![]()
Question Answering
Notes for: NLP with Attention Models Week 4 Natural Language Processing with Attention Models - Chat Bots
Week’s Learning Objectives:
Deep learning and A.I. researchers push the field forward by looking for new techniques as well as refinements of old ideas to get better performance on tasks. In this lesson we cover reversible layers which allow us to leverage a time memory tradeoff to process book length sequences and handle contexts over a conversation.
Video 1 : Tasks with Long Sequences
In this week you are going to learn about tasks that require processing longer sequences: - Writing books - Storytelling and understanding - Building intelligent agents for conversations like chat-bots.

More specifically we will understand how re-former model (AKA the reversible transformer) and reversible layers work. This week you will learn about the bottlenecks in these larger transformer models, and solutions you can use to make them trainable for you. You will also learn about the. Here is what you will be building for your programming assignment: A chatbot!
In many ways a Chat bot is very similar to a Q&A system which we built last week and that is also similar to query based summarization another task we covered a week before that. The new challenge is to manage what parts of the new and old context we keep around as the dialogue progresses. Chatbot are smart A.I. agents and much of the techniques developed under the umbrella of knowledge-based AI is also relevant in developing these. For instance carrying out actions on behalf of the user. Chatbots can also get a very simple ui via the web or as an mobile app, which is another area I have some experience. However an even more powerful paradigm here is the ability to interact using voice which has many additional benefit for example supporting people with disabilities and operating in hands-free mode. Here is a link to an AI Storytelling system.
Video 2: Transformer Complexity

One of the biggest issues with the transformers is that it takes time and a lot of memory when training. Concretely here are the numbers. If you have a sequence of length L , then you need L^2*N memory to handle the sequence. So if you have N layers, that means your model will take N times more time to complete. As L gets larger, the memory and the time quickly increases.
Perhaps this is the reason people are looking into converting transformers into RNN after training.

When you are handling long sequences, you frequently don’t need to consider all L positions. You can just focus on an area of interest instead. For example, when translating a long text from one language to another, you don’t need to consider every word at once. You can instead focus on a single word being translated, and those immediately around it, by using attention.
To overcome the memory requirements you can recompute the activations. As long as you do it efficiently, you will be able to save a good amount of time and memory. You will learn this week how to do it. Instead of storing N layers, you will be able to recompute them when doing the back-propagation. That combined with local attention, will give you a much faster model that works at the same level as the transformer you learned about last week.
one area where we can make headway is working with a subsequence of interest.
during training we need to keep the activations in memory for the back propagation task. Clearly for inference we may be able to save on memory.
the alternative is to discard the activations as we go along and recalculate later. This can allows trading memory for compute time. However with larger models compute time is also a bottleneck.

Video 3: LSH Attention
In Course 1, we covered how locality sensitive hashing (LSH) works. You learned about:
- KNN
- Hash Tables and Hash Functions
- Locality Sensitive Hashing
- Multiple Planes
Here are the steps to follow to compute LSH given some vectors, where the vectors may correspond to the transformed word embedding that your transformer outputs.
Attention is used to try which query (q) and key (k) are the most similar. To do so, you hash q and the keys. This will put similar vectors in the same bucket that you can use. The drawing above shows the lines that separate the buckets. Those could be seen as the planes. Remember that the standard attention mechanism is defined as follows:
A(Q,K,V) = softmax(QK^T)V
Once you hash Q and K you will then compute standard attention on the bins that you have created. You will repeat the same process several times to increase the probability of having the same key in the same bin as the query.
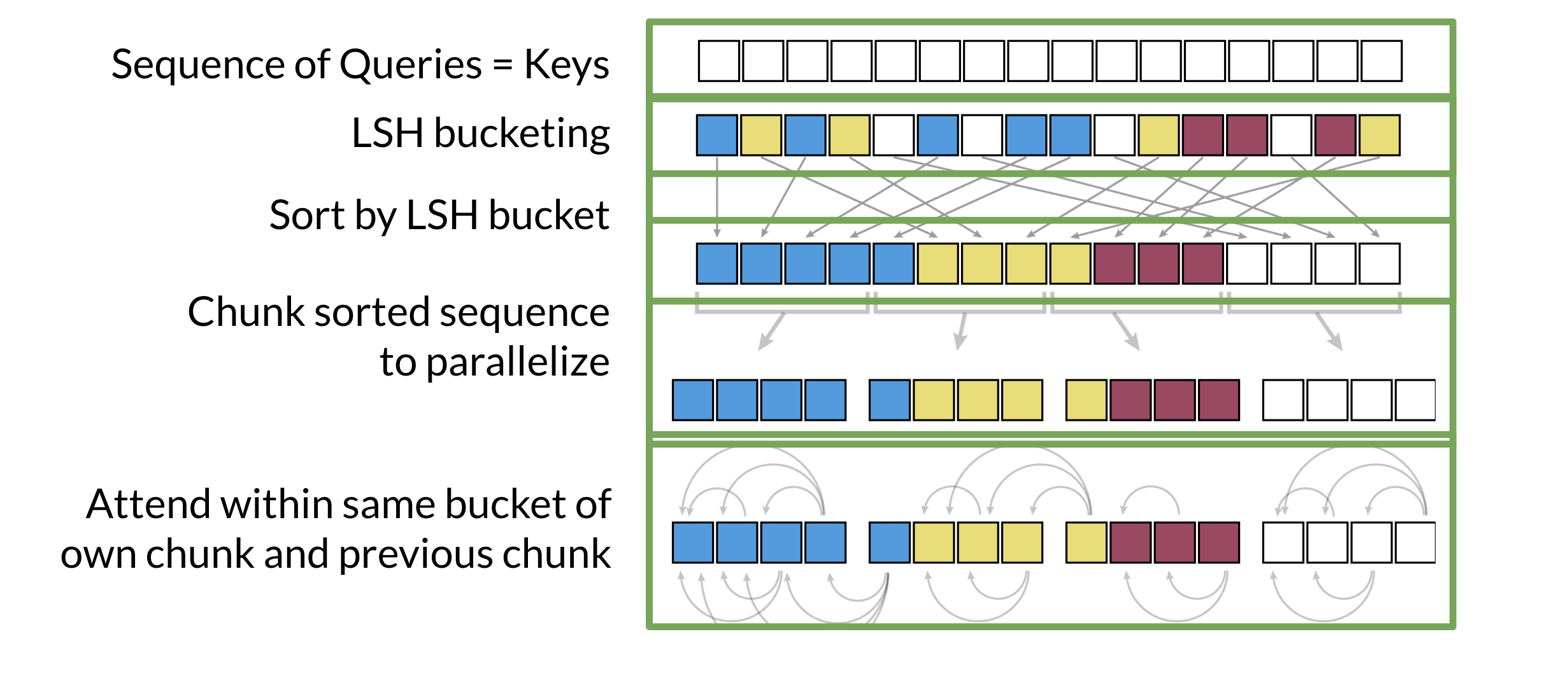
- Given the sequence of queries and keys, you hash them into buckets. Check out Course 1 Week 4 for a review of the hashing.
- You will then sort them by bucket.
- You split the buckets into chunks (this is a technical detail for parallel computing purposes).
- You then compute the attention within the same bucket of the chunk you are looking at and the previous chunk. > Q. Why do you need to look at the previous chunk?
You can see in the figure some buckets (both blue and yellow) have been split across two chunks. Looking at the previous chunk will let you attend to the full bucket.
In Winograd schemas the resolution of the ambiguous pronoun switches between the two variants of the sentence. > the animal didn’t cross the street because it was too tired > the animal didn’t cross the street because it was too wide >The city councilmen refused the demonstrators a permit because they feared violence. >The city councilmen refused the demonstrators a permit because they advocated violence.
Video 4 Motivation for Reversible Layers: Memory!
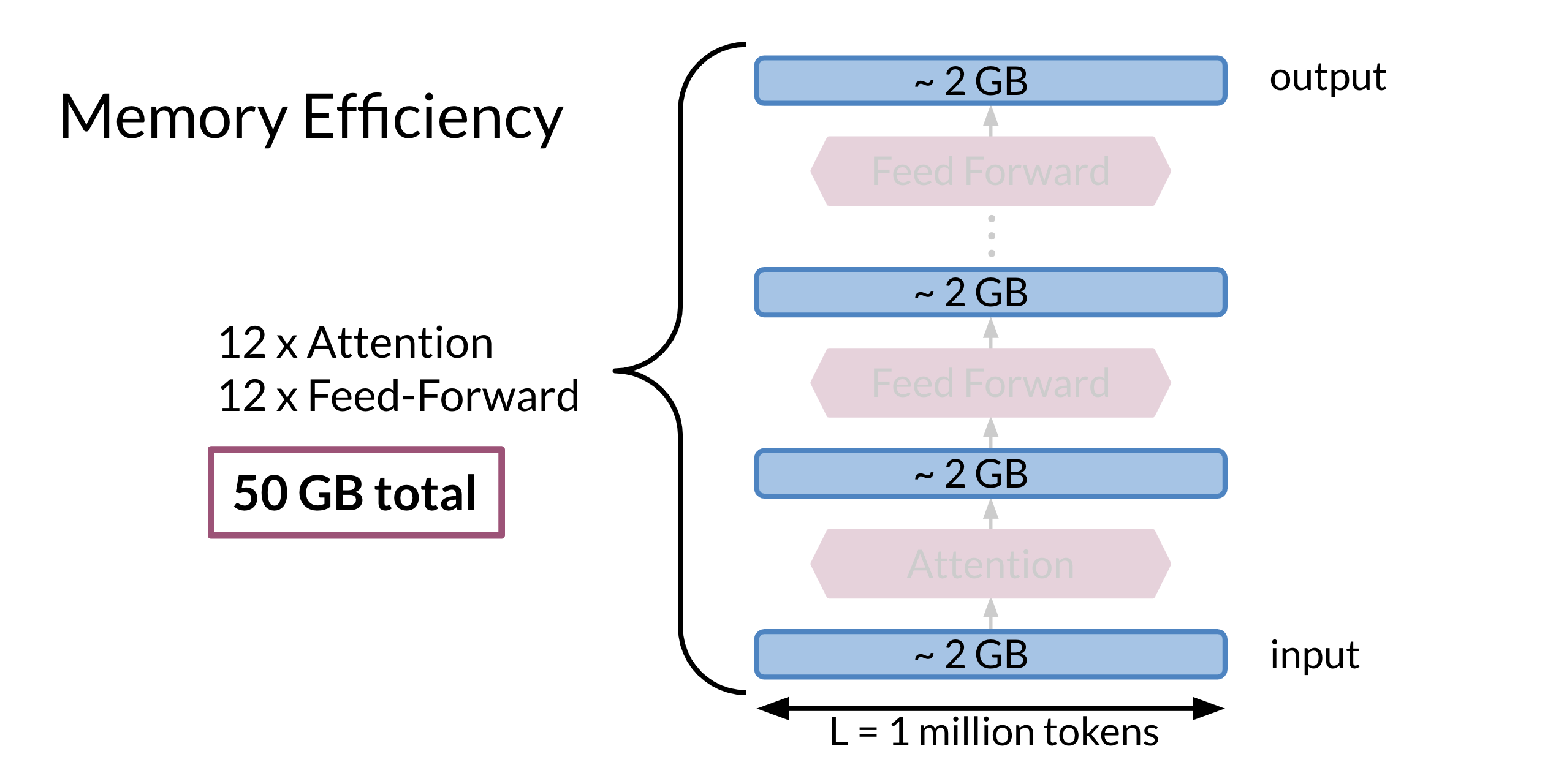
For example in this model:
- 2 GB for the input
- 2 GB are required to compute the Attention
- 2 GB for the feed forward. There are 12 attention layers 12 feed forward layers. That is equal to 12 * 2 + 12*2 + 2 (for the input) = 50 GB. That is a lot of memory.
If N is the sequence length:
- Transformers need O(N^2) memory.
Each layer of a transformers has an Attention block and feed-forward block. If we want to process, for example to train a document of length 1 million token with 12 layers we will need 50 GB of ram. As we use residual architecture during prediction we only need the current layers input and the output for the next layer. But during training we need to keep all the copies so we can back-propagate the errors.
Video 5 Reversible Residual Layers
Video 6 Reformer
can run 1 million token in 16 gb
Lab 2: Reversible layers
From the trax documents a Residual, involves first a split and then a merge:
return Serial(
Branch(shortcut, layer), # split
Add(), # merge
)where:
Branch(shortcut, layers): makes two copies of the single incoming data stream, passes one copy via the shortcut (typically a no-op), and processes the other copy via the given layers (applied in series). [𝑛_{𝑖𝑛}=1, 𝑛_{𝑜𝑢𝑡}=2]Add(): combines the two streams back into one by adding two tensors element-wise. [𝑛_{𝑖𝑛}=2, 𝑛_{𝑜𝑢𝑡}=1] In theBranchoperation each layer in the input list copies as many inputs from the stack as it needs, and their outputs are successively combined on stack. Put another way, each element of the branch can have differing numbers of inputs and outputs. Let’s try a more complex example. To work these operations modify the stack by replicating the input needed as well as pushing the outputs (as specified using thoutparameters).
References:
https://arxiv.org/pdf/1509.02897.pdf
Tokenization
- SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing (Kudo & Richardson 2018) sub-word tokenization
- Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates (Kudo 2018) sub-word tokenization
- Neural Machine Translation of Rare Words with Subword Units (Sennrich et all 2016) sub-word tokenization
- Subword tokenizers TF tutorial sub-word tokenization
- [https://blog.floydhub.com/tokenization-nlp/]
- Swivel: Improving Embeddings by Noticing What’s Missing (Shazeer, 2016)
Transformers
- Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer (Raffel et al, 2019)
- Reformer: The Efficient Transformer (Kitaev et al, 2020)
- Attention Is All You Need (Vaswani et al, 2017)
- Deep contextualized word representations (Peters et al, 2018)
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (Devlin et al, 2018)
- Finetuning Pretrained Transformers into RNNs (Kasai et all 2021)
- The Illustrated Transformer (Alammar, 2018)
- The Illustrated GPT-2 (Alammar, 2019)
- How GPT3 Works - Visualizations and Animations (Alammar, 2020)
- Attention? Attention! (Lilian Weng, 2018)
- The Transformer Family (Lilian Weng, 2020)
- Teacher forcing for RNNs
Question Answering Task:
Links
- Jax
- Trax
- Trax community on Gitter
- CNN daily mail dataset
Lei Mao Machine Learning, Artificial Intelligence, Computer Science. [Byte Pair Encoding (Lei Mao 2021)] (https://leimao.github.io/blog/Byte-Pair-Encoding/) videos:
Q&A
Subword tokenizers Swivel Embeddings https://youtu.be/hAvtJ516Mw4
Reuse
Citation
@online{bochman2021,
author = {Bochman, Oren},
title = {Week 4 {Chat} {Bots}},
date = {2021-04-27},
url = {https://orenbochman.github.io/notes/deeplearning.ai-nlp-c4/2021-04-27-c4w4-chat-bots.html},
langid = {en}
}