In the first week of the fourth course of Coursera’s ‘Bayesian Statistics Specialization’ we will define the AR(1) process, Stationarity, ACF, PACF, differencing, smoothing
coursera
notes
bayesian statistics
autoregressive models
time series
Author
Oren Bochman
Published
Wednesday, October 23, 2024
Keywords
time series, stationarity, strong stationarity, weak stationarity, autocorrelation function (ACF), partial autocorrelation function (PACF), smoothing, trend, seasonality, Durbin-Levinson recursion, Yule-Walker equations, differencing operator, back shift operator, moving average, AR(1) process, R code
Week 1: Introduction to Time Series and the AR(1) process
A time series is said to be stationary if its statistical properties such as mean, variance, and auto-correlation do not change over time.
We make this definition more formal in the definitions of strong and weak stationarity below.
Stationarity
Stationarity is a key concept in time series analysis. A time series is said to be stationary if its statistical properties such as mean, variance, and auto-correlation do not change over time.
Let y_t be a time series. We say that y_t is stationary if the following conditions hold:
Strong Stationarity
Strong Stationarity
Let \{y_t\} \quad \forall n>0 be a time series and h > 0 be a lag. If for any subsequence the distribution of y_t, y_{t+1}, \ldots, y_{t+n} is the same as the distribution of y_{t+h}, y_{t+h+1}, \ldots, y_{t+h+n} we call the series strongly stationary.
Since it is difficult to verify strong stationarity in practice, we will often use the following weaker notion of stationarity.
Weak Stationarity AKA Second-order Stationarity
Weak Stationarity
the mean, variance, and auto-covariance are constant over time.
E(y_t) = \mu \quad \forall t
Var(y_t) = \nu =\sigma^2 \quad \forall t
Cov(y_t , y_s ) = γ(t − s)
Strong stationarity \implies Weak stationarity, but
The converse is not true.
In this course when we deal with a Gaussian process, our typical use case, they are equivalent!
Check your understanding
Q. Can you explain with an example when a time series is weakly stationary but not strongly stationarity.
The auto-correlation function ACF (video)
slide 1
The autocorrelation is simply how correlated a time series is with itself at different lags. Correlation in general is defined in terms of covariance of two variables. The covariance is a measure of the joint variability of two random variables.
Important
Recall that the covariance between two random variables y_t and y_s is defined as:
we get the second line by substituting \mu_t = \mathbb{E}(y_t) and \mu_s = \mathbb{E}(y_s) using the definition of the mean of a RV. the third line is by multiplying out and using the linearity of the expectation operator.
We will frequently use the notation \gamma(h) to denote the autocovariance for a lag h i.e. between y_t and y_{t+h}
\gamma(h) = Cov(y_t, y_s) \qquad
\tag{2}
If the time series is stationary, then the covariance only depends on the lag h = |t-s| and we can write the covariance as \gamma(h).
Let \{y_t\} be a time series. Recall that the covariance between two random variables y_t and y_s is defined as:
be the best linear predictor of y_t based on the previous h − 1 values \{y_{t−1}, \ldots , y_{t−h+1}\}. The best linear predictor of y_t based on the previous h − 1 values of the process is the linear predictor that minimizes
E[(y_t − \hat{y}_y^{h-1})^2]
The partial autocorrelation of this process at lag h, denoted by \phi(h, h) is defined as:
Note that the sample PACF can be obtained by substituting the sample autocorrelations and the sample auto-covariances in the Durbin-Levinson recursion.
Differencing and smoothing (Reading)
Differencing and smoothing are covered in the (Prado, Ferreira, and West 2023, sec. 1.4) and are techniques used to remove trends and seasonality in time series data.
Many time series models are built under the assumption of stationarity. However, time series data often present non-stationary features such as trends or seasonality. Practitioners may consider techniques for detrending, deseasonalizing and smoothing that can be applied to the observed data to obtain a new time series that is consistent with the stationarity assumption.
We briefly discuss two methods that are commonly used in practice for detrending and smoothing.
Differencing
The first method is differencing, which is generally used to remove trends in time series data. The first difference of a time series is defined in terms of the so called difference operator denoted as D, that produces the transformation
differencing operator
Dy_t = y_t - y_{t-1}.
Higher order differences are obtained by successively applying the operator D. For example,
Differencing can also be written in terms of the so called backshift operator B, with
backshift operator
By_t = y_{t-1},
so that
Dy_t = (1 - B) y_t
and
D^dy_t = (1 - B) d y_t.
Smoothing
The second method we discuss is moving averages, which is commonly used to “smooth” a time series by removing certain features (e.g., seasonality) to highlight other features (e.g., trends). A moving average is a weighted average of the time series around a particular time t. In general, if we have data y1:T , we could obtain a new time series such that
moving average
z_t = \sum_{j=-q}^{p} w_j y_{t+j} \qquad
\tag{4}
for t = (q + 1) : (T − p), with weights w_j \ge 0 and \sum^p_{j=−q} w_j = 1
We will frequently work with moving averages for which
p = q \qquad \text{(centered)}
and
w_j = w_{−j} \forall j \text{(symmetric)}
Assume we have periodic data with period d. Then, symmetric and centered moving averages can be used to remove such periodicity as follows:
Example: To remove seasonality in monthly data (i.e., seasonality with a period of d = 12 months), one can use a moving average with p = q = 6, a_6 = a_{−6} = 1/24, and a_j = a_{−j} = 1/12 for j = 0, \ldots , 5 , resulting in:
ACF PACF Differencing and Smoothing Examples (Video)
This video walks through the two code snippets bellow and provides examples of how to compute the ACF and PACF of a time series, how to use differencing to remove trends, and how to use moving averages to remove seasonality.
Outline:
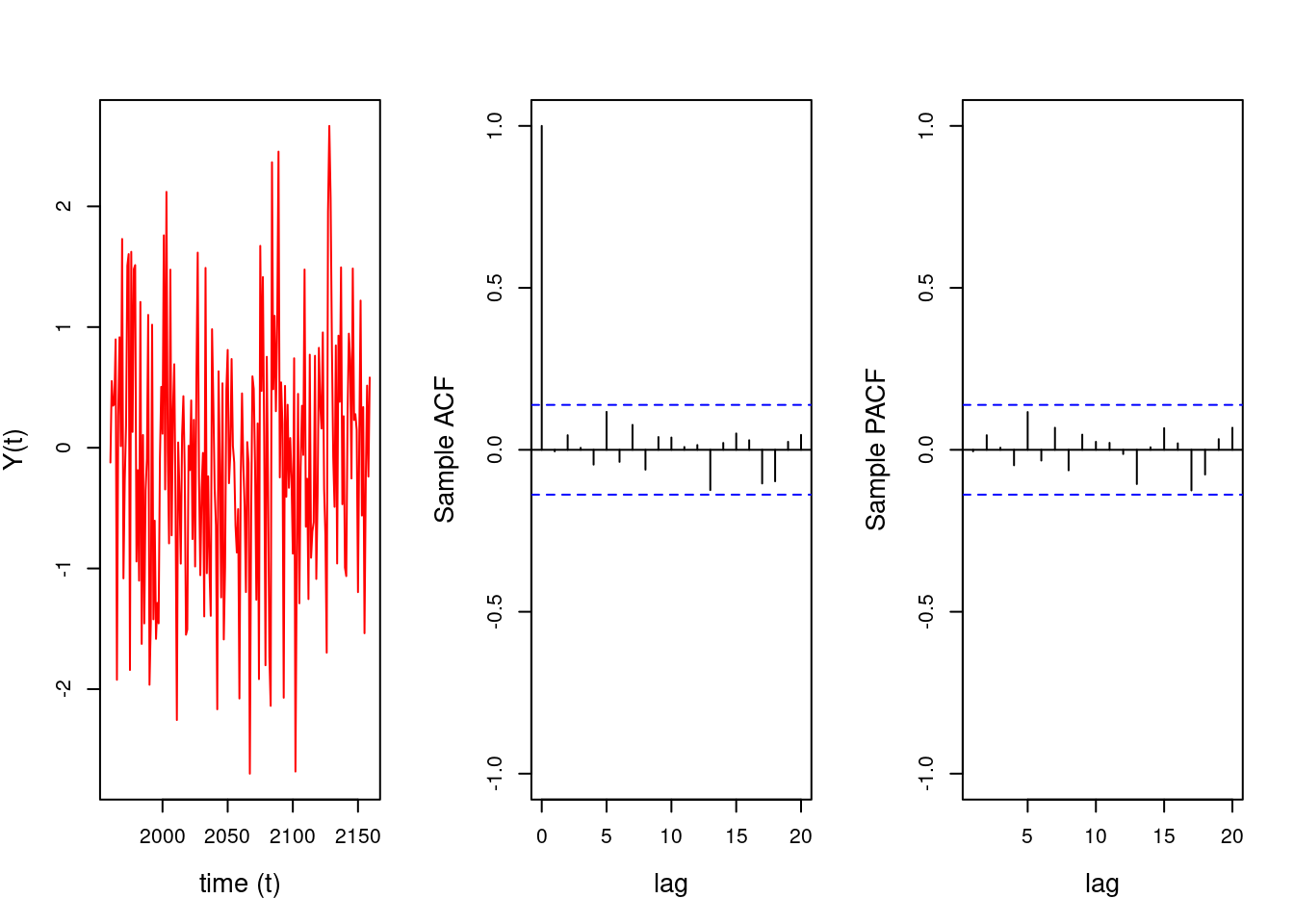
We begin by simulating data using the code in Section 1.3.7
We simulates white noise data using the rnorm(1:2000,mean=0,sd=1) function in R
We plot the white noise data which we can see lacks a temporal structure.
We plot the ACF using the acf function in R:
we specify the number of lags using the lag.max=20
we shows a confidence interval for the ACF values
We plot the PACF using the pacf function in R
Next we define some time series objects in R using the ts function
we define and plot monthly data starting in January 1960
we define and plot yearly data with one observation per year starting in 1960
we define and plot yearly data with four observations per year starting in 1960
We move on to smoothing and differencing in Section 1.3.6
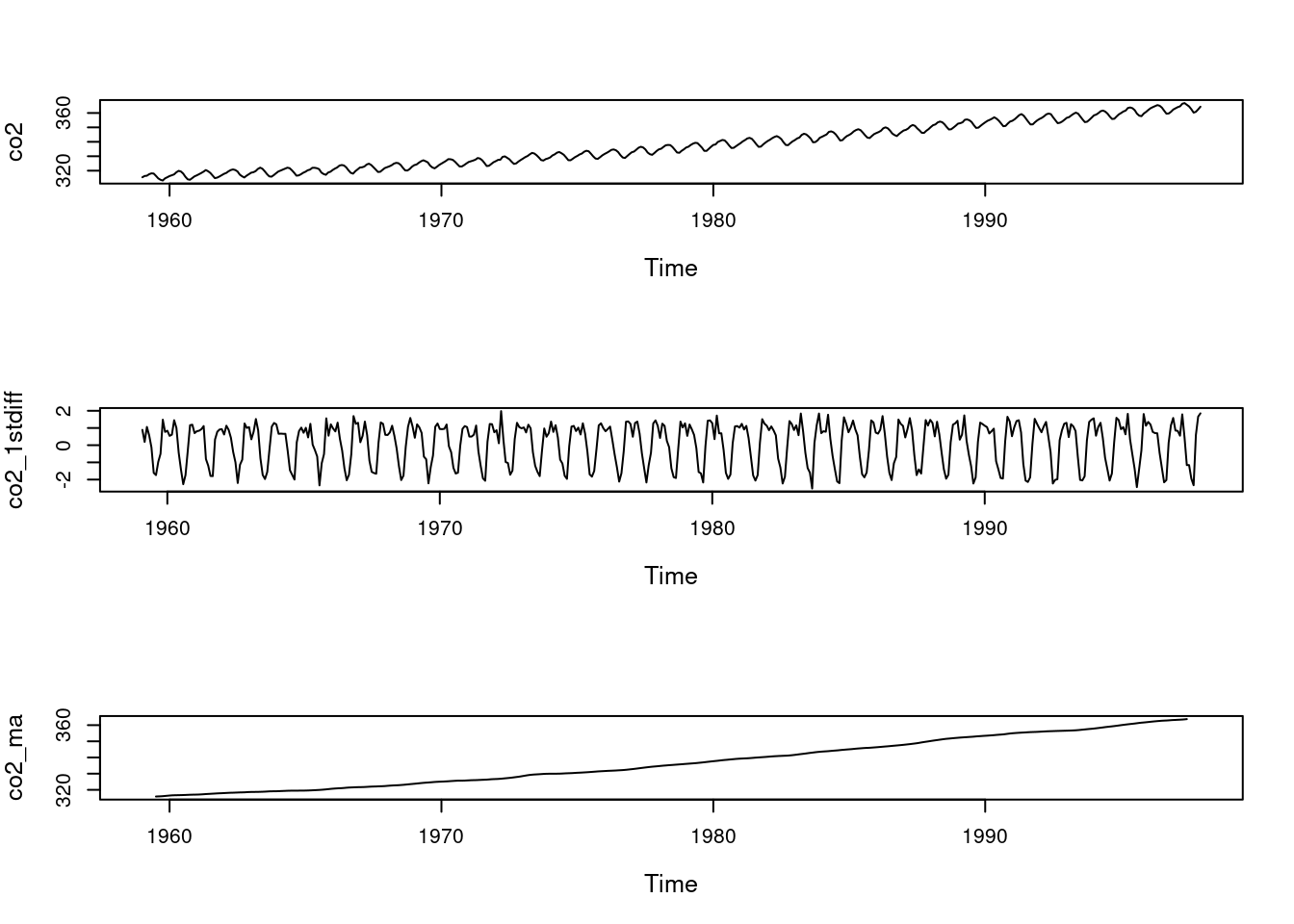
We load the CO2 dataset in R and plot it
we plot the ACF and PACF of the CO2 dataset
we use the filter function in R to remove the seasonal component of the CO2 dataset we plot the resulting time series highlighting the trend.
To remove the trend we use the diff function in R to take the first and second differences of the CO2 dataset
the diff function takes a parameter differences which specifies the number of differences to take
we plot the resulting time series after taking the first and second differences
the ACF and PACF of the resulting time series are plotted, they look different, in that they no longer have the slow decay characteristic of time series with a trend.
The r-code for the examples is provided below.
R code for Differencing and filtering via moving averages (reading)
Code
# Load the CO2 dataset in Rdata(co2) # Take first differences to remove the trend co2_1stdiff=diff(co2,differences=1)# Filter via moving averages to remove the seasonality co2_ma=filter(co2,filter=c(1/24,rep(1/12,11),1/24),sides=2)par(mfrow=c(3,1), cex.lab=1.2,cex.main=1.2)plot(co2) # plot the original data plot(co2_1stdiff) # plot the first differences (removes trend, highlights seasonality)plot(co2_ma) # plot the filtered series via moving averages (removes the seasonality, highlights the trend)
R Code: Simulate data from a white noise process (reading)
Code
## Simulate data with no temporal structure (white noise)#set.seed(2021)T=200t =1:Ty_white_noise=rnorm(T, mean=0, sd=1)## Define a time series object in R: # Assume the data correspond to annual observations starting in January 1960 #yt=ts(y_white_noise, start=c(1960), frequency=1)## plot the simulated time series, their sample ACF and their sample PACF#par(mfrow =c(1, 3), cex.lab =1.3, cex.main =1.3)yt=ts(y_white_noise, start=c(1960), frequency=1)plot(yt, type ='l', col='red', xlab ='time (t)', ylab ="Y(t)")acf(yt, lag.max =20, xlab ="lag",ylab ="Sample ACF",ylim=c(-1,1),main="")pacf(yt, lag.max =20,xlab ="lag",ylab ="Sample PACF",ylim=c(-1,1),main="")
Quiz 1: Stationarity, ACF, PACF, Differencing, and Smoothing
omitted per coursera requirements
The AR(1) process: Definition and properties
We will next introduce the autoregressive process of order one, or AR(1) process, which is a fundamental model in time series analysis. We will discuss the definition of the AR(1) process, its properties, and how to simulate data from an AR(1) process.
The AR(1) process (video)
AR(1)
AR(1) properties
The PACF of the AR(1) process (reading)
It is possible to show that the PACF of an autoregressive process of order one is zero after the first lag. We can use the Durbin-Levinson recursion to show this.
We can prove by induction that in the case of an AR(1), for any lag n,
\phi(n, h) = 0, \phi(n, 1) = \phi and \phi(n, h) = 0 for h \ge 2 and n \ge 2.
Then, the PACF of an AR(1) is zero for any lag above 1 and the PACF coefficient at lag 1 is equal to the AR coefficient \phi
Simulate data from an AR(1) process (video)
This video walks through the code snippet below and provides examples of how to sample data from an AR(1) process and plot the ACF and PACF functions of the resulting time series.
R code: Sample data from AR(1) processes (Reading)
Code
# sample data from 2 ar(1) processes and plot their ACF and PACF functions#set.seed(2021)T=500# number of time points## sample data from an ar(1) with ar coefficient phi = 0.9 and variance 1#v=1.0# innovation variancesd=sqrt(v) #innovation stantard deviationphi1=0.9# ar coefficientyt1=arima.sim(n = T, model =list(ar = phi1), sd = sd)## sample data from an ar(1) with ar coefficient phi = -0.9 and variance 1#phi2=-0.9# ar coefficientyt2=arima.sim(n = T, model =list(ar = phi2), sd = sd)par(mfrow =c(2, 1), cex.lab =1.3)plot(yt1,main=expression(phi==0.9))plot(yt2,main=expression(phi==-0.9))
Code
par(mfrow =c(3, 2), cex.lab =1.3)lag.max=50# max lag### plot true ACFs for both processes#cov_0=sd^2/(1-phi1^2) # compute auto-covariance at h=0cov_h=phi1^(0:lag.max)*cov_0 # compute auto-covariance at hplot(0:lag.max, cov_h/cov_0, pch =1, type ='h', col ='red',ylab ="true ACF", xlab ="Lag",ylim=c(-1,1), main=expression(phi==0.9))cov_0=sd^2/(1-phi2^2) # compute auto-covariance at h=0cov_h=phi2^(0:lag.max)*cov_0 # compute auto-covariance at h# Plot autocorrelation function (ACF)plot(0:lag.max, cov_h/cov_0, pch =1, type ='h', col ='red',ylab ="true ACF", xlab ="Lag",ylim=c(-1,1),main=expression(phi==-0.9))## plot sample ACFs for both processes#acf(yt1, lag.max = lag.max, type ="correlation", ylab ="sample ACF",lty =1, ylim =c(-1, 1), main =" ")acf(yt2, lag.max = lag.max, type ="correlation", ylab ="sample ACF",lty =1, ylim =c(-1, 1), main =" ")## plot sample PACFs for both processes#pacf(yt1, lag.ma = lag.max, ylab ="sample PACF", ylim=c(-1,1),main="")pacf(yt2, lag.ma = lag.max, ylab ="sample PACF", ylim=c(-1,1),main="")
Quiz 2: The AR(1) definition and properties
Omitted per Coursera honor code requirements.
The AR(1) process:Maximum likelihood estimation and Bayesian inference
Review of maximum likelihood and Bayesian inference in regression
Regression Models: Maximum Likelihood Estimation
Assume a regression model with the following structure:
y_i = \beta_1x_{i,1} + \ldots + \beta_kx_{i,k} + \epsilon_i,
for i = 1, \ldots, n and \epsilon_i independent random variables with \epsilon_i \sim N(0, v) \forall i. This model can be written in matrix form as:
y = X \beta + \epsilon, \epsilon \sim N (0, vI), \qquad
where:
y = (y_1, \ldots, y_n)′ is an n-dimensional vector of responses,
X is an n × k matrix containing the explanatory variables,
\beta = (\beta_1, \ldots, \beta_k)′ is the k-dimensional vector of regression coefficients,
\epsilon = (\epsilon_1, \ldots, \epsilon_n)′ is the n-dimensional vector of errors,
I is an n × n identity matrix.
If X is a full rank matrix with rank k the maximum likelihood estimator for \beta, denoted as \hat\beta_{MLE} is given by:
\hat\beta_{MLE} = (X′X)^{−1}X′y,
and the MLE for v is given by
\hat v_{MLE} = \frac{1}{n} (y − X \hat\beta_{MLE})′(y − X \hat\beta_{MLE})
\hat v_{MLE} is not an unbiased estimator of v, therefore, the following unbiased estimator of v is typically used:
s^2 = \frac{1}{n-k}(y − X \hat\beta_{MLE} )′(y − X \hat\beta_{MLE} )
Regression Models: Bayesian Inference
Assume once again we have a model with the structure in (1), which results in a likelihood of the form
(\beta\mid v, y) \sim N (\hat \beta_{MLE} , v(X′X)−1)
(v\mid y) \sim \text{IG}((n − k)/2, d/2) with
d = (y − X \hat \beta_{MLE} )′(y − \hat \beta_{MLE} )
with k = dim(\beta).
Given that p(\beta, v \mid y) = p(\beta \mid v, y)p(v \mid y) the equations above provide a way to directly sample from the posterior distribution of \beta and v by first sampling v from the inverse-gamma distribution above and then conditioning on this sampled value of v, sampling \beta from the normal distribution above.
Maximum likelihood estimation in the AR(1) (video)
slide 1
slide 2
slide 3
R code: MLE for the AR(1), examples (reading)
The following code allows you to compute the MLE of the AR coefficient \psi, the unbiased estimator of v, s^2 , and the MLE of v based on a dataset simulated from an AR(1) process and using the conditional likelihood.
Code
set.seed(2021)phi=0.9# ar coefficientv=1sd=sqrt(v) # innovation standard deviationT=500# number of time pointsyt=arima.sim(n = T, model =list(ar = phi), sd = sd) ## Case 1: Conditional likelihoody=as.matrix(yt[2:T]) # responseX=as.matrix(yt[1:(T-1)]) # design matrixphi_MLE=as.numeric((t(X)%*%y)/sum(X^2)) # MLE for phis2=sum((y - phi_MLE*X)^2)/(length(y) -1) # Unbiased estimate for v v_MLE=s2*(length(y)-1)/(length(y)) # MLE for vcat("\n MLE of conditional likelihood for phi: ", phi_MLE, "\n","MLE for the variance v: ", v_MLE, "\n", "Estimate s2 for the variance v: ", s2, "\n")
MLE of conditional likelihood for phi: 0.9261423
MLE for the variance v: 1.048
Estimate s2 for the variance v: 1.050104
This code allows you to compute estimates of the AR(1) coefficient and the variance using the arima function in R. The first case uses the conditional sum of squares, the second and third cases use the full likelihood with different starting points for the numerical optimization required to compute the MLE with the full likelihood.
Code
# Obtaining parameter estimates using the arima function in Rset.seed(2021)phi=0.9# ar coefficientv=1sd=sqrt(v) # innovation standard deviationT=500# number of time pointsyt=arima.sim(n = T, model =list(ar = phi), sd = sd) #Using conditional sum of squares, equivalent to conditional likelihood arima_CSS=arima(yt,order=c(1,0,0),method="CSS",n.cond=1,include.mean=FALSE)cat("AR estimates with conditional sum of squares (CSS) for phi and v:", arima_CSS$coef,arima_CSS$sigma2,"\n")
AR estimates with conditional sum of squares (CSS) for phi and v: 0.9261423 1.048
Code
#Uses ML with full likelihood arima_ML=arima(yt,order=c(1,0,0),method="ML",include.mean=FALSE)cat("AR estimates with full likelihood for phi and v:", arima_ML$coef,arima_ML$sigma2,"\n")
AR estimates with full likelihood for phi and v: 0.9265251 1.048434
Code
#Default: uses conditional sum of squares to find the starting point for ML and # then uses ML arima_CSS_ML=arima(yt,order=c(1,0,0),method="CSS-ML",n.cond=1,include.mean=FALSE)cat("AR estimates with CSS to find starting point for ML for phi and v:", arima_CSS_ML$coef,arima_CSS_ML$sigma2,"\n")
AR estimates with CSS to find starting point for ML for phi and v: 0.9265252 1.048434
This code shows you how to compute the MLE for \psi using the full likelihood and the function optimize in R.
Code
set.seed(2021)phi=0.9# ar coefficientv=1sd=sqrt(v) # innovation standard deviationT=500# number of time pointsyt=arima.sim(n = T, model =list(ar = phi), sd = sd) ## MLE, full likelihood AR(1) with v=1 assumed known # log likelihood functionlog_p <-function(phi, yt){0.5*(log(1-phi^2) -sum((yt[2:T] - phi*yt[1:(T-1)])^2) - yt[1]^2*(1-phi^2))}# Use a built-in optimization method to obtain maximum likelihood estimatesresult =optimize(log_p, c(-1, 1), tol =0.0001, maximum =TRUE, yt = yt)cat("\n MLE of full likelihood for phi: ", result$maximum)
MLE of full likelihood for phi: 0.9265928
Bayesian inference in the AR(1)
slide 1
Bayesian inference in the AR(1): Conditional likelihood example (video)
This video walks through the code snippet below and provides examples of how to sample from the posterior distribution of the AR coefficient \psi and the variance v using the conditional likelihood and a reference prior.
R Code: AR(1) Bayesian inference, conditional likelihood example (reading)
Code
######################################################### MLE for AR(1) ##########################################################set.seed(2021)phi=0.9# ar coefficientsd=1# innovation standard deviationT=200# number of time pointsyt=arima.sim(n = T, model =list(ar = phi), sd = sd) # sample stationary AR(1) processy=as.matrix(yt[2:T]) # responseX=as.matrix(yt[1:(T-1)]) # design matrixphi_MLE=as.numeric((t(X)%*%y)/sum(X^2)) # MLE for phis2=sum((y - phi_MLE*X)^2)/(length(y) -1) # Unbiased estimate for vv_MLE=s2*(length(y)-1)/(length(y)) # MLE for v print(c(phi_MLE,s2))
[1] 0.9178472 1.0491054
Code
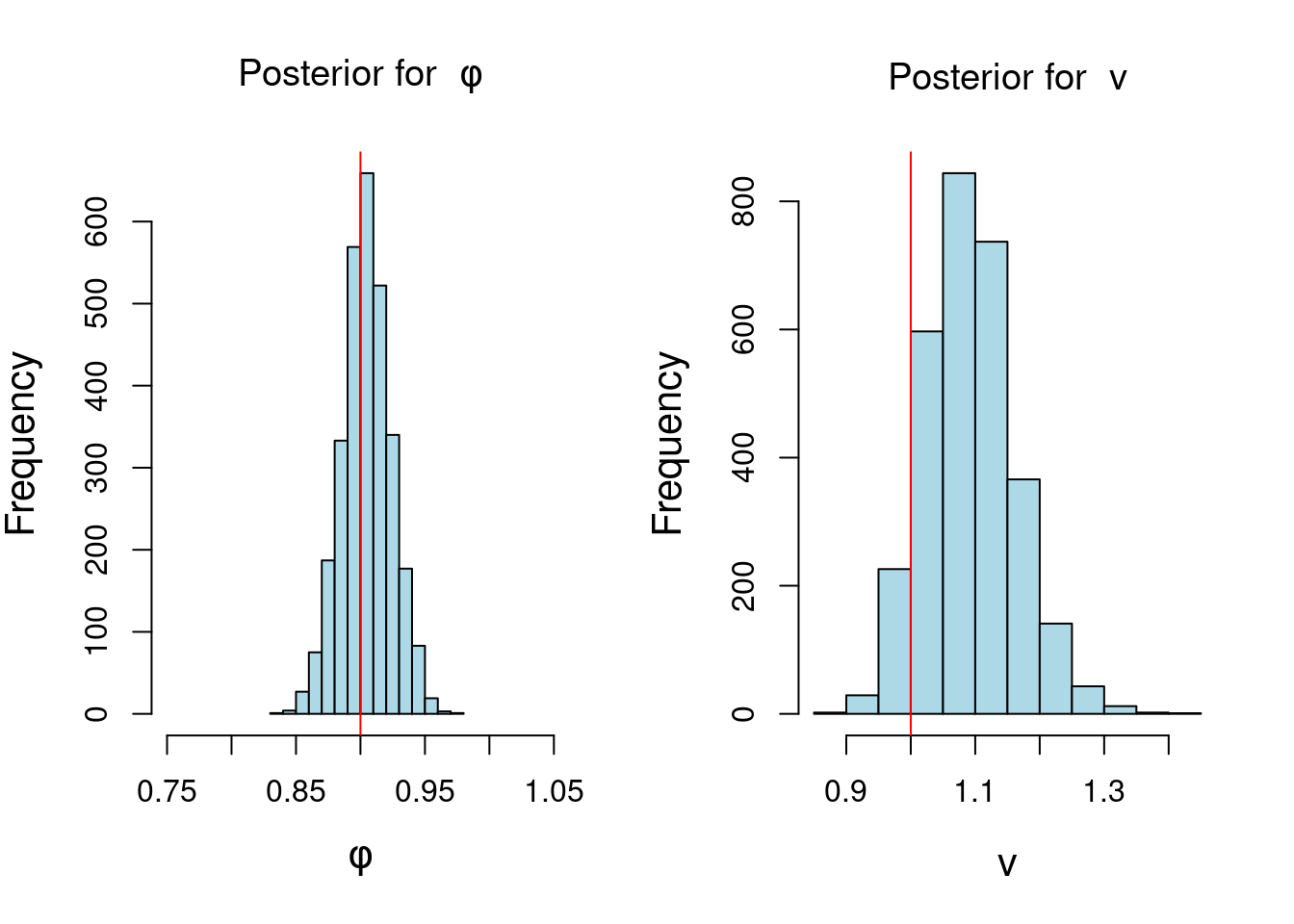
############################################################# Posterior inference, AR(1) ######### Conditional Likelihood + Reference Prior ######### Direct sampling ##########################################################n_sample=3000# posterior sample size## step 1: sample posterior distribution of v from inverse gamma distributionv_sample=1/rgamma(n_sample, (T-2)/2, sum((yt[2:T] - phi_MLE*yt[1:(T-1)])^2)/2)## step 2: sample posterior distribution of phi from normal distributionphi_sample=rep(0,n_sample)for (i in1:n_sample){phi_sample[i]=rnorm(1, mean = phi_MLE, sd=sqrt(v_sample[i]/sum(yt[1:(T-1)]^2)))}## plot histogram of posterior samples of phi and vpar(mfrow =c(1, 2), cex.lab =1.3)hist(phi_sample, xlab =bquote(phi), main =bquote("Posterior for "~phi),xlim=c(0.75,1.05), col='lightblue')abline(v = phi, col ='red')hist(v_sample, xlab =bquote(v), col='lightblue', main =bquote("Posterior for "~v))abline(v = sd, col ='red')
Quizz - MLE and Bayesian inference in the AR(1)
Omitted per Coursera honor code
Practice Graded Assignment: MLE and Bayesian inference in the AR(1)
This peer-reviewed activity is highly recommended. It does not figure into your grade for this course, but it does provide you with the opportunity to apply what you’ve learned in R and prepare you for your data analysis project in week 5.
Consider the R code below: MLE for the AR(1)
Code
######################################################### MLE for AR(1) ##########################################################phi=0.9# ar coefficientv=1sd=sqrt(v) # innovation standard deviationT=500# number of time pointsyt=arima.sim(n = T, model =list(ar = phi), sd = sd) ## Case 1: Conditional likelihoody=as.matrix(yt[2:T]) # responseX=as.matrix(yt[1:(T-1)]) # design matrixphi_MLE=as.numeric((t(X)%*%y)/sum(X^2)) # MLE for phis2=sum((y - phi_MLE*X)^2)/(length(y) -1) # Unbiased estimate for v v_MLE=s2*(length(y)-1)/(length(y)) # MLE for vcat("\n MLE of conditional likelihood for phi: ", phi_MLE, "\n","MLE for the variance v: ", v_MLE, "\n", "Estimate s2 for the variance v: ", s2, "\n")
MLE of conditional likelihood for phi: 0.9048951
MLE for the variance v: 1.084559
Estimate s2 for the variance v: 1.086737
Modify the code above to sample 800 observations from an AR(1) with AR coefficient \psi = -0.8 and variance v = 2. Plot your simulated data. Obtain the MLE for \psi based on the conditional likelihood and the unbiased estimate s^2 for the variance v.
Consider the R code below: AR(1) Bayesian inference, conditional likelihood
Code
############################################################# Posterior inference, AR(1) ######### Conditional Likelihood + Reference Prior ######### Direct sampling ##########################################################n_sample=3000# posterior sample size## step 1: sample posterior distribution of v from inverse gamma distributionv_sample=1/rgamma(n_sample, (T-2)/2, sum((yt[2:T] - phi_MLE*yt[1:(T-1)])^2)/2)## step 2: sample posterior distribution of phi from normal distributionphi_sample=rep(0,n_sample)for (i in1:n_sample){phi_sample[i]=rnorm(1, mean = phi_MLE, sd=sqrt(v_sample[i]/sum(yt[1:(T-1)]^2)))}## plot histogram of posterior samples of phi and vpar(mfrow =c(1, 2), cex.lab =1.3)hist(phi_sample, xlab =bquote(phi), main =bquote("Posterior for "~phi),xlim=c(0.75,1.05), col='lightblue')abline(v = phi, col ='red')hist(v_sample, xlab =bquote(v), col='lightblue', main =bquote("Posterior for "~v))abline(v = sd, col ='red')
Using your simulated data from part 1 modify the code above to summarize your posterior inference for \psi and v based on 5000 samples from the joint posterior distribution of \psi and v.
Grading Criteria
The responses should follow the same template as the sample code provided above but you will submit your code lines in plain text. Peer reviewers will be asked to check whether the different pieces of code have been adequately modified to reflect that :
you generate 800 time points from the AR(1) rather than 500 and plot your simulated data.
your simulated data is from an AR(1) with AR cofficient \psi = -0.8 and variance v = 2 rather than AR(1) with AR coefficient \psi = 0.9 and variance v = 1 and
you obtain 5000 rather than 3000 samples from the posterior distribution from the new simulated process.
Bayesian Inference in the AR(1), : full likelihood example (reading)
We consider a prior distribution that assumes that \phi and v are independent:
i.e., we assume a Uniform prior for \phi \in (-1, 1). Combining this prior with the full likelihood in the AR(1) case, we obtain the following posterior density:
It is not possible to get a closed-form expression for this posterior or to perform direct simulation. Therefore, we use simulation-based Markov Chain Monte Carlo (MCMC) methods to obtain samples from the posterior distribution.
Transformation of \phi
We first consider the following transformation on \phi:
with \phi written as a function of \eta. We proceed to obtain samples from this posterior distribution using the MCMC algorithm outlined below. Once we have obtained M samples from \eta and v after convergence, we can use the inverse transformation above to obtain posterior samples for \phi.
MCMC Algorithm: Bayesian Inference for AR(1), Full Likelihood
Prado, R., M. A. R. Ferreira, and M. West. 2023. Time Series: Modeling, Computation, and Inference. Chapman & Hall/CRC Texts in Statistical Science. CRC Press. https://books.google.co.il/books?id=pZ6lzgEACAAJ.
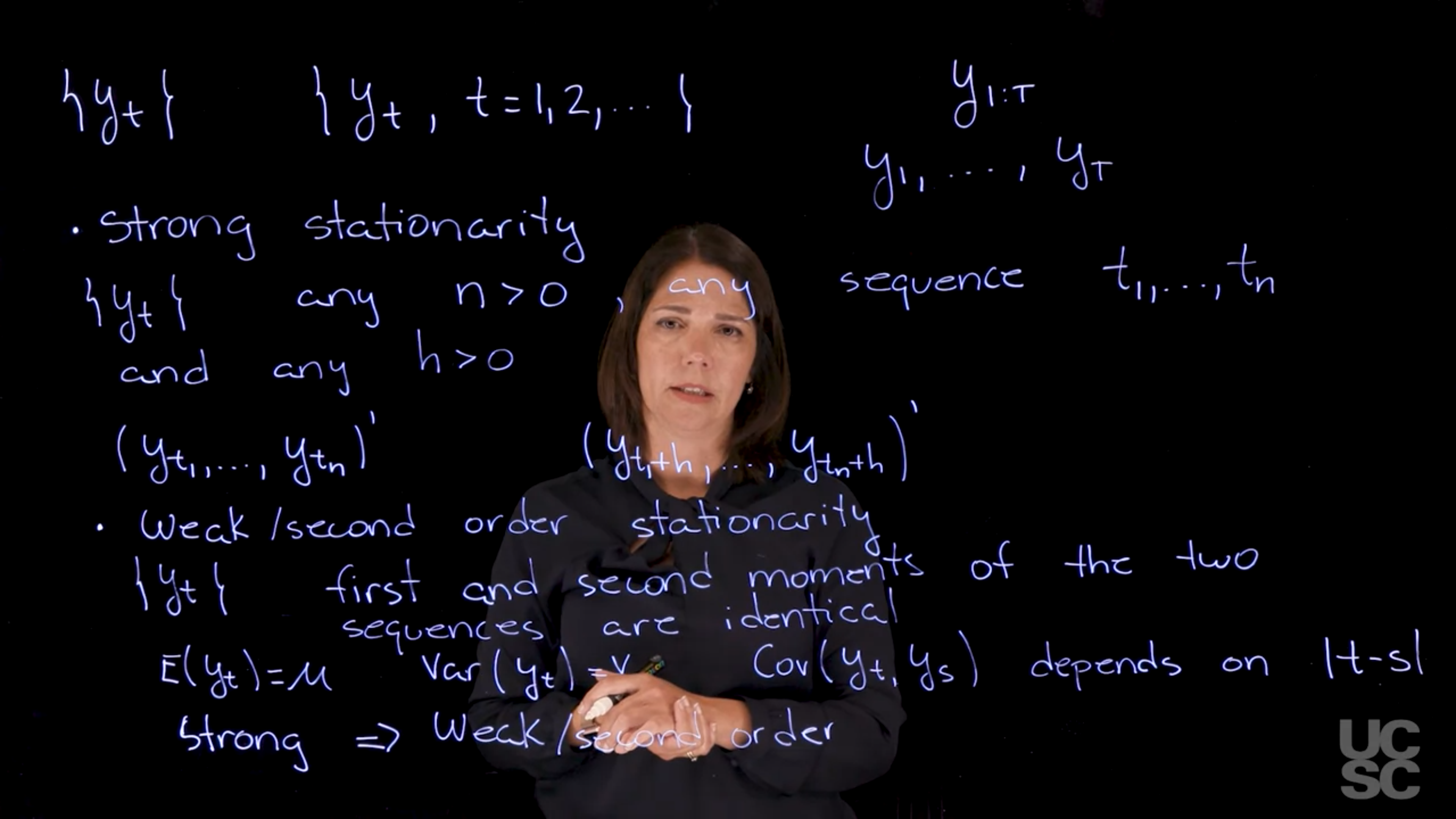
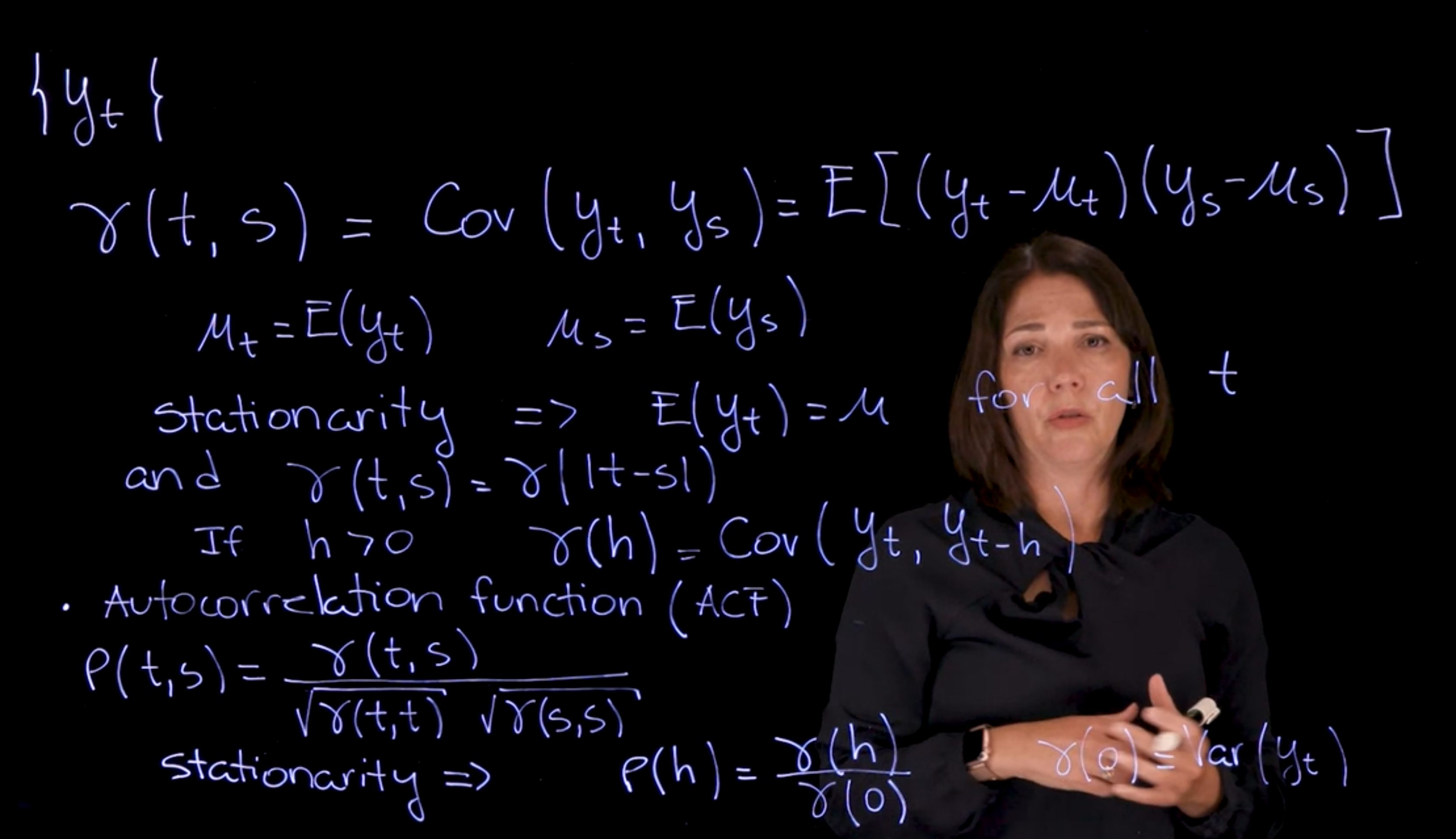

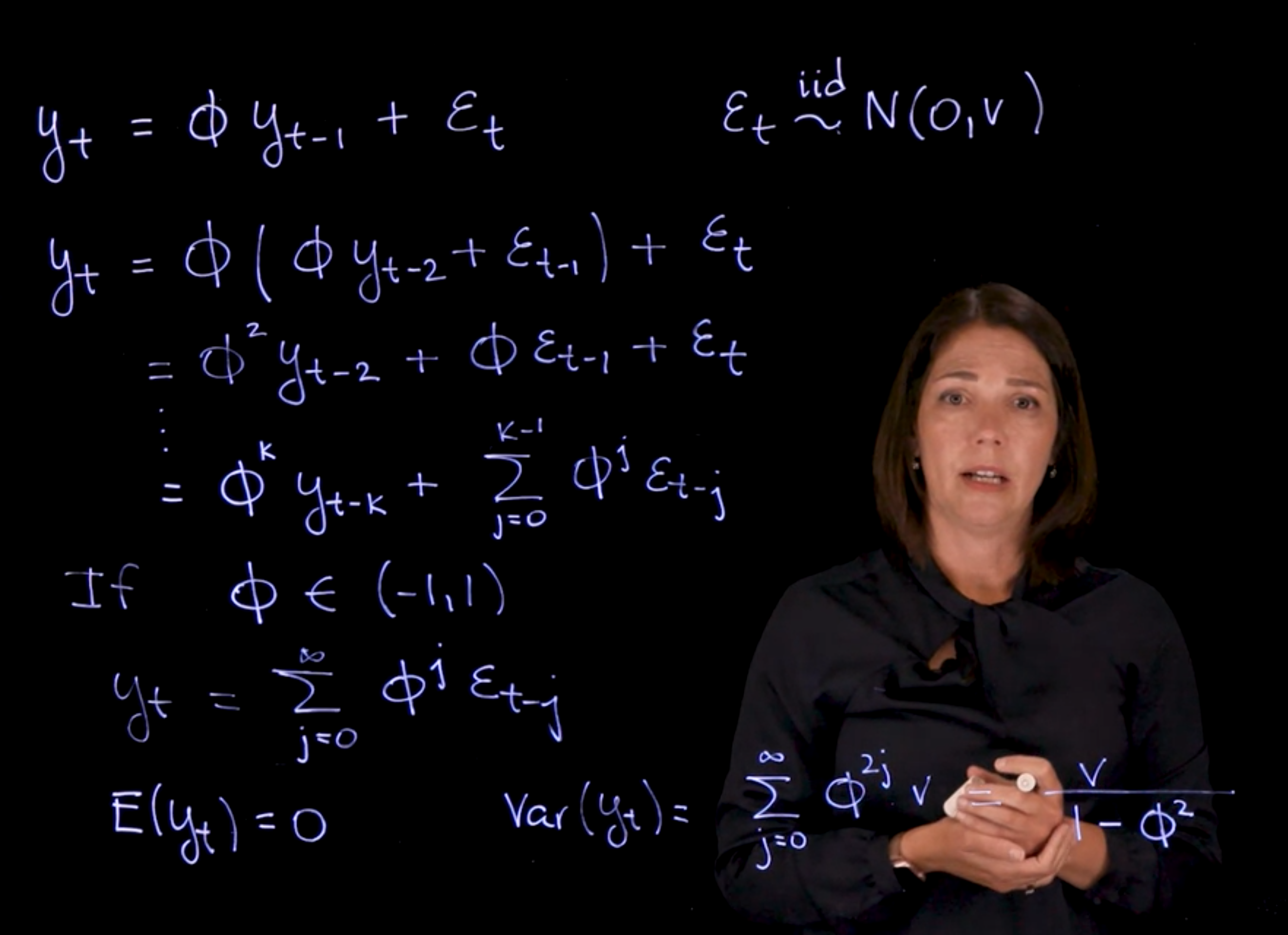

 sampling-1.png)
 sampling-2.png)
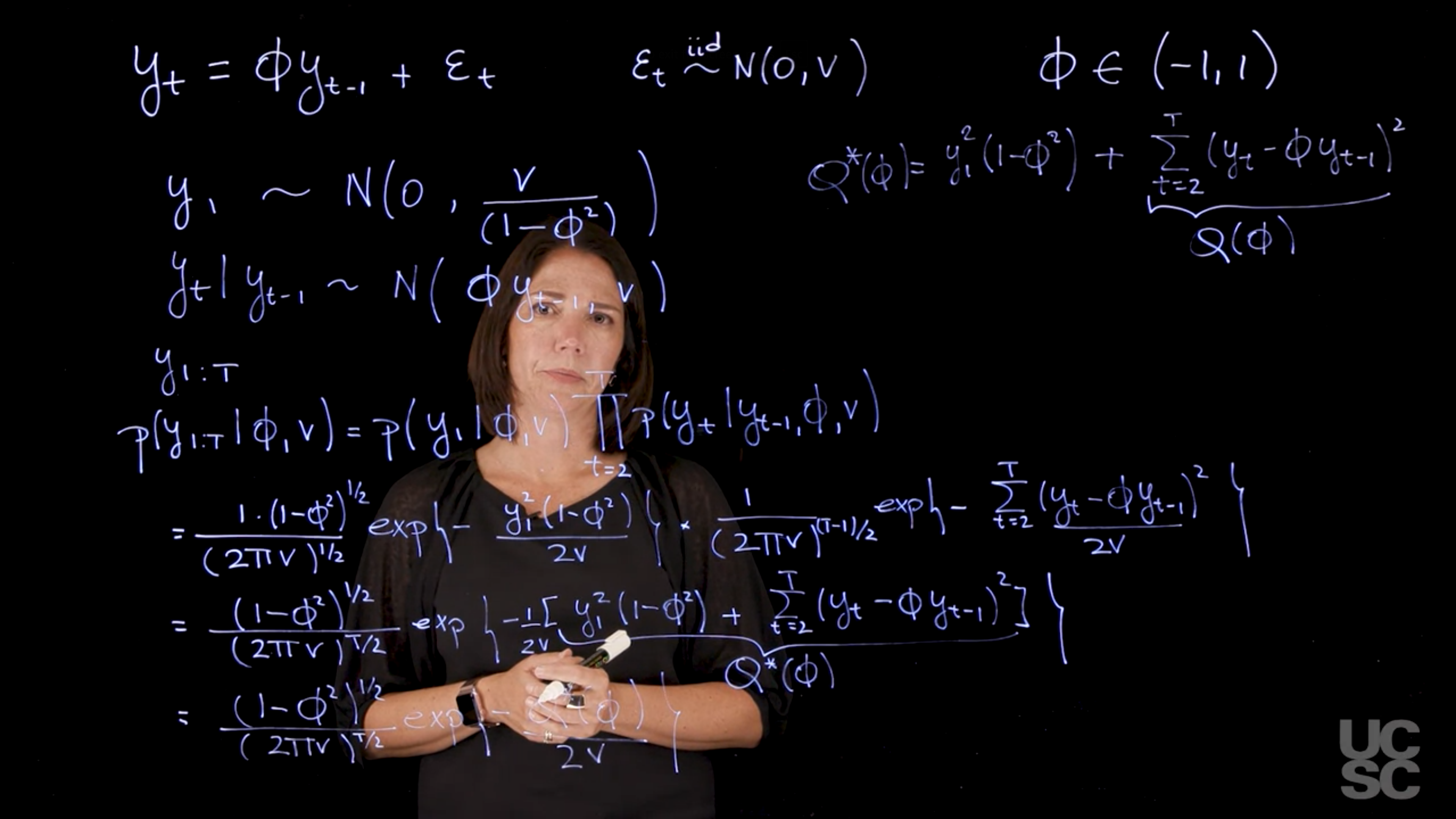
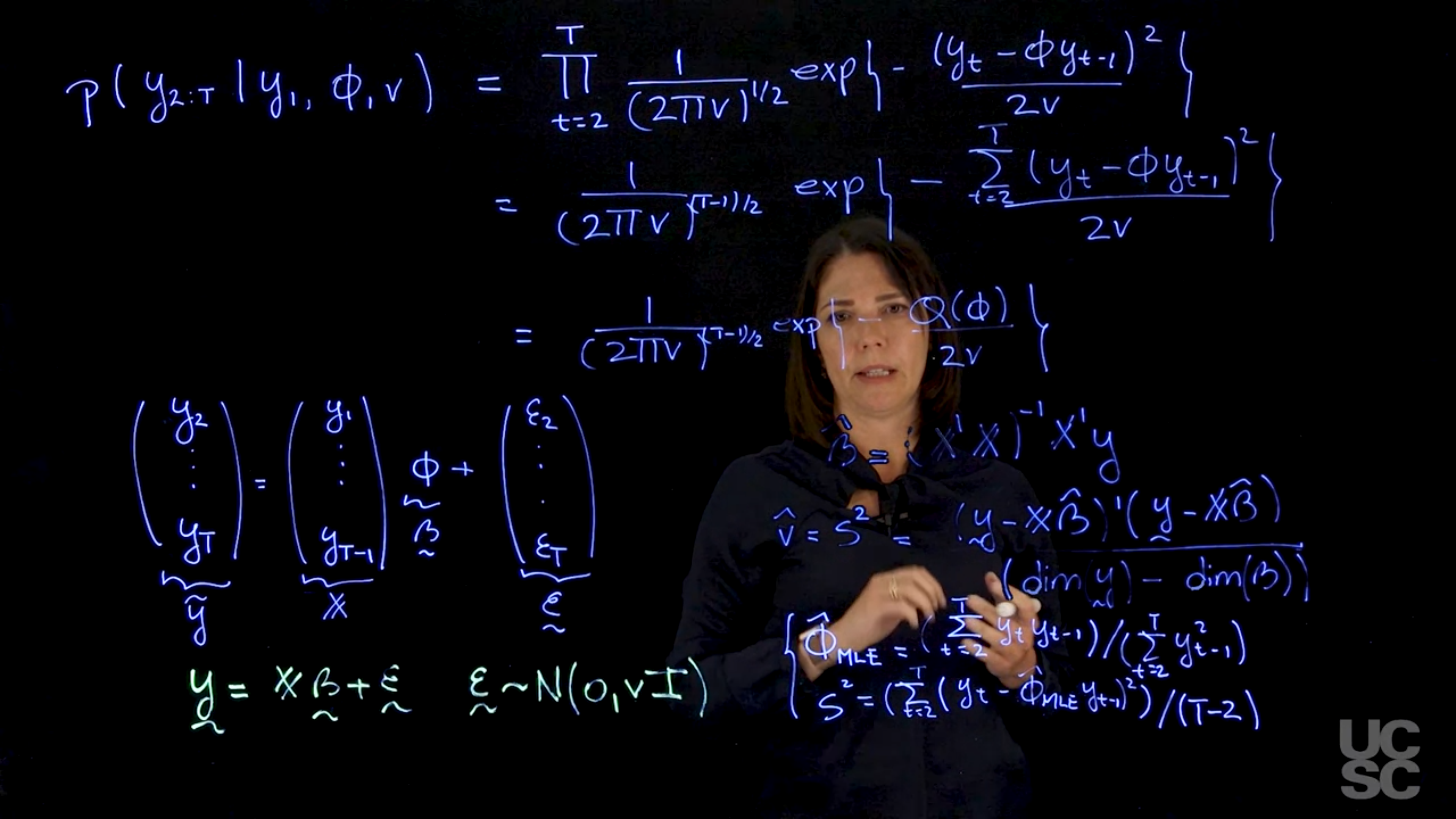
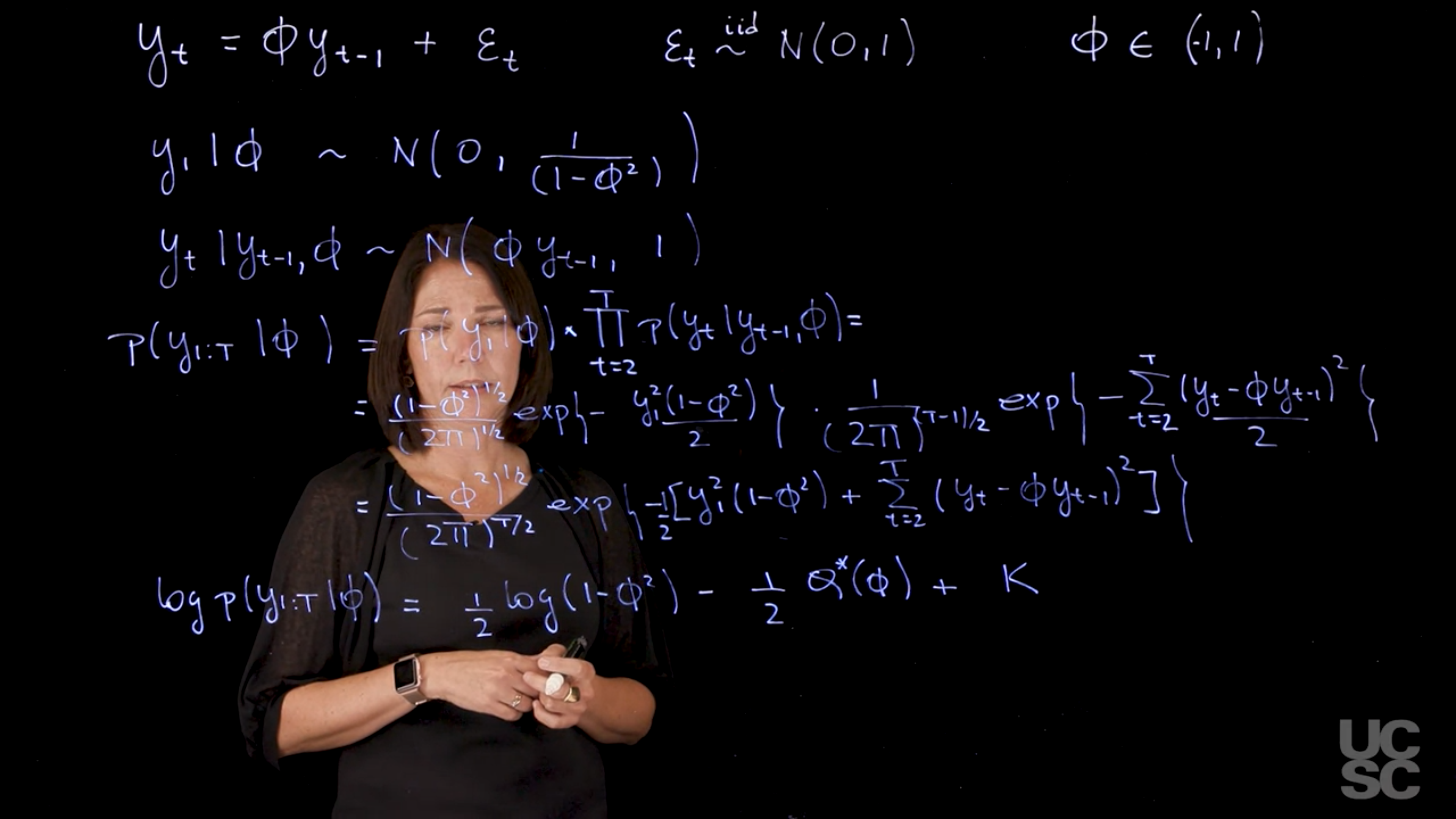
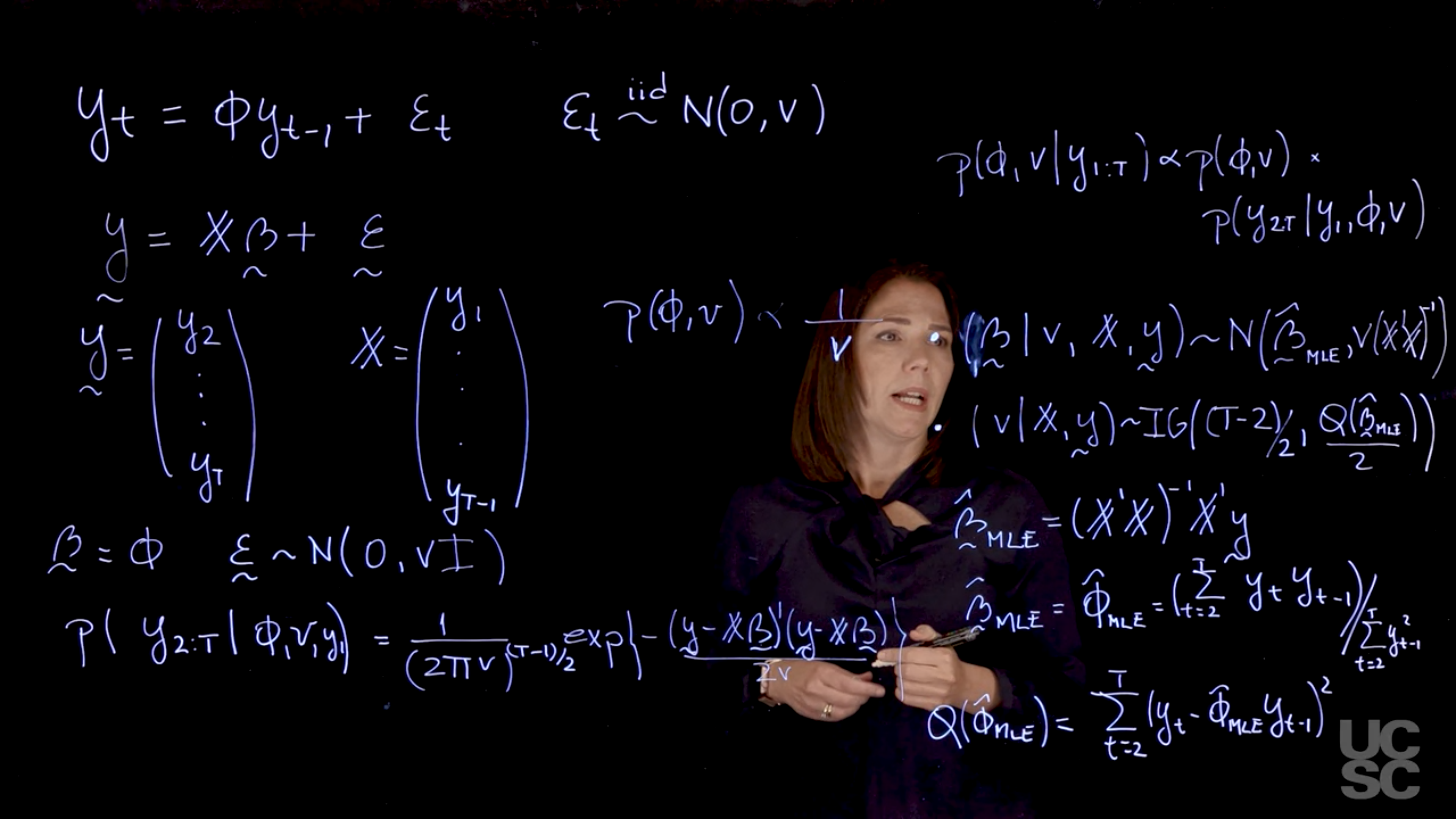
 inference, conditional likelihood example-1.png)