The announcement of the GPT-5 strawberry model has sparked a lot of interest in this paper which seems to be the theory behind Open.ai’s new model.
TLDR
In (Wang et al. 2024), titled “Q*: Improving Multi-step Reasoning for LLMs with Deliberative Planning,” the authors propose a new framework called Q* to improve the multi-step reasoning capabilities of Large Language Models (LLMs). The authors identify a key issue with LLMs: their auto-regressive nature often leads to errors, hallucinations, and inconsistencies in multi-step reasoning tasks.
some questions to consider:
- In the Q* MDP what are the states, actions, rewards, and transition probabilities?
- The idea of a utility function is central to the Q* framework. How is the utility function defined in this context?
Abstract
Large Language Models (LLMs) have demonstrated impressive capability in many natural language tasks. However, the auto-regressive generation process makes LLMs prone to produce errors, hallucinations and inconsistent statements when performing multi-step reasoning. In this paper, by casting multi-step reasoning of LLMs as a heuristic search problem, we aim to alleviate the pathology by introducing Q*, a general, versatile and agile framework for guiding LLMs decoding process with deliberative planning. By learning a plug-and-play Q-value model as heuristic function for estimating expected future rewards, our Q* can effectively guide LLMs to select the most promising next reasoning step without fine-tuning LLMs for the current task, which avoids the significant computational overhead and potential risk of performance degeneration on other tasks. Extensive experiments on GSM8K, MATH and MBPP demonstrate the superiority of our method, contributing to improving the reasoning performance of existing open-source LLMs.
— (Wang et al. 2024)
The Problem
LLMs face challenges in multi-step reasoning tasks, frequently producing errors due to their auto-regressive generation process. While previous efforts have tried to enhance LLMs’ “System 1” capabilities (fast but less accurate), complex reasoning requires “System 2” processes—more deliberative and logical thinking.
The Q* Framework
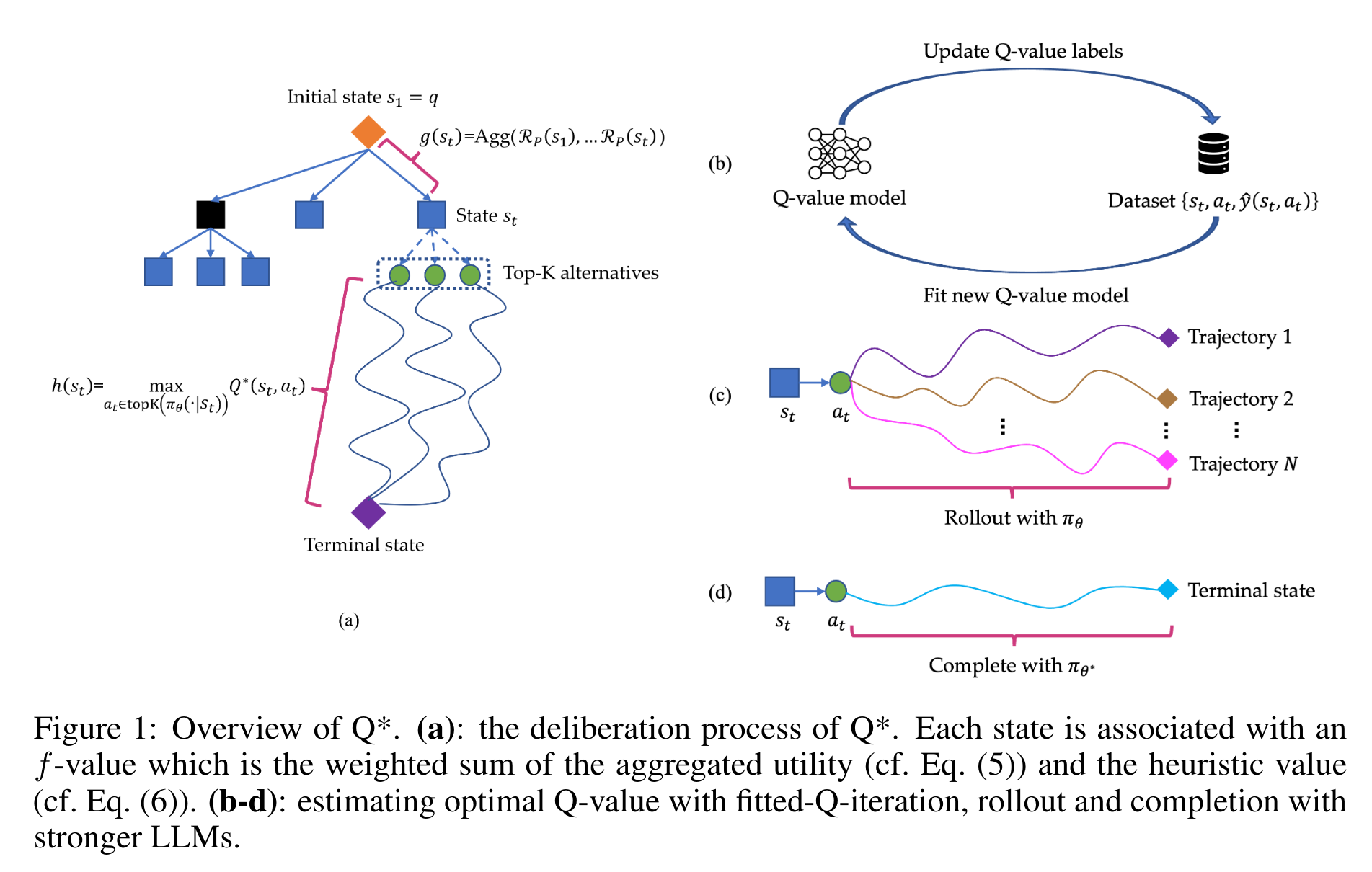
- The authors cast multi-step reasoning as a Markov Decision Process (MDP) and introduce the Q* framework. The framework uses a Q-value model as a heuristic function to guide LLMs during the decoding process.
- Q* operates without the need for fine-tuning LLMs for each task, avoiding computational overhead and the risk of performance degradation in other tasks.
- Q* leverages A* search to select the most promising next reasoning step, using a proxy Q-value model to guide this process.
Key Contributions
- Formalizing multi-step reasoning of LLMs as an MDP
- Introducing general approaches to estimate the optimal Q-value of state-action pairs, including offline reinforcement learning, rollouts, and completion with stronger LLMs.
- Casting multi-step reasoning tasks as a heuristic search problem to find the optimal reasoning trace with maximum utility.

Estimation of Optimal Q-value
The authors present several ways to estimate the optimal Q-value:
- Offline Reinforcement Learning: Using Fitted Q-iteration to update the Q-value model iteratively.
- Learning from Rollout: Performing random rollouts or Monte Carlo Tree Search (MCTS) to identify the best reasoning sequence.
- Completion with Stronger LLMs: Using a stronger LLM to complete the trajectory and estimate the optimal Q-value.
Experiments
The framework was tested on math reasoning (GSM8K, MATH) and code generation (MBPP) tasks. Results showed that:
- Q* improves the reasoning capability of existing open-source LLMs.
- Q* outperforms traditional Best-of-N methods and existing LLMs enhanced with alignment techniques like PPO (Proximal Policy Optimization).
Conclusions
Q* provides an agile deliberation framework for LLMs, improving their multi-step reasoning ability without the need for extensive fine-tuning. It is generalizable across various reasoning tasks, making it a versatile tool for enhancing LLM performance.
Strengths
Novel Framework: Introducing Q* as a deliberative planning framework is a novel approach to improving multi-step reasoning.
Versatility: Q* can be applied to various reasoning tasks without task-specific modifications.
Extensive Evaluation: The authors conducted experiments across multiple datasets, demonstrating the efficacy of their approach.
Weaknesses and Areas for Improvement
Complexity: The paper introduces a relatively complex framework, which might present challenges in understanding and implementing the approach.
Dependency on Q-value Estimation: The performance of Q* is heavily reliant on the accuracy of the Q-value model, which might be sensitive to the chosen estimation method.
Limited Exploration of Alternatives: While the paper focuses on Q*, there could be a discussion on how this method compares with other deliberative planning methods in more depth.
Overall Impression
The paper presents a solid contribution to improving multi-step reasoning in LLMs. The Q* framework is a promising approach, particularly in its ability to generalize across different reasoning tasks. However, its complexity and the reliance on accurate Q-value estimation are potential hurdles that might need further exploration.
The paper
Resources
Citation
@online{bochman2025,
author = {Bochman, Oren},
title = {Q*: {Improving} {Multi-step} {Reasoning} for {LLMs} with
{Deliberative} {Planning}},
date = {2025-05-09},
url = {https://orenbochman.github.io/reviews/2024/q-star/},
langid = {en}
}