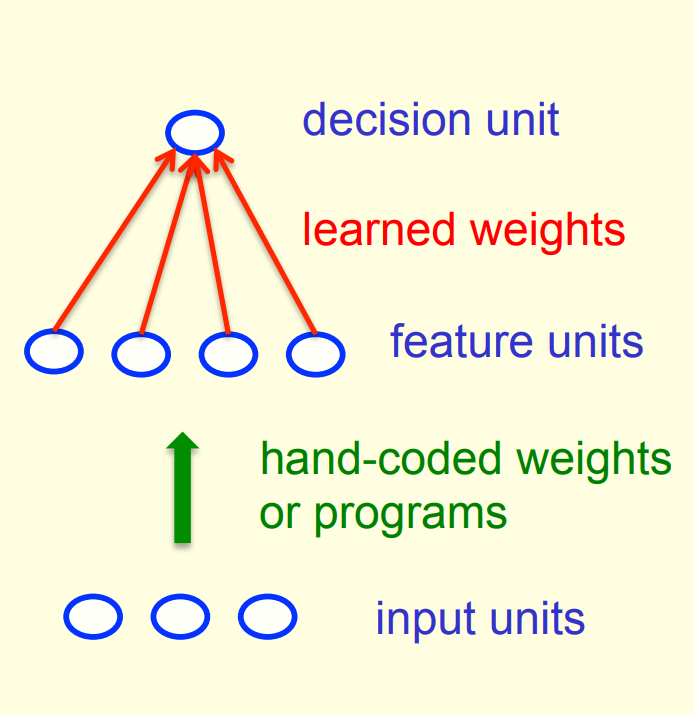
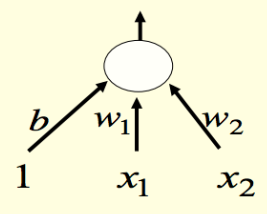
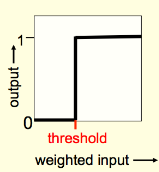
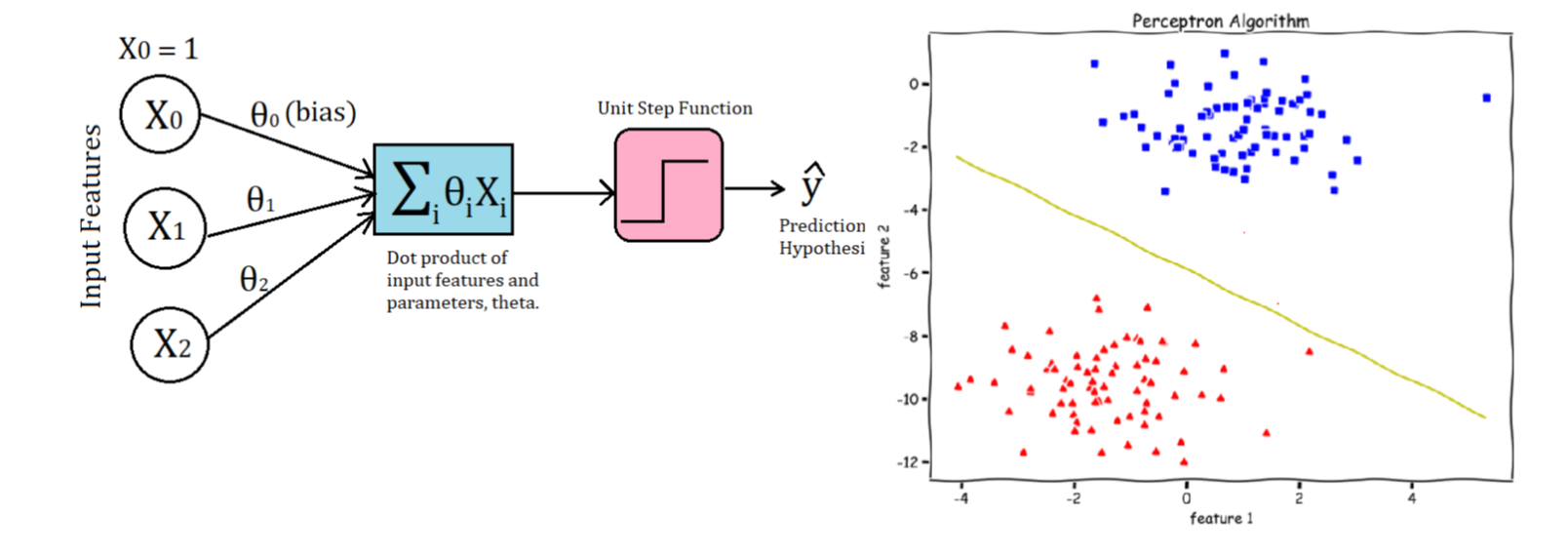
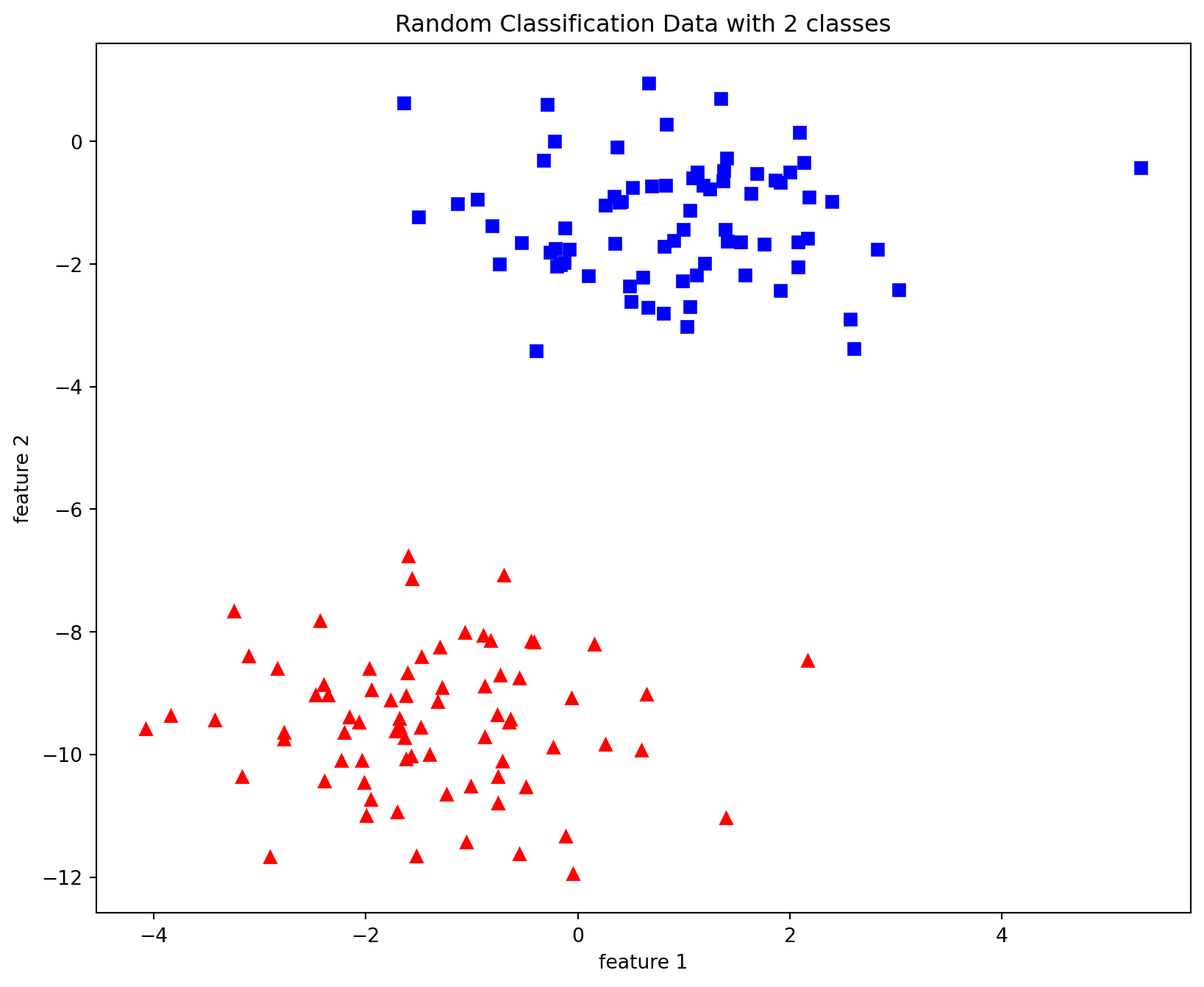
from sklearn import datasetsfrom matplotlib import pyplot as pltimport numpy as npX, y = datasets.make_blobs(n_samples=150,n_features=2, centers=2,cluster_std=1.05, random_state=2)#Plottingfig = plt.figure(figsize=(10,8))plt.plot(X[:, 0][y ==0], X[:, 1][y ==0], 'r^')plt.plot(X[:, 0][y ==1], X[:, 1][y ==1], 'bs')plt.xlabel("feature 1")plt.ylabel("feature 2")plt.title('Random Classification Data with 2 classes')def step_func(z):return1.0if (z >0) else0.0def perceptron(X, y, lr, epochs):''' X: inputs y: labels lr: learning rate epochs: Number of iterations m: number of training examples n: number of features ''' m, n = X.shape # Initializing parapeters(theta) to zeros.# +1 in n+1 for the bias term. theta = np.zeros((n+1,1))# list with misclassification count per iteration. n_miss_list = []# Training.for epoch inrange(epochs):# variable to store misclassified. n_miss =0# looping for every example.for idx, x_i inenumerate(X):# Inserting 1 for bias, X0 = 1. x_i = np.insert(x_i, 0, 1).reshape(-1,1) # Calculating prediction/hypothesis. y_hat = step_func(np.dot(x_i.T, theta))# Updating if the example is misclassified.if (np.squeeze(y_hat) - y[idx]) !=0: theta += lr*((y[idx] - y_hat)*x_i)# Incrementing by 1. n_miss +=1# Appending number of misclassified examples# at every iteration. n_miss_list.append(n_miss)return theta, n_miss_list
Text(0.5, 0, 'feature 1')
Text(0, 0.5, 'feature 2')
Text(0.5, 1.0, 'Random Classification Data with 2 classes')
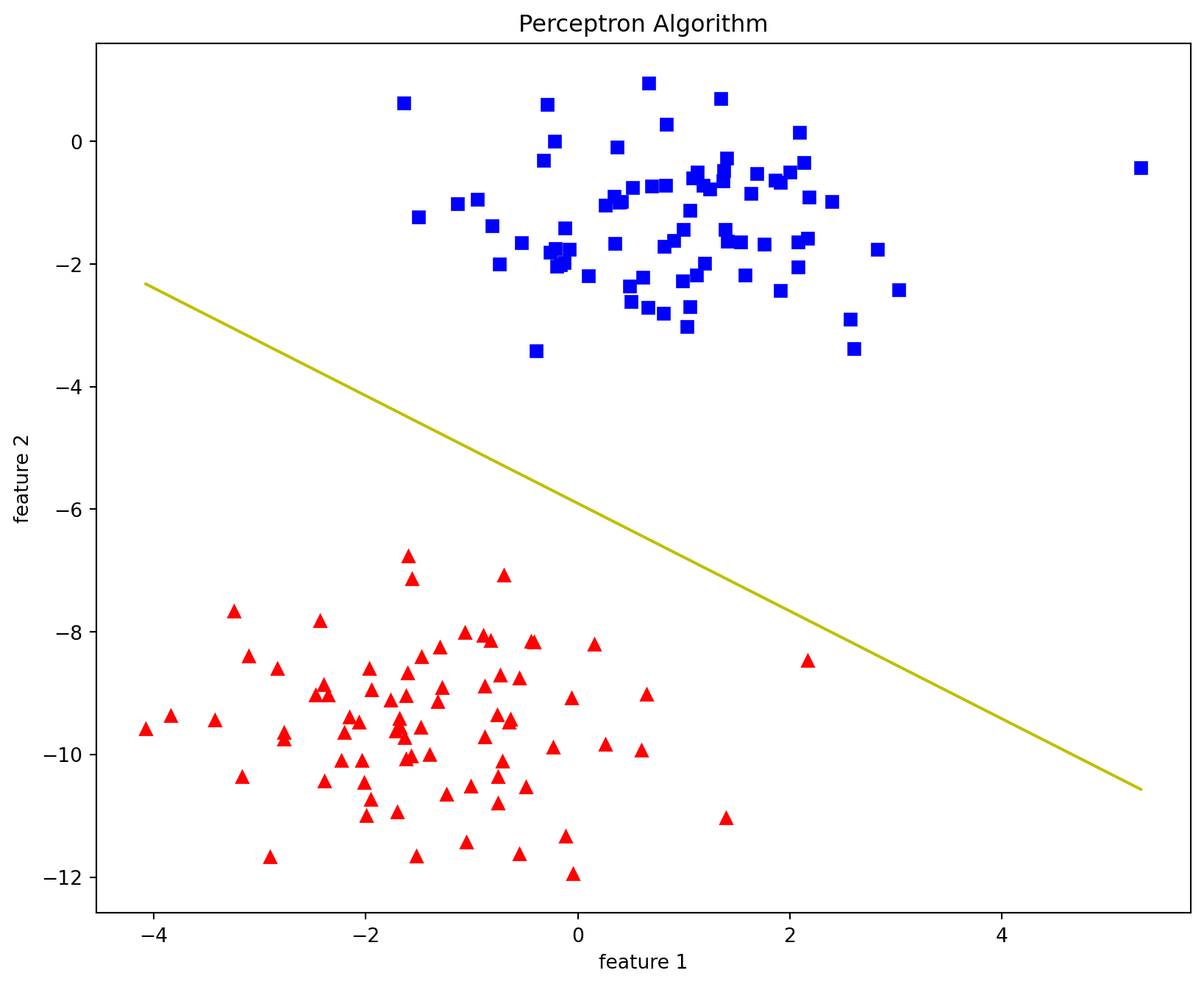
def plot_decision_boundary(X, theta):# X --> Inputs# theta --> parameters# The Line is y=mx+c# So, Equate mx+c = theta0.X0 + theta1.X1 + theta2.X2# Solving we find m and c x1 = [min(X[:,0]), max(X[:,0])] m =-theta[1]/theta[2] c =-theta[0]/theta[2] x2 = m*x1 + c# Plotting fig = plt.figure(figsize=(10,8)) plt.plot(X[:, 0][y==0], X[:, 1][y==0], "r^") plt.plot(X[:, 0][y==1], X[:, 1][y==1], "bs") plt.xlabel("feature 1") plt.ylabel("feature 2") plt.title('Perceptron Algorithm') plt.plot(x1, x2, 'y-')
theta, miss_l = perceptron(X, y, 0.5, 100)plot_decision_boundary(X, theta)
References
Mcculloch, Warren, and Walter Pitts. 1943. “A Logical Calculus of Ideas Immanent in Nervous Activity.”Bulletin of Mathematical Biophysics 5: 127–47.
Minsky, Marvin, and Seymour Papert. 1969. Perceptrons: An Introduction to Computational Geometry. Cambridge, MA, USA: MIT Press.
Rosenblatt, F. 1962. Principles of Neurodynamics: Perceptrons and the Theory of Brain Mechanisms. Cornell Aeronautical Laboratory. Report No. VG-1196-g-8. Spartan Books. https://www.google.com/books?id=7FhRAAAAMAAJ.