Week 1: Introduction to Time Series and the AR(1) process
Learning Objectives
Introduction
Welcome to Bayesian Statistics: Time Series
Raquel Prado is a professor of statistics in the Baskin School of Engineering at the University of California, Santa Cruz. She was the reciepient 2022 Zellner Medal, see Weckerle (2022)
The third is a classic text on machine learning which covers Durban-Levinson recursion and the Yule-Walker equations mentioned in the course.
The fourth is a classic text on statistical learning theory which covers the basics of time series analysis.
Stationarity the ACF and the PACF
Stationarity (video)
Stationarity is a key concept in time series analysis. A time series is said to be stationary if its statistical properties such as mean, variance, and auto-correlation do not change over time.
Notation
\{y_t\} - the time series process, where each y_t is a univariate random variable.
y_{1:T} or y_1, y_2, \ldots, y_T - the observed data.
Strong Stationarity
Strong Stationarity
given \{y_t\} for any n>0 and any h>0 and any subsequence the distribution of y_t, y_{t+1}, \ldots, y_{t+n} is the same as the distribution of y_{t+h}, y_{t+h+1}, \ldots, y_{t+h+n}.
since it is difficult to verify strong stationarity in practice, we often work with weak stationarity.
Weak Stationarity AKA Second-order Stationarity
Weak Stationarity
the mean, variance, and auto-covariance are constant over time.
strong stationarity implies weak stationarity, but
the converse is not true.
for a Gaussian process, our typical use case, they are equivalent!
Let y_t be a time series. We say that y_t is stationary if the following conditions hold:
The auto-correlation function ACF (video)
auto-correlation AFC
The partial auto-correlation function PACF (Reading)
be the best linear predictor of y_t based on the previous h − 1 values \{y_{t−1}, \ldots , y_{t−h+1}\}. The best linear predictor of y_t based on the previous h − 1 values of the process is the linear predictor that minimizes
E[(y_t − \hat{y}_y^{h-1})^2]
The partial autocorrelation of this process at lag h, denoted by \phi(h, h) is defined as:
Note that the sample PACF can be obtained by substituting the sample autocorrelations and the sample auto-covariances in the Durbin-Levinson recursion.
Durbin-Levinson recursion (Off-Course Reading)
Like me, you might be curious about the Durbin-Levinson recursion mentioned above. This is not covered in the course, and turned out to be an enigma wrapped in a mystery.
In (Yule 1927) and (Walker 1931), Yule and Walker proposed a method for estimating the parameters of an autoregressive model. The method is based on the Yule-Walker equations which are a set of linear equations that can be used to estimate the parameters of an autoregressive model.
Due to the autoregressive nature of the model, the equations are take a special form called a Toeplitz matrix. However at the time they probably had to use the numerically unstable Gauss-Jordan elimination to solve these equations which is O(n^3) in time complexity.
A decade or two later in (Levinson 1946) and (Durbin 1960) the authors came up for with a weakly stable yet more efficient algorithm for solving these autocorrelated system of equations which requires only O(n^2) in time complexity. Later their work was further refined in (Trench 1964) and (Zohar 1969) to just 3\times n^2 multiplication. A cursory search reveals that Toeplitz matrix inversion is still an area of active research with papers covering parallel algorithms and stability studies. Not surprising as man of the more interesting deep learning models, including LLMs are autoregressive.
Durbin-Levinson and the Yule-Walker equations (Off-Course Reading)
The Durbin-Levinson recursion is a method in linear algebra for computing the solution to an equation involving a Toeplitz matrix AKA a diagonal-constant matrix where descending diagonals are constant. The recursion runs in O(n^2) time rather then O(n^3) time required by Gauss-Jordan elimination.
The recursion can be used to compute the coefficients of the autoregressive model of a stationary time series. It is based on the Yule-Walker equations and is used to compute the PACF of a time series.
The Yule-Walker equations can be stated as follows for an AR(p) process:
and since this matrix is Toeplitz, we can use Durbin-Levinson recursion to efficiently solve the system for \phi_k \forall k.
Once \{\phi_m ; m=1,2, \dots ,p \} are known, we can consider m=0 and solved for \sigma_\epsilon^2 by substituting the \phi_k into Equation 2 Yule-Walker equations.
Of course the Durbin-Levinson recursion is not the last word on solving this system of equations. There are today numerous improvements which are both faster and more numerically stable.
Differencing and smoothing (Reading)
Many time series models are built under the assumption of stationarity. However, time series data often present non-stationary features such as trends or seasonality. Practitioners may consider techniques for detrending, deseasonalizing and smoothing that can be applied to the observed data to obtain a new time series that is consistent with the stationarity assumption.
We briefly discuss two methods that are commonly used in practice for detrending and smoothing.
Differencing
The first method is differencing, which is generally used to remove trends in time series data. The first difference of a time series is defined in terms of the so called difference operator denoted as D, that produces the transformation
differencing operator
Dy_t = y_t - y_{t-1}.
Higher order differences are obtained by successively applying the operator D. For example,
D^2y_t = D(Dy_t) = D(y_t - y_{t-1}) = y_t - 2y_{t-1} + y_{t-2}.
Differencing can also be written in terms of the so called backshift operator B, with
By_t = y_{t-1},
backshift operator
so that
Dy_t = (1 - B)y_t
and
D^dy_t = (1 - B)d y_t.
Smoothing
The second method we discuss is moving averages, which is commonly used to “smooth” a time series by removing certain features (e.g., seasonality) to highlight other features (e.g., trends). A moving average is a weighted average of the time series around a particular time t. In general, if we have data y1:T , we could obtain a new time series such that
moving average
z_t = \sum_{j=-q}^{p} w_j y_{t+j},
for t = (q + 1) : (T − p), with weights w_j ≥ 0 and \sum^p_{j=−q} w_j = 1
We will frequently work with moving averages for which
p = q \qquad \text{(centered)}
and
w_j = w_{−j} \forall j \text{(symmetric)}
Assume we have periodic data with period d. Then, symmetric and centered moving averages can be used to remove such periodicity as follows:
If d = 2q :
z_t = \frac{1}{2} (y_{t−q} + y_{t−q+1} + \ldots + y_{t+q−1} + y_{t+q})
Example: To remove seasonality in monthly data (i.e., seasonality with a period of d = 12 months), one can use a moving average with p = q = 6, a_6 = a_{−6} = 1/24, and a_j = a_{−j} = 1/12 for j = 0, \ldots , 5 , resulting in:
ACF PACF Differencing and Smoothing Examples (Video)
Praesent ornare dolor turpis, sed tincidunt nisl pretium eget. Curabitur sed iaculis ex, vitae tristique sapien. Quisque nec ex dolor. Quisque ut nisl a libero egestas molestie. Nulla vel porta nulla. Phasellus id pretium arcu. Etiam sed mi pellentesque nibh scelerisque elementum sed at urna. Ut congue molestie nibh, sit amet pretium ligula consectetur eu. Integer consectetur augue justo, at placerat erat posuere at. Ut elementum urna lectus, vitae bibendum neque pulvinar quis. Suspendisse vulputate cursus eros id maximus. Duis pulvinar facilisis massa, et condimentum est viverra congue. Curabitur ornare convallis nisl. Morbi dictum scelerisque turpis quis pellentesque. Etiam lectus risus, luctus lobortis risus ut, rutrum vulputate justo. Nulla facilisi.
Proin sodales neque erat, varius cursus diam tincidunt sit amet. Etiam scelerisque fringilla nisl eu venenatis. Donec sem ipsum, scelerisque ac venenatis quis, hendrerit vel mauris. Praesent semper erat sit amet purus condimentum, sit amet auctor mi feugiat. In hac habitasse platea dictumst. Nunc ac mauris in massa feugiat bibendum id in dui. Praesent accumsan urna at lacinia aliquet. Proin ultricies eu est quis pellentesque. In vel lorem at nisl rhoncus cursus eu quis mi. In eu rutrum ante, quis placerat justo. Etiam euismod nibh nibh, sed elementum nunc imperdiet in. Praesent gravida nunc vel odio lacinia, at tempus nisl placerat. Aenean id ipsum sed est sagittis hendrerit non in tortor.
R code for Differencing and filtering via moving averages (reading)
Code
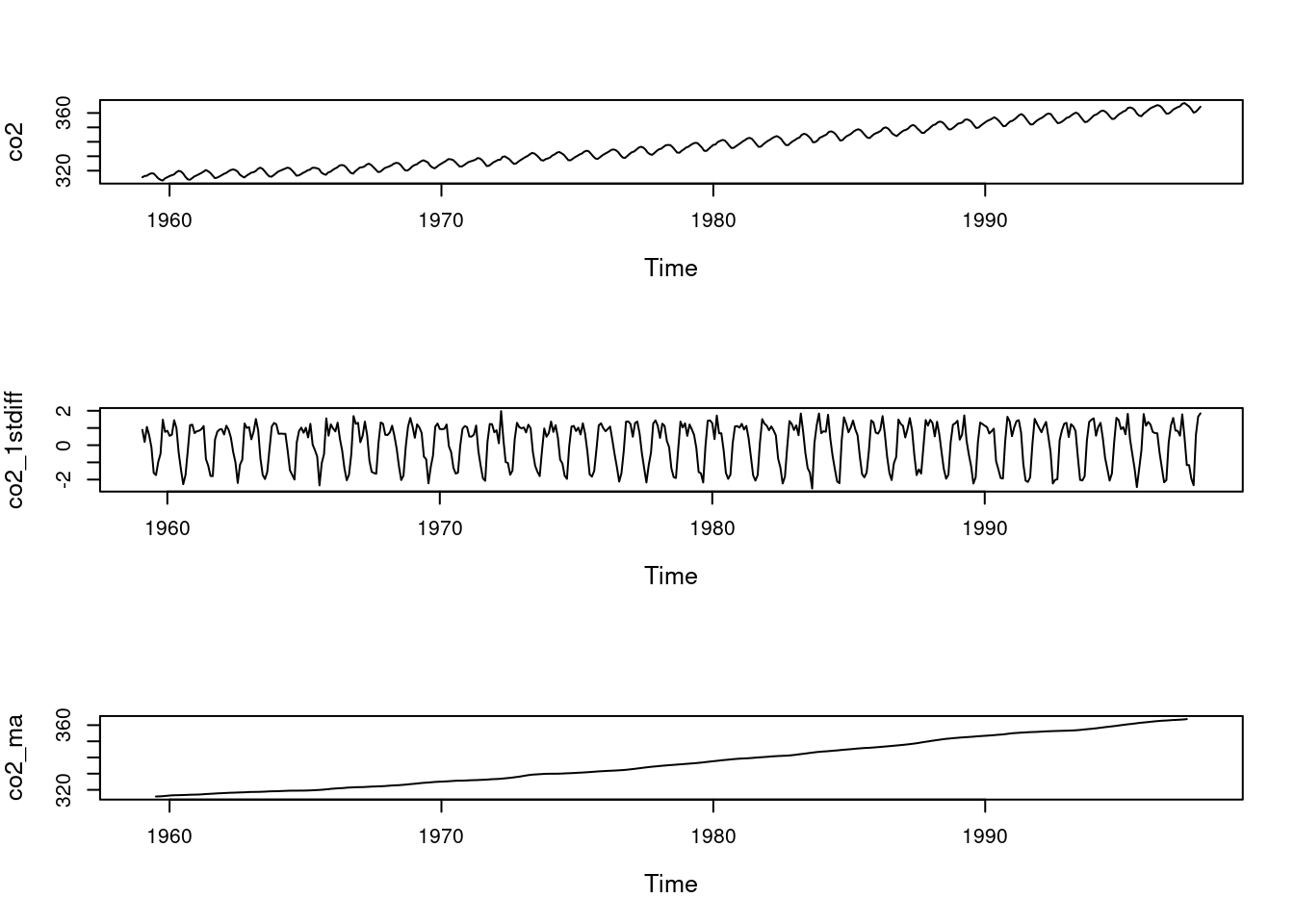
# Load the CO2 dataset in Rdata(co2) # Take first differences to remove the trend co2_1stdiff=diff(co2,differences=1)# Filter via moving averages to remove the seasonality co2_ma=filter(co2,filter=c(1/24,rep(1/12,11),1/24),sides=2)par(mfrow=c(3,1), cex.lab=1.2,cex.main=1.2)plot(co2) # plot the original data plot(co2_1stdiff) # plot the first differences (removes trend, highlights seasonality)plot(co2_ma) # plot the filtered series via moving averages (removes the seasonality, highlights the trend)
R Code: Simulate data from a white noise process
Code
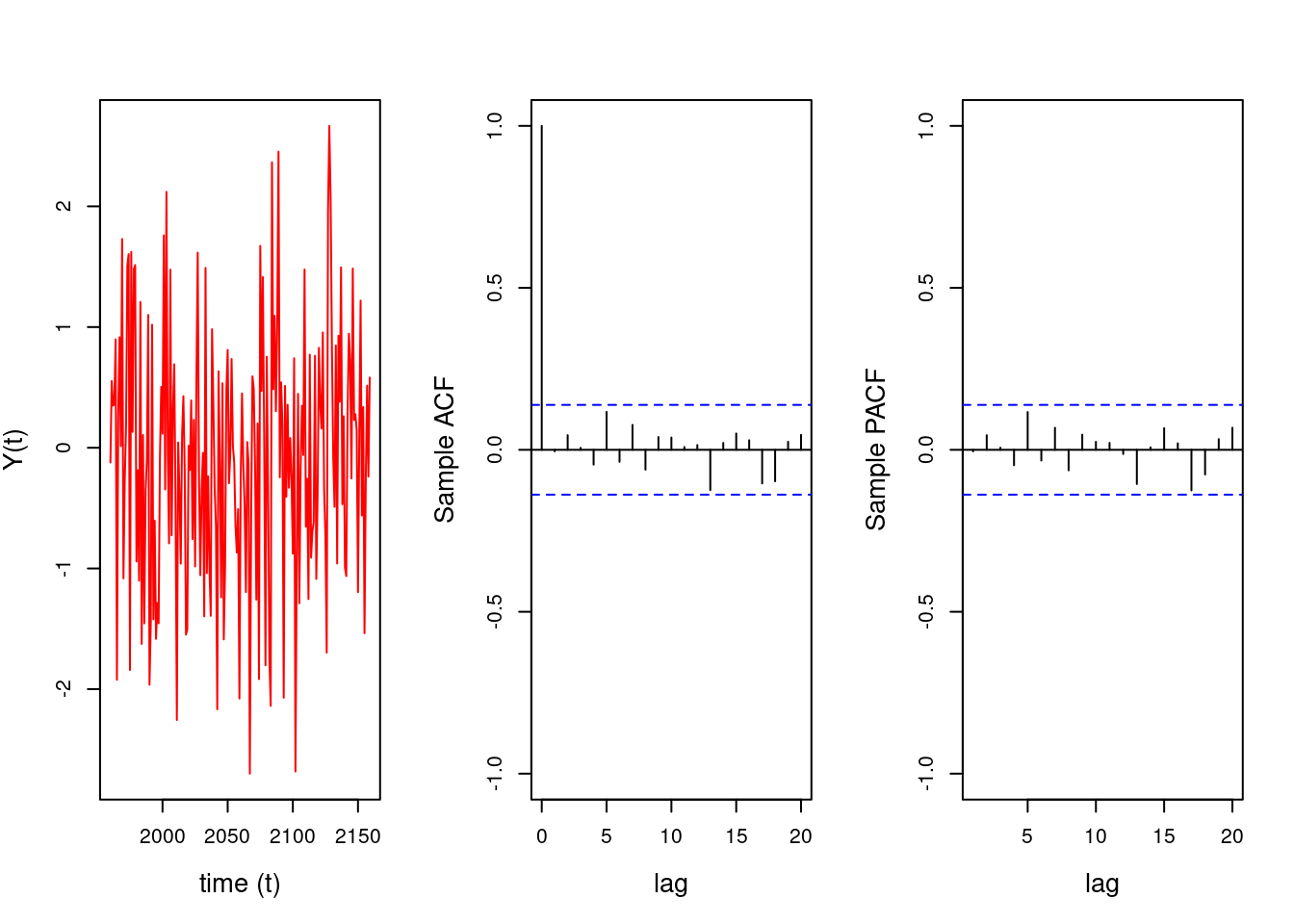
## Simulate data with no temporal structure (white noise)#set.seed(2021)T=200t =1:Ty_white_noise=rnorm(T, mean=0, sd=1)## Define a time series object in R: # Assume the data correspond to annual observations starting in January 1960 #yt=ts(y_white_noise, start=c(1960), frequency=1)## plot the simulated time series, their sample ACF and their sample PACF#par(mfrow =c(1, 3), cex.lab =1.3, cex.main =1.3)yt=ts(y_white_noise, start=c(1960), frequency=1)plot(yt, type ='l', col='red', xlab ='time (t)', ylab ="Y(t)")acf(yt, lag.max =20, xlab ="lag",ylab ="Sample ACF",ylim=c(-1,1),main="")pacf(yt, lag.max =20,xlab ="lag",ylab ="Sample PACF",ylim=c(-1,1),main="")
Quiz 1: Stationarity, ACF, PACF, Differencing, and Smoothing
omitted per corsera requirements
The AR(1) process: Definition and properties
Nullam dapibus cursus dolor sit amet consequat. Nulla facilisi. Curabitur vel nulla non magna lacinia tincidunt. Duis porttitor quam leo, et blandit velit efficitur ut. Etiam auctor tincidunt porttitor. Phasellus sed accumsan mi. Fusce ut erat dui. Suspendisse eu augue eget turpis condimentum finibus eu non lorem. Donec finibus eros eu ante condimentum, sed pharetra sapien sagittis. Phasellus non dolor ac ante mollis auctor nec et sapien. Pellentesque vulputate at nisi eu tincidunt. Vestibulum at dolor aliquam, hendrerit purus eu, eleifend massa. Morbi consectetur eros id tincidunt gravida. Fusce ut enim quis orci hendrerit lacinia sed vitae enim.
Nulla eget cursus ipsum. Vivamus porttitor leo diam, sed volutpat lectus facilisis sit amet. Maecenas et pulvinar metus. Ut at dignissim tellus. In in tincidunt elit. Etiam vulputate lobortis arcu, vel faucibus leo lobortis ac. Aliquam erat volutpat. In interdum orci ac est euismod euismod. Nunc eleifend tristique risus, at lacinia odio commodo in. Sed aliquet ligula odio, sed tempor neque ultricies sit amet.
The AR(1) process (video)
Etiam non efficitur urna, quis elementum nisi. Mauris posuere a augue vel gravida. Praesent luctus erat et ex iaculis interdum. Nulla vestibulum quam ac nunc consequat vulputate. Nullam iaculis lobortis sem sit amet fringilla. Aliquam semper, metus ut blandit semper, nulla velit fermentum sapien, fermentum ultrices dolor sapien sed leo. Vestibulum molestie faucibus magna, at feugiat nulla ullamcorper a. Aliquam erat volutpat. Praesent scelerisque magna a justo maximus, sit amet suscipit mauris tempor. Nulla nec dolor eget ipsum pellentesque lobortis a in ipsum. Morbi turpis turpis, fringilla a eleifend maximus, viverra nec neque. Class aptent taciti sociosqu ad litora torquent per conubia nostra, per inceptos himenaeos.
Duis urna urna, pellentesque eu urna ut, malesuada bibendum dolor. Suspendisse potenti. Vivamus ornare, arcu quis molestie ultrices, magna est accumsan augue, auctor vulputate erat quam quis neque. Nullam scelerisque odio vel ultricies facilisis. Ut porta arcu non magna sagittis lacinia. Cras ornare vulputate lectus a tristique. Pellentesque ac arcu congue, rhoncus mi id, dignissim ligula.
The PACF of the AR(1) process (reading)
It is possible to show that the PACF of an autoregressive process of order one is zero after the first lag. We can use the Durbin-Levinson recursion to show this.
For lag n = 0 we have \phi(0, 0) = 0.
For lag n = 1 we have:
\phi(1, 1) = \rho(1) = \phi
We can prove by induction that in the case of an AR(1), for any lag n,
\phi(n, h) = 0, \phi(n, 1) = \phi and \phi(n, h) = 0 for h ≥ 2 and n ≥ 2.
Then, the PACF of an AR(1) is zero for any lag above 1 and the PACF coefficient at lag 1 is equal to the AR coefficient \phi
Duis urna urna, pellentesque eu urna ut, malesuada bibendum dolor. Suspendisse potenti. Vivamus ornare, arcu quis molestie ultrices, magna est accumsan augue, auctor vulputate erat quam quis neque. Nullam scelerisque odio vel ultricies facilisis. Ut porta arcu non magna sagittis lacinia. Cras ornare vulputate lectus a tristique. Pellentesque ac arcu congue, rhoncus mi id, dignissim ligula.
Praesent ornare dolor turpis, sed tincidunt nisl pretium eget. Curabitur sed iaculis ex, vitae tristique sapien. Quisque nec ex dolor. Quisque ut nisl a libero egestas molestie. Nulla vel porta nulla. Phasellus id pretium arcu. Etiam sed mi pellentesque nibh scelerisque elementum sed at urna. Ut congue molestie nibh, sit amet pretium ligula consectetur eu. Integer consectetur augue justo, at placerat erat posuere at. Ut elementum urna lectus, vitae bibendum neque pulvinar quis. Suspendisse vulputate cursus eros id maximus. Duis pulvinar facilisis massa, et condimentum est viverra congue. Curabitur ornare convallis nisl. Morbi dictum scelerisque turpis quis pellentesque. Etiam lectus risus, luctus lobortis risus ut, rutrum vulputate justo. Nulla facilisi.
Sample data from AR(1) processes (Reading)
Code
# sample data from 2 ar(1) processes and plot their ACF and PACF functions#set.seed(2021)T=500# number of time points## sample data from an ar(1) with ar coefficient phi = 0.9 and variance 1#v=1.0# innovation variancesd=sqrt(v) #innovation stantard deviationphi1=0.9# ar coefficientyt1=arima.sim(n = T, model =list(ar = phi1), sd = sd)## sample data from an ar(1) with ar coefficient phi = -0.9 and variance 1#phi2=-0.9# ar coefficientyt2=arima.sim(n = T, model =list(ar = phi2), sd = sd)par(mfrow =c(2, 1), cex.lab =1.3)plot(yt1,main=expression(phi==0.9))plot(yt2,main=expression(phi==-0.9))
Code
par(mfrow =c(3, 2), cex.lab =1.3)lag.max=50# max lag### plot true ACFs for both processes#cov_0=sd^2/(1-phi1^2) # compute auto-covariance at h=0cov_h=phi1^(0:lag.max)*cov_0 # compute auto-covariance at hplot(0:lag.max, cov_h/cov_0, pch =1, type ='h', col ='red',ylab ="true ACF", xlab ="Lag",ylim=c(-1,1), main=expression(phi==0.9))cov_0=sd^2/(1-phi2^2) # compute auto-covariance at h=0cov_h=phi2^(0:lag.max)*cov_0 # compute auto-covariance at h# Plot autocorrelation function (ACF)plot(0:lag.max, cov_h/cov_0, pch =1, type ='h', col ='red',ylab ="true ACF", xlab ="Lag",ylim=c(-1,1),main=expression(phi==-0.9))## plot sample ACFs for both processes#acf(yt1, lag.max = lag.max, type ="correlation", ylab ="sample ACF",lty =1, ylim =c(-1, 1), main =" ")acf(yt2, lag.max = lag.max, type ="correlation", ylab ="sample ACF",lty =1, ylim =c(-1, 1), main =" ")## plot sample PACFs for both processes#pacf(yt1, lag.ma = lag.max, ylab ="sample PACF", ylim=c(-1,1),main="")pacf(yt2, lag.ma = lag.max, ylab ="sample PACF", ylim=c(-1,1),main="")
Quiz 2: The AR(1) definition and properties
Omitted per Coursera requirements
The AR(1) process:Maximum likelihood estimation and Bayesian inference
Proin sodales neque erat, varius cursus diam tincidunt sit amet. Etiam scelerisque fringilla nisl eu venenatis. Donec sem ipsum, scelerisque ac venenatis quis, hendrerit vel mauris. Praesent semper erat sit amet purus condimentum, sit amet auctor mi feugiat. In hac habitasse platea dictumst. Nunc ac mauris in massa feugiat bibendum id in dui. Praesent accumsan urna at lacinia aliquet. Proin ultricies eu est quis pellentesque. In vel lorem at nisl rhoncus cursus eu quis mi. In eu rutrum ante, quis placerat justo. Etiam euismod nibh nibh, sed elementum nunc imperdiet in. Praesent gravida nunc vel odio lacinia, at tempus nisl placerat. Aenean id ipsum sed est sagittis hendrerit non in tortor.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Duis sagittis posuere ligula sit amet lacinia. Duis dignissim pellentesque magna, rhoncus congue sapien finibus mollis. Ut eu sem laoreet, vehicula ipsum in, convallis erat. Vestibulum magna sem, blandit pulvinar augue sit amet, auctor malesuada sapien. Nullam faucibus leo eget eros hendrerit, non laoreet ipsum lacinia. Curabitur cursus diam elit, non tempus ante volutpat a. Quisque hendrerit blandit purus non fringilla. Integer sit amet elit viverra ante dapibus semper. Vestibulum viverra rutrum enim, at luctus enim posuere eu. Orci varius natoque penatibus et magnis dis parturient montes, nascetur ridiculus mus.
References
Durbin, J. 1960. “The Fitting of Time-Series Models.”Revue de l’Institut International de Statistique / Review of the International Statistical Institute 28 (3): 233–44. http://www.jstor.org/stable/1401322.
Levinson, Norman. 1946. “The Wiener (Root Mean Square) Error Criterion in Filter Design and Prediction.”Journal of Mathematics and Physics 25 (1-4): 261–78. https://doi.org/https://doi.org/10.1002/sapm1946251261.
Prado, R., M. A. R. Ferreira, and M. West. 2023. Time Series: Modeling, Computation, and Inference. Chapman & Hall/CRC Texts in Statistical Science. CRC Press. https://books.google.co.il/books?id=pZ6lzgEACAAJ.
Walker, Gilbert Thomas. 1931. “On Periodicity in Series of Related Terms.”Proceedings of the Royal Society of London. Series A, Containing Papers of a Mathematical and Physical Character 131 (818): 518–32. https://doi.org/10.1098/rspa.1931.0069.
Yule, George Udny. 1927. “VII. On a Method of Investigating Periodicities Disturbed Series, with Special Reference to Wolfer’s Sunspot Numbers.”Philosophical Transactions of the Royal Society of London. Series A, Containing Papers of a Mathematical or Physical Character 226 (636-646): 267–98. https://doi.org/10.1098/rsta.1927.0007.
 sampling-1.png)
 sampling-2.png)