{{< pdf lec5.pdf >}}
Lecture 5d: Convolutional neural networks for object recognition
This video is more a collection of interesting success stories than a thorough introduction to new concepts.
#From hand-written digits to 3-D objects
- Recognizing real objects in color photographs downloaded from the web is much more complicated than recognizing hand-wriHen digits:
- Hundred times as many classes (1000 vs 10)
- Hundred times as many pixels (256 x 256 color vs 28 x 28 gray)
- Two dimensional image of three-dimensional scene.
- CluHered scenes requiring segmentation
- Multiple objects in each image.
- Will the same type of convolutional neural network work?
The ILSVRC-2012 competition on ImageNet
- The dataset has 1.2 million highresolution training images.
- The classification task:
- Get the “correct” class in your top 5 bets. There are 1000 classes.
- The localization task:
- For each bet, put a box around the object. Your box must have at least 50% overlap with the correct box.
- Some of the best existing computer vision methods were tried on this dataset by leading computer vision groups from Oxford, INRIA, XRCE, …
- Computer vision systems use complicated multi-stage systems.
- The early stages are typically hand-tuned by optimizing a few parameters
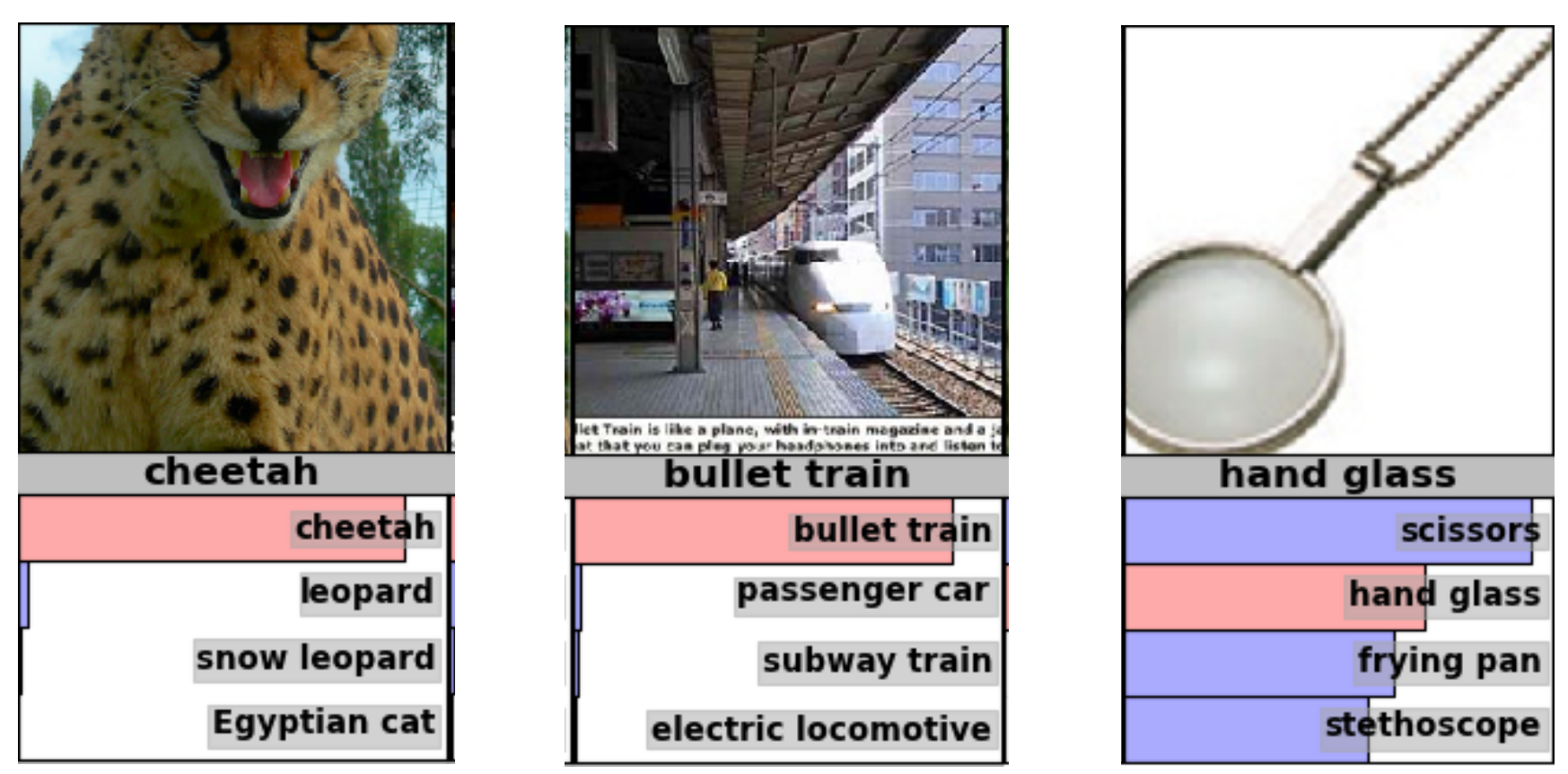
Examples from the test set (with the network’s guesses)
Error rates on the ILSVRC-2012 competition
A neural network for ImageNet
- Alex Krizhevsky (NIPS 2012) developed a very deep convolutional neural net of the type pioneered by Yann Le Cun. Its architecture was:
- 7 hidden layers not counting some max pooling layers.
- The early layers were convolutional.
- The last two layers were globally connected.
- The activation functions were:
- Rectified linear units in every hidden layer. These train much faster and are more expressive than logistic units.
- Competitive normalization to suppress hidden activities when nearby units have stronger activities. This helps with variations in intensity.
Tricks that significantly improve generalization
- Train on random 224x224 patches from the 256x256 images to get more data. Also use left-right reflections of the images.
- At test time, combine the opinions from ten different patches: The four 224x224 corner patches plus the central 224x224 patch plus the reflections of those five patches.
- Use dropout to regularize the weights in the globally connected layers (which contain most of the parameters).
- Dropout means that half of the hidden units in a layer are randomly removed for each training example.
- This stops hidden units from relying too much on other hidden units.
The hardware required for Alex’s net
- He uses a very efficient implementation of convolutional nets on two Nvidia GTX 580 Graphics Processor Units (over 1000 fast liHle cores)
- GPUs are very good for matrix-matrix multiplies.
- GPUs have very high bandwidth to memory.
- This allows him to train the network in a week.
- It also makes it quick to combine results from 10 patches at test time.
- We can spread a network over many cores if we can communicate the states fast enough.
- As cores get cheaper and datasets get bigger, big neural nets will improve faster than old-fashioned (i.e. pre Oct 2012) computer vision systems.
Finding roads in high-resolution images
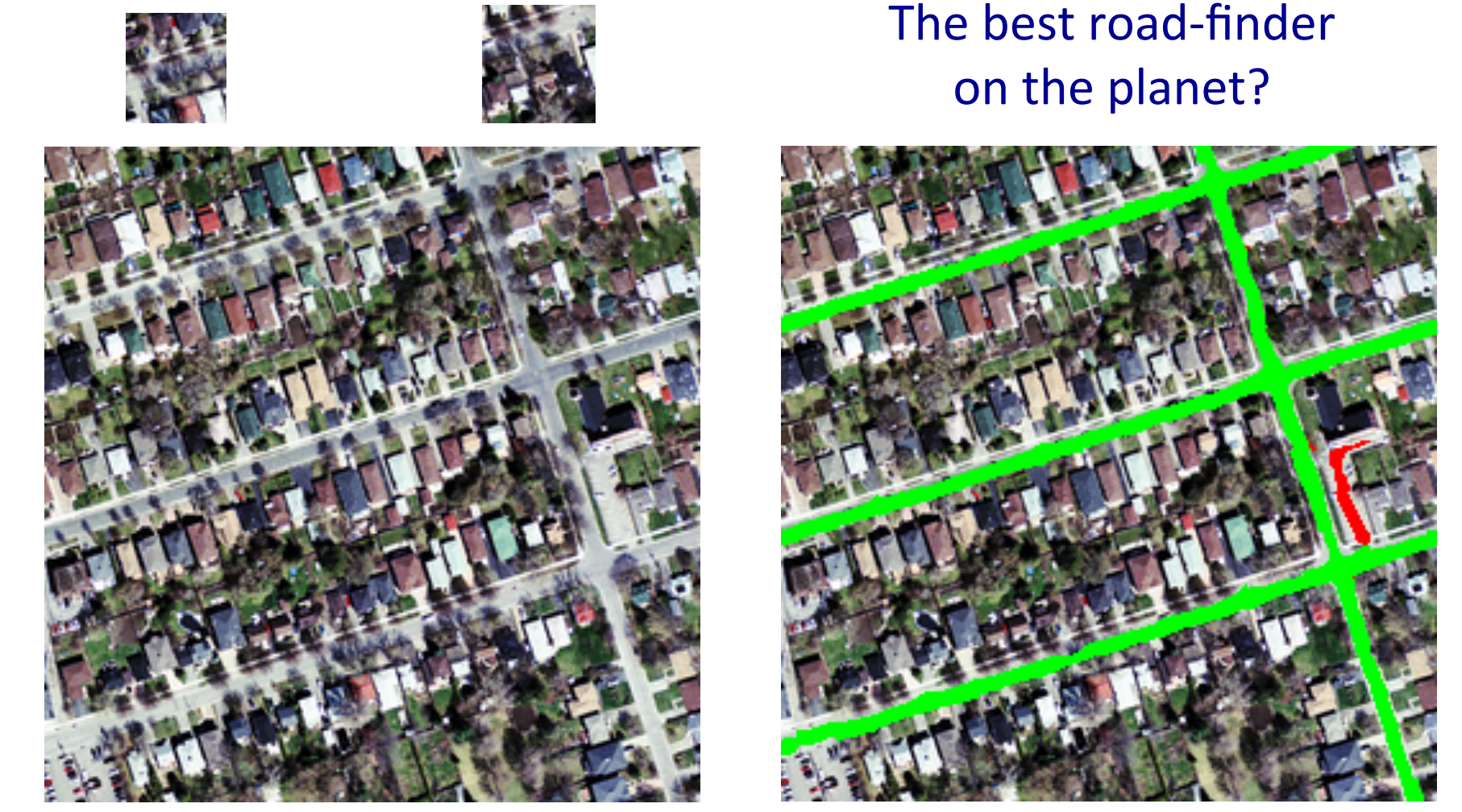
- In (Mnih and Hinton 2012) the author, Vlad Mnih, used a non-convolutional net with local fields and multiple layers of rectified linear units to find roads in cluHered aerial images.
- It takes a large image patch and predicts a binary road label for the central 16x16 pixels.
- There is lots of labeled training data available for this task.
- The task is hard for many reasons:
- Occlusion by buildings trees and cars.
- Shadows, Lighting changes
- Minor viewpoint changes
- The worst problems are incorrect labels:
- Badly registered maps
- Arbitrary decisions about what counts as a road.
- Big neural nets trained on big image patches with millions of examples are the only hope.
References
Mnih, Volodymyr, and Geoffrey Hinton. 2012. “Learning to Label Aerial Images from Noisy Data.” In Proceedings of the 29th International Coference on International Conference on Machine Learning, 203–10. ICML’12. Madison, WI, USA: Omnipress.
Reuse
CC SA BY-NC-ND
Citation
BibTeX citation:
@online{bochman2017,
author = {Bochman, Oren},
title = {Deep {Neural} {Networks} - {Notes} for Lecture 5d},
date = {2017-08-21},
url = {https://orenbochman.github.io/notes/dnn/dnn-05/l05d.html},
langid = {en}
}
For attribution, please cite this work as:
Bochman, Oren. 2017. “Deep Neural Networks - Notes for Lecture
5d.” August 21, 2017. https://orenbochman.github.io/notes/dnn/dnn-05/l05d.html.