We will start by defining diagnosis. From there we will proceed to setup two spaces: A data spaces and a hypothesis space to collect data on the malfunctioning system. The goal being to generate hypothesis for the fault that can explain th system malfunction. We will construct mappings from data space to hypothesis space which amount to diagnosis. We’ll present two views of diagnosis, diagnosis as classification and diagnosis as abduction. Abduction in this context is a new form of reasoning which we shall discuss greater detail.
Exercise Diagnosing Illness
The philosopher Plato greatly admired doctors’ ability to diagnose illnesses and considered it a template for many other complex reasoning tasks. When we think of diagnosis, most of us think in terms of medical diagnosis i.e. the kind of diagnosis a doctor does.
This lesson is motivated by a made up diagnostic exercise.
I felt this course rather metaphysical as the instructors seem to avoid with the realities of implementations of the concepts. They tend to give the KR and algorithms human like capabilities. This is a problem of some other courses to and eventual, I decide to start to supplement my notes with MVPs that will help to ground my understanding in a implementation context.
From this diagnostic exercise I realized:
how to represent the data
how to implement a basic diagnostic
it handles edge cases: 1.1. it finds the closest diagnosis 1.2. if there are several it will list them all
Further work
Since the MVP solved the problem I did not add the ability to consider cases where two or more illnesses are required for the diagnosis of a patient.
Later in the lesson more sophisticated tree based diagnostics are presented. Since taking this course I learned about CI2, XAI3 and CFX4. It would seem instructive to attempt an MVP for tree based explanation, possibly based on using probabilistic counterfactuals examples.
I think the KR could have been reduced to a vector and the alg to a dot product. But I wanted to keep my KR faithful to the problem
This following is an MVP for solving the exercise.
# a metric based diagnosisdef diagnoser(patient,illness):# takes a patient spec and an illness spec# return a distance between patient and illness spec score =0for k in patient.keys():if patient[k] == illness[k]: score +=1else: score -=1return score # next we find the best diagnosis for the for the patient diag_score=0diagnosis=[]for illness in maladies.keys(): score = diagnoser(patient, maladies[illness])print(f"score for {illness} = {score}")if score > diag_score: diag_score = score diagnosis = []if score >= diag_score: diagnosis.append(illness)print(diagnosis)
score for Alphatis = 0
score for Betatosis = 6
score for Gammonoma = -4
score for Deltacol = 2
score for Epsicusus = 4
score for Zetad = 2
score for Etamia = 0
score for Thetadesis = 8
score for Iotaglia = -6
score for Kappacide = -4
score for Lambdacrite = -6
score for Mutension = -2
['Thetadesis']
note: this would have been less code if I used a numpy array for symptoms and a cosine similarity.
What we consider a good solution
This answer covers all these signs and symptoms. This is the principle of coverage. We want to make sure that the diagnostic conclusion actually accounts for all the input data.
we chose a single hypothesis over a combination of hypothesis, although the combination could have explain this data as well. This is the principle of parsimony. In general, we want a simple hypothesis for explaining the entire data.
These hypotheses can have greatest interactions between them, and these interactions can make your diagnostic task quite complicated.
They would use the term explanation. This is an important aspect for diagnosis.
We want a set of hypotheses that could explain the input data. Now this time we succedded in this simple exercise, because there is one single disease that can, in fact, explain all the input data.
Edge cases:
What would happen if there was no single hypothesis that could cover the entire input data?
I would return an empty set of hypothesis.
One could code a stronger algorithm to test for sets up N maladies.
The solver would need to consider that maladies might interact e.g. if one raises fever, the other reduces fever the combination would present temperature as normal.
What would happen if there were multiple hypotheses that could equally well explain the input data?
I would return a list of hypotheses - this is supported!
Diagnostic task can be quite complicated.
Defining Diagnosis
Diagnosis
To determine what is wrong with a malfunctioning device
Figure 2: automotive diagnosis
Figure 3: diagnosing of a faulty computer fan based strange noise from hardware
We discussed the same diagnostic task in three different domains. In each domain, there was a discrepancy between the expected and observed behaviors. We tried to identify the fault or faults responsible for it. We alluded to three different methods for doing diagnosis.
The method of rule-based reasoning.
the method of case-based reasoning.
the method of model-based reasoning.
We haven’t talked much about model-based reasoning so far — we will when we come to systems thinking later in the class. We can use the method of rule-based engine not only for diagnosing car engines, but also for repairing computer hardware or for diagnosing computer software. In this particular lesson, our focus will be on the diagnostic task. By now, we are already familiar with many reasoning methods that are potentially applicable.
Data Space and Hypothesis Space
We can think of diagnosis as a mapping from a data space, to a hypothesis space, In case of a medical diagnosis, the data may be the greatest kind of signs and symptoms that I may go to a doctor with.
Some of the data may be very specific, some of it may be very abstract, an example of a very specific data is that Ashock’s temperature is 104 degrees Fahrenheit.
An example of the extraction of the data is that is running a fever.
The hypothesis space consists of all hypothesis that can explain parts of the observed data. A hypothesis in the hypothesis space can explain some part of the data, In case of medicine, this hypothesis may reference to diseases.
A doctor may say that my hypothesis is that a shook is suffering from flu, and that explains his high fever. In the domain of car repairs, this hypothesis may refer to specific faults with the car, for example, the carburetor is not working properly.
In the domain of computer software, this hypothesis may refer to specific methods not working properly. And this mapping from data space to the hypothesis space can be very complex.
The complexity arises partly because of the size of data space, partly because of the size of hypothesis space, partly because the mapping can be M to N.
And also, because this hypothesis can interact with each other, If H_3 is present, H_4 may be excluded, If H_5 is present, H_6 is sure to be present and so on.
It helps then not to deal with all the raw data, but to deal with abstractions of the data, so the initial data that a patient may go to a doctor with may be very, very specific.
The signs and symptoms of their particular specific patient, but the diagnostic process might abstract them from Ashok has a fever of 104 degrees Fahrenheit to Ashok has a high fever.
This abstract data that can be mapped into an abstract hypothesis, Ashok has high fever can get mapped into Ashok has a bladder infection for example.
The abstract hypothesis can now be refined into a suffering from flu or a flu for a particular screen. At the end, we want a hypothesis that is as refined as possible, and that explains all the available data. When we were talking about classification, we talked about bottom-up process and our top-down process.
The bottom-up process of classification, we started with raw data and then grouped and abstracted, it in case of top-down classification we started with some high-level class and then established it and refined it. You can see that in diagnosis both the bottom-up and the top-down processes of classification co-occur.
This method of bottom-up classification in data space, mapping and then top-down classification of hypothesis space is called heuristic classification. This is yet another method like rule-based reasoning, case-based reasoning, and model-based reasoning with a diagnostic task.
Problems with Diagnosis as Classification
Problem 1: Multiple hypothesis explain one data point (One to Many mapping)
Problem 2: One hypothesis for multiple sets data. (Many to One mapping)
Problem 3: We can also have both above issues (Many to Many mapping)
Problem 4: Mutual exclusion between hypothesis (say H_1 excludes H_2 and visa versa)
Problem 5: Interacting data points (if H_1 “High fever” could cancel H_2 “Low fever” in the patient)
In general, cancellation interactions are very hard to account for 😱
What this means diagnosis in general is more complex than classification.
In order to address these factors that make diagnosis so complex, it is useful to shift perspective from diagnosis as classification to a view of diagnosis as abduction.
Deduction, Induction, Abduction
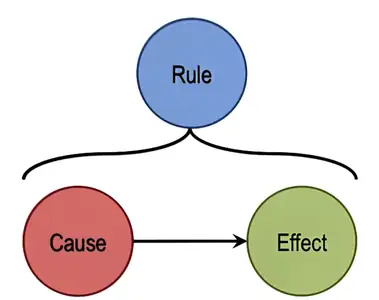
Figure 5: Deduction
Given the rule “if flu then fever” and the fact “Ashok has fever” we could abduce that “Ashok has flu”.
Notice that we are back to diagnosis. Diagnosis is an instance of abduction.But notice several other properties.
Deduction is truth preserving. If the rule is true, and the cause is true, we can always guarantee that the effect is true as well.
Induction and abduction are not truth preserving. We may know something about the relationship between cause and effect for some sample, that does not mean that the same relationship holds for the entire population. Induction does not always guarantee correctness nor does abduction.
This is exactly the problem that we had encountered earlier when we talking about what makes diagnosis hard. We said that deduction, induction, and abduction, are three of the fundamental forms of inference. We can of course also combine these inferences.
Might the cycle also explain significant part of cognition? Is this what you and I do on a daily basis? Abuse, induce, reduce?
Deduction is reasoning from a generality to the specific using propositional logic.
Induction is reasoning by generalizing from specifics to a a generality i.e. deriving a rule from examples. But if we check all possible example we might find counter examples that require revision or discarding the rule.
Abduction is reasoning based on experience - we satisfice by picking the most likely choice sacrificing accuracy for cases with implausible outcomes.
We can of course also combine these inferences.
–>
Criteria for Choosing a Hypothesis
Now that we understand abduction, and now that we know the diagnosis is an instance of abduction, let us ask ourselves, how does this understanding help us in choosing hypotheses?
The first principle for choosing a hypothesis is explanatory coverage. A hypotheses must cover as much of the data as possible.
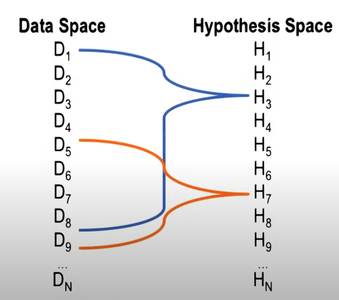
Figure 6: Coverage
Here’s an example, hypotheses H_3 explain data items D_1 through D_8. Hypothesis H_7 explains data item D_5 to D_9. Assuming that all of these data elements are equally important or equally salient, we may prefer H_3 over H_7 because it explains for of the data than does H_7.
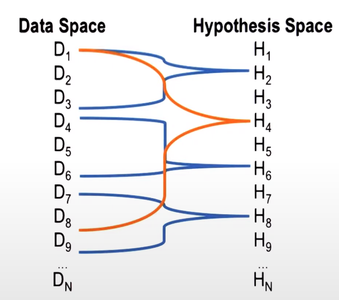
Figure 7: Parsimony
The second principle for choosing between competing hypotheses is called the principle of Parsimony. All things being equal, we want to pick the simplest explanation for the data. So consider the following scenario. H_2 explains data elements D_1 to D_3. H_4 explains data elements D_1 through D_8. H_6 explains data elements D_4 to D_6 and H_8 explains data elements D_7 to D_9. Now if you went by the criteria of explanatory coverage, then we might pick H_2, plus H_6, plus H_8, because the three of them combined, explain more than just H_4. However, the criteria of Parsimony would suggest if you pick H_4, because H_4 alone, explains almost all the data, and we don’t need the other three hypothesis. In general this is a balancing act between these two principles. We want to both maximize the coverage, and maximize the parsimony. Based on this particular example, we may go with H_4 and H_8. The two together explain all the data and in addition, the set of these two hypotheses is smaller than these set of hypotheses H_2, H_6, and H_8.
Figure 8: Confidence
The third criteria for choosing between competing hypotheses is that we want to pick those hypotheses in which we have more confidence . Some hypothesis are more likely than other and one may have more confidence in some hypotheses than in others.
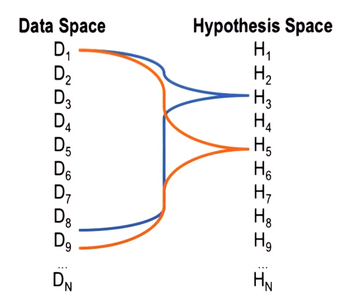
As an example, in this particular scenario, H_3 may explain data items D_1 to D_8 and H_5 may explain more data elements from D_1 to D_9. So H_5 also explains D_9 that H_3 doesn’t. However, we may have more confidence in H_3, and so we may pick H_3 instead of H_5.
Once again this is a balancing act between these three criteria for choosing between competing diagnostic hypotheses. A quick point to note here, these three criteria are useful for choosing between competing hypotheses even if the task is not diagnosis.
The same problem occurs for example in intelligence analysis. Imagine that you have some data that needs to be explained and your competing hypothesis for explaining that particular data, well, you may pick between the competing hypothesis based on this criteria. All of the task is not a diagnostic task. These three criteria are useful for explanation. Diagnosis simply happens to be an example of this explanation task.
Exercise Diagnosis as Abduction
Exercise
Let us do an exercise together.
import itertoolsimport collectionsfrom collections import defaultdictpatient = {k:v for (k,v) inzip(letters ,(0,1,-1,0,0,-1,0,-1))}# a metric based diagnosisdef diagnoser(patient,illness):# takes a patient spec and an illness spec# return a distance between patient and illness spec match,mismatch,score =0,0,0for k in patient.keys():if patient[k] == illness[k] andnot patient[k] ==0: match +=1ifnot patient[k] == illness[k]: mismatch +=1 score = match - mismatchreturn match,mismatch,score # next we find the expected coverage for a diagnosis given the patient _,_,expected_score = diagnoser(patient, patient)print(f"expected score for patient : {expected_score}")def merge(keys,maladies): res = collections.defaultdict(int) counter=0for illness in keys: counter +=1for symptom in maladies[illness].keys(): res[symptom] += maladies[illness][symptom]for key in res.keys():if res[key] >1 : res[key] =1if res[key] <-1 : res[key] =-1return resdiag_score=0diagnosis=[]maldies_set =set(maladies.keys())for comb_len inrange(3):for keys in itertools.combinations(maldies_set,comb_len): key_list =list(keys) key_list.sort()if key_list notin diagnosis:#print(key_list) merged_spec = merge(key_list,maladies) match, mismatch, score = diagnoser(patient, merged_spec)#print(f"match:{match:<1}, missed:{mismatch:<2}, total:{score:<2} score for {key_list}")if score > diag_score: diag_score = score diagnosis = []if score >= diag_score: diagnosis.append(key_list)if score == expected_score: status="full"else: status="partial"print(f"{status:<5} diagnosis metrics: score:{score:<2} hits:{match:<1}, misses:{mismatch:<2}, for {key_list}")print(f'final diagnosis: {diagnosis}')
expected score for patient : 4
partial diagnosis metrics: score:2 hits:3, misses:1 , for ['Thetadesis']
partial diagnosis metrics: score:2 hits:3, misses:1 , for ['Epsicusus', 'Thetadesis']
partial diagnosis metrics: score:3 hits:4, misses:1 , for ['Epsicusus', 'Zetad']
partial diagnosis metrics: score:3 hits:4, misses:1 , for ['Thetadesis', 'Zetad']
full diagnosis metrics: score:4 hits:4, misses:0 , for ['Betatosis', 'Zetad']
final diagnosis: [['Betatosis', 'Zetad']]
Note that one can use alternative methods for the same problem.
For example, one could use K-space reasoning.
And for when we came across a problem very similar to this one previously. Suppose that the solution of that particular problem was ever labeled as a case. In that particular case, B was high, C was low, and H was low. And the solution was Thetadesis.
In the current problem, the additional symptom is that F is low. So case retrieval would first lead you to the conclusion of Thetadesis. But this particular solution should also account for the additional symptom of F being low. We could do that by adding Kappacide and Mutension to Thetadesis. Case based system thus would tend to focus the alternate set of hypotheses.
Different methods can lead to different solutions - particularly since we discussed a number of conflicting priorities between good solutions. This suggests that each tradeoff between parsimony, coverage and completeness may give a different diagnosis.
Given these different methods, how might an AI agent decide which method to select?
The basic method in ML is to create different loss functions representing different priorities. I chose one that prioritizes parsimony over confidence in the sense that when I merged hypothesis I allowed them to cancel opposing effects. However, we might not be certain this is how a set of hypothesis should interact.
We’ll return to this particular problem when we discuss meta-reasoning.
Completing the Process
We can also think of this last phase as a type of configuration which we talked about last time. Given a set of hypothesis about illnesses or faults with a car, we can then configure a set of treatments or repairs that best address the faults we discovered before.
Assignment Diagnosis
So would the idea of diagnosis help us design an agent that can answer Raven’s progressive matrices? Perhaps the best way to think about this is to consider how your agent might respond when it answers a question wrong.
what data will it use to investigate its incorrect answer?
what hypotheses might it have for incorrect answers?
how will it select a hypothesis that best explains that data?
once it’s selected hypothesis that explains that data, how will it use that to repair its reasoning, so it doesn’t make the same mistake again?
Wrap Up
We talked about diagnosis which is a term we’re very familiar with from our everyday lives. But today, we talked about it specifically in a knowledge-based AI sense. We started off by defining diagnosis, which is finding the fault responsible for the malfunction in some system. This can be computers, computer programs, cars or even people and animals.
We then talked about the process of diagnosis, mapping data onto hypotheses and how we can see this as a form of classification. We discovered though that this can be a very complicated process and classification might not get us all the way there. So then we talked about diagnosis as a form of abduction. Given a rule and effect or a symptom, we can abduce the cause of that problem, like an illness or a software bug.
Both configuration and diagnosis have been small tasks in the broader process of design. Now that we talk about them, we can talk about AI agents that can actually do design in the real world, as well as what it would mean for an AI agent to really be creative.
The Cognitive Connection
Diagnosis is a very common cognitive task. It occurs whenever our expectations are violated. We start diagnosing. Why were our expectations violated? Within a system, we expect some behavior out of it. We get a different behavior. Why did the system not give the behavior we expected from it? Notice that diagnosis is a task. We can use several methods to address it, like case-based reasoning. We have discussed diagnosis on several contexts like medicine, program debugging, car repair, but it’s also very common in other aspects of our life. For example, you get unexpected traffic. Why did it occur? We review interaction with a co-worker or the economy. All are examples of diagnosis





{kind=link}