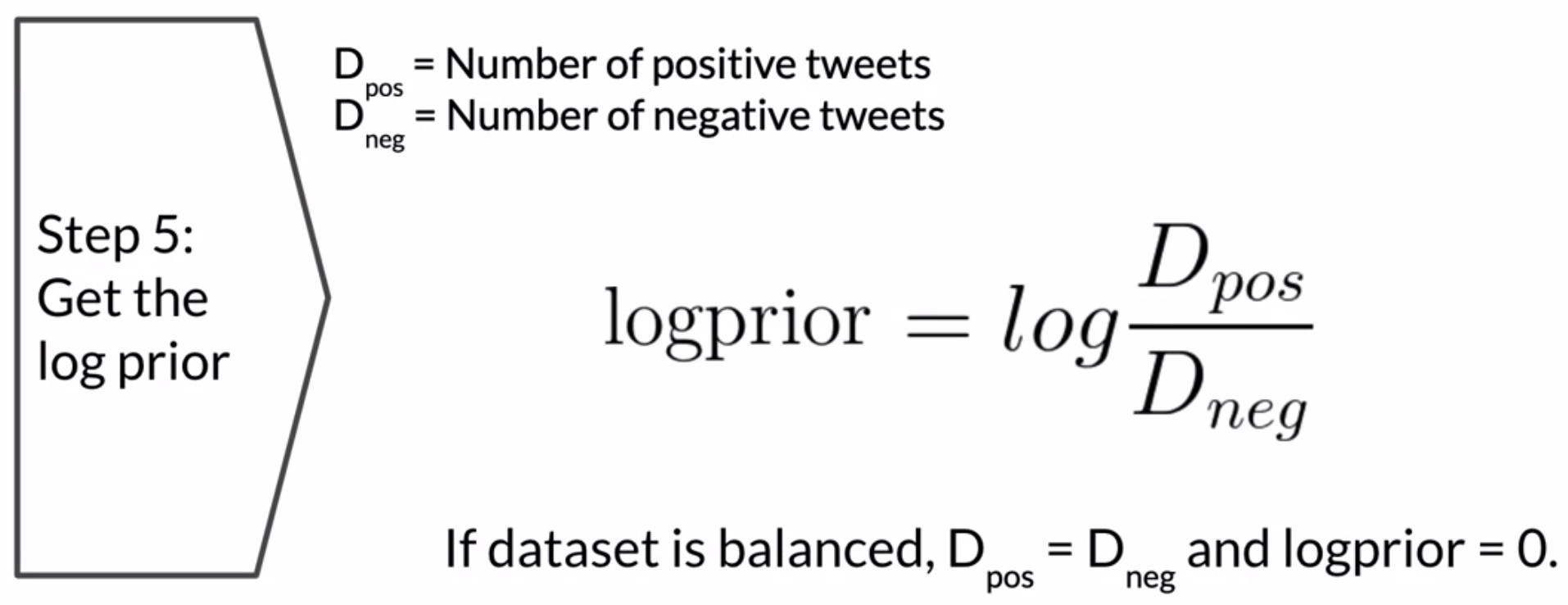Classification & Vector Spaces - Probability and Bayes’ Rule
Course 1 of NLP Specialization
Concepts, code snippets, and slide commentaries for this week’s lesson of the Course notes from the deeplearning.ai natural language programming specialization.
NLP
Coursera
notes
deeplearning.ai
course notes
Conditional Probability
Bayes rule
Naïve Bayes
Laplace smoothing
Log-likelihood
classification
sentiment analysis task
bibliography
Author
Oren Bochman
Published
Friday, October 23, 2020
Since I majored in Mathematics, I glossed over many details when I took the initial notes, since the course caters to all levels of students. When I migrated the notes from OneNotes to the web, I updated and reviewed the current course material and at times additional notes by (Chadha 2020) and (Jelliti2020NLP?). I have tried to add my own insights from other sources, books I read or others courses I have taken. ::: callout-note
Naïve Bayes
Naïve Bayes is a probabilistic algorithm commonly used in machine learning for classification problems. It’s based on Bayes’ theorem, which is a fundamental concept in probability theory. Naïve Bayes assumes that all the features of the input data are independent of each other, which is why it’s called “naïve.” ::: The following two results are due to (NIPS2001_7b7a53e2?) by way of Naive_Bayes_classifier wikipedia article. Another detail that can help you make sense of this lesson is the following result relating Naïve Bayes to Logistic Regression which we covered last week. In the case of discrete inputs (indicator or frequency features for discrete events), naive Bayes classifiers form a generative-discriminative pair with multinomial logistic regression classifiers: each naive Bayes classifier can be considered a way of fitting a probability model that optimizes the joint likelihood p (C,x), while logistic regression fits the same probability model to optimize the conditional p(C∣x). ::: callout-note ## Theorem — Naive Bayes classifiers on binary features are subsumed by logistic regression classifiers. ### Proof Consider a generic multiclass classification problem, with possible classes {\displaystyle Y\in \{1,...,n\}} , then the (non-naive) Bayes classifier gives, by Bayes theorem:
{ p(Y\mid X=x)={\text{softmax}}(\{\ln p(Y=k)+\ln p(X=x\mid Y=k)\}_{k})}
The naive Bayes classifier gives
{ {\text{softmax}}\left(\left\{\ln p(Y=k)+{\frac {1}{2}}\sum _{i}(a_{i,k}^{+}-a_{i,k}^{-})x_{i}+(a_{i,k}^{+}+a_{i,k}^{-})\right\}_{k}\right)}
where
{ a_{i,s}^{+}=\ln p(X_{i}=+1\mid Y=s);\quad a_{i,s}^{-}=\ln p(X_{i}=-1\mid Y=s)}
This is exactly a logistic regression classifier. :::
Introduction
We start with a corpus of 20 tweets that can be categorized as having either positive+ or negative- sentiment, but not both. ::: callout-caution
Research questions
How can we model our corpus using probability theory?
How can we infer the sentiment of a tweet based on our corpus ::: Since we can use the sum rule, product rule and Bayes rule which we shall cover shortly to manipulate probabilities we start by representing what we know about our corpus using probabilities. ## Probability of a randomly selected tweet’s sentiment
To calculate a probability of a certain event happening, you take the count of that specific event and divide it by the sum of all events.
Furthermore, the sum of all probabilities has to equal 1. If we pick a tweet at random, what is the probability of it being +? We define an event A: “A tweet is positive” and calculate its probability
P(A) = P(+) = \frac{N_{+}}{N}=\frac{13}{20}=0.65
And since probabilities add up to one:
P(-) = 1- P(+)=0.35
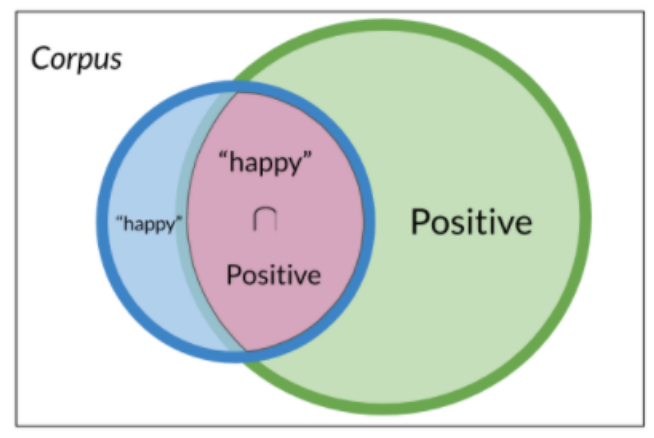
## Probabiliy for a specific word’s sentiment Within that corpus, the word happy is sometimes labeled + and in other cases, -. This indicates that some negative tweets contain the word happy. Shown below is a graphical representation of this “overlap”. Let’s explore how we may represent this graphically using a venn diagram and then derive a probability-based representation. First, we need to estimate the probability of the event B: “tweets containing the word happy”
P(B) = P(Happy)=\frac{N_{happy}}{N}=\frac{4}{20}=0.2
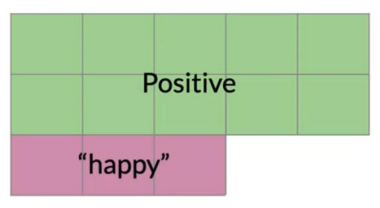
To compute the probability of 2 events happening like happyand+ in the picture you would be looking at the intersection, or overlap of the two events, In this case, the red and the blue boxes overlap in three boxes, So the answer is:
P(A \cap B) = P(A,B) = \frac{2}{20}
The Event “A is labeled +”, - The probability of events A shown as P(A) is calculated as the ratio between the count of positive tweets and the corpus divided by the total number of tweets in the corpus. ::: {.column-margin layout-ncol=“1”} specific tweets color coded per the Venn diagram ::: ::: callout-note
Definition of conditional probability
Conditional probability is the probability of an outcome B when we already know for certain that an event A has already happened. Notation:
P(B|A)
::: - and there more + than - more specifically our prior knowledge is that :
\frac{P(+)}{P(−)}=\frac{13}{7}
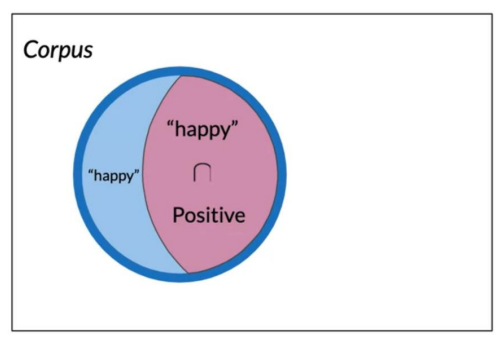
- the likelihood of a tweet with happy being + is - the challenge arises from some words being in both + and - tweets Conditional probabilities help us reduce the sample search space by restricting it to a specific event which is a given. We should understand the difference between P(A|B) and P(B|A) ## what is P(+|happy) - We start with the Venn diagram for the P(A|B). - Where we restricted the diagram to just A the subset of happy tweets. - And we just want those tweets that are also + i.e. (B). - all we need is to plug in the counts from our count chart. - which we now estimate
P(A|B) = P(Positive|happy) = \frac{3}{4} = 0.75
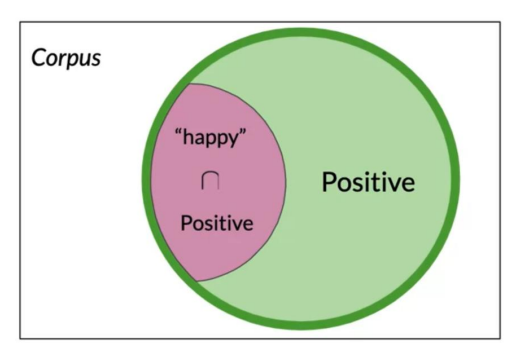
## what is P(happy|+) - We start with the Venn diagram for the P(B|A) - where we have restricted the diagram to just B the subset of + tweets. - and we just want from those the tweets that are also happy i.e. (A). - and the counts for P(B|A) - which we now estimate
P(B|A) = P(happy|Positive) = \frac{3}{13} = 0.231
Bayes’ rule
From this, we can now write:
P(+|happy) = \frac{P(+ \cap happy) }{P(happy)}
and
P(happy|+) = \frac{P(happy \cap +) }{P(+)}
we can combine these since the intersections are the same and we get
P(+|happy) = \frac{P(+ \cap happy) }{P(happy)} = \frac{P(happy|+) \times P(+) }{P(happy)}
which generalizes to:
P(X|Y) = \frac{P(Y|X) \times P(X) }{P(Y)}
which we call Bayes rule ::: callout-note ## Bayes Rule Bayes Rule is the rule for inverting conditional probabilities. ::: However, we gain a deeper insight by considering that Bayes’s rule is more than just a tool for inverting conditional probabilities but the basis of a casual framework for updating our beliefs as we uncover new evidence.
p(H|e)=\frac{P(e|H) \times P(H)}{P(e|H)+P(e|\bar H)} = \frac{P(e|H) \times P(H)}{P(e)}
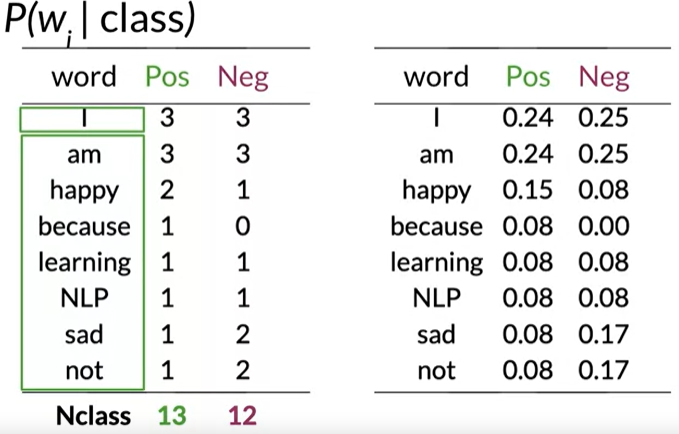
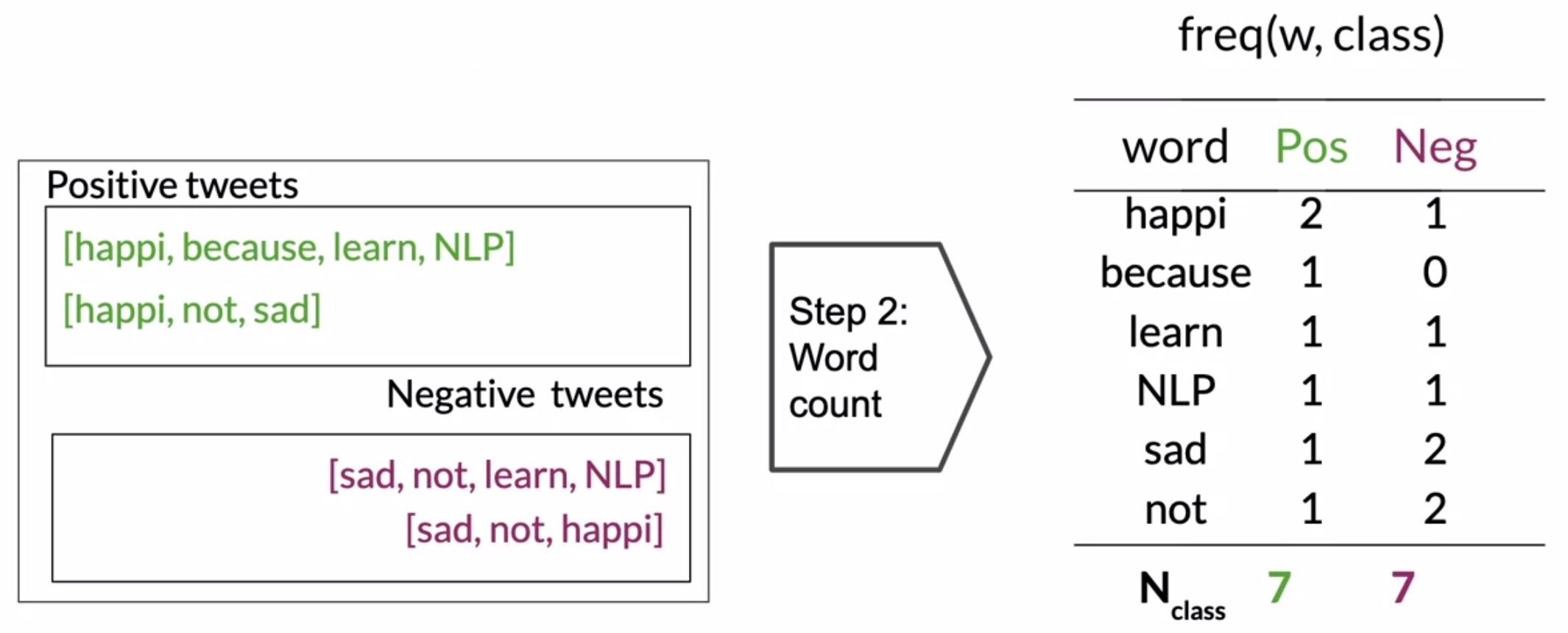
to reflect the notion of updating using new data. where we call: - p(H|e) the posterior - P(H) the prior - P(e|H) the likelihood (of evidence given the Hypothesis is true). - P(e) the marginal ## Naïve Bayes Introduction Here is a sample corpus ::: {#table-tweets } |+ tweets| - tweets | |—————|——————-| |I am happy because I am learning NLP |I am sad, I am not learning NLP | |I am happy |I am sad | And these are the class frequencies and probabilities Table of tweets :::
import pandas as pdimport string raw_tweets=["I am happy because I am learning NLP","I am sad, I am not learning NLP","I am happy, not sad","I am sad, not happy",]def clean(tweet:str):return tweet.translate(str.maketrans('', '', string.punctuation)).lower()tweets = [clean(tweet) for tweet in raw_tweets]labels=['+','-','+','-']df = pd.DataFrame({'tweets': tweets, 'labels': labels})df
tweets
labels
0
i am happy because i am learning nlp
+
1
i am sad i am not learning nlp
-
2
i am happy not sad
+
3
i am sad not happy
-
import numpy as npfrom collections import Counterp_freq,n_freq = Counter(), Counter()#print( df[df.labels == '+']['tweets'].to_list())[p_freq.update(tweet.split()) for tweet in df[df.labels =='+']['tweets'].to_list()][n_freq.update(tweet.split()) for tweet in df[df.labels =='-']['tweets'].to_list()]print(p_freq)print(n_freq)vocab =list(set(p_freq.keys()).union(set(n_freq.keys())))pos_freq = [p_freq[word] for word in vocab ]neg_freq = [n_freq[word] for word in vocab ]vocab_df=pd.DataFrame({'vocab':vocab,'pos_freq':pos_freq,'neg_freq':neg_freq})vocab_df['p_pos']=vocab_df.pos_freq/vocab_df.pos_freq.sum()vocab_df['p_neg']=vocab_df.neg_freq/vocab_df.neg_freq.sum()vocab_df['p_pos_sm']=(vocab_df.pos_freq+1)/(vocab_df.pos_freq.sum()+vocab_df.shape[1])vocab_df['p_neg_sm']=(vocab_df.neg_freq+1)/(vocab_df.neg_freq.sum()+vocab_df.shape[1])vocab_df['ratio']= vocab_df.p_pos_sm/vocab_df.p_neg_smvocab_df['lambda']= np.log(vocab_df.p_pos_sm/vocab_df.p_neg_sm)pd.set_option('display.float_format', '{:.2f}'.format)vocab_dfprint(vocab_df.shape)
Let’s motivate the Naïve Bayes inference condition rule for binary classification: To build a classifier, we will first start by creating conditional probabilities given the table; - We want to find if given our prior knowledge of P(+) and P(-) if a new tweet has + or - sentiment. - To do that we will estimate p(+|T) and p(-|T) and then decide based on which is greater than 0.5. We can use the Bayes rule:
p(+|T) = \frac{ p(T|+) \times p(+) }{ p(T) }
and
p(-|T) = \frac{ p(T|-) \times p(-) }{ p(T) }
where: - p(+|T) is the posterior probability of a label + given tweet T - p(+) is our prior knowledge - p(T|+) is the likelihood of tweet T being +. - {p(T)} The term p(T) is in both terms and can be eliminated. However, it will cancel out when we use the ratio for the inference. This lets us compute the following table of probabilities; word am learning NLP Pos 0.24 0.08 0.08 Neg 0.25 0.08 0.08 .17 Naïve Bayes is the simplest probabilistic graphical model which comes with an independence assumption for the features.
p(T|+) = \prod^m_{i=1}P(w_i|+) \implies p(+|T)=\frac{P(+)}{P(T)} \prod^m_{i=1}P(w_i|+)
and
p(T|−) = \prod^m_{i=1}P(w_i|−) \implies p(−|T) = \frac{P(−)}{P(T)} \prod^m_{i=1} P(w_i|−)
Once you have the probabilities, you can compute the likelihood score as follows: Tweet: I am happy today: I am learning. - Since there is no entry for today in our conditional probabilities table, this implies that this word is not in your vocabulary. So we’ll ignore its contribution to the overall score. - All the neutral words in the tweet such as I and am cancel out in the expression, as shown in the figure below.
\prod^m_{i=1} \frac{P(w_i|+)}{P(w_i|-)}= \frac {0.14}{0.10} =1.4 > 1
- A score greater than 1 indicates that the class is positive, otherwise, it is negative.
P(+|T) > P(−|T)
then we infer that the T has + sentiment. dividing by the right term we get the inference rule:
\frac{P(+|T)}{P(−|T)} > 1
which expands to :
\frac {P(+|T)}{P(−|T)} = \frac {P(+)}{P(-)}\prod^m_{i=1} \frac {P(w_i|+)}{P(w_i|−)} > 1
This is the inference rule for naïve Bayes. Note: Naïve Bayes is a model which assumes all features are independent, so the basic component here is:
\frac{P(w_i|+)}{P(w_i|-)} > 1
the ratio of the probability that a word appears in a positive tweet and that it appears in a negative tweet
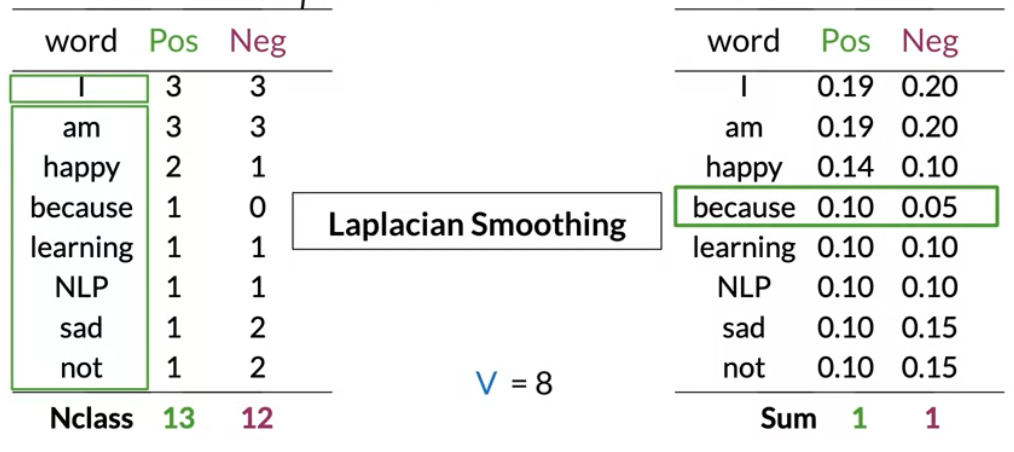
Laplace smoothing
Smoothing
A probability distribution can take zero values at certain points i.e. for certain inputs. Smoothing is a family of techniques for improving our estimate of conditional class probabilities to estimate probabilities for missing words. The name smoothing comes from the fact that these techniques tend to make distributions more uniform, by adjusting low probabilities such as zero probabilities upward, and high probabilities downward. Not only do smoothing methods generally prevent zero probabilities, but they also attempt to improve the accuracy of the model as a whole. Whenever a probability is estimated from a few counts, smoothing has the potential to improve estimation.
The course introduces smoothing here since sparsity breaks the naive Bayes model. But smoothing and filtering are big topics in NLP and Data Science. I have added some extra info drawn from (Jurafsky and Martin 2000)Laplace smoothing also called add one smoothing replaces a distribution with zero probabilities (due to sparse data) with a distribution that steals some mass and spreads it over the points which were zero. It solves the data sparsity issue but Laplace smoothing will skew/bias the probabilities (it affects rare and common probabilities differently) giving you behavior that is hard to explain, as it assigns too much mass to unknown words. When we compute the conditional probability P(w|class) using:
P(w_i|class) = \frac{freq(w_i,class)}{N_{class}} \qquad class \in \{ +, -\}
If a word does not appear in the training corpus or is missing from one of the classes then its frequency is 0 so it gets a probability of 0. Since we are taking products of probabilities, and soon we will take logs of probabilities and zeros present us with a numerical problem that we can address using smoothing as follows:
P(w_i|class) = \frac{freq(w_i,class) + 1}{N_{class} + |V|}
where: - N_{class} is the frequency of all words in a class. - V is unique words in the vocabulary Note: that we added a 1 in the numerator and since there are |V| words to normalize we add |V| in the denominator so that all the probabilities sum up to 1.
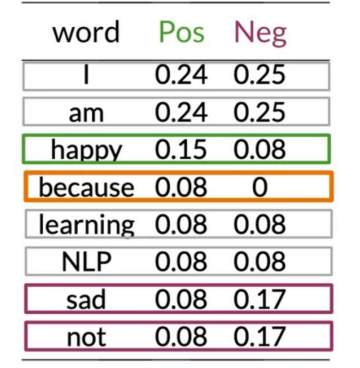
Table 3: P(w_i|class) no smoothing {#tbl-unsmoothed} | word | + | - | |———-|:—-:|:—-:| | I | 0.20 | 0.20 | | am | 0.20 | 0.20 | | happy | 0.14 | 0.10 | | because | 0.10 | 0.05 | | learning | 0.10 | 0.10 | | NLP | 0.10 | 0.10 | | sad | 0.10 | 0.15 | | not | 0.10 | 0.15 | : P(w_i|class) with smoothing {#tbl-smoothing} Probabilities
word
+
-
I
0.24
0.25
am
0.24
0.25
happy
0.15
0.08
because
0.08
0.00
learning
0.08
0.08
NLP
0.08
0.08
sad
0.08
0.17
not
0.08
0.17
Additive smoothing:
p_{addative}(w_i|class)=\frac{ freq(w,class)+\delta}{ N_{class} + \delta \times V}
## More alternatives to Laplacian smoothing - Kneser-Ney smoothing(NEY19941?) which corrects better for smaller data sets. - Good-Turing smoothing(Good 1953) which uses order statistics to give even better estimates. with a survey of the subject here: Chen and Goodman (1996)
recall that
\frac {P(+|T)}{P(−|T)} = \frac {P(+)}{P(-)}\prod^m_{i=1} \frac {P(w_i|+)}{P(w_i|−)} > 1
taking logs we get
\log \frac{P(+|T)}{P(−|T)} = \log \frac {P(+)}{P(-)} + \sum^m_{i=1} \lambda(w_i) > 0
where
\lambda(w_i) = log \frac {P(w_i|+)}{P(w_i|−)}
To compute the likelihood, we need to get the ratios and use them to compute a score that Will allow us to decide if a tweet is positive or negative. The higher the ratio, the more positive the word. - Long Products of small probabilities create a risk of numeric underflow. - logs let us mitigate this risk.
\lambda(w) = \log \frac{p(w|+)}{p(w|-)}
\log prior = \log \frac{p(+)}{p(-)}
Where D_{+} and D_{-} correspond to the number Of negative documents respectively.
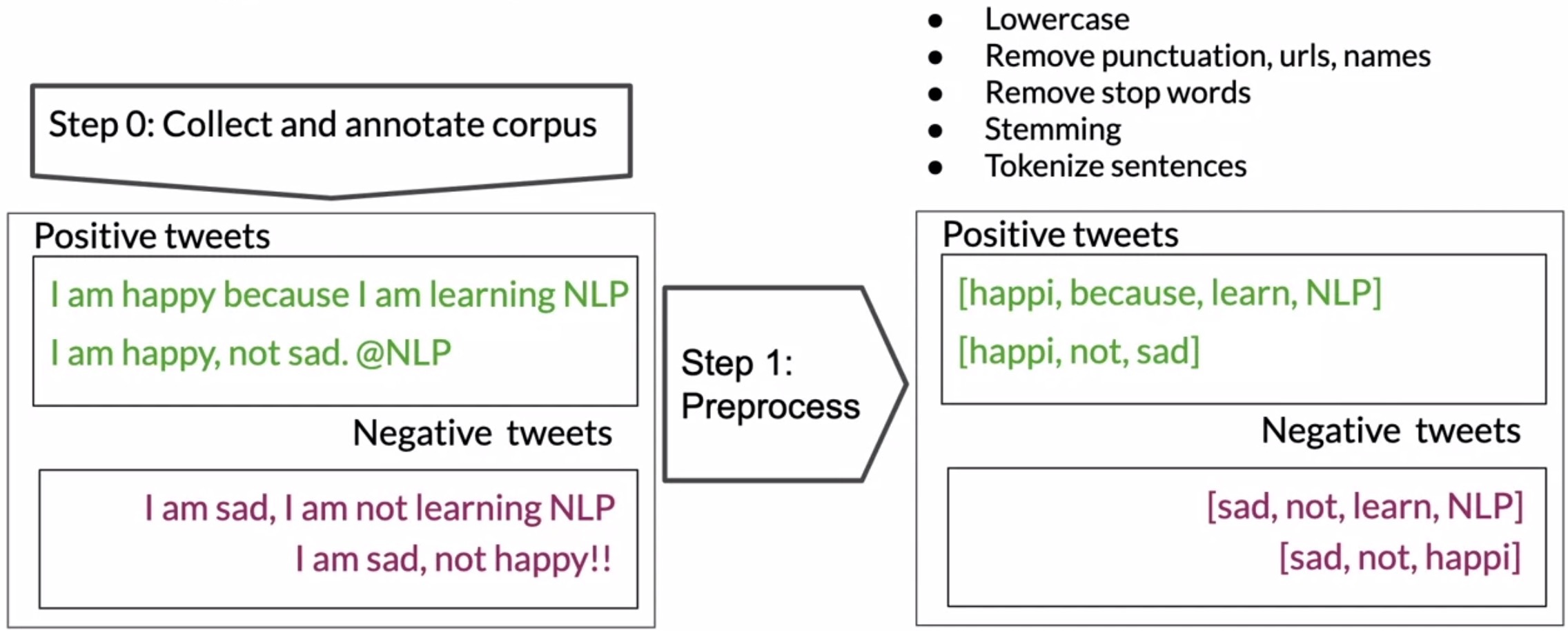
Training Naïve Bayes
To train a naïve Bayes classifier, we should perform the following steps: 1. Get or annotate a dataset with positive and negative tweets 2. preprocess the tweets. - Tokenize sentences - Remove punctuation, URLs and names - Remove stop words - Stem words
3. Compute the vocaulary: freq(word, class) 4. Use Laplacian smoothing to estimate word class probabilites P(w|+) and P(w|-). 5. Compute \lambda(w) = \log \frac{p(w|+)}{p(w|-)} 6. Compute logprior = \log \frac{p(w|+)}{p(w|-)} Where D_{+} and D_{-} correspond to the number Of negative documents respectively.
Testing Naïve Bayes
Let’s work on applying the Naïve Bayes classifier on validation examples to compute the model’s accuracy. The steps involved in testing a Naïve Bayes model for sentiment analysis are as follows: 1. Use the validation set to test the model on tweets it has not seen. Which is comprised of a set of raw tweets X_{val}, and their corresponding sentiments, Y_{val}. 1. We use the conditional p(word|state) and use them to predict the sentiments of new unseen tweets, 2. We apply Pre-processing: as before in training. 3. Lookup the \lambda score for each unique word: Using the \lambda table (i.e., the log-likelihood table). - Words that have entries in the table, are summed over all the corresponding \lambda terms. - Unknown words are skipped as words that lack a log-likelihood in the table are considered neutral. 4. Obtain the overall score by summing up the scores of all the individual words, along with with our estimation of the log prior (important for an unbalanced dataset), we get the overall sentiment score of the new tweet. 5. Check against the threshold we check if the sentiment score >0 . Let’s consider an example tweet, "I passed the NLP interview", and use our trained model to predict if this is a positive or negative tweet: - Look up each word from the vector in your log-likelihood table. Words such as “I”, “pass”, “the”, and “NLP”, have entries in the table, while the word interview does not (which implies that it needs to be ignored). Now, add the log before accounting for the imbalance of classes in the dataset. Thus, the overall score sums up to 0.48, as shown in the figure below. - Recall that if the overall score of the tweet is larger than 0, then this tweet has a positive sentiment, so the overall prediction is that this tweet has a positive sentiment. Even in real life, passing the NLP interview is a very positive thing.
Naïve Bayes Applications
There are many applications of naïve Bayes including: - Author identification - Spam filtering - Information retrieval - Word disambiguation
This method is usually used as a simple baseline.
It is also really fast.
Naïve Bayes Assumptions
Naïve Bayes makes the independence assumption and is affected by the word frequencies in the corpus. For example, if you had the following "It is sunny and hot in the Sahara desert." `“It’s always cold and snowy in …”In the first image, you can see the word sunny and hot tend to depend on each other and are correlated to a certain extent with the"desert", Naïve Independence throughout, Furthermore, if you were to fill in the sentence on the right. this naïve model will assign equal weight to the words : - spring. - summer, - fall, - winter, Relative frequencies in the corpus On Twitter, there are usually more positive tweets than negative ones However, some clean datasets are artificially balanced to have the same amount of positive and negative tweets. Just keep in mind, that in me real world. the data could be much noisier. ## Sources of Errors in Naïve Bayes ### Error Analysis Bad sentiment classifications are due to: 1. preprocessing dropping punctuation that encodes emotion like asad smiley`. 1. Word order can contribute to meaning - breaking the independence assumption of our model 1. Pronouns removed as stop words - may encode emotion 1. Sarcasm can confound the model 1. Eupemisms are also a challange
resources:
notes on the course by
References
Chadha, Aman. 2020. “Distilled Notes for the Natural Language Processing Specialization on Coursera (Offered by Deeplearning.ai).”https://www.aman.ai. www.aman.ai.
Chen, Stanley F., and Joshua T. Goodman. 1996. “An Empirical Study of Smoothing Techniques for Language Modeling.”https://arxiv.org/abs/cmp-lg/9606011.
Good, I. J. 1953. “The Population Frequencies of Species and the Estimation of Population Parameters.”Biometrika 40 (3-4): 237–64. https://doi.org/10.1093/biomet/40.3-4.237.
Jurafsky, D., and J. H. Martin. 2000. Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition. Prentice Hall Series in Artificial Intelligence. Prentice Hall. https://books.google.co.il/books?id=85BvQgAACAAJ.
Reuse
CC SA BY-NC-ND
Citation
BibTeX citation:
@online{bochman2020,
author = {Bochman, Oren},
title = {Classification \& {Vector} {Spaces} - {Probability} and
{Bayes’} {Rule}},
date = {2020-10-23},
url = {https://orenbochman.github.io/notes/deeplearning.ai-nlp-c1/l2-naive-bayes/l2-native-bayes.html},
langid = {en}
}
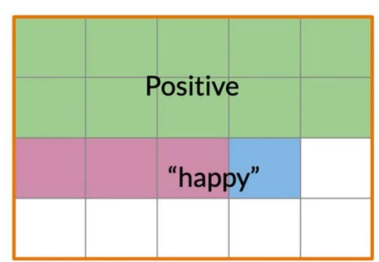 specific tweets color coded per the Venn diagram ::: ::: callout-note
specific tweets color coded per the Venn diagram ::: ::: callout-note