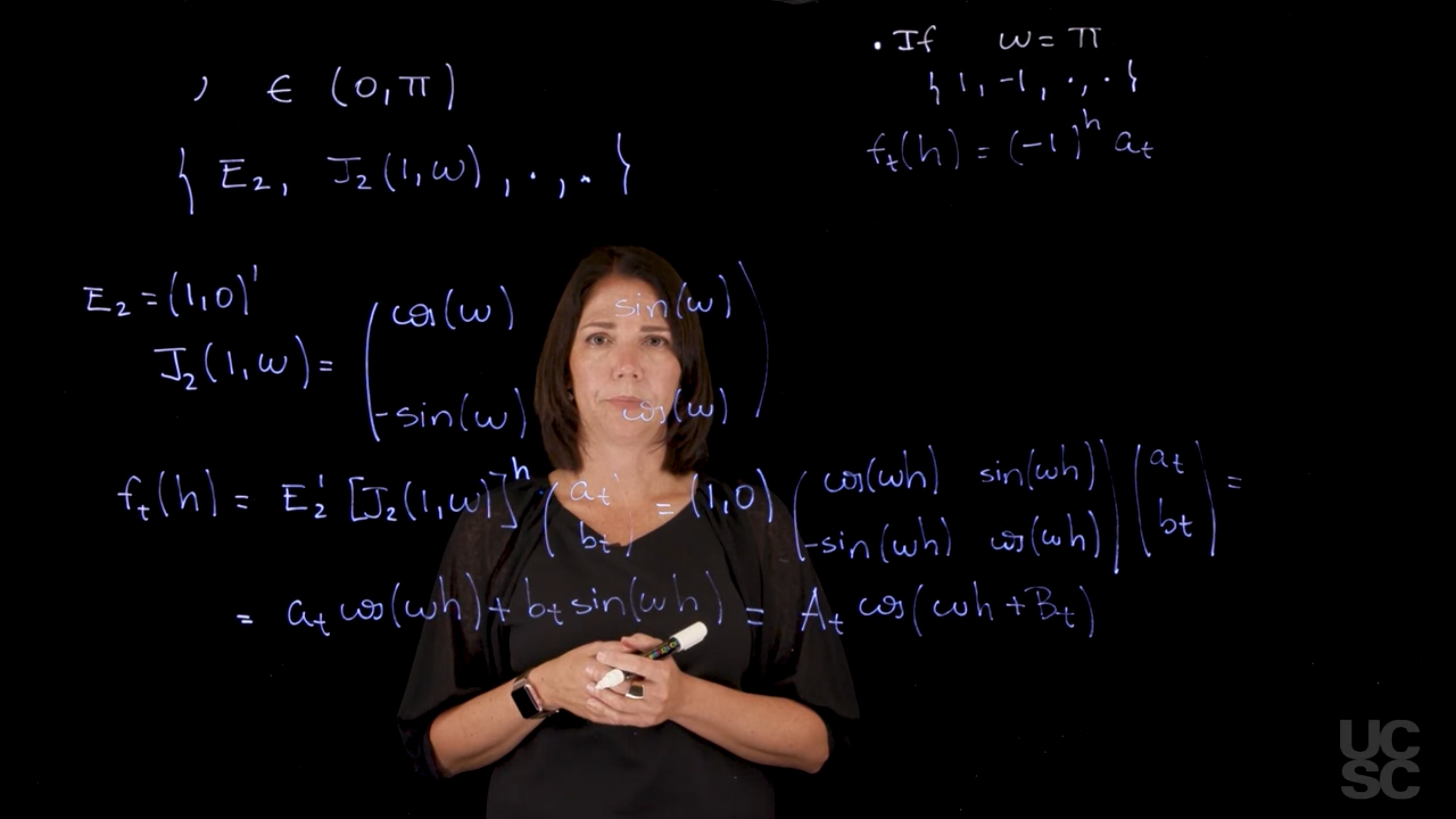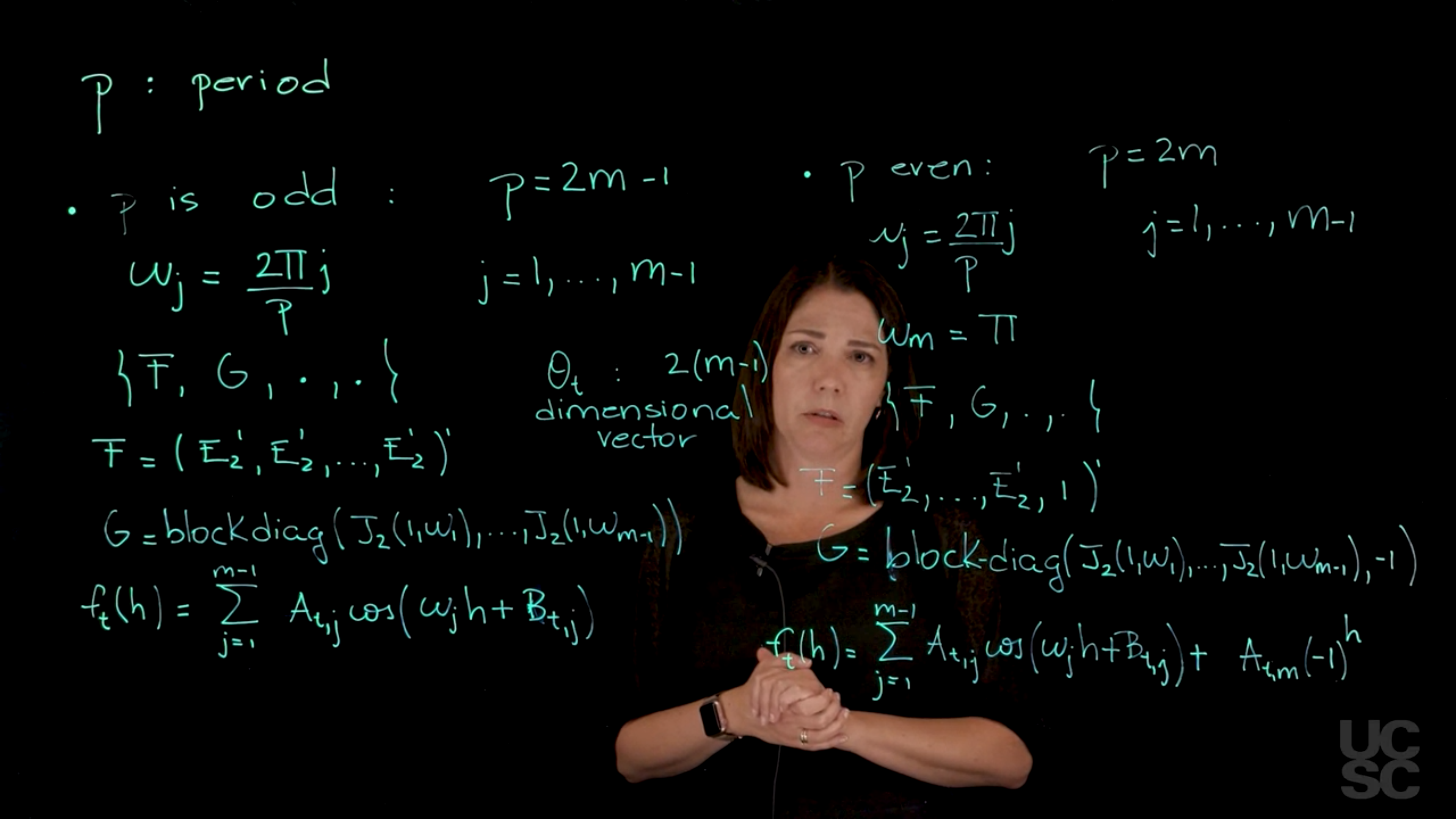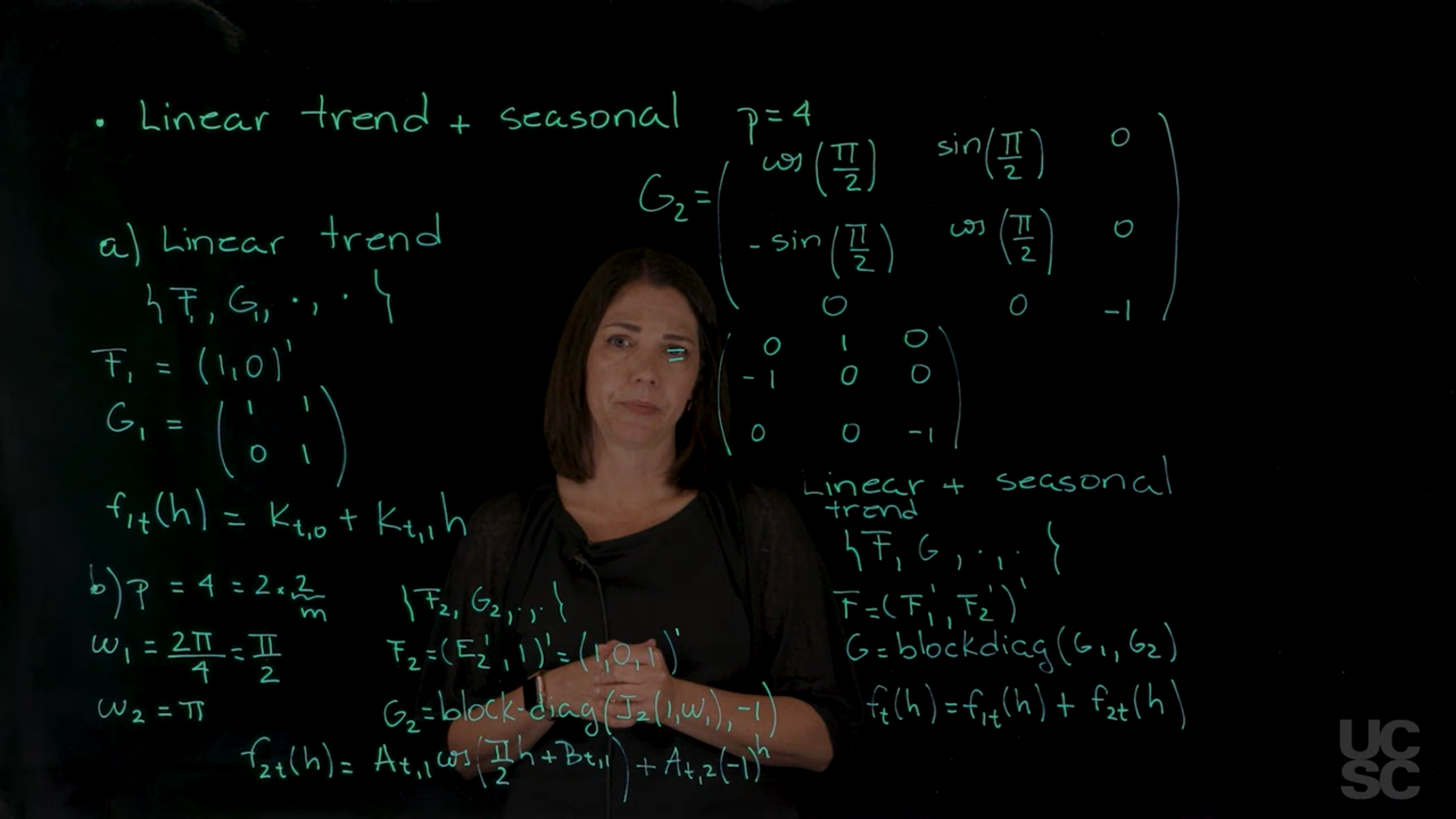The AR(1) process, Stationarity, ACF, PACF, Differencing, and Smoothing
Coursera
notes
Bayesian Statistics
Normal Dynamic Linear Models
Time Series
Author
Oren Bochman
Published
Saturday, October 26, 2024
Keywords
time series, filtering, smoothing, NLDM, Polynomial Trend Models, Regression Models, Superposition Principle, R code
Learning Objectives
Seasonal NDLMs
Fourier representation (Video)
Transcript:
I will now describe how to incorporate seasonal components in a normal dynamic linear model. What we will do is we will first talk about the so-called single Fourier component representation . Just in case you have a single frequency and how to incorporate that single frequency in your model for the seasonality. Then using the superposition principle, you can incorporate several frequencies or a single frequency and the corresponding harmonics in your model.
single Fourier component representation
There are other seasonal representations as well clarification needed. We will focus on the Fourier representation as is is flexible without needing too many parameters. E.g. if you want to consider, a fundamental frequency but you don’t want all the harmonics of that frequency. The Fourier representation, if you happen to have a single frequency.
We will discuss two cases with different component representations:
\omega \in (0,\pi)
\omega = \pi \implies \{ 1,1,\cdot, \cdot\}
In the case of any frequency \omega \in (0,\pi), we will have a DLM that has this structure:
Since this is a 2 by 2 matrix the our state parameter vector will also be a vector of dimension 2.
If we think about the forecast function, f_t(h) h-steps ahead, (you are at time t and you want to look for h steps ahead).
Let’s recall: the way we work with this is F* G^h * a_t
going to be your E_2', then you have to take this G matrix, which is just this J_2(1,\omega)^h, and then you have a vector, I’m going to call a_t and b_t, which is just going to be this vector value of your Theta t vector given the information up to the time t. It’s going to have two components, I’m just going to generically call them a_t and b_t. When you take this to the power of h using just trigonometric results, you’re going to get that J_2(1,\omega)^h, is just going to give you cosine of Omega h sine of Omega h minus sine of Omega h cosine of Omega h. When you look at this expression, you get something that looks like this, and then you have, again, times these a_t, b_t.
You’re going to have the cosine and sine only multiplied by this. In the end, you’re going to have something that looks like this.
You have this sinusoidal form with the period Omega in your forecast function. You can also write this down in terms of an amplitude that I’m going to call A_t and then a phase that is B_t. Here again, you have your periodicity that appears in this cosine wave. This is again for the case in which you have a single frequency and the frequencies in this range. There was a second case that I mentioned, and that case is the case in which the Omega is exactly Pi. In this case, your Fourier representation is going to be your model that has a state vector that is just one dimensional. In the case where Omega is between zero and Pi, you have a two-dimensional state, vector here you’re going to have a one-dimensional state vector.
This is going to be your F and your G. Then you have again whatever you want to put here as your v_t and W_t. This gives me, if I think about the forecast function, h steps ahead is just going to be something that has the form -1^h \times a_t. Now I have a single component here, is uni-dimensional. This is going to have an oscillatory behavior between a_t and -a_t if I were to look h steps ahead forward when I’m at time t. These two forms give me the single component Fourier representation and using the superposition principle, we will see that we can combine a single frequency and the corresponding harmonics or several different frequencies just using the superposition principle in the normal dynamic linear model. You can also incorporate more than one component in a full Fourier representation. Usually the way this works is you have a fundamental period, let’s say p. For example, if you are recording monthly data, p could be 12 and then you are going to incorporate in the model the fundamental frequency, and then all the harmonics that go with that fundamental frequency related to the period p.
slide 1
Here p, is the period and in this case, we are going to discuss essentially two different situations. One is when p is an odd number, the other one is when p is an even number. Let’s begin with the case of p is odd and in this particular scenario, we can write down p as 2 times m minus 1 for some value of m. This gives me a period that is odd. How many frequencies I’m going to incorporate in this model? I’m going to be able to write down \omega_j = 2 \pi \times j / p, which is the fundamental period. j here goes from one all the way to m minus 1. Now we can use the superposition principle thinking we have a component DLM representation for each of these frequencies. They are all going to be between 0 and Pi. For each of them I’m going to have that two-dimensional DLM representation in terms of the state vector and then I can use the superposition principle to concatenate them all and get a model that has all these frequencies, the one related to the fundamental period and all the harmonics for that. Again, if I think about what is my F and my G here, I’m not writing down the t because both F and G are going to be constant over time. So my F is going to be again, I concatenate as many E_2 as I have frequencies in here. I’m going to have E_2 transpose and so on and I’m going to have m minus one of those. Times 2 gives me the dimension of Theta t. The vector here is 2 times m minus 1 dimensional vector.
My G is going to have that block diagonal structure where we are going to just have all those J_2 1 Omega 1, all the way down to the last harmonic. Each of these blocks is a two-by-two matrix and I’m going to put them together in a block diagonal form. This gives me the representation when the period is odd, what is the structure of the forecast function? Again, using the superposition principle, the forecast function is going to be just the sum of m minus 1 components, where each of those components is going to have an individual forecast function that has that cosine wave representation that we discussed before. Again, if I think about the forecast function at time t h steps ahead, I will be able to write it down like this.
This should be a B. B_t,j. Again here, I have an amplitude for each of the components and a phase for each of the components so it depends on time but does not depend on h. The h enters here, and this is my forecast function. In the case of P even the situation is slightly different. But again, it’s the same in terms of using the superposition principle. In this case, we can write down P as 2 times m because it’s an even number. Now I can write down these Omega j’s as a function of the fundamental period. Again, this goes from 1 up to m minus 1. But there is a last frequency here. When j is equal to m, this simplifies to be the Nyquist frequency. In this case, I have my Omega is equal to Pi. In this particular case, when I concatenate everything, I’m going to have again an F and a G that look like this. Once again, I concatenate all of these up to the component m minus 1. Then I have this 1 for the last frequency. Then my G is going to be the block diagonal.
For the last frequency I have that minus 1. This determines the dimension of the state vector, in this case I’m going to have 2 times m minus 1 plus 1.
My f function, my forecast function, is again a function of the number of steps ahead. I’m going to have the same structure I had before for the m minus 1 components. Then I have to add one more component that corresponds to the frequency Pi. This one appears with the power of h. As you can see, I’m using once again the superposition principle to go from component representation to the full Fourier representation. In practice, once we set the period, we can use a model that has the fundamental period and all the harmonics related to that fundamental period. We could also use, discard some of those harmonics and use a subset of them. This is one of the things that the Fourier representation allows. It allows you to be flexible in terms of how many components you want to add in this model. There are other representations that are also used in practice. One of them is the seasonal factors representation. In that case, you’re going to have a model in which the state vector has dimension p for a given period. It uses a G matrix that is a permutation matrix. There is a correspondence between this parameterization using the Fourier representation and that other parameterization. If you want to use that parameterization, the way to interpret the components of this state vector, since you have P of those, is going to be a representation in terms of factors. For example, if you think about monthly data, you will have the say January factor, February factor, March factor, and so on. You could think about those effects and do a correspondence with this particular model. We will always work in this class with these representations because it’s more flexible. But again, you can go back and forth between one and the other.
Building NDLMs with multiple components: Examples (Video)
two component model
In this second example, we are going to have two components; a linear trend plus a seasonal component where the fundamental period is four. The way to build this model, again, is using the superposition principle.
First we need to think “what structure do we need, to get a linear trend in the forecast function?”
The linear trend is a linear function on the number of steps ahead.
Whenever you have that structure, you will get a DLM that is the so-called polynomial model of order 2. So let’s discuss first the linear. Let’s say the linear trend part, and in this case, we have an F and a G, I’m going to call them 1, F_1 and G_1 to denote that this is the first component in the model.
F_1 is just going to be 1, 0 transpose, and the G_1 is that upper triangular matrix, it’s a 2 by 2 matrix that has 1, 1 in the first row, 0, 1 in the second row, so this gives me a linear trend.
My forecast function, let’s call it f_{1,t} in terms of the number of steps ahead is just a linear function on h, is a linear polynomial order 1. Let’s say it’s a constant of K but depends on t0 plus K_{t_1}^h. This is the structure of the first component. Then I have to think about the seasonal component with period of four. If we are going to incorporate all the harmonics, we have to think again, is this an even period or a not period? In this example, this is an even period. I can write p, which is 4, as 2 times 2, so this gives me that m. I’m going to have one frequency, the first one, Omega 1, is related to the fundamental period of 4, so is 2 Pi over 4, which I can simplify and write down this as Pi over 2. This is the first frequency. The last one is going to correspond to the Nyquist.
We could obtain that doing 4Pi over 4, which is just Pi. As you remember, this component is going to require a two-dimensional DLM component model, this one is going to require a one-dimensional DLM component model in terms of the dimension here is the dimension of the state vectors. When we build this concatenating these components, we are going to have, again, let’s call it F_2 and G_2 for this particular component. I had called this here a, let’s call this b. My F_2 has that E_2 transpose and a 1, which gives me just 1, 0, 1. My G matrix is going to be a 3 by 3 matrix. The first component is
the component associated to that fundamental period. It’s a block diagonal again, and I’m going to have that J_2, 1 Omega 1, and then I have my minus 1 here. What this means is if I write this down as a matrix, let me write it here, G_2 is going to be cosine of that Pi halves,
and then I have zeros here, I have my minus 1 here, 0, and 0. I can further simplify these to have this structure. The cosine of Pi halves is 0, the sine is 1, so I can write this down as 0, 1, 0, minus 1, 0, 0, and 0, 0 minus 1. Now if I want to go back to just having a model that has both components, I use the superposition principle again and combine this component with this component. The linear plus seasonal
is a model that is going to have the representation F, G, with F is going to be just concatenate F_1 and F_2. G now has that block diagonal form again.
If I look at what I have, I have this block that is a 2 by 2, this block that is a 3 by 3. Therefore my model is going to be a five-dimensional model in terms of the state parameter vector, so this G is a 5 by 5, and this one is also a five-dimensional vector. Finally, if I think about the forecast function in this case, if I call here the forecast function f_{2,t} for the component that is seasonal, I’m going to have my A_t1 cosine of Pi halves h plus B_{t,1}, and then I have my A_{t,2} minus 1^h. My forecast function for the final model is going to be just the sum of these two components.
You can see how I can now put together all these blocks, so I have a block that is seasonal and a block that is a linear polynomial model, and I can put them together in a single model just to create a more flexible structure. You could add regression components, you could add autoregressive components and put together as many components as you need for the forecast function to have the form that you expect it to have. All of these models are using, again, the superposition principle and the fact that we’re working with a linear and Gaussian structure in terms of doing the posterior inference later.
Summary: DLM Fourier representation (Reading)
Seasonal Models: Fourier Representation
For any frequency \omega \in (0, \pi), a model of the form \{E_2, J_2(1, \omega), \cdot, \cdot\} with a 2-dimensional state vector \theta_t = (\theta_{t,1}, \theta_{t,2})' and
For \omega = \pi, the NDLM is \{1, -1, \cdot, \cdot\} and has a forecast function of the form
f_t(h) = (-1)^h m_t
These are component Fourier models. Now, for a given period p, we can build a model that contains components for the fundamental period and all the harmonics of such a period using the superposition principle as follows:
Case: p = 2m - 1 (odd)
Let \omega_j = 2\pi j / p for j = 1 : (m - 1), F a (p - 1)-dimensional vector, or equivalently, a 2(m - 1)-dimensional vector, and G a (p - 1) \times (p - 1) matrix with F = (E_2', E_2', \dots, E_2')',
G = \text{blockdiag}[J_2(1, \omega_1), \dots, J_2(1, \omega_{m-1})].
Case: p = 2m (even)
In this case, F is again a (p - 1)-dimensional vector (or equivalently a (2m - 1)-dimensional vector), and G is a (p - 1) \times (p - 1) matrix such that F = (E_2', \dots, E_2', 1)' and
G = \text{blockdiag}[J_2(1, \omega_1), \dots, J_2(1, \omega_{m-1}), -1].
In both cases, the forecast function has the general form:
Filtering, Smoothing and Forecasting: Unknown observational variance (Video)
Summary of Filtering, Smoothing and Forecasting Distributions, NDLM unknown observational variance (Reading)
Specifying the system covariance matrix via discount factors (Video)
NDLM, Unknown Observational Variance: Example (Video)
This is a walk though of the R code for the example bellow.
Rcode: NDLM, Unknown Observational Variance Example (Reading)
This code allows time-varying F_t, G_t and W_t matrices and assumes an unknown but constant \nu. It also allows the user to specify W_t using a discount factor \delta \in (0,1] or assume W_t known.
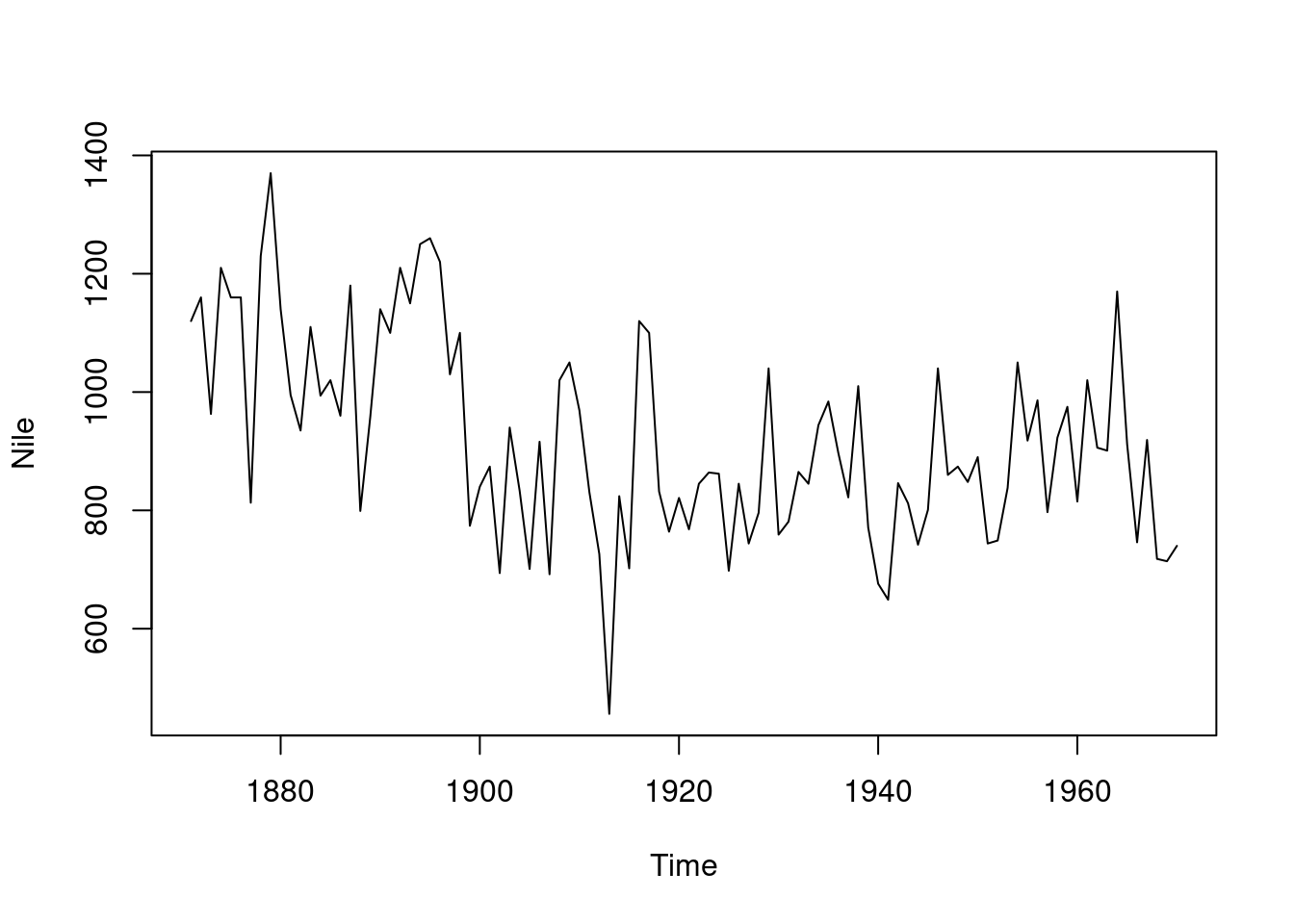
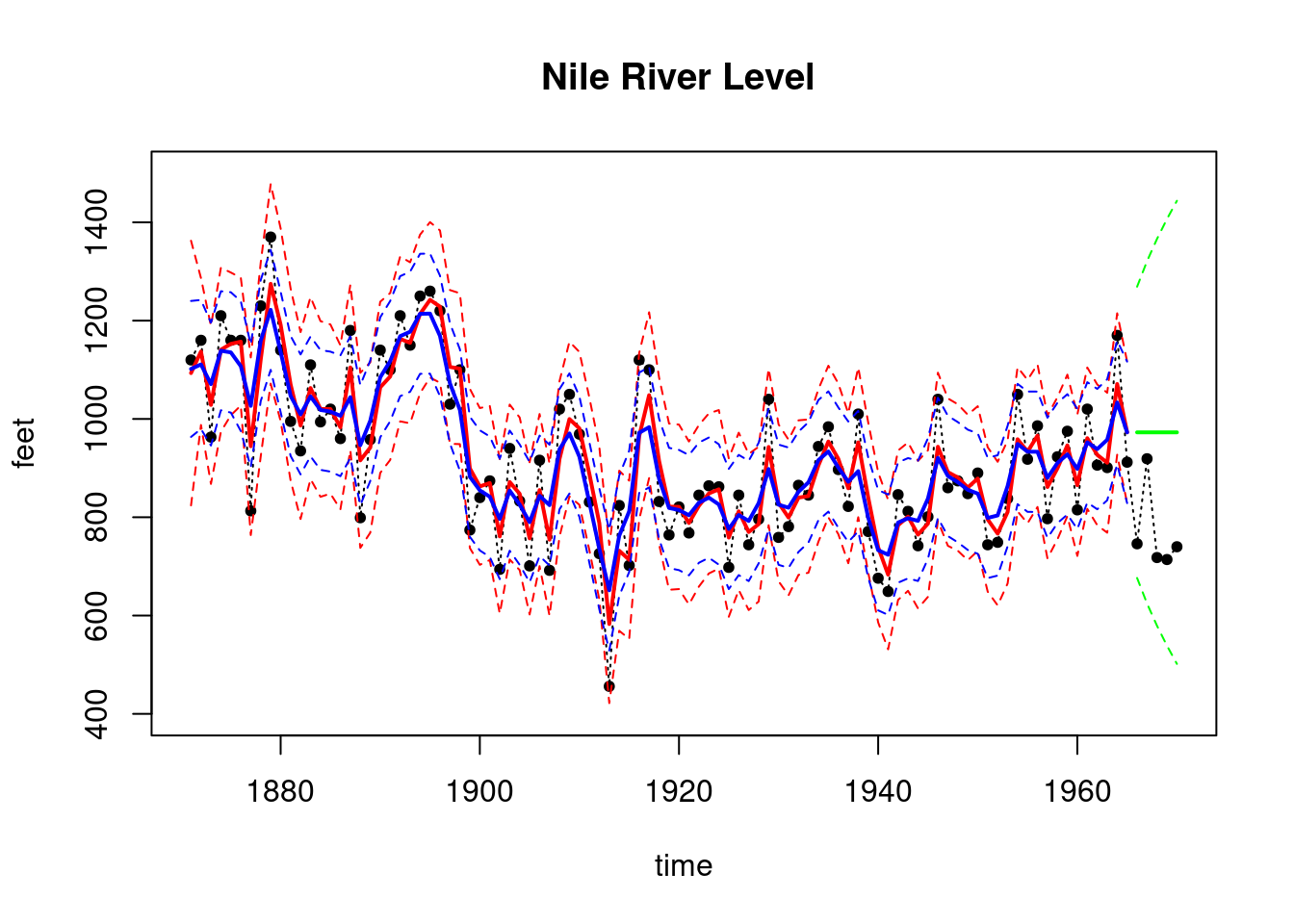
n=length(Nile) #n=100 observations k=5T=n-kdata_T=Nile[1:T]test_data=Nile[(T+1):n]data=list(yt = data_T)## set up matrices for first order polynomial model Ft=array(1, dim =c(1, 1, n))Gt=array(1, dim =c(1, 1, n))Wt_star=array(1, dim =c(1, 1, n))m0=as.matrix(800)C0_star=as.matrix(10)n0=1S0=10## wrap up all matrices and initial valuesmatrices =set_up_dlm_matrices_unknown_v(Ft, Gt, Wt_star)initial_states =set_up_initial_states_unknown_v(m0, C0_star, n0, S0)## filtering results_filtered =forward_filter_unknown_v(data, matrices, initial_states)
This peer-reviewed activity is highly recommended. It does not figure into your grade for this course, but it does provide you with the opportunity to apply what you’ve learned in R and prepare you for your data analysis project in week 5.
The R code below fits a Normal Dynamic Linear Model to the monthly time series of Google trends “hits” for the term “time series”. The model has two components: (a) a polynomial model of order 2 and (b) a seasonal component with 4 frequencies: ω_1=2π/12, (annual cycle) ω_2=2π/6 (6 months cycle), ω_3=2π/4 and ω_4=2π/3. The model assumes that the observational variance v is unknown and the system variance-covariance matrix W_t is specified using a single discount factor. The discount factor is chosen using an optimality criterion as explained in the course.
You will be asked to modify the code in order to consider a DLM with two components: (a) a polynomial model of order 1 and (b) a seasonal component that contains a fundamental period of p = 12 and 2 additional harmonics for a total of 3 frequencies: ω1=2π/12, ω2=2π/6 and ω3=2π/4. You will also need to optimize the choice of the discount factor for this model. You will be asked to upload pictures summarizing your results.
R code to fit the model: requires R packages gtrends,and dlm as well as the files “all_dlm_functions_unknown_v.R” and “discountfactor_selection_functions.R” also provided below.
#| label: code-gtrendsR-data-analysis# download data library(gtrendsR)timeseries_data <-gtrends("time series",time="all")plot(timeseries_data)names(timeseries_data)timeseries_data=timeseries_data$interest_over_timedata=list(yt=timeseries_data$hits)library(dlm)model_seasonal=dlmModTrig(s=12,q=4,dV=0,dW=1)model_trend=dlmModPoly(order=2,dV=10,dW=rep(1,2),m0=c(40,0))model=model_trend+model_seasonalmodel$C0=10*diag(10)n0=1S0=10k=length(model$m0)T=length(data$yt)Ft=array(0,c(1,k,T))Gt=array(0,c(k,k,T))for(t in1:T){ Ft[,,t]=model$FF Gt[,,t]=model$GG}source('all_dlm_functions_unknown_v.R')source('discountfactor_selection_functions.R')matrices=set_up_dlm_matrices_unknown_v(Ft=Ft,Gt=Gt)initial_states=set_up_initial_states_unknown_v(model$m0, model$C0,n0,S0)df_range=seq(0.9,1,by=0.005)## fit discount DLM## MSEresults_MSE <-adaptive_dlm(data, matrices, initial_states, df_range,"MSE",forecast=FALSE)## print selected discount factorprint(paste("The selected discount factor:",results_MSE$df_opt))## retrieve filtered resultsresults_filtered <- results_MSE$results_filteredci_filtered <-get_credible_interval_unknown_v( results_filtered$ft,results_filtered$Qt,results_filtered$nt)## retrieve smoothed resultsresults_smoothed <- results_MSE$results_smoothedci_smoothed <-get_credible_interval_unknown_v( results_smoothed$fnt, results_smoothed$Qnt, results_filtered$nt[length(results_smoothed$fnt)])## plot smoothing results par(mfrow=c(1,1))index <- timeseries_data$dateplot(index, data$yt, ylab='Google hits',main ="Google Trends: time series", type ='l',xlab ='time', lty=3,ylim=c(0,100))lines(index, results_smoothed$fnt, type ='l', col='blue', lwd=2)lines(index, ci_smoothed[, 1], type='l', col='blue', lty=2)lines(index, ci_smoothed[, 2], type='l', col='blue', lty=2)# Plot trend and rate of change par(mfrow=c(2,1))plot(index,data$yt,pch=19,cex=0.3,col='lightgray',xlab="time",ylab="Google hits",main="trend")lines(index,results_smoothed$mnt[,1],lwd=2,col='magenta')plot(index,results_smoothed$mnt[,2],col='darkblue',lwd=2,type='l', ylim=c(-0.6,0.6), xlab="time",ylab="rate of change")abline(h=0,col='red',lty=2)# Plot seasonal components par(mfrow=c(2,2))plot(index,results_smoothed$mnt[,3],lwd=2,col="darkgreen",type='l', xlab="time",ylab="",main="period=12",ylim=c(-12,12))plot(index,results_smoothed$mnt[,5],lwd=2,col="darkgreen",type='l',xlab="time",ylab="",main="period=6",ylim=c(-12,12))plot(index,results_smoothed$mnt[,7],lwd=2,col="darkgreen",type='l', xlab="time",ylab="",main="period=4",ylim=c(-12,12))plot(index,results_smoothed$mnt[,9],lwd=2,col="darkgreen",type='l', xlab="time",ylab="",main="period=3",ylim=c(-12,12))#Estimate for the observational variance: St[T]results_filtered$St[T]
####################################################### using discount factor ############################################################## compute measures of forecasting accuracy## MAD: mean absolute deviation## MSE: mean square error## MAPE: mean absolute percentage error## Neg LL: Negative log-likelihood of disc,## based on the one step ahead forecast distributionmeasure_forecast_accuracy <-function(et, yt, Qt=NA, nt=NA, type){if(type =="MAD"){ measure <-mean(abs(et)) }elseif(type =="MSE"){ measure <-mean(et^2) }elseif(type =="MAPE"){ measure <-mean(abs(et)/yt) }elseif(type =="NLL"){ measure <-log_likelihood_one_step_ahead(et, Qt, nt) }else{stop("Wrong type!") }return(measure)}## compute log likelihood of one step ahead forecast functionlog_likelihood_one_step_ahead <-function(et, Qt, nt){## et:the one-step-ahead error## Qt: variance of one-step-ahead forecast function## nt: degrees freedom of t distribution T <-length(et) aux=0for (t in1:T){ zt=et[t]/sqrt(Qt[t]) aux=(dt(zt,df=nt[t],log=TRUE)-log(sqrt(Qt[t]))) + aux } return(-aux)}## Maximize log density of one-step-ahead forecast function to select discount factoradaptive_dlm <-function(data, matrices, initial_states, df_range, type, forecast=TRUE){ measure_best <-NA measure <-numeric(length(df_range)) valid_data <- data$valid_data df_opt <-NA j <-0## find the optimal discount factorfor(i in df_range){ j <- j +1 results_tmp <-forward_filter_unknown_v(data, matrices, initial_states, i) measure[j] <-measure_forecast_accuracy(et=results_tmp$et, yt=data$yt,Qt=results_tmp$Qt, nt=c(initial_states$n0,results_tmp$nt), type=type)if(j ==1){ measure_best <- measure[j] results_filtered <- results_tmp df_opt <- i }elseif(measure[j] < measure_best){ measure_best <- measure[j] results_filtered <- results_tmp df_opt <- i } } results_smoothed <-backward_smoothing_unknown_v(data, matrices, results_filtered, delta = df_opt)if(forecast){ results_forecast <-forecast_function(results_filtered, length(valid_data), matrices, df_opt)return(list(results_filtered=results_filtered, results_smoothed=results_smoothed, results_forecast=results_forecast, df_opt = df_opt, measure=measure)) }else{return(list(results_filtered=results_filtered, results_smoothed=results_smoothed, df_opt = df_opt, measure=measure)) }}
Grading Criteria
The assignment will be graded based on the uploaded pictures summarizing the results. Estimates of some of the model parameters and additional discussion will also be requested.