Lecture 4a: Learning to predict the next word
A simple example of relational information
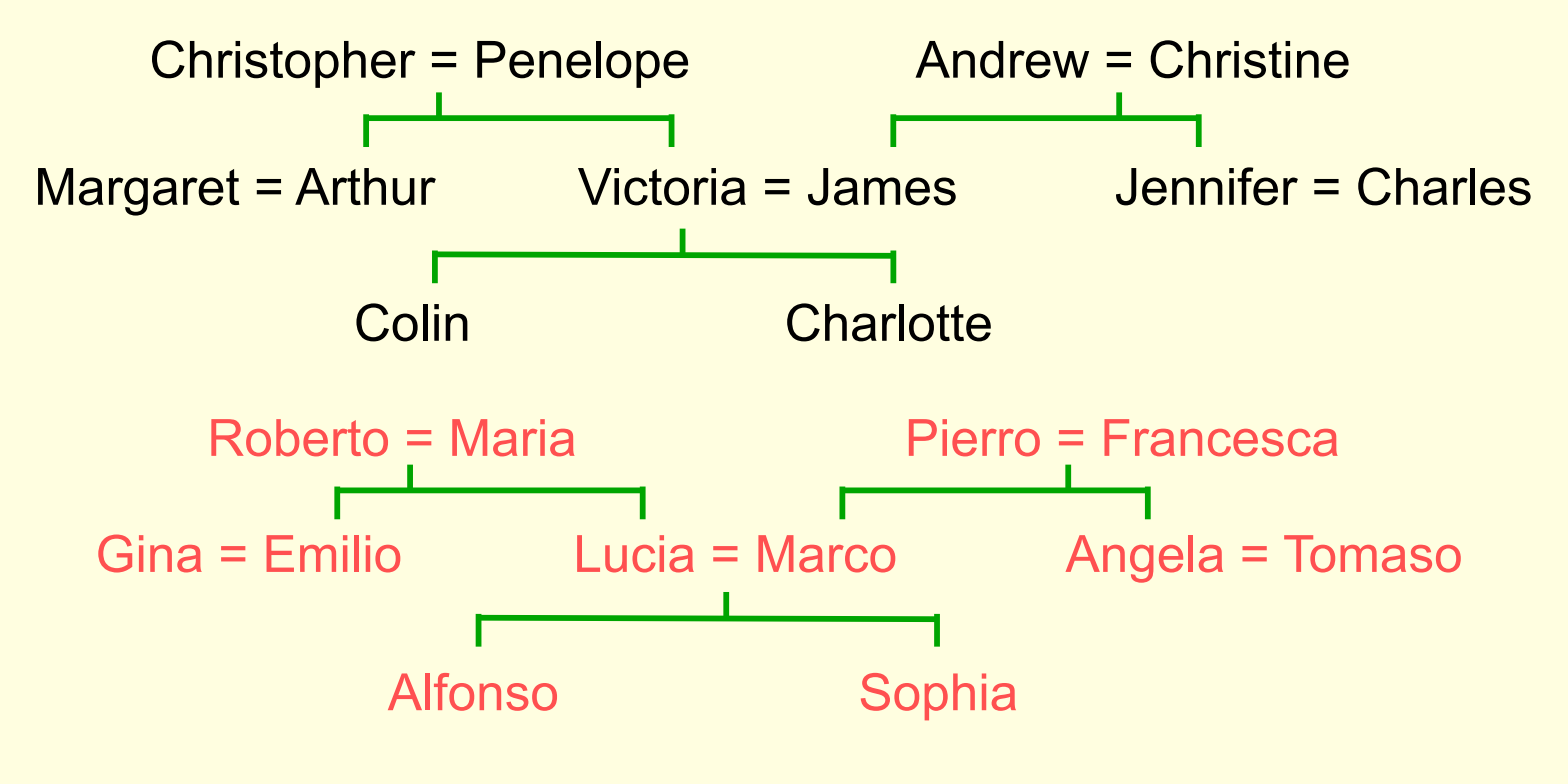
Another way to express the same information
- Make a set of propositions using the 12 relationships:
- son, daughter, nephew, niece, father, mother, uncle, aunt
- brother, sister, husband, wife
- (Colin has-father James)
- (Colin has-mother Victoria)
- (James has-wife Victoria) this follows from the two above
- (Charlotte has-brother Colin)
- (Victoria has-brother Arthur)
- (Charlotte has-uncle Arthur) this follows from the above
A relational learning task
- Given a large set of triples that come from some family trees, figure out the regularities.
- The obvious way to express the regularities is as symbolic rules (x has-mother y) & (y has-husband z) => (x has-father z)
- Finding the symbolic rules involves a difficult search through a very large discrete space of possibilities.
- Can a neural network capture the same knowledge by searching through a continuous space of weights?
The structure of the neural net
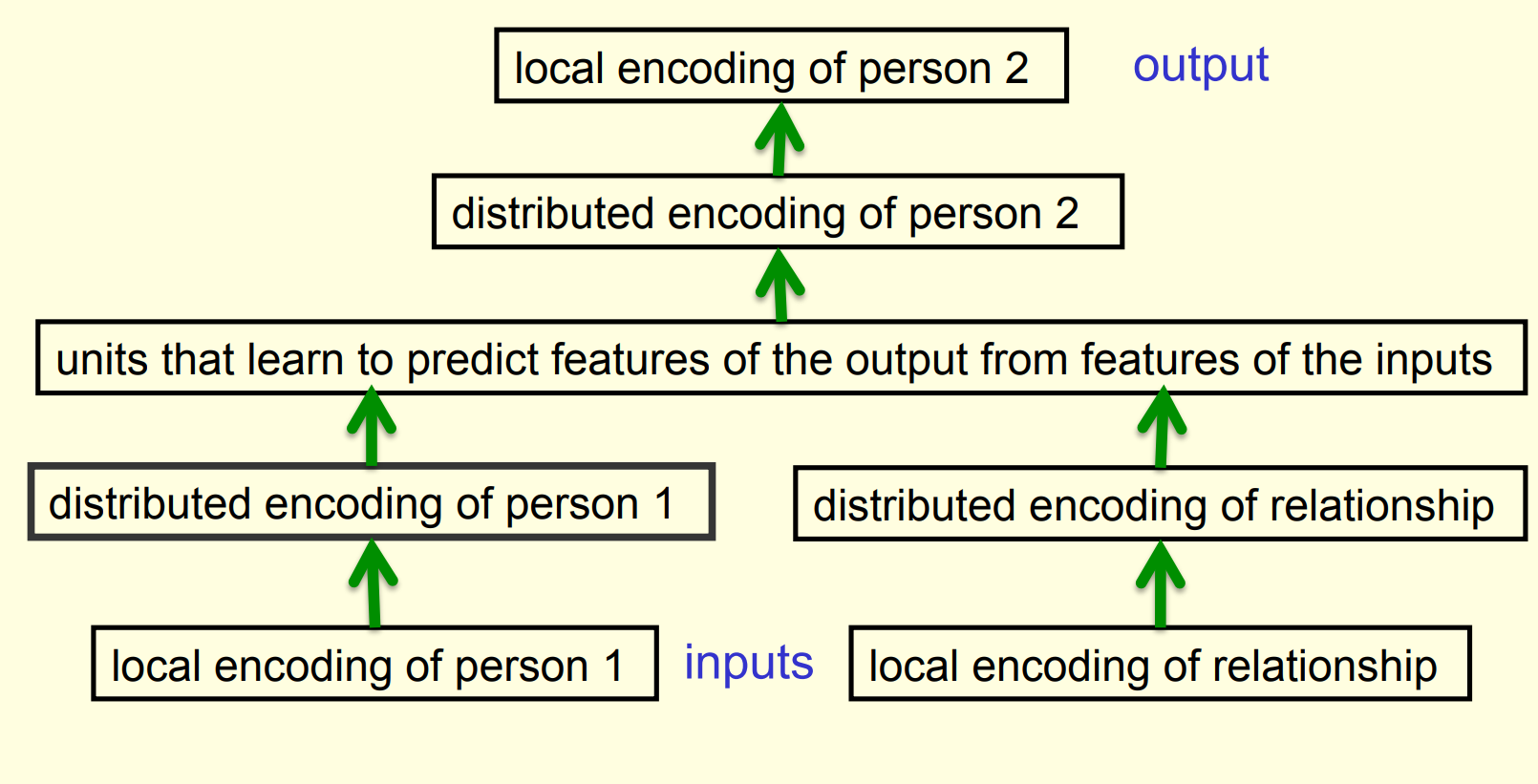
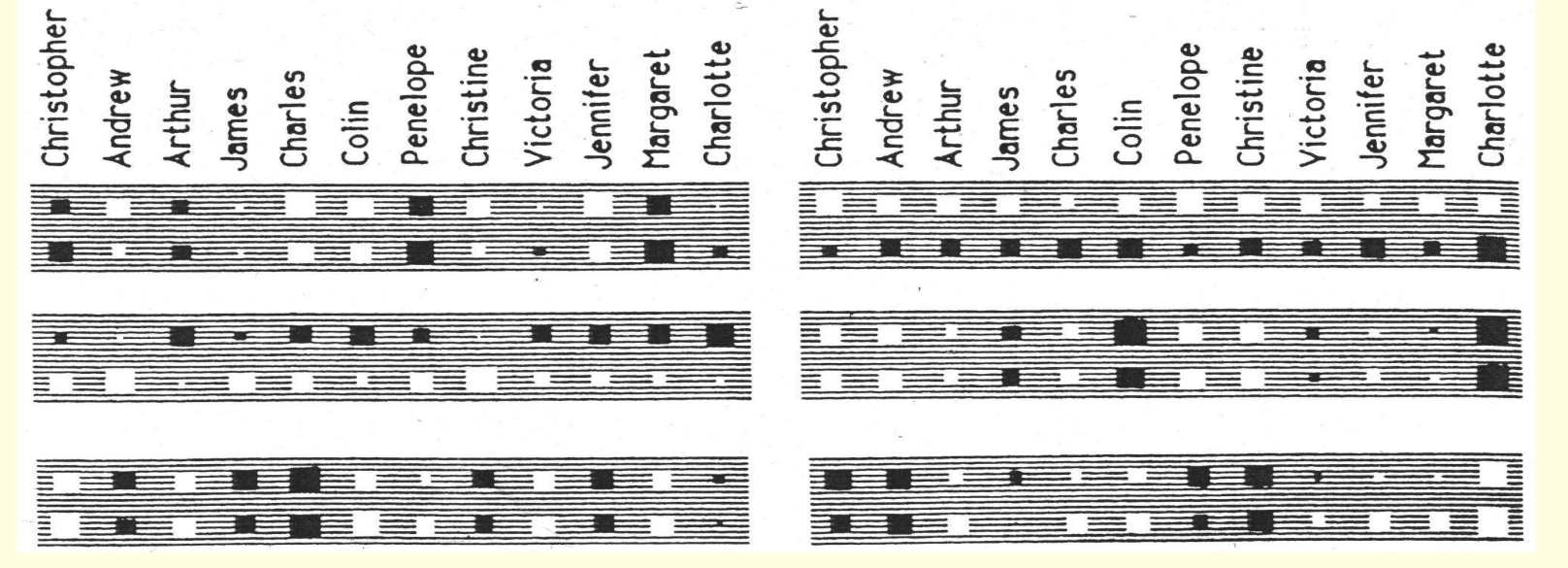
What the network learns ?
- The six hidden units in the bottleneck connected to the input representation of person 1 learn to represent features of people that are useful for predicting the answer.
- Nationality, generation, branch of the family tree.
- These features are only useful if the other bottlenecks use similar representations and the central layer learns how features predict other features. For example:
- Input person is of generation 3 and
- relationship requires answer to be one generation up
- implies
- Output person is of generation 2
Another way to see that it works
- Train the network on all but 4 of the triples that can be made using the 12 relationships
- It needs to sweep through the training set many times adjusting the weights slightly each time.
- Then test it on the 4 held-out cases.
- It gets about 3/4 correct.
- This is good for a 24-way choice.
- On much bigger datasets we can train on a much smaller fraction of the data.
A large-scale example
- Suppose we have a database of millions of relational facts of the form (A R B).
- We could train a net to discover feature vector representations of the terms that allow the third term to be predicted from the first two.
- Then we could use the trained net to find very unlikely triples. These are good candidates for errors in the database.
- Instead of predicting the third term, we could use all three terms as input and predict the probability that the fact is correct.
- To train such a net we need a good source of false facts.
A relational learning task
- Given a large set of triples that come from some family trees, figure out the regularities.
- The obvious way to express the regularities is as symbolic rules:
HasMother(x,y)\ and\ HasHusband(y,z) \implies HasFather(x, z)
- The obvious way to express the regularities is as symbolic rules:
- Finding the symbolic rules involves a difficult search through a very large discrete space of possibilities.
- Can a neural network capture the same knowledge by searching through a continuous space of weights?
The structure of the neural net
- The six hidden units in the bottleneck connected to the input representation of person 1 learn to represent features of people that are useful for predicting the answer.
- Nationality, generation, branch of the family tree. These features are only useful if the other bottlenecks use similar representations and the central layer learns how features predict other features. For example: Input person is of generation 3 and relationship requires answer to be one generation up implies Output person is of generation 2 This video introduces distributed representations. It’s not actually about predicting words, but it’s building up to that. It does a great job of looking inside the brain of a neural network. That’s important, but not always easy to do.
Reuse
CC SA BY-NC-ND
Citation
BibTeX citation:
@online{bochman2017,
author = {Bochman, Oren},
title = {Deep {Neural} {Networks} - {Notes} for Lecture 4a},
date = {2017-08-11},
url = {https://orenbochman.github.io/notes/dnn/dnn-04/l_04a.html},
langid = {en}
}
For attribution, please cite this work as:
Bochman, Oren. 2017. “Deep Neural Networks - Notes for Lecture
4a.” August 11, 2017. https://orenbochman.github.io/notes/dnn/dnn-04/l_04a.html.