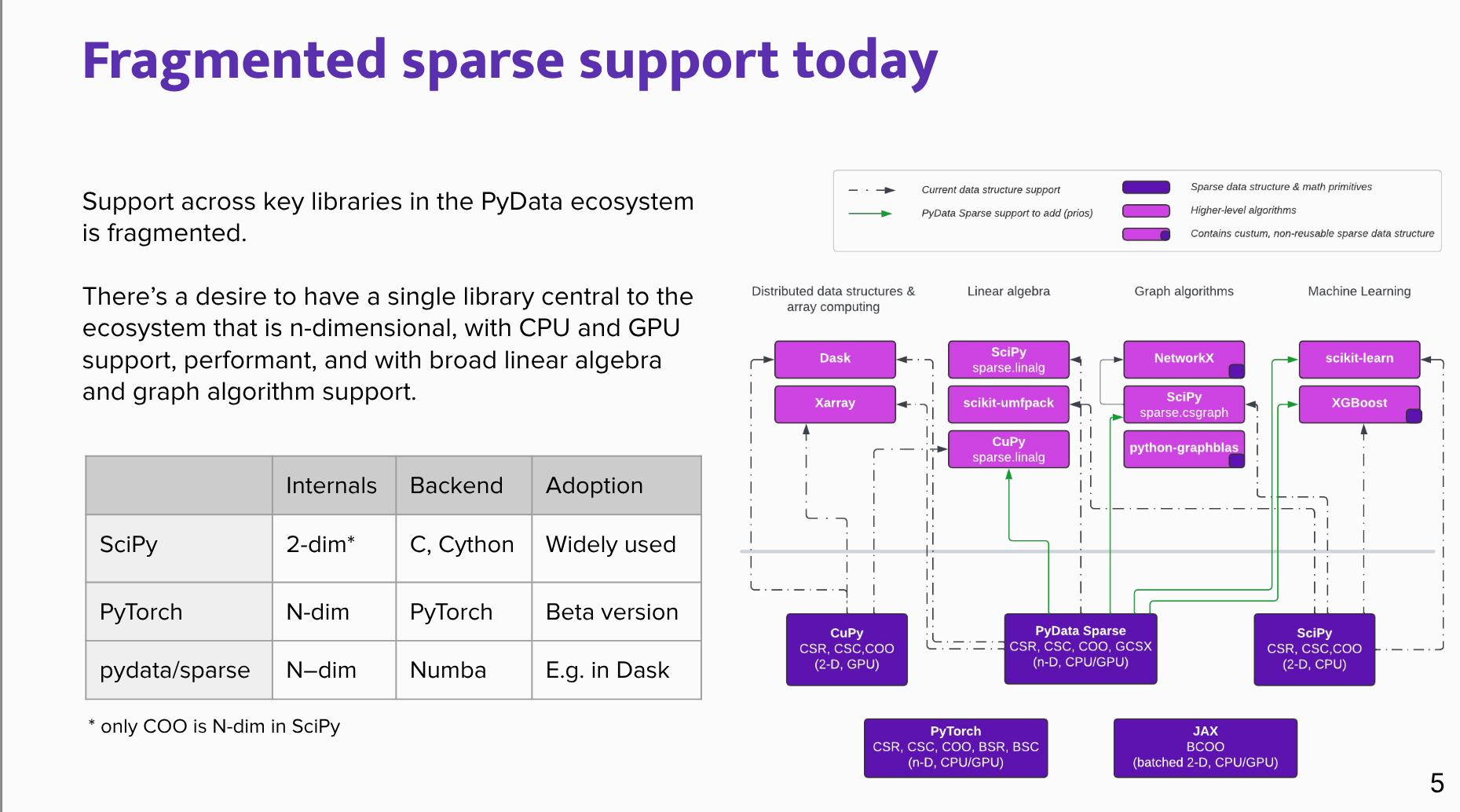
Current ecosystem issue:
- Sparse support in the PyData ecosystem is fragmented.
- SciPy, PyTorch, and PyData/Sparse each support different dimensions, formats, operations, and backends.
- The desired target is a central sparse array library that is n-dimensional, performant, supports central processing units and graphics processing units, and has broad linear algebra and graph algorithm coverage.

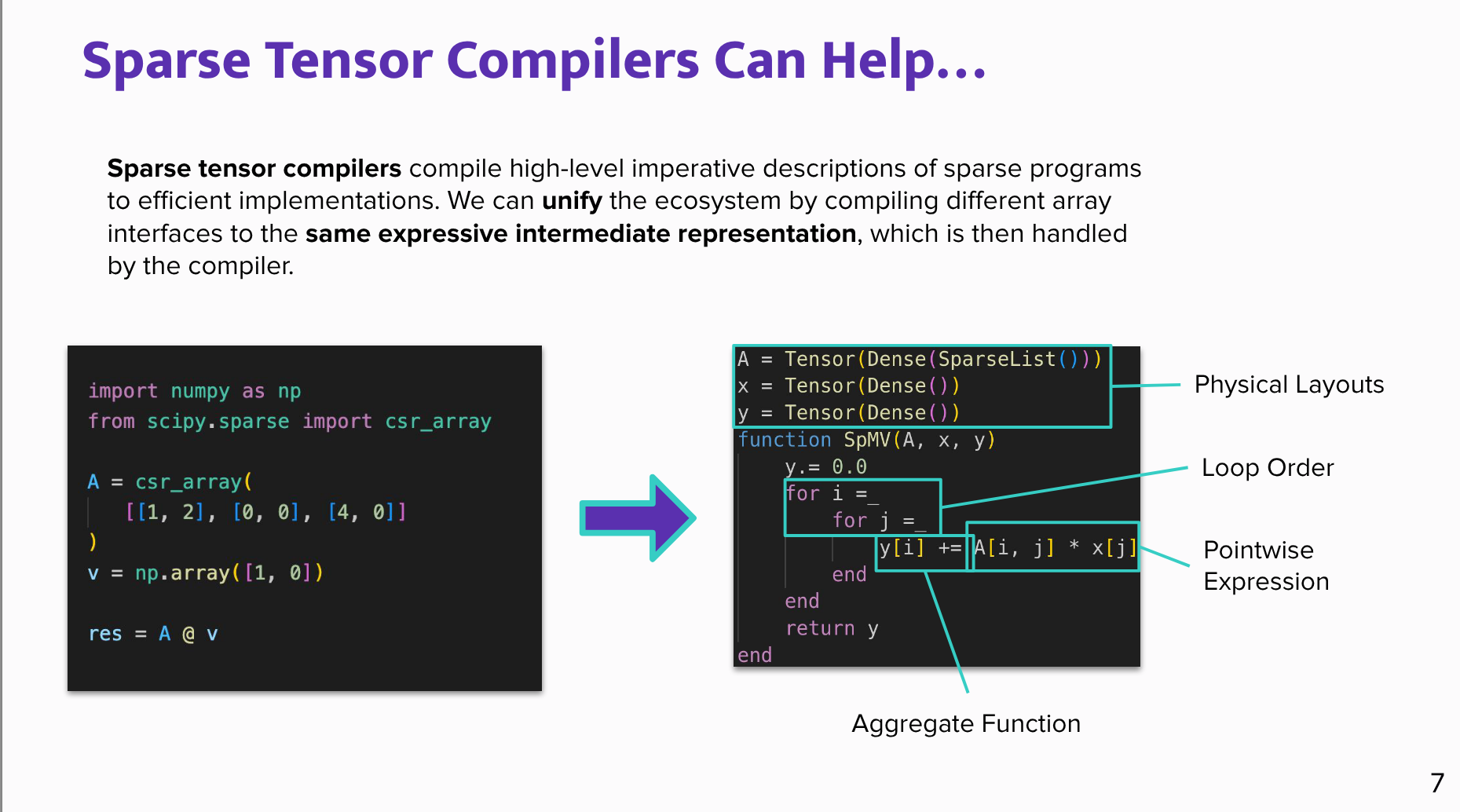
Why compilers matter:
- The implementation burden grows combinatorially across operations, structures, data formats, and hardware architectures.
- A sparse tensor compiler can take a high-level sparse program plus format descriptions and generate specialized code automatically.
- This lets different interfaces and sparse formats map into a shared intermediate representation rather than requiring hand-written kernels for every case.
























HITS ::: {.sl-text}

::::





Q&A point:
- A question focused on understanding the lowering process.
- The answer emphasized that the lowering design is intended to be extensible across triangular, run-length encoded, and general sparse matrix structures, making the system more future-proof.
Reflections
WoW
- a good sparse library for python calls for implementing many Stats and ML algorithm using this backend.
- Also streaming algorithms can benefit from this.
- The tensor logic needs
einsum- is this op supported ? - work by Willow Arhens and her team suggest that it is possible to dramatically speed up einsums for sparse tensors using an
insumoperation that skips zero values and empty loops. code and paper
For situations where more complex operations are needed, Finch supports an (einsum?) syntax on sparse and structured tensors.
julia> @einsum E[i] += A[i, j] * B[i, j]
julia> @einsum F[i, k] <<max>>= A[i, j] + B[j, k]Resources
Repos and Docs:
binsparse specification A cross-platform binary storage format for sparse data, particularly sparse matrices.
Papers:
Citation
@online{bochman2025,
author = {Bochman, Oren},
title = {Sparse \& {Finch}},
date = {2025-12-12},
url = {https://orenbochman.github.io/posts/2025/2025-12-11-pydata-sparse-and-finch/},
langid = {en}
}