Code
set.seed(123)
n <- 100
V <- 1
mu <- 0
y <- mu + rnorm(n, 0, V)
plot(y, type = "l", col = "blue", lwd = 2, xlab = "Time", ylab = "y", main = "Model with no temporal structure")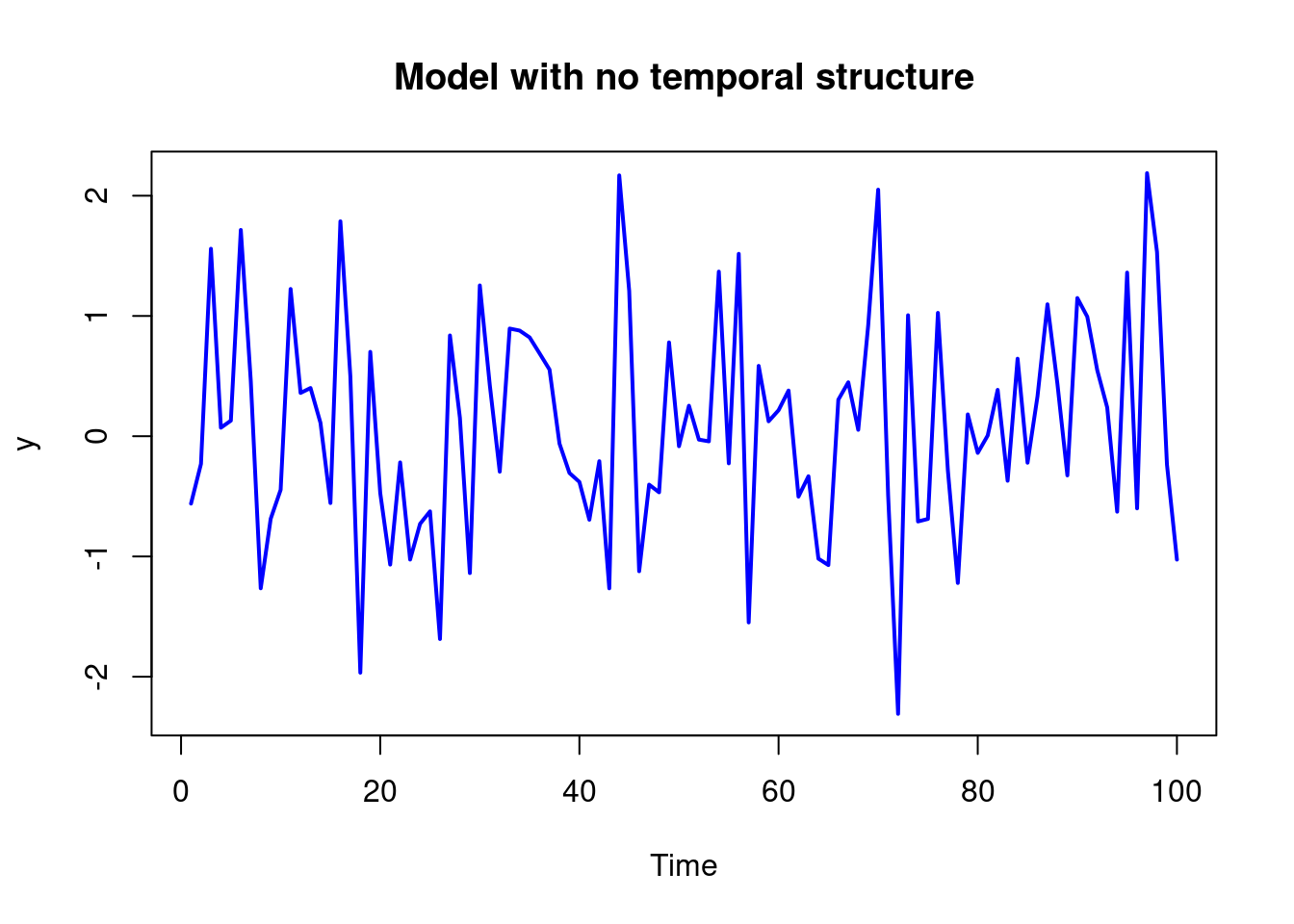
time series, filtering, smoothing, NLDM, Polynomial Trend Models, Regression Models, Superposition Principle, R code
Normal Dynamic Linear Models (NDLMs) are defined and illustrated in this module using several examples Model building based on the forecast function via the superposition principle is explained. Methods for Bayesian filtering, smoothing and forecasting for NDLMs in the case of known observational variances and known system covariance matrices are discussed and illustrated..
The Normal Dynamic Linear Model (DLM) covered (Prado, Ferreira, and West 2023, 117–44)
I found this video hard to follow. I watched it carefully a number of times and reworked the math and video’s transcript. But in the end this and the next two video are more like a summary of the material rather than a motivated development of the models.
The text also diverge when it comes to the F in the state space representation equation. In West and Harrison (2013) it is a matrix and in Prado, Ferreira, and West (2023) it is called a vector. In some places it is referenced as a p \times 1. As far as I can tell this reflects different state space representation of the model which neither text is particularly clear.
Although we are give a couple of motivational examples the way they generalize to the NLDM is not as clear as in West and Harrison (2013) but this text is very verbose and covers much more material. West and Harrison (2013) also discusses how the math relates to more common statistical scenarios and how the model can be adapted to these scenarios e.g. replacing the obs. normal distribution with a t-distribution or a mixture of normals to handle outliers. I.e. see NLDMs as a looser framework with the assumptions of independence and normality as guidelines rather than strict assumptions. In Prado, Ferreira, and West (2023) we quickly get a large number of mathematically concise format, that illustrate how NLDM generalize other time series models. However these examples assume we are sufficiently familiar with this models.
The NDLM is also a hierarchical model which we have not looked into in much depth in this specialization. This is another missed opportunity to connect to previous material and deepen our understanding. Particularly as the bayesian formulation should be able to overcome the limitations of the frequentist approach where we need to make strong assumptions on IID of the shocks but in a time series local observations often highly correlated.
NLDM have efficient algorithms for inference and forecasting mostly by using the Kalman filter, again this is not mentioned not is a bayesian formulation presented
So I guess the main issue is that the vide just lists lots of equations and does not really without providing a good intuition behind the model.
I hope that with the rest of this and the next lesson we can get a better understanding of the NLDM.
I ended up skimming through large portions of West and Harrison (2013) which goes into much greater detail on the NLDM. The first and second polynomial models developed, explained and motivation is clearer. The state space representation is not explained but the model is developed in a more coherent way and this is a good starting point for developing a more intuitive understanding of the NLDMs. The notation in this book is also easier to follow.
The state space representation here is omitted. The F vector or matrix is not really motivates as a latent state space representation.
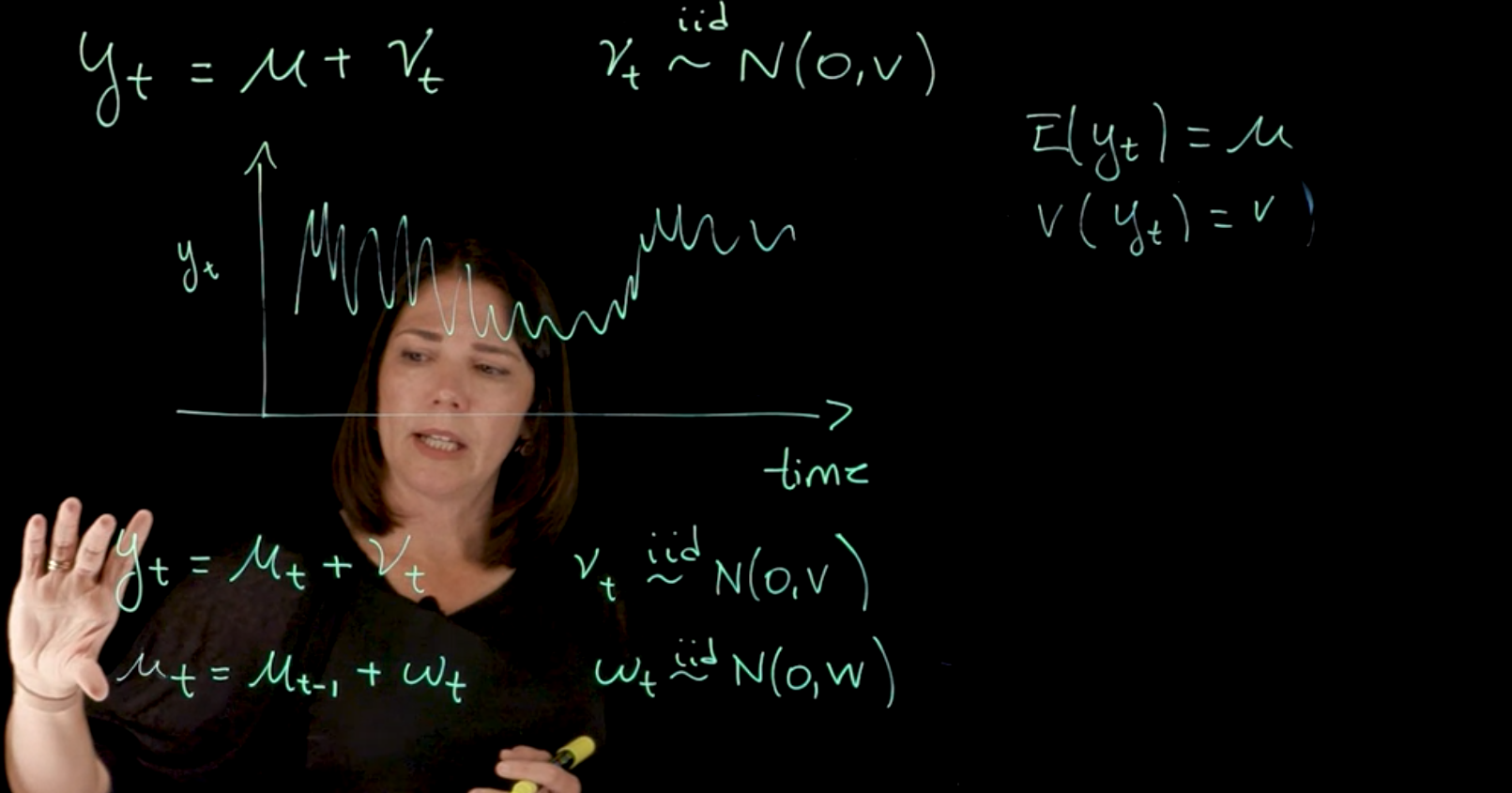
In this module, we will motivate and develop a class of models suitable for for analyzing and forecasting non-stationary time series called normal dynamic linear models . We will talk about Bayesian inference and forecasting within this class of models and describe model building as well.
Let’s begin with a very simple model that has no temporal structure, just a model that is:
y_t = \mu + v_t \qquad v_t \overset{\text{iid}}{\sim} N(0, \nu) \qquad \tag{1}
where:
If we plot this model we might see the following graph:
set.seed(123)
n <- 100
V <- 1
mu <- 0
y <- mu + rnorm(n, 0, V)
plot(y, type = "l", col = "blue", lwd = 2, xlab = "Time", ylab = "y", main = "Model with no temporal structure")
For this model the mean of the time series is \mu will be the the expected value of y_t, which is \mu. And the variance of y_t is \nu.
E[y_t] = \mu \qquad \text{and} \qquad Var[y_t] = \nu \qquad \tag{2}
Next let’s incorporate some temporal structure, in particular, let us allow the expected value of the time series, to change over time. To can achieve this, by update the model definition with a \mu_t where the index indicates that it can change at every time step. And let us keep the noise unchanged. i.e. we set it to \mu_t \in N(0,\nu).
We get the following model:
y_t = \mu_t + \nu_t \quad \nu_t \overset{\text{iid}}{\sim} N(0, V) \qquad \text{(Observation eq)} \tag{3}
To complete this we need to also decide how to incorporate the the changes over time in the parameter \mu_t. We might consider different options but we should pick the simplest possible to start with. One option is to assume that the expected value of \mu_t is just the expected value of \mu_{t-1} plus some noise. \mu_t = \mu_{t-1} + \omega_t \quad \omega_t \overset{\text{iid}}{\sim} N(0, W) \quad \text{(Sys. evolution eq)} \tag{4}
We now have that random walk type of structure where \mu_t can be written in terms of \mu(t-1). The expected value of \mu_t, we can think of it as \mu_{t-1} + \text{some noise}. This error is once again, assumed to be normally distributed random variable centered at zero and with variance W.
Another assumption that we have made here is that the \nu_t and \omega_t, are also independent of each other.
With this model, what we are assuming is that the mean level of the series is changing over time.
This is an example of a Gaussina or Normal dynamic linear model,
NLDMs are a two level hierarchial models where :
This is our first example. Next we will be discuss the general class of models. Later we will consider how to incorporate different structures into the model, and how to perform Bayesian inference for filtering smoothing and forecasting.
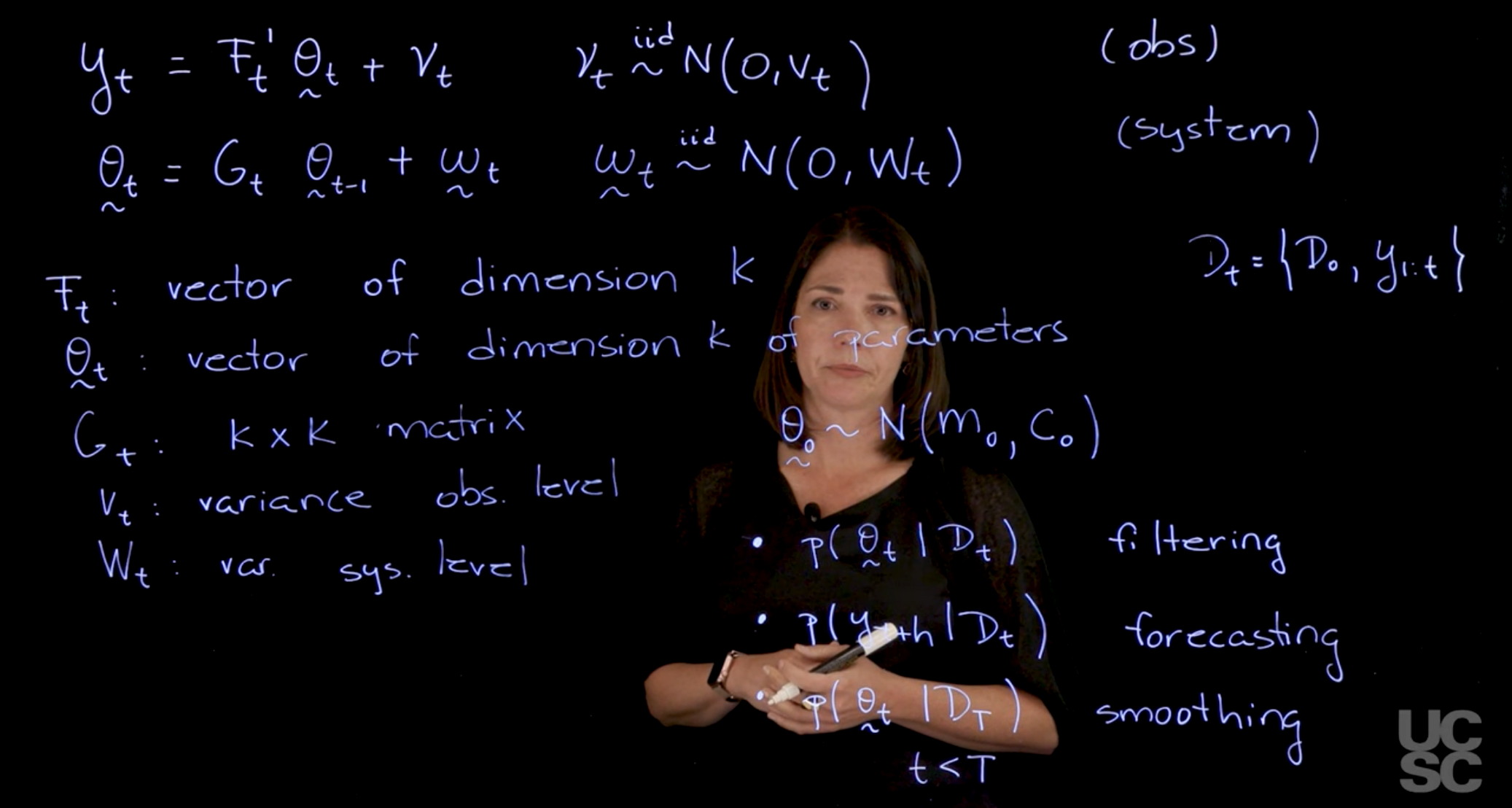
The general class of dynamic linear models can be written as follows:
We are going to have two equations. One is the so-called observation equation that relates the observations to the parameters in the model, and the notation we are going to use is as follows.
\begin{aligned} y_t &= \vec{F}_t' \vec{\theta}_t + \nu_t && \nu_t \overset{\text{iid}}{\sim} N(0, V_t) && \text{(obs)} \\ \vec{\theta}_t &= G_t \vec{\theta}_{t-1} + \vec{\omega}_t && \vec{\omega}_t \overset{\text{iid}}{\sim} N(0, W_t) && \text{(system)} \end{aligned}
Where:
We also have the prior distribution for the state vector at time 0:
Q. Why are F_t and G_t a vector and a matrix respectively?
This is because the observation equation is a linear equation that relates the observations to the parameters in the model. The system equation is also a linear equation that tells us how the time-varying parameter is going to be changing over time. This is why we call this a linear model.
Q. Why are the noise terms \nu_t and \omega_t assumed to be normally distributed?
This is a common assumption in time series analysis. It is a convenient assumption that allows us to perform Bayesian inference and forecasting in a very simple way. And this is why we call this a normal dynamic linear model.
Q. Isn’t this just a hierarchical model?
Yes, this is a hierarchical model. We have a model for the observations and a model for the system level. The system level is changing over time and the observations are related to the system level through the observation equation. And so it is possible to extend this model to more complex structures if we wish to do so. c.f.
In terms of the inference, there are a few different kinds of densities and quantities that we are interested in:
One of the distributions that we are interested in finding is the so-called filtering distribution. We may be interested here in finding what is the density of \theta_t given all the observations that we have up to time t.
\mathcal{D}_t= \{\mathcal{D}_0, y_{1:T}\}
We will denote information as \mathcal{D}_t. Usually, it is all the information we have at time zero (i.e. our prior), coupled with all the data points I have up to time t.
Here we conditioning on all the observed quantities and the prior information up to time t, and I may be interested in just finding what is the distribution for \theta_t. This is called filtering.
p(\theta_t \mid \mathcal{D}_t) \qquad \text{filtering distribution}
Another distribution that is very important in time series analysis is the forecasting distribution. We may be interested in the distribution of y{t+h}? where we consider h lags into the future and we have all the information \mathcal{D}_t, up to time t. We want to do a predictions here
p(y_{t+h} \mid \mathcal{D}_t) \qquad \text{forecasting distribution}
Another important quantity or an important set of distributions is what we call the smoothing distribution. Usually, you have a time series, when you get your data, you observe, I don’t know, 300 data points. As you go with the filtering, you are going to start from zero all the way to 300 and you’re going to update these filtering distributions as you go and move forward. We may want instead to revisit the parameter at time 10, for example, given that you now have observed all these 300 observations. In that case, you’re interested in densities that are of the form. Let’s say that you observe capital T in your process and now you are going to revisit that density for \theta_t. This is now in the past. Here we assume that t<T. This is called smoothing.
So you have more observation once you have seen the data. We will talk about how to perform Bayesian inference to obtain all these distributions under this model setting.
p(\theta_t \mid D_T) \qquad t < T \qquad \text{smoothing distribution}
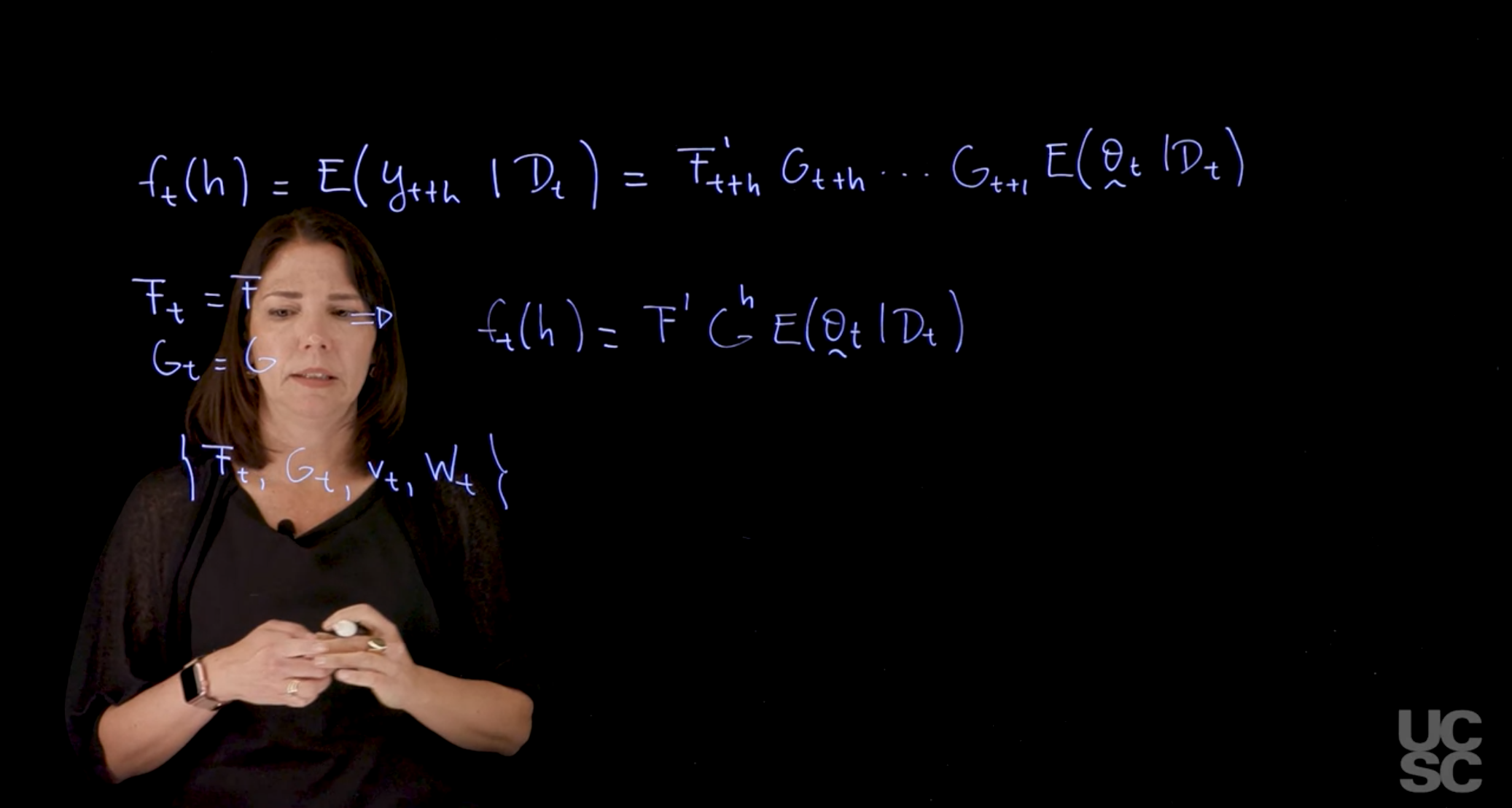
In addition to all the structure that we described before and all the densities that we are interested in finding, we also have as usual, the so-called forecast function, which instead of being the density is just \mathbb{E}[y(t+h)\mid \mathcal(D_t)] i.e. expected value of y at time t given all the information we have before time t.
\mathbb{E}[y(t+h)\mid \mathcal(D_t)] = F'_{t+h} G_{t+h} \ldots G_{t+1} \mathbb{E}[\theta_t \mid \mathcal{D}_t] \tag{5}
This is the form of the forecast function.
There are particular cases and particular models that we will be discussing in which the F_t=F, i.e. constant and also G_t = G is also constant for all t. In these cases, the forecast function can be simplified and written as:
f_t(h) = \mathbb{E}(y_{t+h} \mid D_t) = F'G^h \mathbb{E}(\theta_t \mid \mathcal{D}_t) \tag{6}
One thing that we will learn is that the eigenstructure of this matrix is very important to define the form of the forecast function, and it’s very important for model building and for adding components into your model.
Finally, just in terms of short notation, we can always write down when we’re working with normal dynamic linear models, we may be referring to the model instead of writing the two equations, the system and the observation equation. I can just write all the components that define my model. \{F_t, G_t, v_t, W_t\} \tag{7}
Now lets looks at the polynomial trend models. These are models that are useful to describe linear trends or polynomial trends in your time series. So if you have a data set, where you have an increasing trend, or a decreasing trend, you would use one of those components in your model.
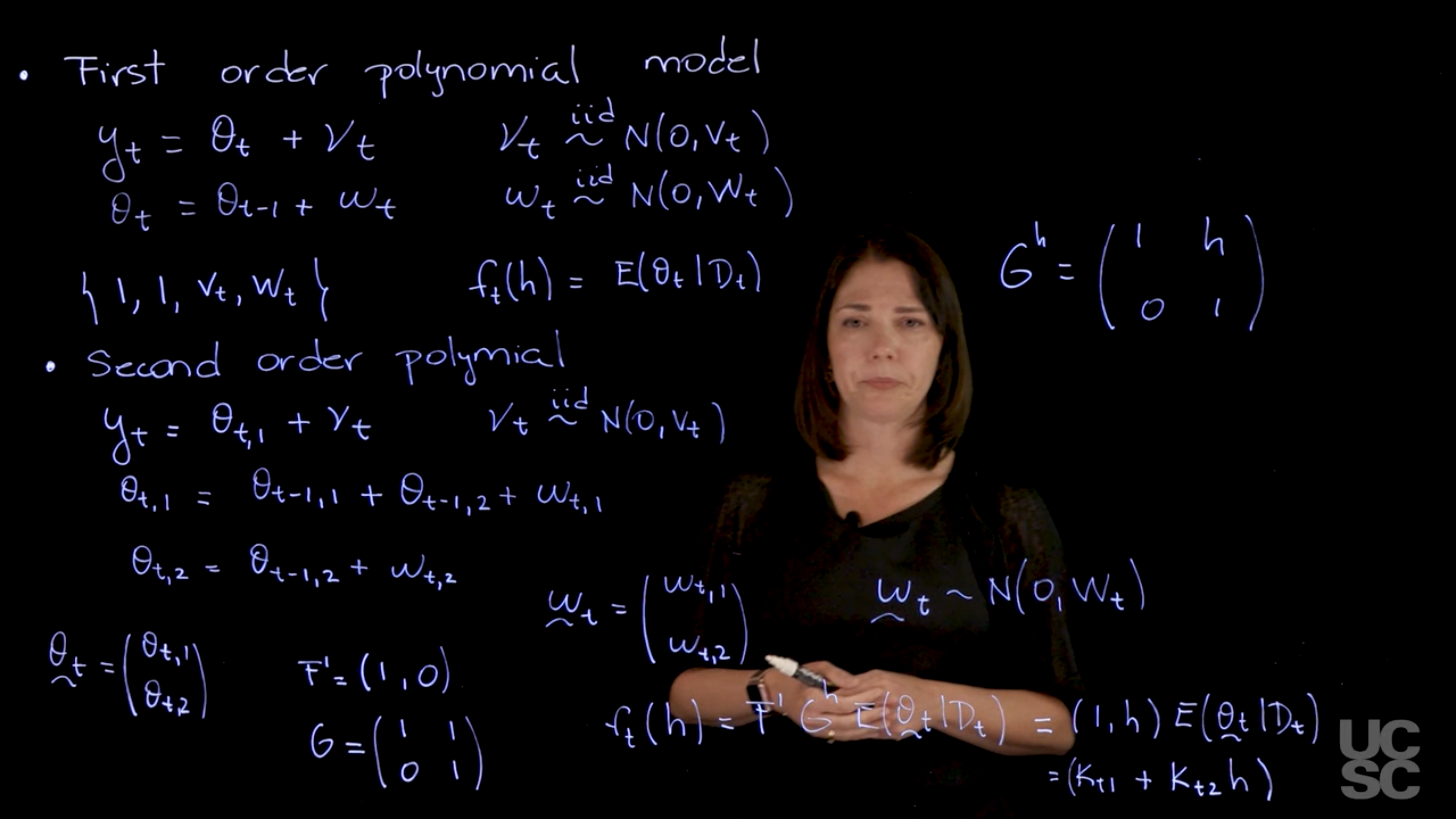
In (West and Harrison 2013, sec. 2.1) this is used in the introduction to the DLM and a very large proportion of the book is dedicated to in depth analysis and Bayesian development of this specific model and different distribution of interests as well as including comparison to other models and a look at the signal to noise ratio in the model.
. A first order polynomial is of the form “Ax+B” where A is the slope and B is the intercept. This is also the same model we saw in motivating the NLDM above.
\begin{aligned} y_t &= \theta_t + \nu_t, \qquad & \nu_t & \overset{\text{iid}}{\sim} N(0, V_t) \\ \theta_t &= \theta_{t-1} + \omega_t, \qquad & \omega_t & \overset{\text{iid}}{\sim} N(0, W_t) \end{aligned}
In the observation equation, \theta_{t} is the level of the series at time t and \nu_t is the observation error. In the evolution equation we see the mean for this parameter changing over time as a random walk or a local constant mean with evolution noise \omega_t.
(West and Harrison 2013, sec. 2.1) gives the following representation of the model:
It is useful to think of \theta_t as a smooth function of time \theta(t) with an associated Taylor series representation
\theta(t + δt) = \theta(t) + higher-order terms,
with the model simply describing the higher-order terms as zero-mean noise.
This is the genesis of the first-order polynomial DLM: the level model is a locally constant (first-order polynomial) proxy for the underlying evolution.
We can write it down in short form with the following quadrupleL
\{1, 1, V_t, W_t\} \qquad f_t(h) = \mathbb{E}[\theta_t \mid \mathcal{D}_t] = m_t \ \forall h>0
which fully defines the model.
Next we can write the forecast function of this model using the representation we gave in Equation 6.
Again, we’re going to have something of the form F transposed G to the power of h and then the expected value of that \theta_t given \mathcal{D}_t. F is 1, G is 1, therefore I’m going to end up having just expected value of \theta_t given \mathcal{D}_t.
Which depending on the data that you have is you’re just going to have something that is a value that depends on t and it doesn’t depend on h. What this model is telling you is that the forecast function, how you expect to see future values of the series h steps ahead is something that looks like the level that you estimated at time t.
(West and Harrison 2013, secs. 7.1–7.2) gives a detailed analysis of this model.
Now we want to create a model in which captures things that has a linear trend either increasing or decreasing. To do thus we need to have two components in our parameter vector of the state vector.
\begin{aligned} y_t &= \theta_{t,1} + \nu_t \quad &\nu_t &\overset{\text{iid}}{\sim} N(0, v_t) \\ \theta_{t,1} &= \theta_{t-1,1} + \theta_{t-1,2} + \omega_{t,1} \qquad &\omega_{t,1} &\overset{\text{iid}}{\sim} N(0, w_{t,11}) \\ \theta_{t,2} &= \theta_{t-1,2} + \omega_{t,2} \qquad &\omega_{t,2} &\overset{\text{iid}}{\sim} N(0, w_{t,22}) \end{aligned}
For this we will need two components in our parameter vector of the state vector1.
So we have again something that looks like in my observation equation. I’m going to have, I’m going to call it say \theta_{t,1} Normal vt, and then I’m going to have say theta_{t,1} is going to be of the form to theta_{t-1,1} and there is another component here.
The other component enters this equation plus let’s call this
And then I have finally also I need an evolution for the second component of the process which is going to be again having a random walk type of behavior.
So there is different ways in which you can interpret this two parameters but essentially one of them is related to the baseline level of the series the other one is related to the rate of change of the of the series. So if you think about the dlm representation again, these two components, I can collect into the vector wt.
and then assume that this wt Is normal. Now this is a bivariate normal. So what would be my F and my G in this model? So again my theta vector has two components
My G, so my F is going to be a two dimensional vectors. So I can write down F transposed as the only component that appears at this level is the first component of the vector. I’m going to have 1 and then a zero for F transposed. And then my G here if you think about writing down theta t times G say the t -1 +wt. Then you have that you’re G is going to have this form.
So for the first component, I have past values of both components. That’s why I have a 1 and 1 here for the second component I only have the past value of the second component. So there is a zero and a 1. So this tells me what is the structure of this second order polynomial. If I think about how to obtain the forecast function for this second order polynomial is going to be very similar to what we did before. So you can write it down as F transposed G to the power of h, expected value of theta t given Dt. Now the expected value is going to be vector also with two components because theta_t is a two dimensional vector. The structure here if you look at what G is G to the power of h going to be a matrix, that is going to look like 1, h, 0 1. When you multiply that matrix time this times this F what you’re going to end up having is something that looks like 1 h times this expected value of theta t given Dt. So I can think of two components here, so this gives you a constant on h, this part is not going to depend on h. So I can write this down as k t 11 component multiplied by 1 and then I have another constant, multiplied by h. So you can see what happens now is that your forecast function has the form of a linear polynomial. So it’s just a linear function on the number of steps ahead. The slope and the intercept related to that linear function are going to depend on the expected value of, theta_t given the all the information I have up to time t. But essentially is a way to model linear trends. So this is what happens with the second order polynomial model.
As we included linear trends and constant values in the forecast function, we may want to also incorporate other kinds of trends, polynomial trends in the model. So you may want to have a quadratic form, the forecast function or a cubic forecast function as a function of h.
\{F, G, V_t, W_t\}
\theta_t = (\theta_{t,1}, \theta_{t,2})' \qquad \mathbf{G} = \mathbf{J}_2(1) \qquad \mathbf{E}_2 = (1, 0)'
\quad \mathbf{G^h} = \begin{pmatrix} 1 & h \\ 0 & 1 \end{pmatrix}
$$ \begin{aligned} f_t(h) &= F' G^h \mathbb{E}[\theta_t \mid \mathcal{D}_t] \\ &= (K_{t,0} + h K_{t,1}) \end{aligned}$$
\begin{aligned} \mathbf{G^h} &= \begin{pmatrix} 1 & h \\ 0 & 1 \end{pmatrix} \end{aligned}
In this case, we have:
The first order polynomial model is a model that is useful to describe linear trends in your time series. If you have a data set where you have an increasing trend or a decreasing trend, you would use one of those components in your model.
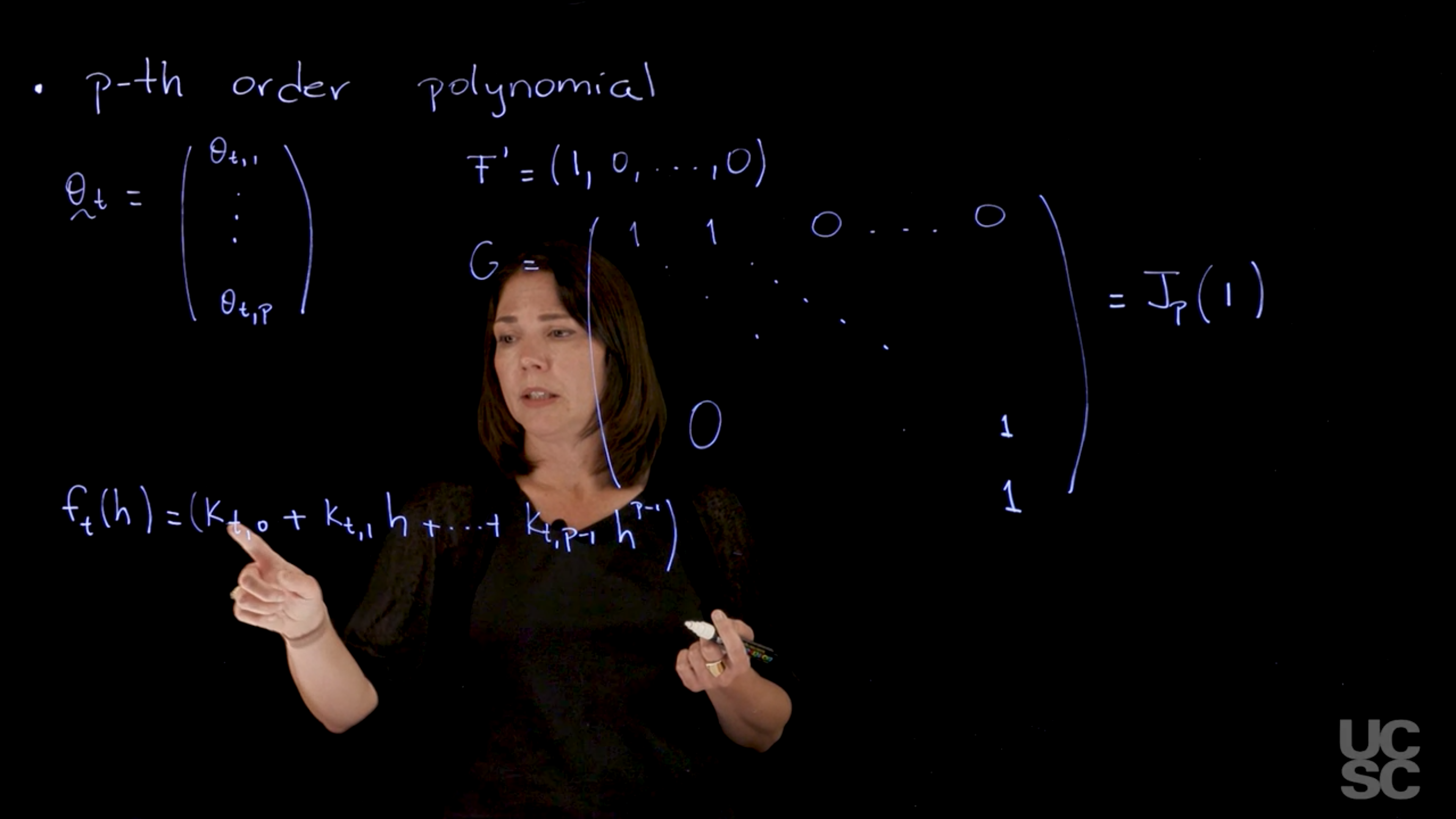
So the all those can be incorporated using the general p-order polynomial model, so I will just describe the form of this model.
And in this type of model, the forecast function is going to have order p -1. So your parameter vector is going to have dimension p. So you’re going to have theta_t theta t1 to tp.
Your F matrix is going to be constant if I write it as a row vector. F transpose is going to be a p dimensional vector with the one in the first entry and zeros everywhere else.
My G matrix is going to have this form and there is different parameterizations of this model and I will talk a little bit about this. But one way to parameterize the model is something that looks like this. So you have ones in the diagonal of the matrix, the matrix is going to be a p by p has to be the dimension of the p compatible with the dimension of the state vector. And then you have zeros’s below the diagonal above that set of ones that are also ones above the diagonal. So this matrix G is what we call a Jordan block of dimension p of 1. So here 1 is the number that appears in the diagonal. And then I have a p Ip matrix, I have ones in the upper diagonal part. So this is the form of the model, so once again I have the F the G, and the wt. I have my model. The forecast function in this case again can be written as F transposed G to the power of h. And when you simplify times expected value of theta_t, given Dt. Once you simplify those functions you get something that is a polynomial of order p-1 in h. So I just can write this down as kt constant.
Plus kt1 h + kt p- 1, h to the p -1, so that’s my forecast function. There is an alternative parameterization of this model that has the same F and the same algebraic form of the forecast function, the same form of the forecast function. But instead of having this G matrix, it has a matrix that has ones in the diagonal and ones everywhere above the diagonal. So it’s an upper triangular matrix with ones in the diagonal and above the diagonal. That’s a different parameterization of the same model is going to have the same general form of the forecast function is a different parameterization. So again, you can consider the way you think about these models is you think what kind of forecast function I want to have for my future? What is the type of predictions that I expect to have in my model? And if they look like a linear trend, I use a second order polynomial. If it looks like a quadratic trend in the forecast then I would use 3rd order polynomial model representation.

Duis ornare ex ac iaculis pretium. Maecenas sagittis odio id erat pharetra, sit amet consectetur quam sollicitudin. Vivamus pharetra quam purus, nec sagittis risus pretium at. Nullam feugiat, turpis ac accumsan interdum, sem tellus blandit neque, id vulputate diam quam semper nisl. Donec sit amet enim at neque porttitor aliquet. Phasellus facilisis nulla eget placerat eleifend. Vestibulum non egestas eros, eget lobortis ipsum. Nulla rutrum massa eget enim aliquam, id porttitor erat luctus. Nunc sagittis quis eros eu sagittis. Pellentesque dictum, erat at pellentesque sollicitudin, justo augue pulvinar metus, quis rutrum est mi nec felis. Vestibulum efficitur mi lorem, at elementum purus tincidunt a. Aliquam finibus enim magna, vitae pellentesque erat faucibus at. Nulla mauris tellus, imperdiet id lobortis et, dignissim condimentum ipsum. Morbi nulla orci, varius at aliquet sed, facilisis id tortor. Donec ut urna nisi.
\begin{aligned} y_t &= \mu_t + \nu_t, \qquad & \nu_t &\sim N(0, v_t) \\ \mu_t &= \mu_{t-1} + \omega_t, \qquad & \omega_t &\sim N(0, w_t) \end{aligned}
In this case, we have:
\theta_t = \mu_t \quad \forall t
F_t = 1 \quad \forall t,
G_t = 1 \quad \forall t,
resulting in:
\{1, 1, v_t, w_t\} \qquad \text{(short notation)}
The forecast function is:
f_t(h) = E(\mu_t \mid \mathcal{D}_t) = k_t, \quad \forall h > 0.
\begin{aligned} y_t &= \theta_{t,1} + \nu_t, \quad &\nu_t &\sim N(0, v_t) \\ \theta_{t,1} &= \theta_{t-1,1} + \theta_{t-1,2} + \omega_{t,1}, \qquad &\omega_{t,1} &\sim N(0, w_{t,11}) \\ \theta_{t,2} &= \theta_{t-1,2} + \omega_{t,2}, \qquad &\omega_{t,2} &\sim N(0, w_{t,22}), \end{aligned}
where we can also have:
\text{Cov}(\theta_{t,1}, \theta_{t,2} ) = w_{t,12} = w_{t,21}
This can be written as a DLM with the state-space vector \theta_t = (\theta_{t,1}, \theta_{t,2})', and
\{\mathbf{F}, \mathbf{G}, v_t, \mathbf{W}_t\} \qquad \text{(short notation)}
with \mathbf{F} = (1, 0)' and
\mathbf{G} = \begin{pmatrix} 1 & 1 \\ 0 & 1 \end{pmatrix}, \quad \mathbf{W}_t = \begin{pmatrix} w_{t,11} & w_{t,12} \\ w_{t,21} & w_{t,22} \end{pmatrix}.
Note that
\mathbf{G}^2 = \begin{pmatrix} 1 & 2 \\ 0 & 1 \end{pmatrix}, \quad \mathbf{G}^h = \begin{pmatrix} 1 & h \\ 0 & 1 \end{pmatrix},
and so:
f_t(h) = (1, h) E(\mathbf{\theta}_t \mid \mathcal{D}_t) = (1, h) (k_{t,0}, k_{t,1})' = (k_{t,0} + h k_{t,1}).
Here \mathbf{G} = \mathbf{J}_2(1) (see below).
Also, we denote \mathbf{E}_2 = (1, 0)', and so the short notation for this model is
\{E_2, J_2(1), \cdot, \cdot\}
We can consider a p-th order polynomial model. This model will have a state-space vector of dimension p and a polynomial of order p-1 forecast function on h. The model can be written as
\{E_p, J_p(1), v_t, W_t\} \qquad \text{(short notation)}
with \mathbf{F}_t = \mathbf{E}_p = (1, 0, \dots, 0)' and \mathbf{G}_t = \mathbf{J}_p(1), with
\mathbf{J}_p(1) = \begin{pmatrix} 1 & 1 & 0 & \cdots & 0 & 0 & 0 \\ 0 & 1 & 1 & \cdots & 0 & 0 & 0 \\ \vdots & \vdots & \ddots & \ddots & & \vdots \\ 0 & 0 & 0 & \cdots & 0 & 1 & 1 \\ 0 & 0 & 0 & \cdots & 0 & 0 & 1 \end{pmatrix}.
The forecast function is given by
f_t(h) = k_{t,0} + k_{t,1} h + \dots + k_{t,p-1} h^{p-1}.
There is also an alternative parameterization of this model that leads to the same algebraic form of the forecast function, given by \{E_p, L_p, v_t, W_t\}, with
L_p = \begin{pmatrix} 1 & 1 & 1 & \cdots & 1 \\ 0 & 1 & 1 & \cdots & 1 \\ \vdots & \vdots & \ddots & \ddots & \vdots \\ 0 & 0 & 0 & \cdots & 1 \end{pmatrix}.
\begin{aligned} y_t &= \beta_{t,0} + \beta_{t,1} x_t + \nu_t \\ \beta_{t,0} &= \beta_{t-1,0} + \omega_{t,0} \\ \beta_{t,1} &= \beta_{t-1,1} + \omega_{t,1} \end{aligned}
Thus:
\theta_t = (\beta_{t,0}, \beta_{t,1})'
F_t = (1, x_t)'
and
G = I_2
This results in a forecast function of the form
f_t(h) = k_{t,0} + k_{t,1} x_{t+h}.
\begin{aligned} y_t &= \beta_{t,0} + \beta_{t,1} x_{t,1} + \dots + \beta_{t,M} x_{t,M} + \nu_t \\ \beta_{t,m} &= \beta_{t-1,m} + \omega_{t,m}, \quad &m = 0:M. \end{aligned}
Then,
\theta_t = (\beta_{t,0}, \dots, \beta_{t,M})',
\mathbf{F}_t = (1, x_{t,1}, \dots, x_{t,M})' and
\mathbf{G} = \mathbf{I}_M.
The forecast function is given by:
f_t(h) = k_{t,0} + k_{t,1} x_{t+h,1} + \dots + k_{t,M} x_{t+h,M}.
A particular case of dynamic regressions is the case of time-varying autoregressions (TVAR) with
\begin{aligned} y_t &= \phi_{t,1} y_{t-1} + \phi_{t,2} y_{t-2} + \dots + \phi_{t,p} y_{t-p} + \nu_t \\ \phi_{t,m} &= \phi_{t-1,m} + \omega_{t,m}, \quad m = 1:p. \end{aligned}
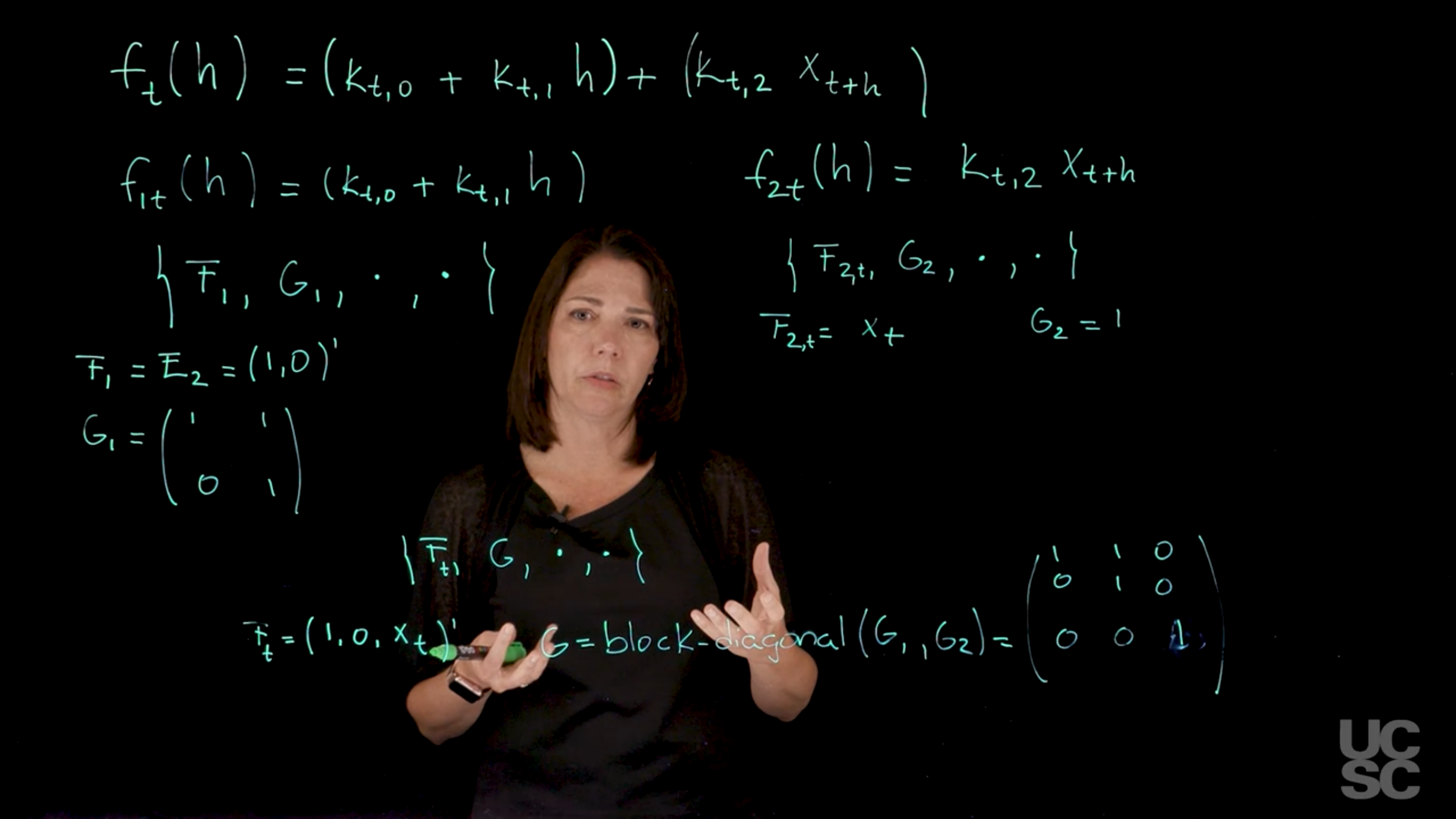
We can use the superposition principle to build models that have different kinds of components. The main idea is to think about what is the general structure we want for the forecast function and then isolate the different components of the forecast function and think about the classes of dynamic linear models that are represented in each of those components. Each of those components has a class and then we can build the general dynamic linear model with all those pieces together using this principle.
I will illustrate how to do that with an example: Let’s say that you want to create a model here with a forecast function that has a linear trend component. Let’s say we have a linear function as a function of the number of steps ahead that you want to consider. Then suppose you also have a covariate here that you want to include in your model as a regression component. f_t(h) = \underbrace{(k_{t,0} + k_{t,1}h)}_{\text{linear trend component}} + \underbrace{(k_{t,2}x_{t+h})}_{\text{regression component}} \tag{8}
where:
Let’s say we have a K_{t2} and then we have x_{t+h}, this is my covariate. Again, the k’s here are just constants, as of constants in terms of h, they are dependent on time. This is the general structure we want to have for the forecast function.
When I look at the forecast function, I can isolate and separate these two components. I have a component that looks like a linear trend and then I have a component that is a regression component. Each of this can be set in terms of two forecast functions. I’m going to call the forecast function f_1t h, this is just the first piece.
f_t(h) = f_{1,t}(h) + f_{2,t}(h)
where:
f_{1,t}(h) = k_{t,0} + k_{t,1} \qquad \text{(linear trend component)} \tag{9} and f_{2,t}(h) = k_{t,2}x_{t+h} \qquad \text{(regression component)} \tag{10}
Then I have my second piece here. I’m going to call it f_{2t}, is just this piece here with the regression component. We know how to represent this forecast function in terms of a dynamic linear model.
For the linear trend component, we have a 2-dimensional state vector, \theta_t = (\theta_{t,1}, \theta_{t,2})', with
for the linear trend component f_{1,t}(h) we have the following DLM representation:
\{F_1, G_1, \cdot, \cdot\} \qquad \text{(short notation)}
where we don’t explicitly specify the observational and system variances, V and W - The important bit are F,and G. The forecast function is given by:
F_{1} = E_2 = (1, 0)'
G_{1} = \begin{pmatrix} 1 & 1 \\ 0 & 1 \end{pmatrix}
for the regression component f_{2,t}(h) we have the following DLM representation:
\{F_2,t, G_2, \cdot, \cdot\} \qquad \text{(short notation)}
where
F_{2,t} = x_{t+h}
G_{2} = 1
I can write down a model that has an F, G, and some V, and some W that I’m going to just leave here and not specify them explicitly because the important components for the structure of the model are the F and the G. If you’ll recall the F in the case of a forecast function with a linear trend like this, is just my E_2 vector, which is a two-dimensional vector. The first entry is one, and the second one is a zero. Then the G in this case is just this upper triangular matrix that has 1, 1 in the first row and 0, 1 in the second one. Remember, in this case we have a two-dimensional state vector where one of the components in the vector is telling me information about the level of the time series, the other component is telling me about the rate of change in that level. This is a representation that corresponds to this forecast function. For this other forecast function, we have a single covariate, it’s just a regression and I can represent these in terms of an F_2, G_2, and then some observational variance and some system variance here in the case of a single covariate and this one depends on t. We have F_2t is X_t and my G here is simply going to be one. This is a one-dimensional vector in terms of the state parameter vector. We have a single state vector and it’s just going to tell me about the changes, the coefficient that goes with the X_t covariate. Once I have these, I can create my final model and I’m going to just say that my final model is F, G, and then I have some observational variance and some covariance also for the system where the F is going to be an F that has, you just concatenate the two Fs. You’re going to get 1, 0 and then you’re going to put the next component here. Again, this one is dependent on time because this component is time dependent and then the G, you can create it just taking a block diagonal structure,
G_1 and G_2. You just put together, the first one is 1, 1, 0, 1 and then I concatenate this one as a block diagonal. This should be one.
This gives me the full G function for the model. Now a model with this F_t and this G that is constant over time will give me this particular forecast function. I’m using the superposition principle to build this model. If you want additional components, we will learn how to incorporate seasonal components, regression components, trend components. You can build a fairly sophisticated model with different structures into this particular model using the superposition principle.
You can build dynamic models with different components, for example, a trend component plus a regression component, by using the principle of superposition. The idea is to think about the general form of the forecast function you want to have for prediction. You then write that forecast function as a sum of different components where each component corresponds to a class of DLM with its own state-space representation. The final DLM can then be written by combining the pieces of the different components.
For example, suppose you are interested in a model with a forecast function that includes a linear polynomial trend and a single covariate x_t, i.e.,
f_t(h) = k_{t,0} + k_{t,1}h + k_{t,3}x_{t+h}.
This forecast function can be written as f_t(h) = f_{1,t}(h) + f_{2,t}(h), with
f_{1,t}(h) = (k_{t,0} + k_{t,1}h), \quad f_{2,t}(h) = k_{t,3}x_{t+h}.
The first component in the forecast function corresponds to a model with a 2-dimensional state vector, F_{1,t} = F_1 = (1, 0)',
G_{1,t} = G_1 = \begin{pmatrix} 1 & 1 \\ 0 & 1 \end{pmatrix}.
The second component corresponds to a model with a 1-dimensional state vector, F_{2,t} = x_t, G_{2,t} = G_2 = 1.
The model with forecast function f_t(h) above is a model with a 3-dimensional state vector with F_t = (F_1', F_{2,t})' = (1, 0, x_t)' and
G_t = \text{blockdiag}[G_1, G_2] = \begin{pmatrix} 1 & 1 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{pmatrix}.
Assume that you have a time series process y_t with a forecast function
f_t(h) = \sum_{i=1}^{m} f_{i,t}(h),
where each f_{i,t}(h) is the forecast function of a DLM with representation \{F_{i,t}, G_{i,t}, v_{i,t}, W_{i,t}\}.
Then, f_t(h) has a DLM representation \{F_t, G_t, v_t, W_t\} with
F_t = (F_{1,t}', F_{2,t}', \dots, F_{m,t}')',
G_t = \text{blockdiag}[G_{1,t}, \dots, G_{m,t}],
v_t = \sum_{i=1}^{m} v_{i,t},
and
W_t = \text{blockdiag}[W_{1,t}, \dots, W_{m,t}].
Omitted due to Coursera honor code

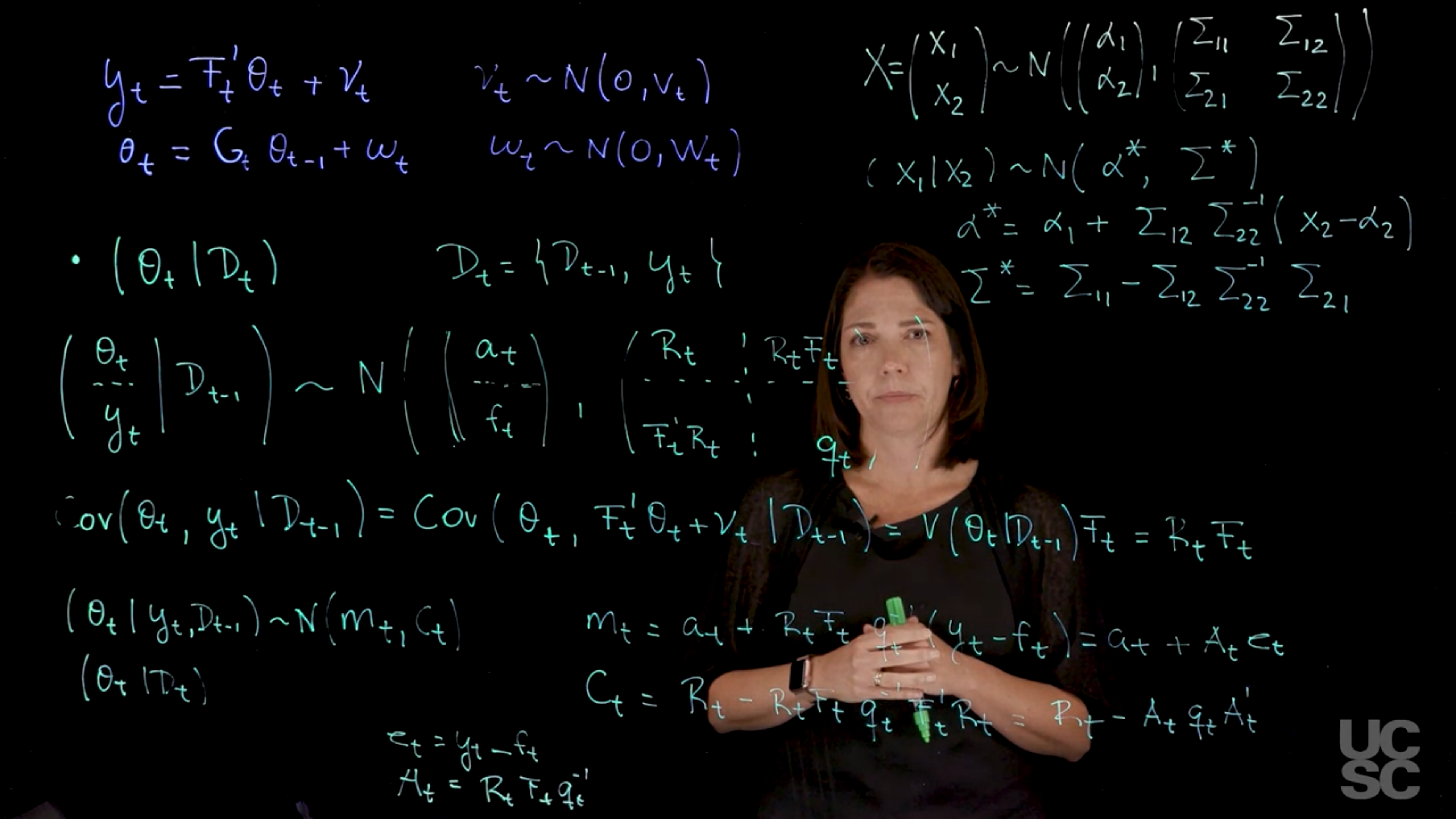
Etiam quis tortor luctus, pellentesque ante a, finibus dolor. Phasellus in nibh et magna pulvinar malesuada. Ut nisl ex, sagittis at sollicitudin et, sollicitudin id nunc. In id porta urna. Proin porta dolor dolor, vel dapibus nisi lacinia in. Pellentesque ante mauris, ornare non euismod a, fermentum ut sapien. Proin sed vehicula enim. Aliquam tortor odio, vestibulum vitae odio in, tempor molestie justo. Praesent maximus lacus nec leo maximus blandit.
Maecenas turpis velit, ultricies non elementum vel, luctus nec nunc. Nulla a diam interdum, faucibus sapien viverra, finibus metus. Donec non tortor diam. In ut elit aliquet, bibendum sem et, aliquam tortor. Donec congue, sem at rhoncus ultrices, nunc augue cursus erat, quis porttitor mauris libero ut ex. Nullam quis leo urna. Donec faucibus ligula eget pellentesque interdum. Lorem ipsum dolor sit amet, consectetur adipiscing elit. Aenean rhoncus interdum erat ut ultricies. Aenean tempus ex non elit suscipit, quis dignissim enim efficitur. Proin laoreet enim massa, vitae laoreet nulla mollis quis.
Consider an NDLM given by:
y_t = F_t' \theta_t + \nu_t, \quad \nu_t \sim N(0, v_t), \tag{1}
\theta_t = G_t \theta_{t-1} + \omega_t, \quad \omega_t \sim N(0, W_t), \tag{2}
with F_t, G_t, v_t, and W_t known. We also assume a prior distribution of the form (\theta_0 \mid D_0) \sim N(m_0, C_0), with m_0, C_0 known.
We are interested in finding p(\theta_t \mid D_t) for all t. Assume that the posterior at t-1 is such that:
(\theta_{t-1} \mid D_{t-1}) \sim N(m_{t-1}, C_{t-1}).
Then, we can obtain the following:
(\theta_t \mid D_{t-1}) \sim N(a_t, R_t),
with
a_t = G_t m_{t-1},
and
R_t = G_t C_{t-1} G_t' + W_t.
(y_t \mid D_{t-1}) \sim N(f_t, q_t),
with
f_t = F_t' a_t, \quad q_t = F_t' R_t F_t + v_t.
\begin{aligned} m_t &= a_t + R_t F_t q_t^{-1} (y_t - f_t), \\ C_t &= R_t - R_t F_t q_t^{-1} F_t' R_t. \end{aligned}
Now, denoting e_t = (y_t - f_t) and A_t = R_t F_t q_t^{-1}, we can rewrite the equations above as:
\begin{aligned} m_t &= a_t + A_t e_t, \\ C_t &= R_t - A_t q_t A_t' \end{aligned}
#################################################
##### Univariate DLM: Known, constant variances
#################################################
set_up_dlm_matrices <- function(FF, GG, VV, WW){
return(list(FF=FF, GG=GG, VV=VV, WW=WW))
}
set_up_initial_states <- function(m0, C0){
return(list(m0=m0, C0=C0))
}
### forward update equations ###
forward_filter <- function(data, matrices, initial_states){
## retrieve dataset
yt <- data$yt
T <- length(yt)
## retrieve a set of quadruples
# FF, GG, VV, WW are scalar
FF <- matrices$FF
GG <- matrices$GG
VV <- matrices$VV
WW <- matrices$WW
## retrieve initial states
m0 <- initial_states$m0
C0 <- initial_states$C0
## create placeholder for results
d <- dim(GG)[1]
at <- matrix(NA, nrow=T, ncol=d)
Rt <- array(NA, dim=c(d, d, T))
ft <- numeric(T)
Qt <- numeric(T)
mt <- matrix(NA, nrow=T, ncol=d)
Ct <- array(NA, dim=c(d, d, T))
et <- numeric(T)
for(i in 1:T){
# moments of priors at t
if(i == 1){
at[i, ] <- GG %*% t(m0)
Rt[, , i] <- GG %*% C0 %*% t(GG) + WW
Rt[, , i] <- 0.5*Rt[, , i]+0.5*t(Rt[, , i])
}else{
at[i, ] <- GG %*% t(mt[i-1, , drop=FALSE])
Rt[, , i] <- GG %*% Ct[, , i-1] %*% t(GG) + WW
Rt[, , i] <- 0.5*Rt[, , i]+0.5*t(Rt[, , i])
}
# moments of one-step forecast:
ft[i] <- t(FF) %*% (at[i, ])
Qt[i] <- t(FF) %*% Rt[, , i] %*% FF + VV
# moments of posterior at t:
At <- Rt[, , i] %*% FF / Qt[i]
et[i] <- yt[i] - ft[i]
mt[i, ] <- at[i, ] + t(At) * et[i]
Ct[, , i] <- Rt[, , i] - Qt[i] * At %*% t(At)
Ct[, , i] <- 0.5*Ct[, , i]+ 0.5*t(Ct[, , i])
}
cat("Forward filtering is completed!") # indicator of completion
return(list(mt = mt, Ct = Ct, at = at, Rt =
Rt, ft = ft, Qt = Qt))
}
forecast_function <- function(posterior_states, k, matrices){
## retrieve matrices
FF <- matrices$FF
GG <- matrices$GG
WW <- matrices$WW
VV <- matrices$VV
mt <- posterior_states$mt
Ct <- posterior_states$Ct
## set up matrices
T <- dim(mt)[1] # time points
d <- dim(mt)[2] # dimension of state-space parameter vector
## placeholder for results
at <- matrix(NA, nrow = k, ncol = d)
Rt <- array(NA, dim=c(d, d, k))
ft <- numeric(k)
Qt <- numeric(k)
for(i in 1:k){
## moments of state distribution
if(i == 1){
at[i, ] <- GG %*% t(mt[T, , drop=FALSE])
Rt[, , i] <- GG %*% Ct[, , T] %*% t(GG) + WW
Rt[, , i] <- 0.5*Rt[, , i]+0.5*t(Rt[, , i])
}else{
at[i, ] <- GG %*% t(at[i-1, , drop=FALSE])
Rt[, , i] <- GG %*% Rt[, , i-1] %*% t(GG) + WW
Rt[, , i] <- 0.5*Rt[, , i]+0.5*t(Rt[, , i])
}
## moments of forecast distribution
ft[i] <- t(FF) %*% t(at[i, , drop=FALSE])
Qt[i] <- t(FF) %*% Rt[, , i] %*% FF + VV
}
cat("Forecasting is completed!") # indicator of completion
return(list(at=at, Rt=Rt, ft=ft, Qt=Qt))
}
## obtain 95% credible interval
get_credible_interval <- function(mu, sigma2,
quantile = c(0.025, 0.975)){
z_quantile <- qnorm(quantile)
bound <- matrix(0, nrow=length(mu), ncol=2)
bound[, 1] <- mu +
z_quantile[1]*sqrt(as.numeric(sigma2)) # lower bound
bound[, 2] <- mu +
z_quantile[2]*sqrt(as.numeric(sigma2)) # upper bound
return(bound)
}
####################### Example: Lake Huron Data ######################
plot(LakeHuron,main="Lake Huron Data",
ylab="level in feet") # Total of 98 observations 
k=4
T=length(LakeHuron)-k # We take the first 94 observations
# only as our data
ts_data=LakeHuron[1:T]
ts_validation_data <- LakeHuron[(T+1):98]
data <- list(yt = ts_data)
# First order polynomial model
## set up the DLM matrices
FF <- as.matrix(1)
GG <- as.matrix(1)
VV <- as.matrix(1)
WW <- as.matrix(1)
m0 <- as.matrix(570)
C0 <- as.matrix(1e4)
## wrap up all matrices and initial values
matrices <- set_up_dlm_matrices(FF, GG, VV, WW)
initial_states <- set_up_initial_states(m0, C0)
## filtering
results_filtered <- forward_filter(data, matrices,
initial_states)Forward filtering is completed!names(results_filtered)[1] "mt" "Ct" "at" "Rt" "ft" "Qt"ci_filtered <- get_credible_interval(results_filtered$mt,
results_filtered$Ct)
## forecasting
results_forecast <- forecast_function(results_filtered,k,
matrices)Forecasting is completed!ci_forecast <- get_credible_interval(results_forecast$ft,
results_forecast$Qt)
index=seq(1875, 1972, length.out = length(LakeHuron))
index_filt=index[1:T]
index_forecast=index[(T+1):98]
plot(index, LakeHuron, ylab = "level",
main = "Lake Huron Level",type='l',
xlab="time",lty=3,ylim=c(574,584))
points(index,LakeHuron,pch=20)
lines(index_filt, results_filtered$mt, type='l',
col='red',lwd=2)
lines(index_filt, ci_filtered[, 1], type='l',
col='red', lty=2)
lines(index_filt, ci_filtered[, 2], type='l', col='red', lty=2)
lines(index_forecast, results_forecast$ft, type='l',
col='green',lwd=2)
lines(index_forecast, ci_forecast[, 1], type='l',
col='green', lty=2)
lines(index_forecast, ci_forecast[, 2], type='l',
col='green', lty=2)
legend('bottomleft', legend=c("filtered","forecast"),
col = c("red", "green"), lty=c(1, 1))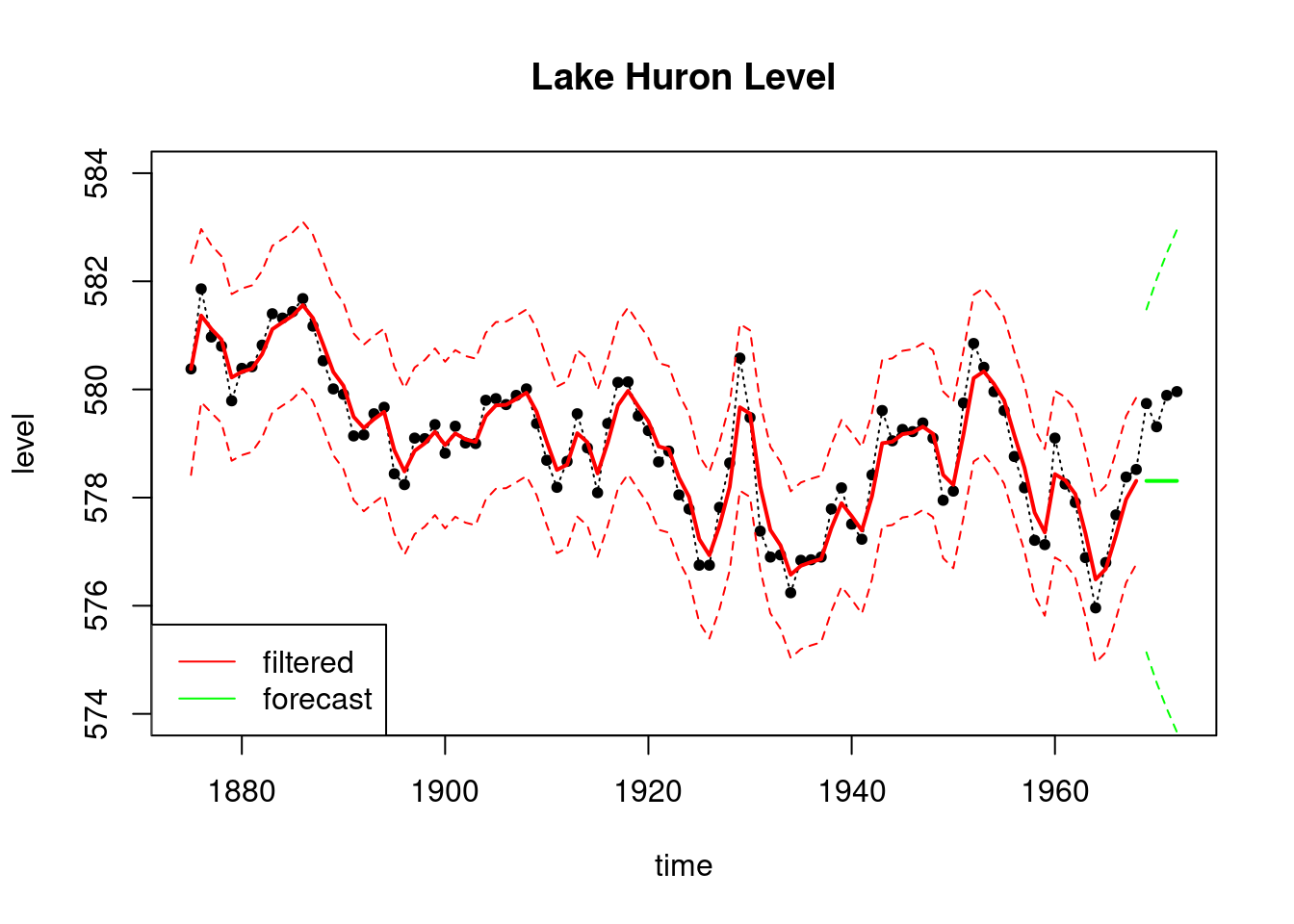
#Now consider a 100 times smaller signal to noise ratio
VV <- as.matrix(1)
WW <- as.matrix(0.01)
matrices_2 <- set_up_dlm_matrices(FF,GG, VV, WW)
## filtering
results_filtered_2 <- forward_filter(data, matrices_2,
initial_states)Forward filtering is completed!ci_filtered_2 <- get_credible_interval(results_filtered_2$mt,
results_filtered_2$Ct)
results_forecast_2 <- forecast_function(results_filtered_2,
length(ts_validation_data),
matrices_2)Forecasting is completed!ci_forecast_2 <- get_credible_interval(results_forecast_2$ft,
results_forecast_2$Qt)
plot(index, LakeHuron, ylab = "level",
main = "Lake Huron Level",type='l',
xlab="time",lty=3,ylim=c(574,584))
points(index,LakeHuron,pch=20)
lines(index_filt, results_filtered_2$mt, type='l',
col='magenta',lwd=2)
lines(index_filt, ci_filtered_2[, 1], type='l',
col='magenta', lty=2)
lines(index_filt, ci_filtered_2[, 2], type='l',
col='magenta', lty=2)
lines(index_forecast, results_forecast_2$ft, type='l',
col='green',lwd=2)
lines(index_forecast, ci_forecast_2[, 1], type='l',
col='green', lty=2)
lines(index_forecast, ci_forecast_2[, 2], type='l',
col='green', lty=2)
legend('bottomleft', legend=c("filtered","forecast"),
col = c("magenta", "green"), lty=c(1, 1))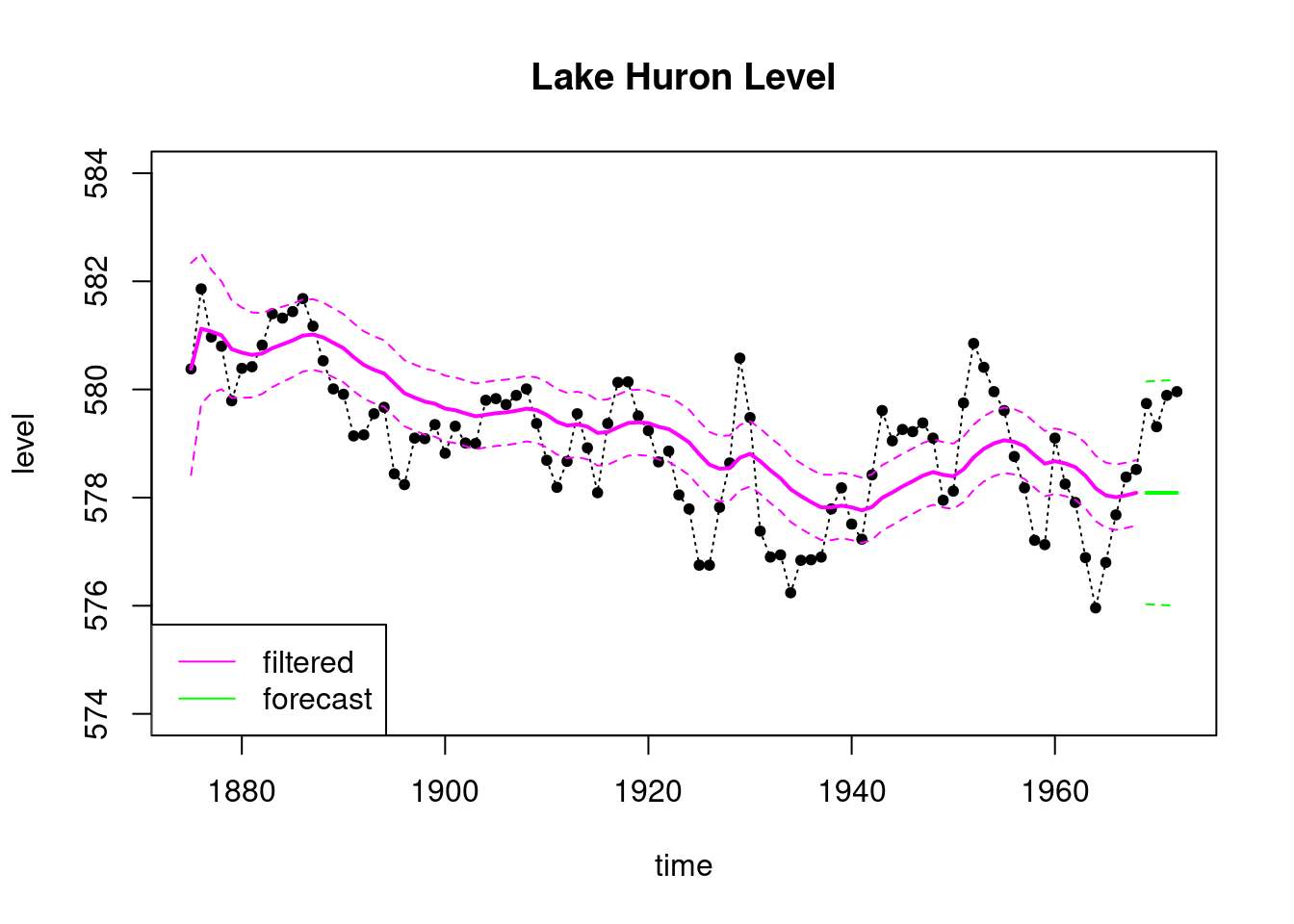
plot(index_filt,results_filtered$mt,type='l',col='red',lwd=2,
ylim=c(574,584),ylab="level")
lines(index_filt,results_filtered_2$mt,col='magenta',lwd=2)
points(index,LakeHuron,pch=20)
lines(index,LakeHuron,lty=2)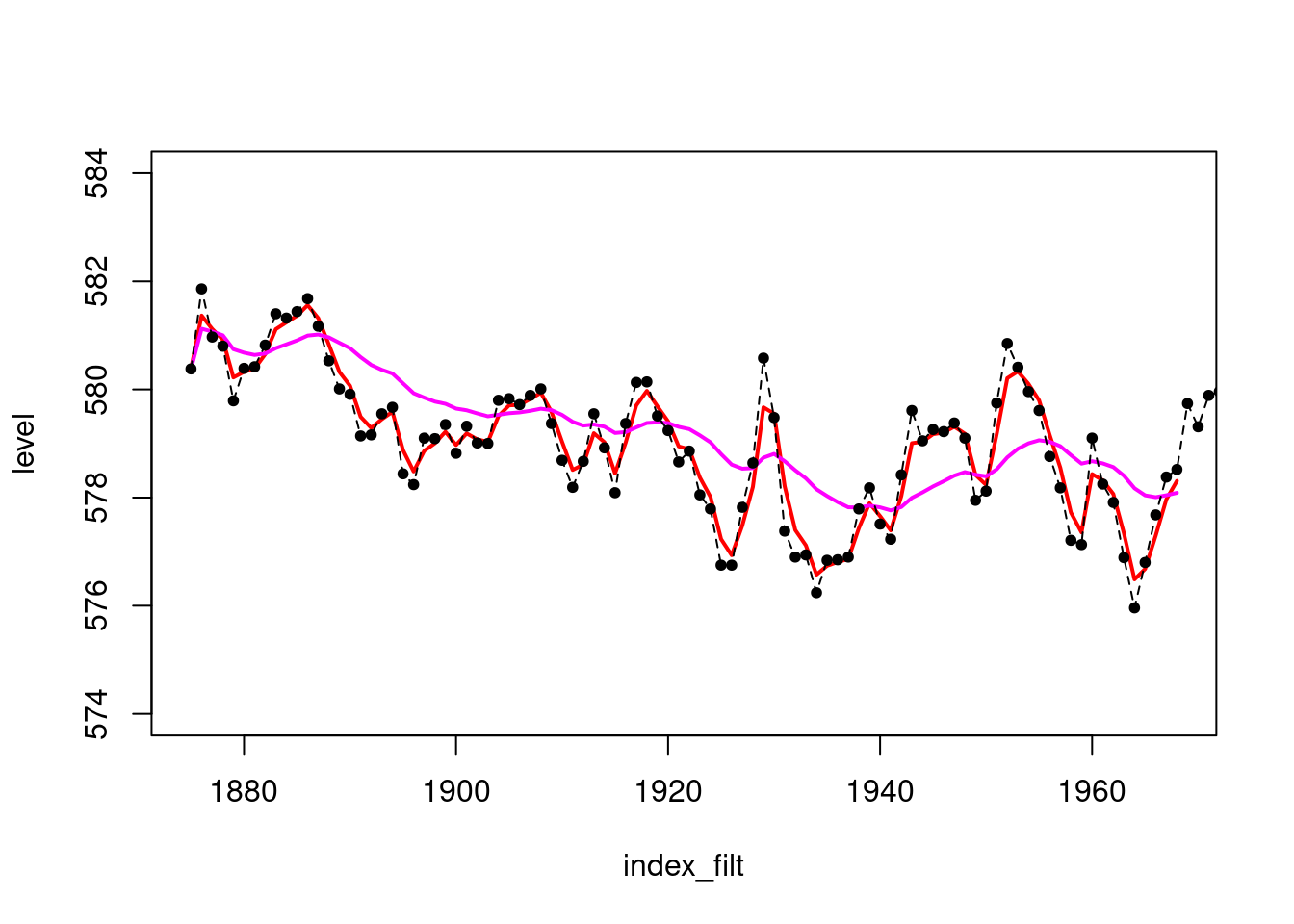

We know, we now discuss the smoothing equations for the case of the normal dynamic linear model. When we are assuming that both the variance at the observation level is known and the covariance matrix at the system level is also known. Recall we have two equations here, we have the observation equation, where yt is modeled as Ft’θt + noise the noise is N(0,vt). And we’re assuming that the vt is given. We are also assuming that we know Ft for all t. And then in the evolution equation we have θt= Gtθ(t-1)+noise. And then again, the assumption for the wt is here is that they are normally distributed with mean zero, and these variants co variance matrix, capital Wt. So we can summarize the model in terms of Ft, Gt, Vt and Wt, that are given for all t. We have discussed the filtering equations. So the process for obtaining the distributions of θt given Dt, as we collect observations over time is called filtering. Now we will discuss what happens when we do smoothing, meaning when we revisit the distributions of θt, given now that we have received a set of observations. So Just to illustrate the process, we have here, θ0,θ1 all way up to θ4. And we can assume just for the sake of the example, that we are going to receive three observations. So we are going to proceed with the filtering, and then once we receive the last observation at time three, we’re going to go backwards and we’re going to revisit the distributions for the state parameters. So just to remind you how the filtering works, we move forward, before we receive any observations. In the normal dynamic linear model, when we have all the variances known. The conjugate prior distribution is a normal, with mean m0 and variance C0. So this is specified by the user, before collecting any observations. We can then use the structure of the model, meaning the system equation and the observation equation to obtain the distribution of θt, given D0. Before observing the first y. This gives us first the distribution of θt, θ1 given D0, which is normal a1 R1. And then we can also get the one step ahead forecast distribution for y1 given D0, which is a normal f1 and q1. And we have discussed how to obtain these moments using the filtering equations. Then we received the first observation, and the first observation can allows us to update the distribution of θ1. So we obtain now the distribution of θ1 given y1, and whatever information we have at D0. So this gives us m1 C1. And using again the structure of the model, we can get the prior distribution for θ2 given the one and that’s a normal a2 R2. And then the one step ahead forecast distribution now for y2 given D1 and that’s a normal f2 q2. So we can receive y2 update the distribution of θ2 and we can continue this process, now get the priors at T=3. And then once we get the observation at T=3, we update the distribution. And we can continue like this with the prior for θ4 and so on. Let’s say that we stop here, at T=3. And now we are interested in answering the question. Well, what is the distribution for example of θ2 given that, now, I obtain not only y1 and y2, but also y3. I want to revisit that distribution using all that information. Same thing for say, the distribution of θ0, given the D0, y1, y2 and y3. So that’s what it’s called smoothing. So the smoothing equations, allow us to obtain those distributions. So just to talk a little bit about the notation again, in the normal dynamic linear model where vt and wt are known for all t’s. We have that this is a normal, so the notation here, the T, is larger than t, here. So we’re looking at the distribution of θt, now in the past and that one follows a normal distribution with mean aT(t-T). So the notation here for the subscript T means that I’m conditioning on all the information I have to T. And then the variance covariance matrix is given by this, RT(t-T). So this is just going to indicate how many steps I’m going to go backwards as you will see in the example.
So we have some recursions in the same way that we have the filtering equations. Now we have the smoothing equations. And for these smoothing equations we have that the mean. You can see here, that whenever you’re computing a particular step t- T, you’re going to need a quantity that you computed in the previous step, t-T+1. So you’re going to need that, is a recursion, but you’re also going to need mt and and at+1. So those are quantities that you computed using the filtering equations. So in order to get the smoothing equations, you first have to proceed with the filtering. Similarly for RT(t-T), you have also that depends on something you previously obtained. And then you also have the Ct, the Rt+1 and so on. So those quantities you computed when you were updating the filtering equations. The recursion begins with aT(0) meaning that you are not going to go backwards any points in time. So that is precisely the mean is going to be whatever you computed with the filtering equations of up to T, that’s mT. And then RT(0) is going to be CT. So just to again illustrate how this would work in the example, if we start here right? If we condition, so the first step would be to compute again to initialize using the distribution of θ3 given D3. And that is a normal with mean a3(0) and variance covariance matrix R3(0), But those are precisely m3 and C3 respectively. Then we go backwards one step. And if we want to look at what is the distribution of θ2, now conditional on D3. That’s a normal with mean a3(-1) and variance covariance matrix R3(-1). So if you look at the equations down here, you will see that, in order to compute a3 (-1), and R3(-1). You’re going to need m2,C2, a3,R3 and then what you computed here these moments in the previous step, a3(0) and R3(0). Then you obtain that distribution and you can now look at the distribution of θ1 given D3, that’s the normal a3(-2), R3(-2). And once again, to compute these moments, you’re going to need m1,C1,a2,R2 and then you’re going to need a3(-1),R3(-1). And you can continue all the way down to θ0 given D3 using these recursions. So the smoothing equations allow us to, just compute all these distributions. And the important equations work basically because of the linear and Gaussian structure in the normal dynamic linear model.
In a similar way, we can compute the forecasting distributions. Now we are going to be looking forward, and in the case of forecasting, we are interested in the distribution of θ(t+h) given Dt. And now h is a positive lag. So here we assume that is h≥0. So we are going to have the recursion is a N(at(h), Rt(h)). The mean is at(h) and we are going to use the structure of the model to obtain these recursions, again. So here we are using the system equation, and the moment at(h) depends on what you computed at at(h-1) the previous lag, times Gt+h. And then, would you initialize the recursion with at(0)=mt.
Similarly, for the covariance matrix h steps ahead, you’re going to have a recursion that depends on Rt(h-1). And then you’re going to need to input also Gt+h and Wt+h. To initialize, the recursion with Rt(0)= Ct. So you can see that in order to compute these moments, you’re going to need mt and Ct to start with. And then you’re also going to have to input all the G’s and the W’s for the number of steps ahead that you require.
Similarly, you can compute the distribution, the h steps ahead distribution of yt+h given Dt. And that one also follows a normal, with mean ft(h), qt(h). And now we also have a recursion here, ft(h) depends on at(h) and as we said, at(h) depends on at(h-1) and so on. And qt(h) is just given by these equations. So once again, you have to have access to Ft+h for all the h, a number of steps ahead that you are trying to compute this distribution. And then you also have to provide the observational variance for every h value. So that you get vt+h. So this is specified in the modeling framework as well. If you want proceed with the forecasting distributions.
Consider the NDLM given by:
y_t = F_t' \theta_t + \nu_t, \quad \nu_t \sim N(0, v_t), \tag{1}
\theta_t = G_t \theta_{t-1} + \omega_t, \quad \omega_t \sim N(0, W_t), \tag{2}
with F_t, G_t, v_t, and W_t known. We also assume a prior distribution of the form (\theta_0 \mid D_0) \sim N(m_0, C_0), with m_0 and C_0 known.
For t < T, we have that:
(\theta_t \mid D_T) \sim N(a_T(t - T), R_T(t - T)),
where
a_T(t - T) = m_t - B_t [a_{t+1} - a_T(t - T + 1)],
R_T(t - T) = C_t - B_t [R_{t+1} - R_T(t - T + 1)] B_t',
for t = (T - 1), (T - 2), \dots, 0, with B_t = C_t G_t' R_{t+1}^{-1}, and a_T(0) = m_T, R_T(0) = C_T. Here a_t, m_t, R_t, and C_t are obtained using the filtering equations as explained before.
For h \geq 0, it is possible to show that:
(\theta_{t+h} \mid D_t) \sim N(a_t(h), R_t(h)),
(y_{t+h} \mid D_t) \sim N(f_t(h), q_t(h)),
with
a_t(h) = G_{t+h} a_t(h - 1),
R_t(h) = G_{t+h} R_t(h - 1) G_{t+h}' + W_{t+h},
f_t(h) = F_{t+h}' a_t(h),
q_t(h) = F_{t+h}' R_t(h) F_{t+h} + v_{t+h},
and
a_t(0) = m_t, \quad R_t(0) = C_t.
#################################################
##### Univariate DLM: Known, constant variances
#################################################
set_up_dlm_matrices <- function(FF, GG, VV, WW){
return(list(FF=FF, GG=GG, VV=VV, WW=WW))
}
set_up_initial_states <- function(m0, C0){
return(list(m0=m0, C0=C0))
}
### forward update equations ###
forward_filter <- function(data, matrices, initial_states){
## retrieve dataset
yt <- data$yt
T <- length(yt)
## retrieve a set of quadruples
# FF, GG, VV, WW are scalar
FF <- matrices$FF
GG <- matrices$GG
VV <- matrices$VV
WW <- matrices$WW
## retrieve initial states
m0 <- initial_states$m0
C0 <- initial_states$C0
## create placeholder for results
d <- dim(GG)[1]
at <- matrix(NA, nrow=T, ncol=d)
Rt <- array(NA, dim=c(d, d, T))
ft <- numeric(T)
Qt <- numeric(T)
mt <- matrix(NA, nrow=T, ncol=d)
Ct <- array(NA, dim=c(d, d, T))
et <- numeric(T)
for(i in 1:T){
# moments of priors at t
if(i == 1){
at[i, ] <- GG %*% t(m0)
Rt[, , i] <- GG %*% C0 %*% t(GG) + WW
Rt[,,i] <- 0.5*Rt[,,i]+0.5*t(Rt[,,i])
}else{
at[i, ] <- GG %*% t(mt[i-1, , drop=FALSE])
Rt[, , i] <- GG %*% Ct[, , i-1] %*% t(GG) + WW
Rt[,,i] <- 0.5*Rt[,,i]+0.5*t(Rt[,,i])
}
# moments of one-step forecast:
ft[i] <- t(FF) %*% (at[i, ])
Qt[i] <- t(FF) %*% Rt[, , i] %*% FF + VV
# moments of posterior at t:
At <- Rt[, , i] %*% FF / Qt[i]
et[i] <- yt[i] - ft[i]
mt[i, ] <- at[i, ] + t(At) * et[i]
Ct[, , i] <- Rt[, , i] - Qt[i] * At %*% t(At)
Ct[,,i] <- 0.5*Ct[,,i] + 0.5*t(Ct[,,i])
}
cat("Forward filtering is completed!") # indicator of completion
return(list(mt = mt, Ct = Ct, at = at, Rt = Rt,
ft = ft, Qt = Qt))
}
forecast_function <- function(posterior_states, k, matrices){
## retrieve matrices
FF <- matrices$FF
GG <- matrices$GG
WW <- matrices$WW
VV <- matrices$VV
mt <- posterior_states$mt
Ct <- posterior_states$Ct
## set up matrices
T <- dim(mt)[1] # time points
d <- dim(mt)[2] # dimension of state parameter vector
## placeholder for results
at <- matrix(NA, nrow = k, ncol = d)
Rt <- array(NA, dim=c(d, d, k))
ft <- numeric(k)
Qt <- numeric(k)
for(i in 1:k){
## moments of state distribution
if(i == 1){
at[i, ] <- GG %*% t(mt[T, , drop=FALSE])
Rt[, , i] <- GG %*% Ct[, , T] %*% t(GG) + WW
Rt[,,i] <- 0.5*Rt[,,i]+0.5*t(Rt[,,i])
}else{
at[i, ] <- GG %*% t(at[i-1, , drop=FALSE])
Rt[, , i] <- GG %*% Rt[, , i-1] %*% t(GG) + WW
Rt[,,i] <- 0.5*Rt[,,i]+0.5*t(Rt[,,i])
}
## moments of forecast distribution
ft[i] <- t(FF) %*% t(at[i, , drop=FALSE])
Qt[i] <- t(FF) %*% Rt[, , i] %*% FF + VV
}
cat("Forecasting is completed!") # indicator of completion
return(list(at=at, Rt=Rt, ft=ft, Qt=Qt))
}
## obtain 95% credible interval
get_credible_interval <- function(mu, sigma2,
quantile = c(0.025, 0.975)){
z_quantile <- qnorm(quantile)
bound <- matrix(0, nrow=length(mu), ncol=2)
bound[, 1] <- mu + z_quantile[1]*sqrt(as.numeric(sigma2)) # lower bound
bound[, 2] <- mu + z_quantile[2]*sqrt(as.numeric(sigma2)) # upper bound
return(bound)
}
### smoothing equations ###
backward_smoothing <- function(data, matrices,
posterior_states){
## retrieve data
yt <- data$yt
T <- length(yt)
## retrieve matrices
FF <- matrices$FF
GG <- matrices$GG
## retrieve matrices
mt <- posterior_states$mt
Ct <- posterior_states$Ct
at <- posterior_states$at
Rt <- posterior_states$Rt
## create placeholder for posterior moments
mnt <- matrix(NA, nrow = dim(mt)[1], ncol = dim(mt)[2])
Cnt <- array(NA, dim = dim(Ct))
fnt <- numeric(T)
Qnt <- numeric(T)
for(i in T:1){
# moments for the distributions of the state vector given D_T
if(i == T){
mnt[i, ] <- mt[i, ]
Cnt[, , i] <- Ct[, , i]
Cnt[, , i] <- 0.5*Cnt[, , i] + 0.5*t(Cnt[, , i])
}else{
inv_Rtp1<-solve(Rt[,,i+1])
Bt <- Ct[, , i] %*% t(GG) %*% inv_Rtp1
mnt[i, ] <- mt[i, ] + Bt %*% (mnt[i+1, ] - at[i+1, ])
Cnt[, , i] <- Ct[, , i] + Bt %*% (Cnt[, , i + 1] - Rt[, , i+1]) %*% t(Bt)
Cnt[,,i] <- 0.5*Cnt[,,i] + 0.5*t(Cnt[,,i])
}
# moments for the smoothed distribution of the mean response of the series
fnt[i] <- t(FF) %*% t(mnt[i, , drop=FALSE])
Qnt[i] <- t(FF) %*% t(Cnt[, , i]) %*% FF
}
cat("Backward smoothing is completed!")
return(list(mnt = mnt, Cnt = Cnt, fnt=fnt, Qnt=Qnt))
}
####################### Example: Lake Huron Data ######################
plot(LakeHuron,main="Lake Huron Data",ylab="level in feet") 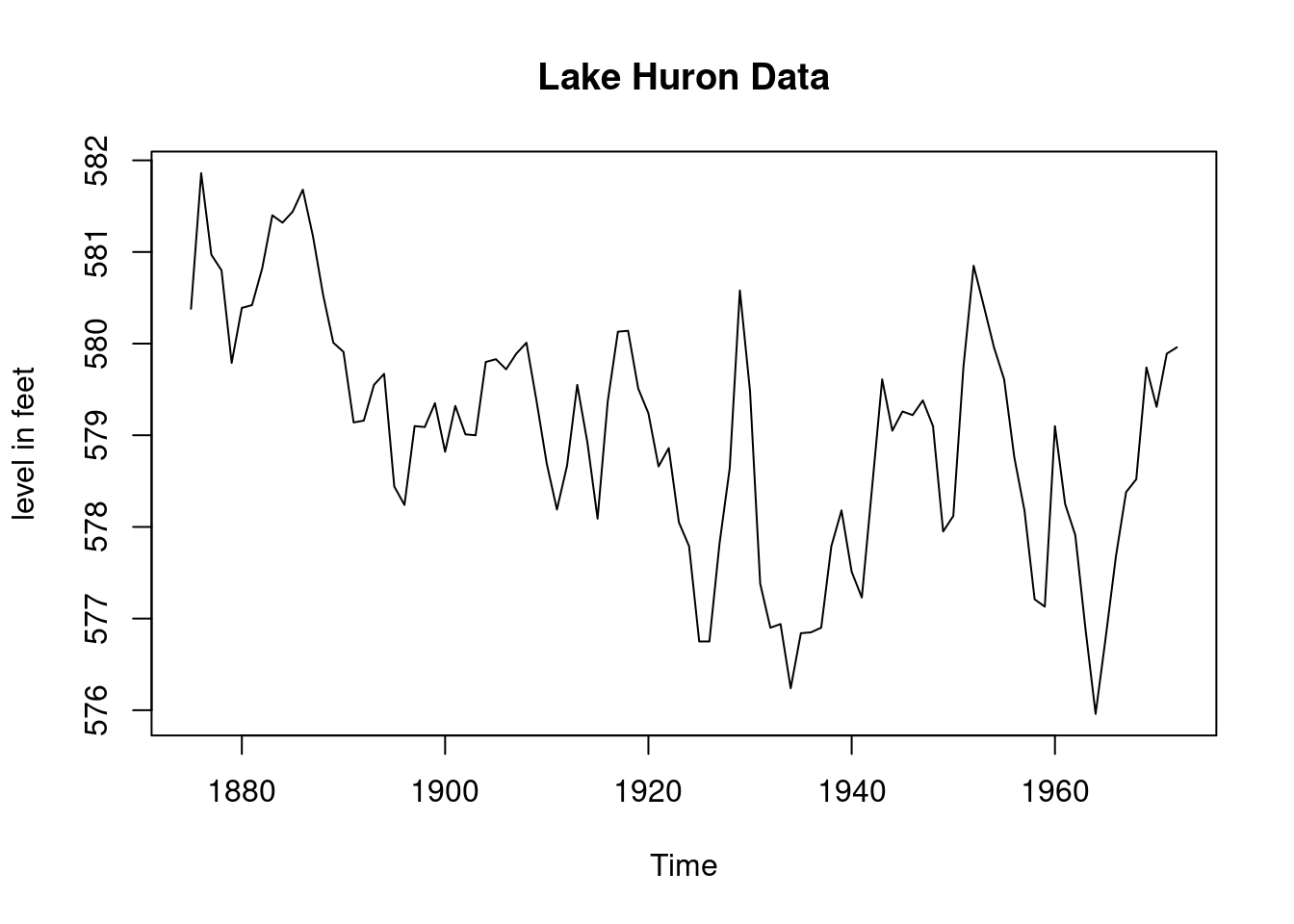
# 98 observations total
k=4
T=length(LakeHuron)-k # We take the first 94 observations
# as our data
ts_data=LakeHuron[1:T]
ts_validation_data <- LakeHuron[(T+1):98]
data <- list(yt = ts_data)
## set up matrices
FF <- as.matrix(1)
GG <- as.matrix(1)
VV <- as.matrix(1)
WW <- as.matrix(1)
m0 <- as.matrix(570)
C0 <- as.matrix(1e4)
## wrap up all matrices and initial values
matrices <- set_up_dlm_matrices(FF,GG,VV,WW)
initial_states <- set_up_initial_states(m0, C0)
## filtering
results_filtered <- forward_filter(data, matrices,
initial_states)Forward filtering is completed!ci_filtered<-get_credible_interval(results_filtered$mt,
results_filtered$Ct)
## smoothing
results_smoothed <- backward_smoothing(data, matrices,
results_filtered)Backward smoothing is completed!ci_smoothed <- get_credible_interval(results_smoothed$mnt,
results_smoothed$Cnt)
index=seq(1875, 1972, length.out = length(LakeHuron))
index_filt=index[1:T]
plot(index, LakeHuron, main = "Lake Huron Level ",type='l',
xlab="time",ylab="level in feet",lty=3,ylim=c(575,583))
points(index,LakeHuron,pch=20)
lines(index_filt, results_filtered$mt, type='l',
col='red',lwd=2)
lines(index_filt, ci_filtered[,1], type='l', col='red',lty=2)
lines(index_filt, ci_filtered[,2], type='l', col='red',lty=2)
lines(index_filt, results_smoothed$mnt, type='l',
col='blue',lwd=2)
lines(index_filt, ci_smoothed[,1], type='l', col='blue',lty=2)
lines(index_filt, ci_smoothed[,2], type='l', col='blue',lty=2)
legend('bottomleft', legend=c("filtered","smoothed"),
col = c("red", "blue"), lty=c(1, 1))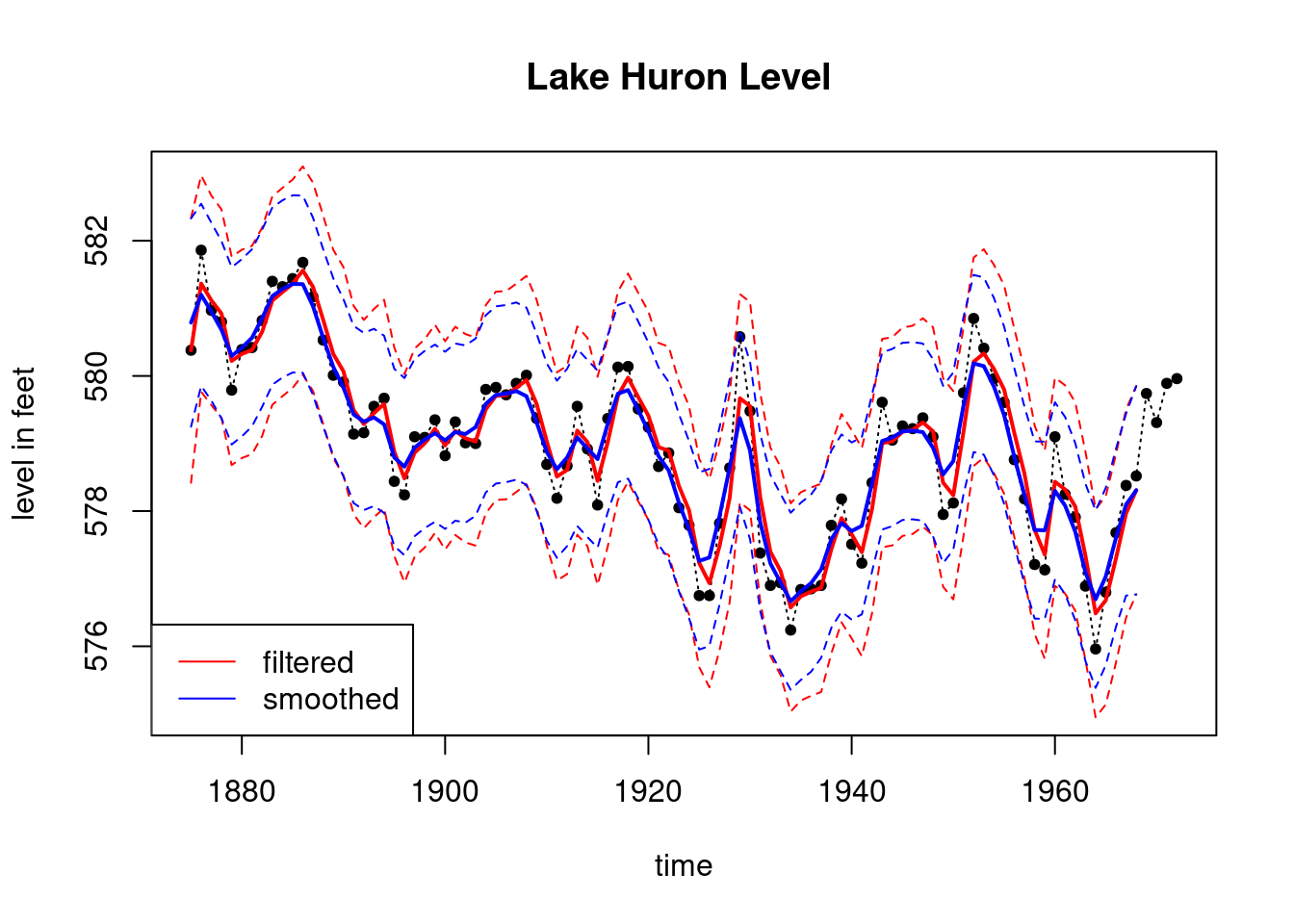
In this video walk through the code provided in the section below the comment
Similarly, for the second order polynomial and the co2 data:
The dlm package in R is a powerful tool for working with dynamic linear models. The package provides a wide range of functions for filtering, smoothing, forecasting, and parameter estimation in DLMs. In this video, we walk through the code provided in the section below.
Since the code below is too long, I will try and split it into smaller bits later. TODO
dlm package in R (Reading)#################################################
##### Univariate DLM: Known, constant variances
#################################################
set_up_dlm_matrices <- function(FF, GG, VV, WW){
return(list(FF=FF, GG=GG, VV=VV, WW=WW))
}
set_up_initial_states <- function(m0, C0){
return(list(m0=m0, C0=C0))
}
### forward update equations ###
forward_filter <- function(data, matrices, initial_states){
## retrieve dataset
yt <- data$yt
T <- length(yt)
## retrieve a set of quadruples
# FF, GG, VV, WW are scalar
FF <- matrices$FF
GG <- matrices$GG
VV <- matrices$VV
WW <- matrices$WW
## retrieve initial states
m0 <- initial_states$m0
C0 <- initial_states$C0
## create placeholder for results
d <- dim(GG)[1]
at <- matrix(NA, nrow=T, ncol=d)
Rt <- array(NA, dim=c(d, d, T))
ft <- numeric(T)
Qt <- numeric(T)
mt <- matrix(NA, nrow=T, ncol=d)
Ct <- array(NA, dim=c(d, d, T))
et <- numeric(T)
for(i in 1:T){
# moments of priors at t
if(i == 1){
at[i, ] <- GG %*% t(m0)
Rt[, , i] <- GG %*% C0 %*% t(GG) + WW
Rt[,,i] <- 0.5*Rt[,,i]+0.5*t(Rt[,,i])
}else{
at[i, ] <- GG %*% t(mt[i-1, , drop=FALSE])
Rt[, , i] <- GG %*% Ct[, , i-1] %*% t(GG) + WW
Rt[,,i] <- 0.5*Rt[,,i]+0.5*t(Rt[,,i])
}
# moments of one-step forecast:
ft[i] <- t(FF) %*% (at[i, ])
Qt[i] <- t(FF) %*% Rt[, , i] %*% FF + VV
# moments of posterior at t:
At <- Rt[, , i] %*% FF / Qt[i]
et[i] <- yt[i] - ft[i]
mt[i, ] <- at[i, ] + t(At) * et[i]
Ct[, , i] <- Rt[, , i] - Qt[i] * At %*% t(At)
Ct[,,i] <- 0.5*Ct[,,i] + 0.5*t(Ct[,,i])
}
cat("Forward filtering is completed!") # indicator of completion
return(list(mt = mt, Ct = Ct, at = at, Rt = Rt,
ft = ft, Qt = Qt))
}
forecast_function <- function(posterior_states, k, matrices){
## retrieve matrices
FF <- matrices$FF
GG <- matrices$GG
WW <- matrices$WW
VV <- matrices$VV
mt <- posterior_states$mt
Ct <- posterior_states$Ct
## set up matrices
T <- dim(mt)[1] # time points
d <- dim(mt)[2] # dimension of state parameter vector
## placeholder for results
at <- matrix(NA, nrow = k, ncol = d)
Rt <- array(NA, dim=c(d, d, k))
ft <- numeric(k)
Qt <- numeric(k)
for(i in 1:k){
## moments of state distribution
if(i == 1){
at[i, ] <- GG %*% t(mt[T, , drop=FALSE])
Rt[, , i] <- GG %*% Ct[, , T] %*% t(GG) + WW
Rt[,,i] <- 0.5*Rt[,,i]+0.5*t(Rt[,,i])
}else{
at[i, ] <- GG %*% t(at[i-1, , drop=FALSE])
Rt[, , i] <- GG %*% Rt[, , i-1] %*% t(GG) + WW
Rt[,,i] <- 0.5*Rt[,,i]+0.5*t(Rt[,,i])
}
## moments of forecast distribution
ft[i] <- t(FF) %*% t(at[i, , drop=FALSE])
Qt[i] <- t(FF) %*% Rt[, , i] %*% FF + VV
}
cat("Forecasting is completed!") # indicator of completion
return(list(at=at, Rt=Rt, ft=ft, Qt=Qt))
}
## obtain 95% credible interval
get_credible_interval <- function(mu, sigma2,
quantile = c(0.025, 0.975)){
z_quantile <- qnorm(quantile)
bound <- matrix(0, nrow=length(mu), ncol=2)
bound[, 1] <- mu + z_quantile[1]*sqrt(as.numeric(sigma2)) # lower bound
bound[, 2] <- mu + z_quantile[2]*sqrt(as.numeric(sigma2)) # upper bound
return(bound)
}
### smoothing equations ###
backward_smoothing <- function(data, matrices,
posterior_states){
## retrieve data
yt <- data$yt
T <- length(yt)
## retrieve matrices
FF <- matrices$FF
GG <- matrices$GG
## retrieve matrices
mt <- posterior_states$mt
Ct <- posterior_states$Ct
at <- posterior_states$at
Rt <- posterior_states$Rt
## create placeholder for posterior moments
mnt <- matrix(NA, nrow = dim(mt)[1], ncol = dim(mt)[2])
Cnt <- array(NA, dim = dim(Ct))
fnt <- numeric(T)
Qnt <- numeric(T)
for(i in T:1){
# moments for the distributions of the state vector given D_T
if(i == T){
mnt[i, ] <- mt[i, ]
Cnt[, , i] <- Ct[, , i]
Cnt[, , i] <- 0.5*Cnt[, , i] + 0.5*t(Cnt[, , i])
}else{
inv_Rtp1<-solve(Rt[,,i+1])
Bt <- Ct[, , i] %*% t(GG) %*% inv_Rtp1
mnt[i, ] <- mt[i, ] + Bt %*% (mnt[i+1, ] - at[i+1, ])
Cnt[, , i] <- Ct[, , i] + Bt %*% (Cnt[, , i + 1] - Rt[, , i+1]) %*% t(Bt)
Cnt[,,i] <- 0.5*Cnt[,,i] + 0.5*t(Cnt[,,i])
}
# moments for the smoothed distribution of the mean response of the series
fnt[i] <- t(FF) %*% t(mnt[i, , drop=FALSE])
Qnt[i] <- t(FF) %*% t(Cnt[, , i]) %*% FF
}
cat("Backward smoothing is completed!")
return(list(mnt = mnt, Cnt = Cnt, fnt=fnt, Qnt=Qnt))
}
####################### Example: Lake Huron Data ######################
plot(LakeHuron) # 98 observations total 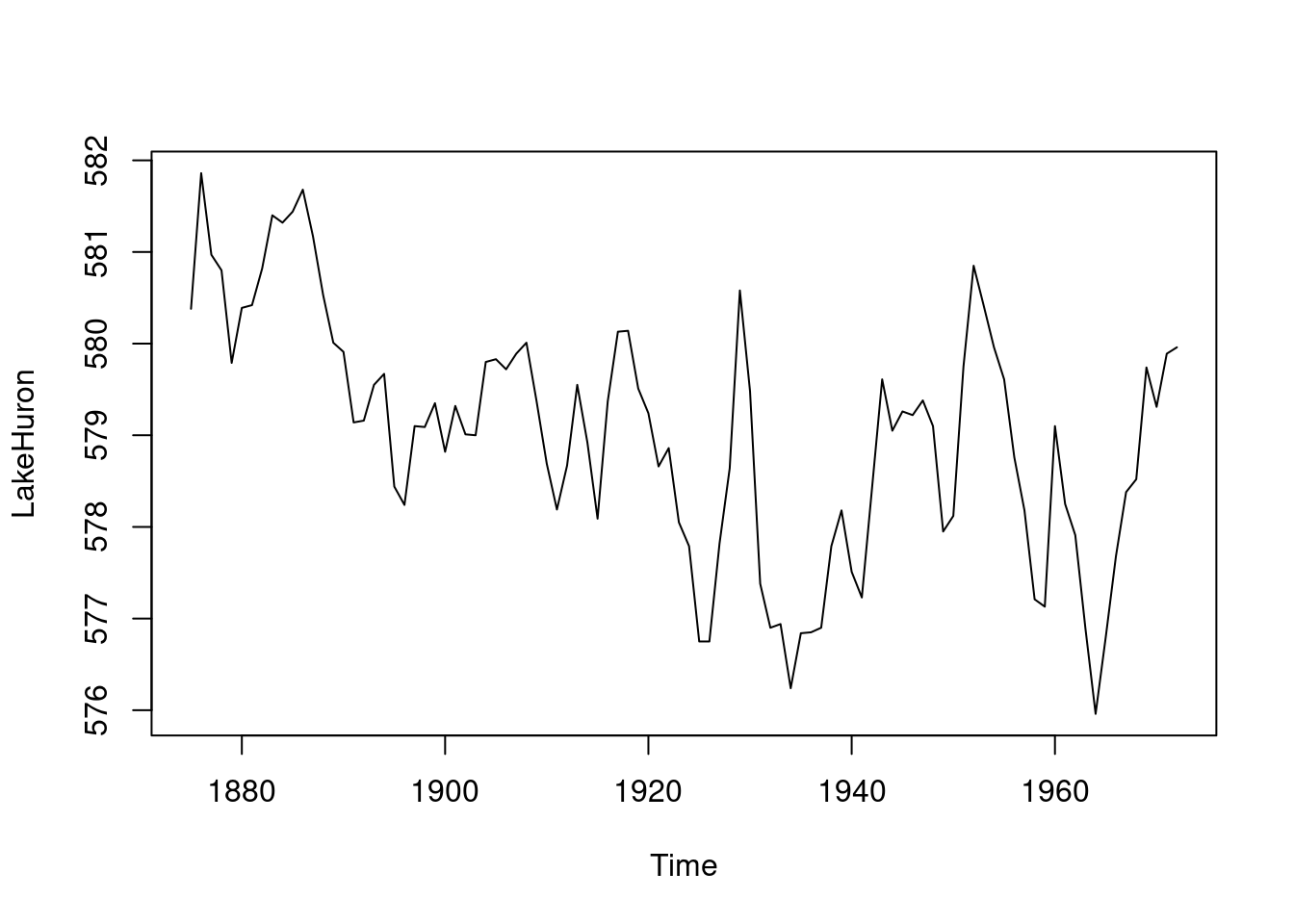
k=4
T=length(LakeHuron)-k # We take the first
# 94 observations only as our data
ts_data=LakeHuron[1:T]
ts_validation_data <- LakeHuron[(T+1):98]
data <- list(yt = ts_data)
## set up dlm matrices
GG <- as.matrix(1)
FF <- as.matrix(1)
VV <- as.matrix(1)
WW <- as.matrix(1)
m0 <- as.matrix(570)
C0 <- as.matrix(1e4)
## wrap up all matrices and initial values
matrices <- set_up_dlm_matrices(FF, GG, VV, WW)
initial_states <- set_up_initial_states(m0, C0)
## filtering and smoothing
results_filtered <- forward_filter(data, matrices,
initial_states)Forward filtering is completed!results_smoothed <- backward_smoothing(data, matrices,
results_filtered)Backward smoothing is completed!index=seq(1875, 1972, length.out = length(LakeHuron))
index_filt=index[1:T]
par(mfrow=c(2,1))
plot(index, LakeHuron, main = "Lake Huron Level ",type='l',
xlab="time",ylab="feet",lty=3,ylim=c(575,583))
points(index,LakeHuron,pch=20)
lines(index_filt, results_filtered$mt, type='l',
col='red',lwd=2)
lines(index_filt, results_smoothed$mnt, type='l',
col='blue',lwd=2)
# Now let's look at the DLM package
library(dlm)
model=dlmModPoly(order=1,dV=1,dW=1,m0=570,C0=1e4)
results_filtered_dlm=dlmFilter(LakeHuron[1:T],model)
results_smoothed_dlm=dlmSmooth(results_filtered_dlm)
plot(index_filt, LakeHuron[1:T], ylab = "level",
main = "Lake Huron Level",
type='l', xlab="time",lty=3,ylim=c(575,583))
points(index_filt,LakeHuron[1:T],pch=20)
lines(index_filt,results_filtered_dlm$m[-1],col='red',lwd=2)
lines(index_filt,results_smoothed_dlm$s[-1],col='blue',lwd=2)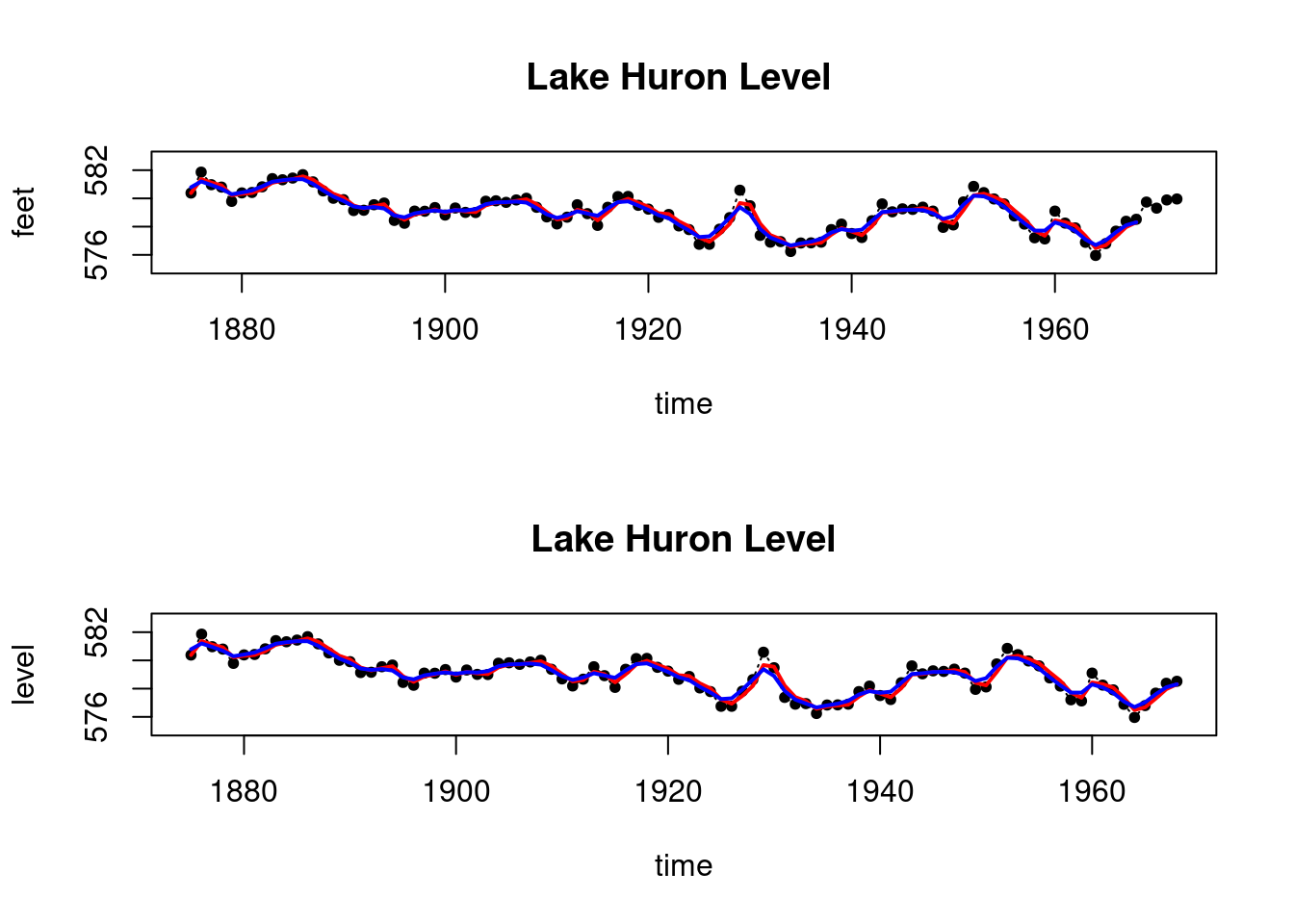
# Similarly, for the second order polynomial and the co2 data:
T=length(co2)
data=list(yt = co2)
FF <- (as.matrix(c(1,0)))
GG <- matrix(c(1,1,0,1),ncol=2,byrow=T)
VV <- as.matrix(200)
WW <- 0.01*diag(2)
m0 <- t(as.matrix(c(320,0)))
C0 <- 10*diag(2)
## wrap up all matrices and initial values
matrices <- set_up_dlm_matrices(FF,GG, VV, WW)
initial_states <- set_up_initial_states(m0, C0)
## filtering and smoothing
results_filtered <- forward_filter(data, matrices,
initial_states)Forward filtering is completed!results_smoothed <- backward_smoothing(data, matrices,
results_filtered)Backward smoothing is completed!#### Now, using the DLM package:
model=dlmModPoly(order=2,dV=200,dW=0.01*rep(1,2),
m0=c(320,0),C0=10*diag(2))
# filtering and smoothing
results_filtered_dlm=dlmFilter(data$yt,model)
results_smoothed_dlm=dlmSmooth(results_filtered_dlm)
par(mfrow=c(2,1))
plot(as.vector(time(co2)),co2,type='l',xlab="time",
ylim=c(300,380))
lines(as.vector(time(co2)),results_filtered$mt[,1],
col='red',lwd=2)
lines(as.vector(time(co2)),results_smoothed$mnt[,1],
col='blue',lwd=2)
plot(as.vector(time(co2)),co2,type='l',xlab="time",
ylim=c(300,380))
lines(as.vector(time(co2)),results_filtered_dlm$m[-1,1],
col='red',lwd=2)
lines(as.vector(time(co2)),results_smoothed_dlm$s[-1,1],
col='blue',lwd=2)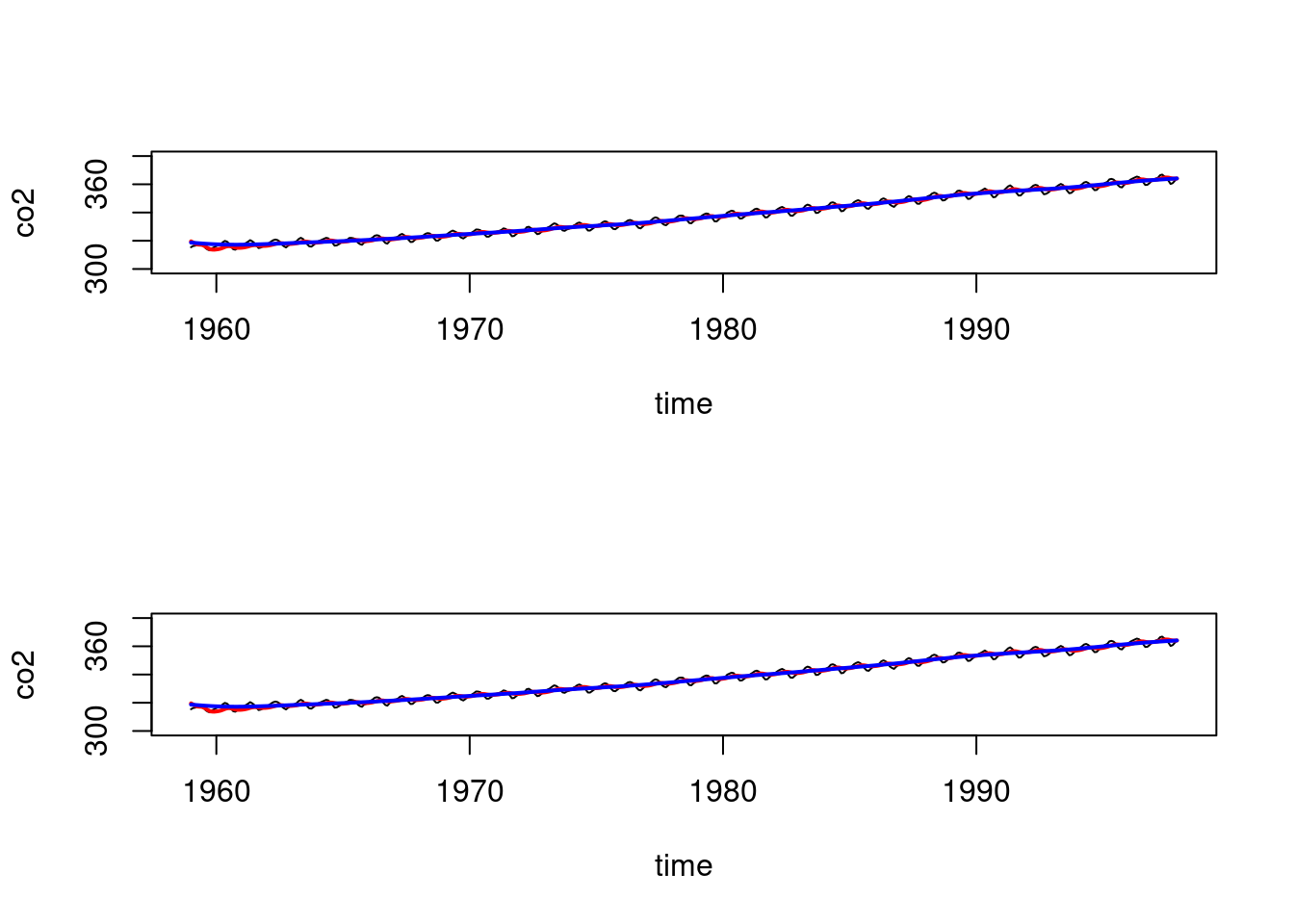
This is a peer reviewed assignment. I may drop in the instructions but the solution will not be provided here due to the Coursera honor code.
This peer-reviewed activity is highly recommended. It does not figure into your grade for this course, but it does provide you with the opportunity to apply what you’ve learned in R and prepare you for your data analysis project in week 5.
Consider the following R code:
#######################
##### DLM package #####
#######################
library(dlm)
k=4
T=length(LakeHuron)-k # We take the first
# 94 observations only as our data
index=seq(1875, 1972, length.out = length(LakeHuron))
index_filt=index[1:T]
model=dlmModPoly(order=1,dV=1,dW=1,m0=570,C0=1e4)
results_filtered_dlm=dlmFilter(LakeHuron[1:T],model)
results_smoothed_dlm=dlmSmooth(results_filtered_dlm)
plot(index_filt, LakeHuron[1:T], ylab = "level",
main = "Lake Huron Level",
type='l', xlab="time",lty=3,ylim=c(575,583))
points(index_filt,LakeHuron[1:T],pch=20)
lines(index_filt,results_filtered_dlm$m[-1],col='red',lwd=2)
lines(index_filt,results_smoothed_dlm$s[-1],col='blue',lwd=2)
legend(1880,577, legend=c("filtered", "smoothed"),
col=c("red", "blue"), lty=1, cex=0.8)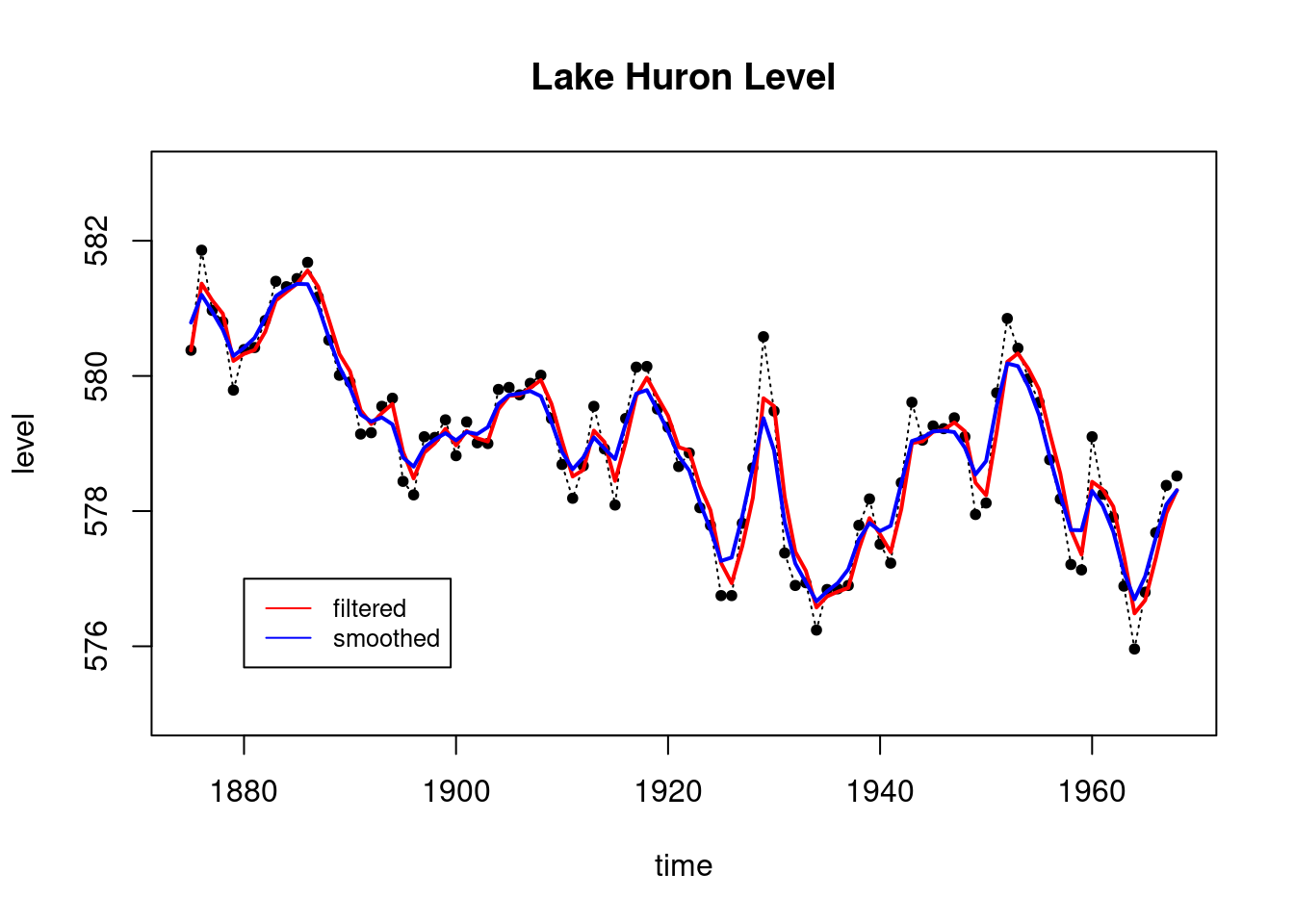
Note that you will need to install the dlm package in R if you don’t have it installed in order to run the code above. After installing the package and running the code above you will be asked to change some of the model specifications, upload some graphs and and answer some questions. In particular, you will be asked to:
Modify the above code to change the variance of the prior distribution from C_0=10^4 to C_0=10 and plot and upload the traces of E(\theta_t \mid \matchcal D_T) (mean of the filtered distribution) and E(\theta_t \mid \matchcal D_T) for T\geq t and all t=1:T (mean of the smoothed distribution). Are these new results different from the results with the model with C_0=10^4?
Keep the variance of the prior distribution at C_0=10^4. Now change the evolution variance from W=1 to W=0.01 . Plot and upload the new means of the filtered and smoothed results. Are they different from the results when evolution variance is W=1 ?
Peer reviewers will be asked to check whether
To receive full credit for this assignment you will have to grade the assignments of 2 students taking the course.
This is omitted due to the Coursera honor code.
the state makes it’s appearance↩︎
@online{bochman2024,
author = {Bochman, Oren},
title = {Week 3: {Normal} {Dynamic} {Linear} {Models,} {Part} 1},
date = {2024-10-25},
url = {https://orenbochman.github.io/notes/bayesian-ts/module3.html},
langid = {en}
}