TL;DR
In (Lin et al. 2014) the authors, Lin, Min, Qiang Chen, and Shuicheng Yan, of this paper titled “Network in Network” paper came up with a way of connencting somee ideas on improving CNNs which had been mostly getting bigger (VGG > AlexNet > LeNet) . They replaced traditional linear filters in convolutional neural networks (CNNs) with multilayer perceptrons (MLPs) to enhance local feature abstraction. This new architecture, called NIN, also introduces global average pooling in place of fully connected layers thus reducing overfitting, improving model interpretability and more significantly reducing the size of the network.
It took a while for the idea to catch on, but in computer vision, most of the parameters are in the fully connected layers, and the NIN architecture enables us to to reduce the number of parameters in the fully connected layers thereby breaking the curse of dimensionality in CNN. Once people realized this the NIN architecture became more widely adopted and influenced the development of more sophisticated deep learning architectures like the Inception architecture and further refined into the Resnet architecture
The NIN architecture has a significant impact on the design of CNNs by demonstrating that local feature abstraction can be enhanced with MLPs, leading to better performance with fewer parameters. Global average pooling, which replaces fully connected layers, makes the architecture more robust to overfitting and spatial translations, making it a powerful tool for image classification tasks. This combination of techniques has influenced the development of more sophisticated deep learning architectures, particularly in domains where model interpretability and reduced overfitting are critical.
Abstract
We propose a novel deep network structure called “Network In Network” (NIN) to enhance model discriminability for local patches within the receptive field. The conventional convolutional layer uses linear filters followed by a nonlinear activation function to scan the input. Instead, we build micro neural networks with more complex structures to abstract the data within the receptive field. We instantiate the micro neural network with a multilayer perceptron, which is a potent function approximator. The feature maps are obtained by sliding the micro networks over the input in a similar manner as CNN; they are then fed into the next layer. Deep NIN can be implemented by stacking multiple of the above described structure. With enhanced local modeling via the micro network, we are able to utilize global average pooling over feature maps in the classification layer, which is easier to interpret and less prone to overfitting than traditional fully connected layers. We demonstrated the state-of-the-art classification performances with NIN on CIFAR-10 and CIFAR-100, and reasonable performances on SVHN and MNIST datasets.
– (Lin et al. 2014)
Review
In (Lin et al. 2014) the authors introduced a novel deep learning architecture that aims to improve the abstraction capabilities of convolutional neural networks (CNNs) by incorporating multilayer perceptrons (MLPs) into the convolution layers. This approach, termed “Network in Network,” replaces the conventional linear filters used in CNNs with small neural networks, allowing for better local feature modeling. The NIN architecture also introduces global average pooling as a substitute for traditional fully connected layers to reduce overfitting and improve the interpretability of the model.
Key Contributions
The NIN paper makes several key contributions to the deep learning landscape:
Mlpconv Layer: Instead of using traditional linear filters, NIN proposes the use of multilayer perceptrons (MLPs) within the convolutional layers (termed mlpconv layers). These layers act as universal function approximators, capable of modeling more complex representations within local receptive fields. This structure allows for better abstraction of non-linear latent concepts, overcoming the limitations of traditional linear filters in CNNs.
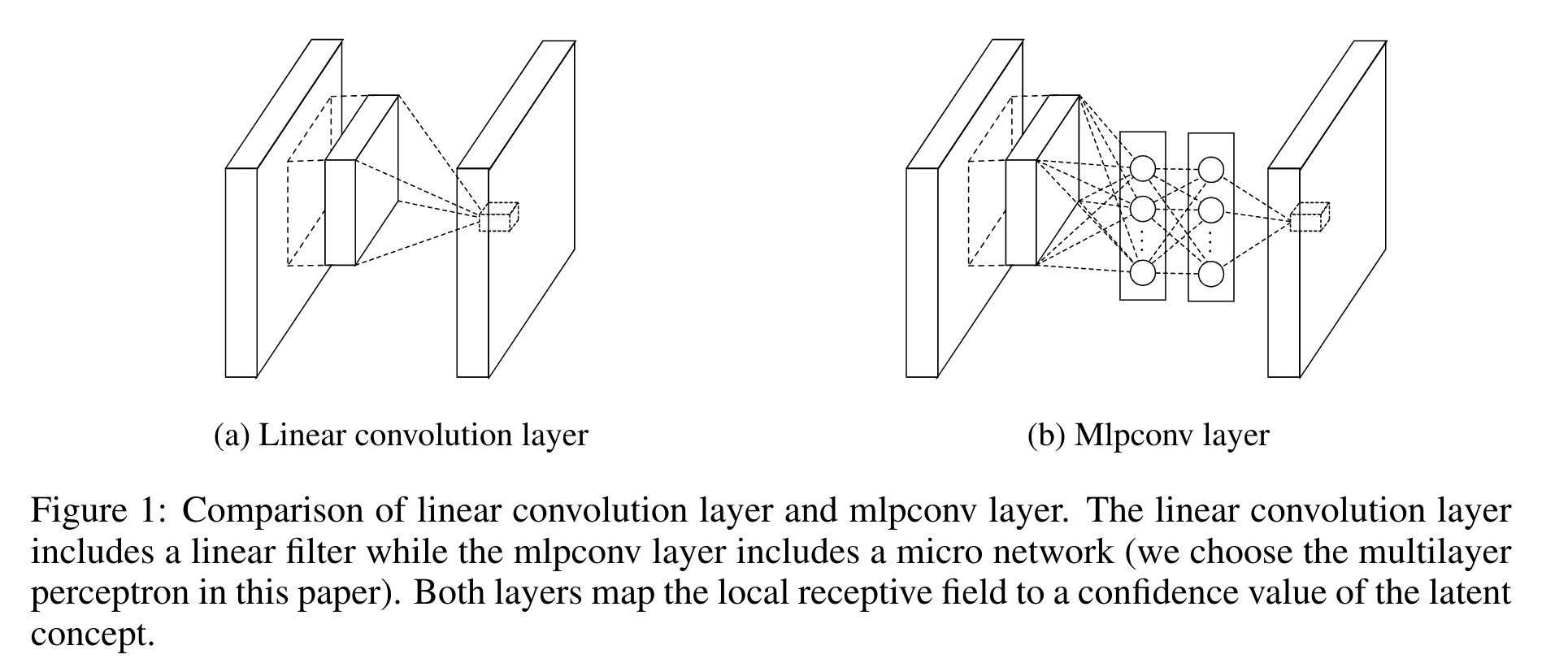
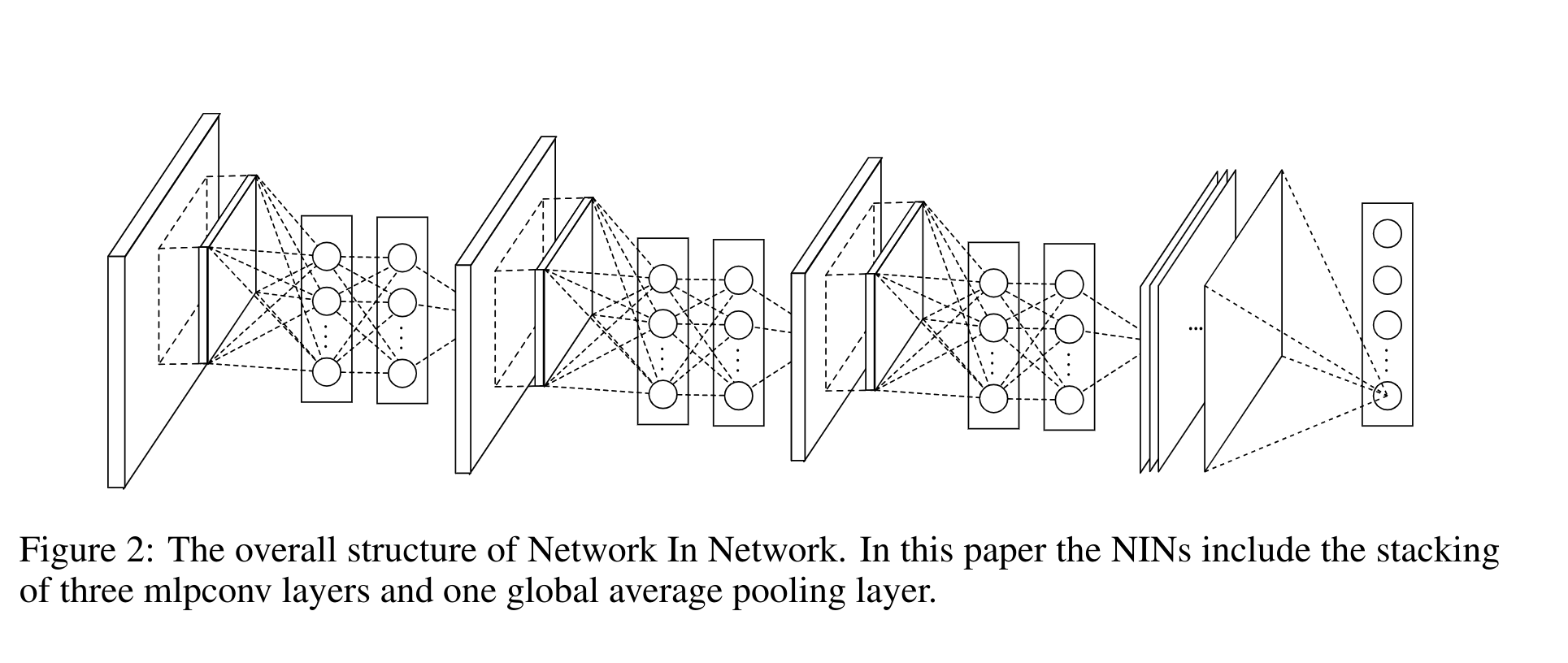
Global Average Pooling: NIN introduces global average pooling as an alternative to fully connected layers in the final classification stage. This technique computes the spatial average of each feature map, feeding the result directly into a softmax layer for classification. By avoiding fully connected layers, the model becomes less prone to overfitting, thus improving generalization performance. Furthermore, this method provides more interpretable results by establishing a direct correspondence between feature maps and class labels.
State-of-the-Art Performance: The authors demonstrate that NIN achieves state-of-the-art performance on several benchmark datasets, including CIFAR-10, CIFAR-100, and SVHN, without the need for extensive data augmentation or model ensembling. The architecture consistently outperforms other methods, such as maxout networks and CNNs with dropout regularization, especially in terms of classification accuracy.

Strengths
Innovative Architecture: The introduction of MLPs into convolutional layers is a simple yet effective modification that significantly enhances the representational power of the model. This makes NIN a powerful alternative to traditional CNNs, especially for tasks that require fine-grained feature extraction and abstraction.
Reduced Overfitting: The use of global average pooling not only replaces the computationally expensive fully connected layers but also serves as a built-in regularizer, reducing the need for additional techniques like dropout. This structural regularization helps to prevent overfitting, particularly on datasets with limited training examples, such as CIFAR-100.
Better Interpretability: The global average pooling layer allows for easier interpretation of the learned feature maps, as each map is directly associated with a class. This increases the transparency of the network’s the decision-making process compared to conventional CNNs.

Limitations
Limited Novelty in Pooling: While global average pooling is effective, the concept is not entirely new, and its novelty is limited. Previous works have proposed similar techniques for specific tasks. However NIN certainly demonstrates the concepts efficacy.
Scalability: The paper focuses primarily on relatively small datasets like CIFAR-10, CIFAR-100, SVHN, and MNIST. While NIN excels in these scenarios, it would be interesting to see how the architecture performs on larger, more complex datasets such as ImageNet, where the size and variety of the data might pose additional challenges.
Lack of Depth Exploration: While the architecture consists of three stacked mlpconv layers, the paper does not deeply explore the impact of adding more layers or experimenting with deeper NIN networks. Such exploration could provide insight into how well the architecture scales with increased model depth.
Conclusion
NIN architecture is an elegant and effective solution to improving feature abstraction and reducing overfitting in CNNs. By embedding MLPs within convolutional layers and using global average pooling for classification, NIN achieves state-of-the-art performance across a variety of tasks. NIN presented a strong case for the importance of local feature modeling and interpretable classification mechanisms in modern deep learning.
The paper
- Alex Smola Course Video on NIN, his course and book
Citation
@online{bochman2018,
author = {Bochman, Oren},
title = {NIN -\/-\/- {Network} in {Network}},
date = {2018-12-31},
url = {https://orenbochman.github.io/reviews/2013/NIN/},
langid = {en}
}