time series analysis, forecasting, R, linear regression, normality, residuals, t-test, coursera
if (!require("pacman")) install.packages("pacman")
Loading required package: pacman
pacman::p_load(faraway)
Installing package into '/home/oren/work/blog/renv/library/R-4.4/x86_64-pc-linux-gnu'
(as 'lib' is unspecified)
also installing the dependencies 'minqa', 'nloptr', 'RcppEigen', 'lme4'
faraway installed
I took this course on Coursera in primarily to get a more solid foundation in time series analysis and forecasting before taking the bayesian time series course. I have some experience with time series analysis from reading a few books and papers, but I wanted to get a more solid foundation in the subject.
Most of the material in this course is introductory and I did not bother with very in depth explanations or notes, often listing just what is covered.
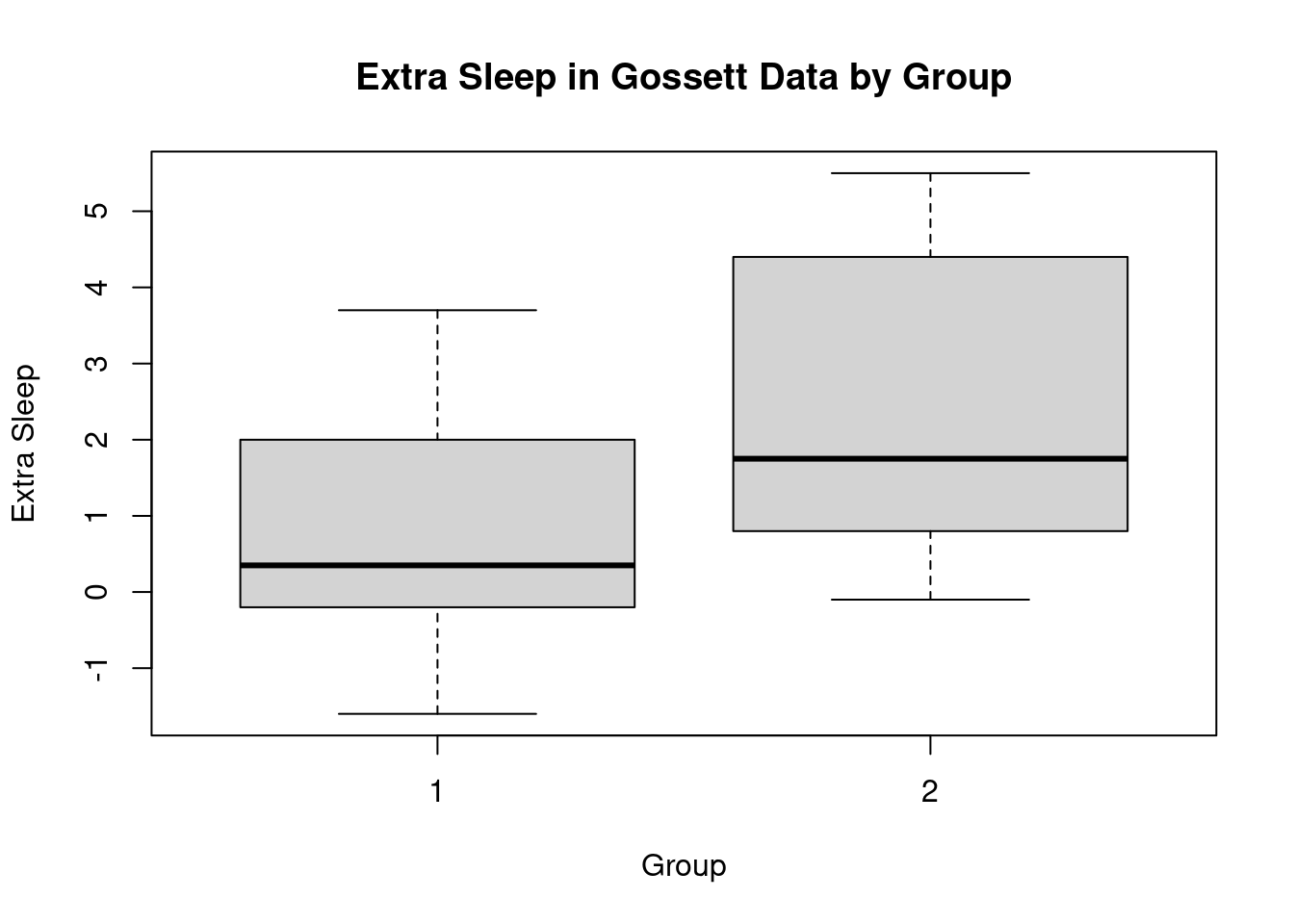
Paired t-test
data: extra_1 and extra_2
t = -4.0621, df = 9, p-value = 0.002833
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
-2.4598858 -0.7001142
sample estimates:
mean difference
-1.58
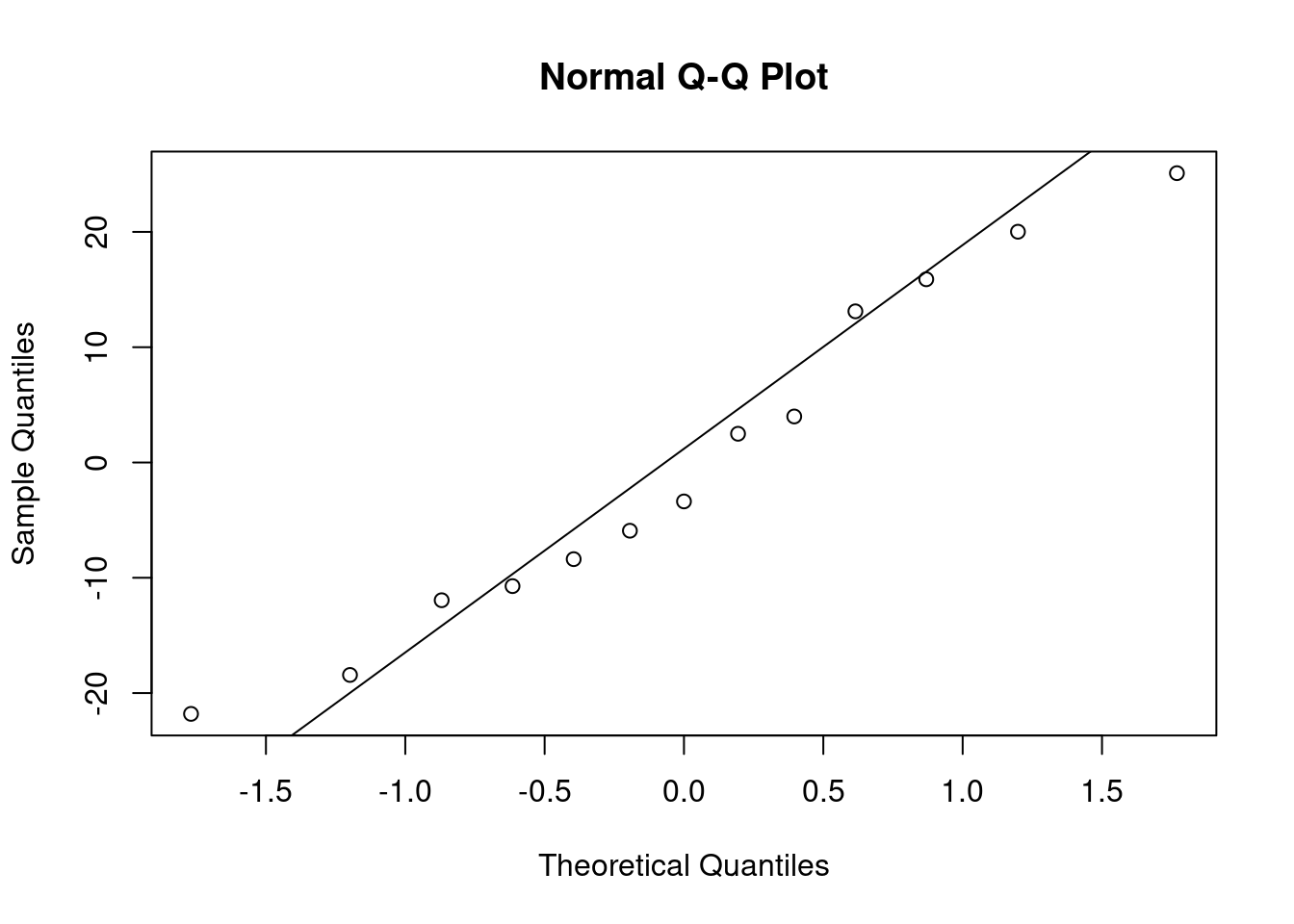
the confidence interval does not contain zero, so we can reject the null hypothesis that the means are equal, and conclude that the means are different.
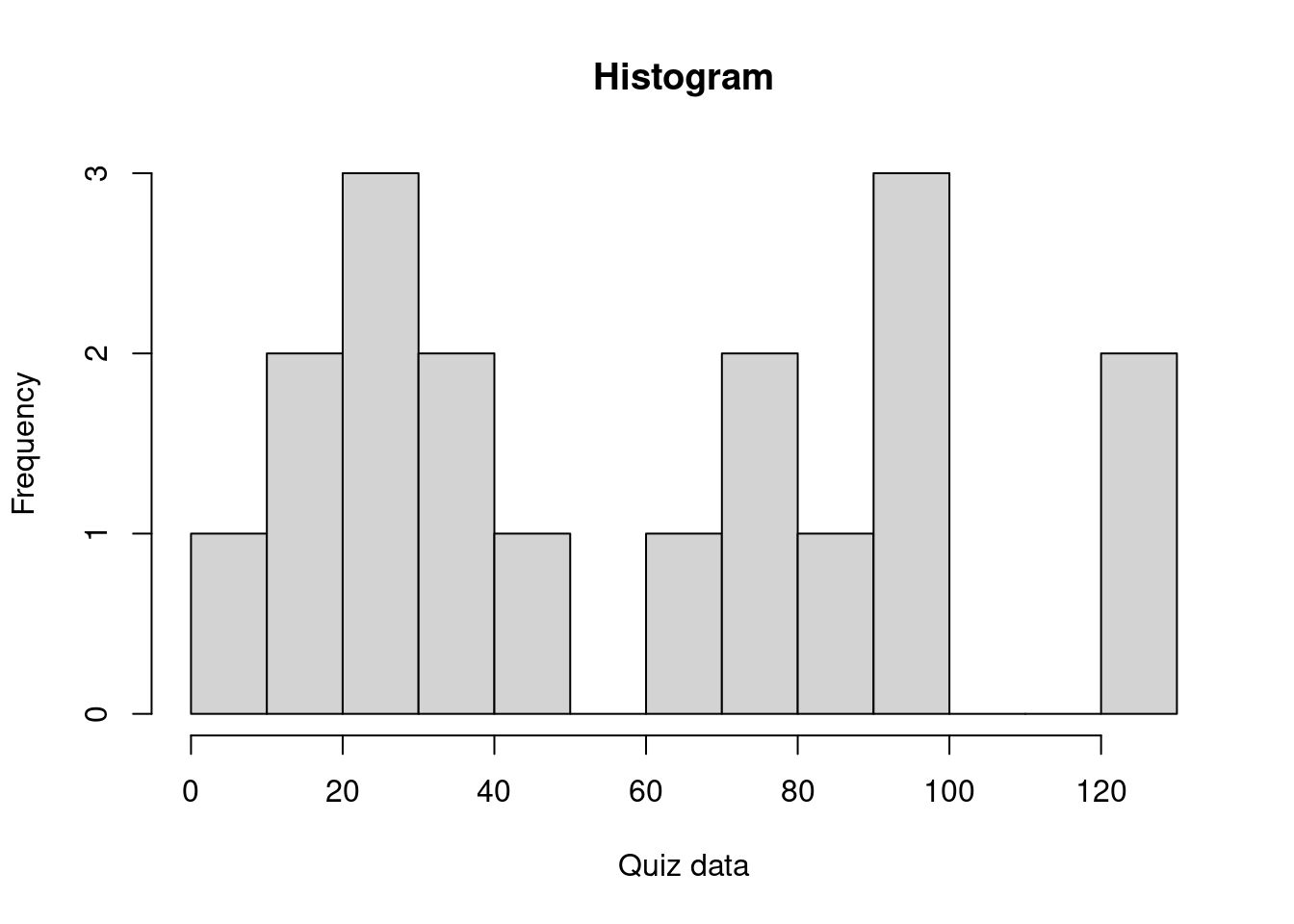
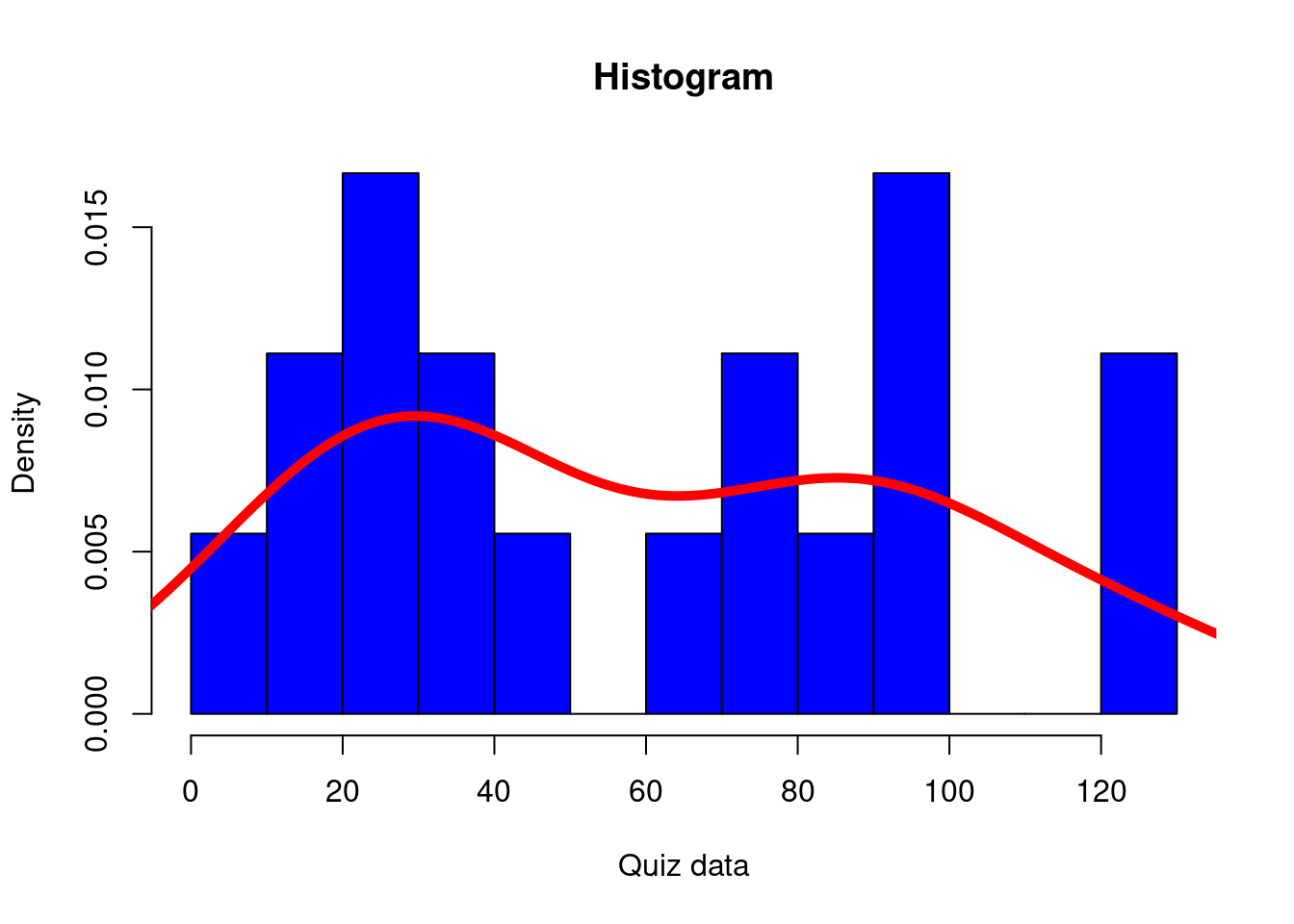
visulization homework
Which of the following has the right R command and the right histogram for the dataset (called quiz_data) from Part 1 (provided below) with a title ‘Histogram’, x-label ‘Quiz data’ and 10 break points?