Session Video
Course Leaders:
- Bitya Neuhof - DataNights
- Yasmin Bokobza - Microsoft
Speaker:
- Amit Sharma - Microsoft
Sharma is a Principal Researcher at Microsoft Research India. His work bridges CI (causal inference) techniques with machine learning, to make ML models generalize better, be explainable and avoid hidden biases. To this end, Sharma has co-led the development of the open-source DoWhy library for causal inference and DiCE library for counterfactual explanations. The broader theme in his work is how ML can be used for better decision-making, especially in sensitive domains. In this direction, Sharma collaborates with NIMHANS on mental health technology, including a recent app, MindNotes, that encourages people to break the stigma and reach out to professionals.
His work has received many awards including:
- a Best Paper Award at ACM CHI 2021 conference,
- Best Paper Honorable Mention at ACM CSCW 2016 conference,
- the 2012 Yahoo! Key Scientific Challenges Award and
- the 2009 Honda Young Engineer and Scientist Award.
Amit received his:
- Ph.D. in computer science from Cornell University and
- B.Tech. in Computer Science and Engineering from the Indian Institute of Technology (IIT) Kharagpur.
- Profile
What is this session about?
How to explain a machine learning model such that the explanation is truthful to the model and yet interpretable to people? This question is key to ML explanations research because explanation techniques face an inherent trade-off between fidelity and interpretability: a high-fidelity explanation for an ML model tends to be complex and hard to interpret, while an interpretable explanation is often inconsistent with the ML model.
In this talk, the speaker presented counterfactual explanations (CFX) that bridge this trade-off. Rather than approximate an ML model or rank features by their predictive importance, a CF explanation “interrogates” a model to find required changes that would flip the model’s decision and presents those examples to a user. Such examples offer a true reflection of how the model would change its prediction, thus helping decision-subject decide what they should do next to obtain a desired outcome and helping model designers debug their model. Using benchmark datasets on loan approval, I will compare counterfactual explanations to popular alternatives like LIME and SHAP. I will also present a case study on generating CF examples for image classifiers that can be used for evaluating the fairness of models as well as improving the generalizability of a model.
The speaker pointed out that he is primarily interested lay in CI and that when he later got interested in XAI his focused was on the cusp of CI and XAI.
Sharma shared that initially his work on XAI focused on deterministic, differential models. Only later when people asked about using them with traditional ML models like sk-learn and random forest that he went back to the drawing board and discovered how sampling counterfactual locally it is possible to got even better results.
Sharma also pointed out a shortcomings of algorithms like LIME and SHAP. While these present feature importance, their explanation are not actionable. This is in the sense that they fail to spell out to decision maker which interventions would allow them to cross decision boundaries, with least resistance, into their zone of desired outcomes.
Outline

Background

A great starting point for ML tasks if often best motivated by considering pros and cons of human capabilities in these tasks. Sharma points out that in (Weichselbaumer 2019) researchers used counterfactual thinking to study if employers discriminate against women wearing a head scarf. The idea was to they sent resumes sent to German Companies and modified names and images of applicants. German companies usually require images in the C.V. The study found there was discrimination.
Counterfactual Definition

Sharma presents the definition for a counterfactual provided by Judea Pearl
Given a system output y, a counterfactual y_{X_i=x'} is the output of a system had some input X_i changed but everything else unaffected by X_i remained the same. — (Pearl 2009).
Under the holistic paradigm introduced in Smuts (1926) complex real world systems are inherently interconnected with the implication that that a change to just one thing will end up changing everything. ML Models of reality are reductionist, make simplifying assumptions Linear model and many traditional ML model will allow us to test a CF type intervention.
And this can be be very useful.
The many uses of model CF Models
Estimating f(X_i=x')-f(x) can provide:
- Individual Effect of Feature a feature X_i
X_i = E[Y_{X_i=x'}\mid X=x,Y=y]-E[Y \mid X=x] \qquad \tag{1}
Explanation of how important is feature X_i
Bias in model M if X_i is a sensitive feature1
More generally, CF provide a natural way to debug ML models via
Why do we need CF Explanations?

Feature importance is not enough?
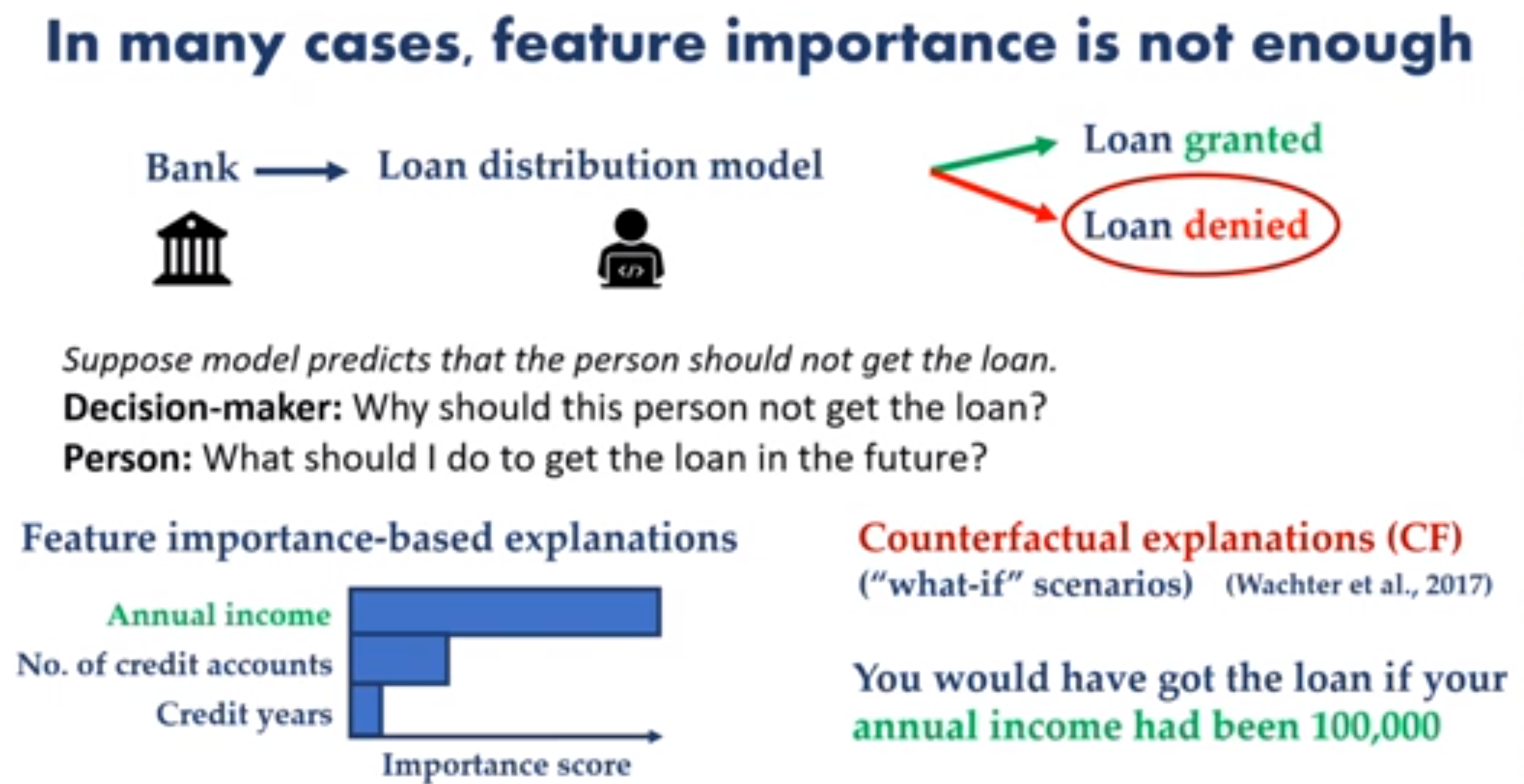
Suppose an ML model recommends that an individual should be denied a loan
🧑 Loan Officer : would like to understand why this individual was denied?
👳 Individual: would also like to know what she could do get the loan approved?
Sharma points out two shortcomings of traditional XAI methods
- Feature importance is inadequate to fully inform the stakeholders if it does not suggest a useful action.
- Feature importance can have low fidelity 😡
The top feature may mandate unrealistic changes.
e.g. “increase your income by 5x” 🙀
While the third Credit years and may not be on the path of least resistance to getting the loan.
e.g. “just wait three more years and you will be approved.” 👍
Desiderata for counterfactuals

- Actionalbility - Ceteris paribus a CFX should be actionable for the decision subject.
- Diversity - we want to understand different casual choices
- Proximity - the CFX should be similar to the “query” in the sense of a local explanation.
- User constraints - it should only suggest actions that can be performed by the user. A loan applicant cannot easily, become younger, change sex or get a degree.2
- Sparsity - a CFX should only require change a minimal set of features. i.e. a few small steps in two or three dimensions to cross the decision boundary.
- Casual constraints
- Going further it is suggested that we should view CFX as aggregating feasibility with diversity components
Before introducing his ideas Sharma references two prior works.
In the lengthy (Wachter, Mittelstadt, and Russell 2018), the authors suggest that to comply with GDPR regulations CFX should take the form:
Score p was returned because variables V had values (v_1,v_2,...) associated with them. If V instead had values (v_1',v_2',...), and all other variables had remained constant, then score p' would have been returned.
And and an approach to come up with suitable CFXs. Sharma references a formula:
C= \arg \min_c loss_y(f(c),y)+|x-c| \qquad \tag{2}
🏴 But this formula is not in the 📃 paper — perhaps it is a simplification of the idea.
🤔 I believe it suggests their recipe to generate desirable CFX by picking a change c in feature x with a minimal impact on y as measured by some loss function on outcome y.This approach is summarized in @molnar2022§9.3.1.1
In (Russell 2019) the author introduced a CFX algorithm based on mixed integer programming that supports diversity. However it is limited to linear ML models.
General Optimization framework

This is the simple framework used in DICE to generate diverse counterfactual explanations.
what is the easiest way to get CFX ?
if the model is differentialable and
if we have deep model we know gradient descent.
What have we have here ?
- we start with a mean of a Wachter type constraint
- this is being minimized.
- we add a proximity constraint weighted by hyper parameter \lambda_1
- this is being minimized.
- we add a diversity constraint weighted by hyper parameter \lambda_2
- this is being maximized.
- based on K some kind of metric for the distance for CFX distances.
Sharma considers this approach dated in lieu of more recent publications.
He references to other methods.
I think though he is talking about MOC which is based on multi-objective optimization problem, introduced in (Dandl et al. 2020) which the authors compare to DiCE (Mothilal, Sharma, and Tan 2020) Recourse from (Ustun, Spangher, and Liu 2019) and Tweaking from (Tolomei et al. 2017)
Diverse CFX
these can be used to inspect the black box model and understand what is going in there
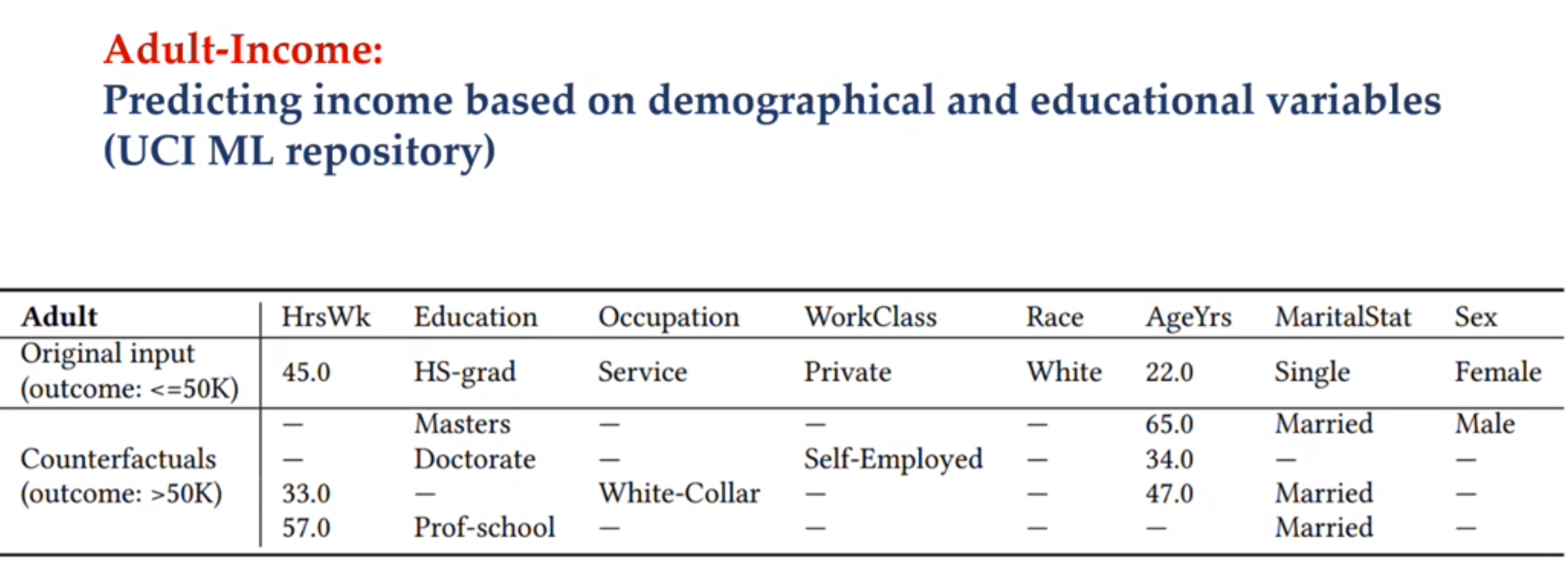
Generating debugging edge-cases

Quantitative Evaluation for CFX
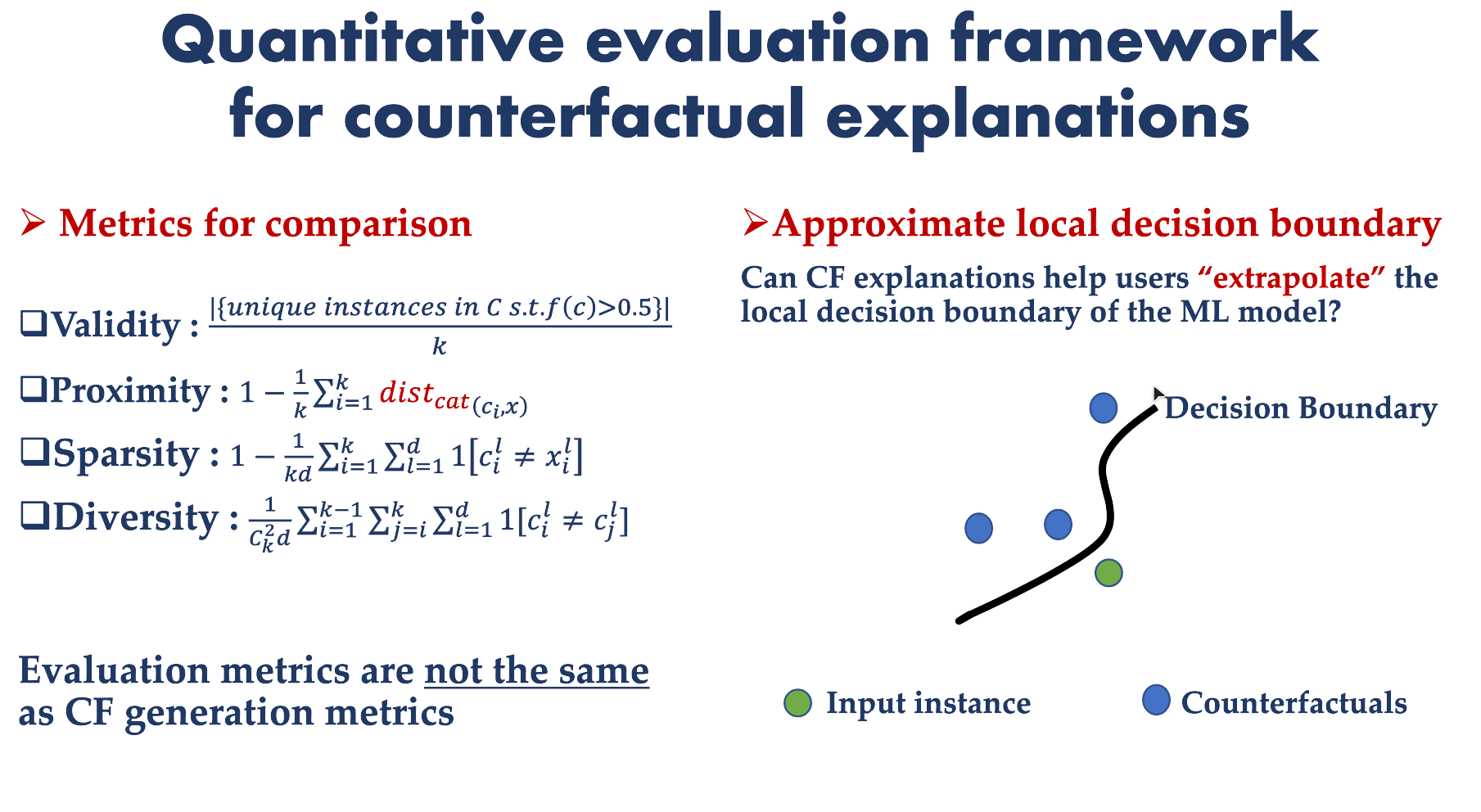
This is how we translate the desiderata into a formal model using metrics.
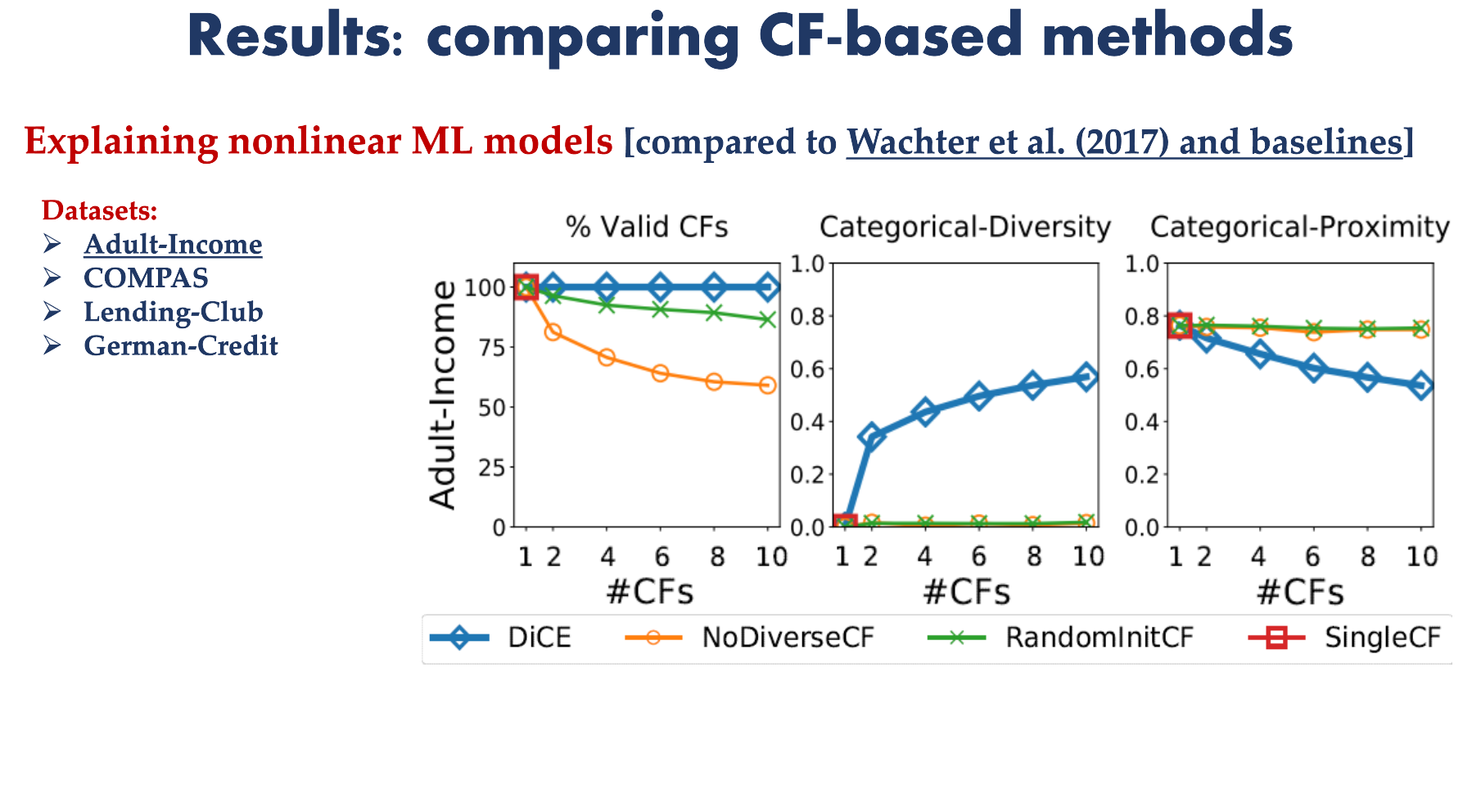
How does DiCE compare with LIME and SHAP
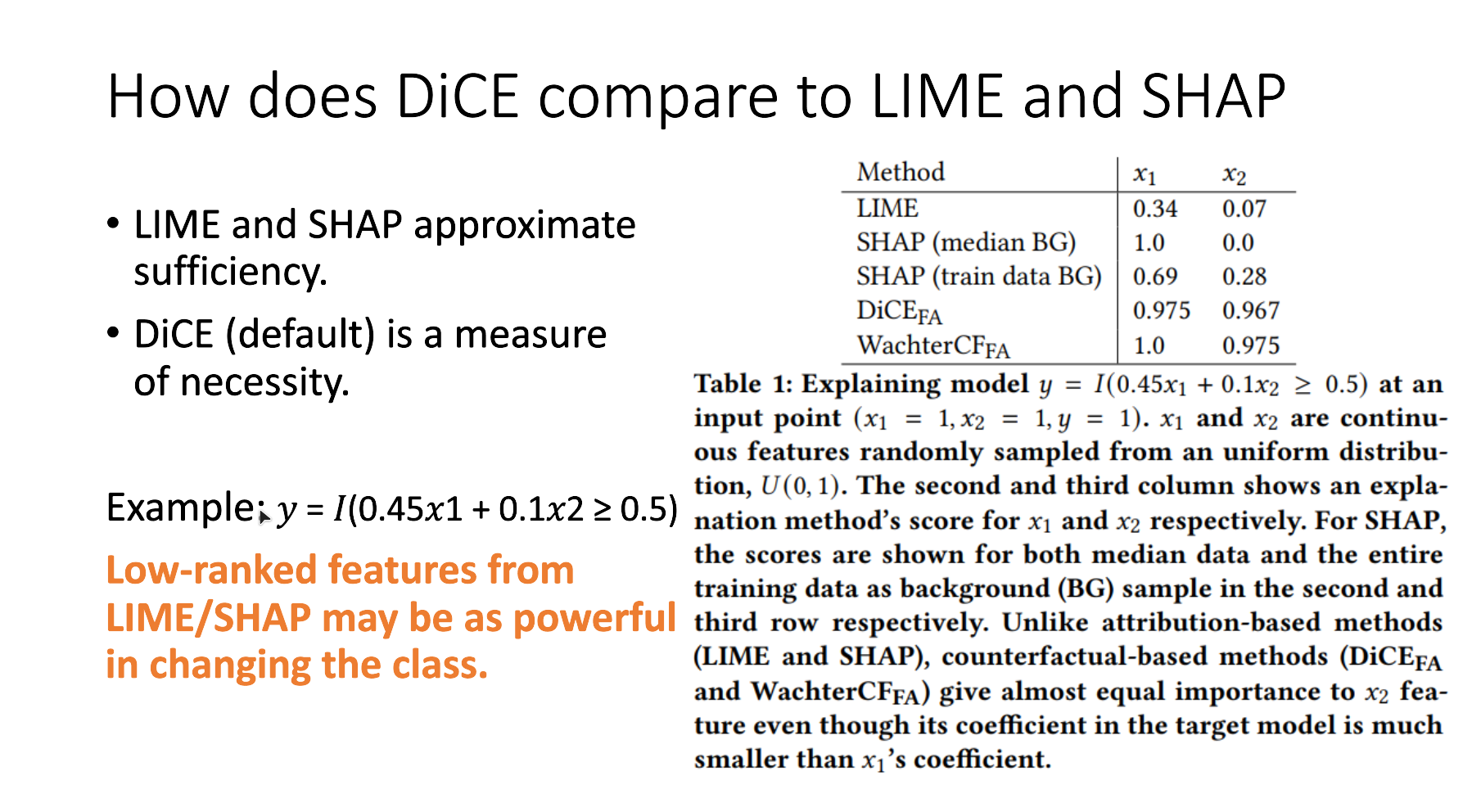
The results section from the DiCE paper!
Practical considerations

Returning to the optimization problem

How to Generate a CF for a ML model

Conclusion
| Data | Name | Citation | Python | R |
|---|---|---|---|---|
| Tabular | DoWhy | (Sharma and Kiciman 2020a) (Blöbaum et al. 2022) |
pywhy | |
| Tabular | DiCE | (Mothilal, Sharma, and Tan 2020) | github | |
| Tabular | MOC | (Dandl et al. 2020) | github | |
| Tabular | Recourse | (Ustun, Spangher, and Liu 2019) | ||
| Tabular | Tweaking | (Tolomei et al. 2017) | ||
| Text | Checklist | (Ribeiro et al. 2020) | checklist | |
| Text | Litmus | litmus | ||
| Image | CF-CLIP | (Yu et al. 2022) | CF-CLIP |
Conclusion

Resources:
- DoWhy is a Python library for causal inference that supports explicit modeling and testing of causal assumptions. DoWhy is based on a unified language for causal inference, combining causal graphical models and potential outcomes frameworks. Microsoft Research Blog | Video Tutorial | (Sharma and Kiciman 2020b) | (Blöbaum et al. 2022) | Slides
Action Items:
- Once again I want to put some JSON-LD data as a Knowledge Graph into this article but I don’t have the tools to do it with.
- collect the people’s info using a headless CMS like sanity or blazegraph
- store the data on the papers using bibtex
- use the YAML metadata with categories
- some ontology for concepts and conferences
- write a sequence of queries
- visualize and interact with the output of the queries
- Try out DiCE notbook
- Try out DoWhy notebook
- Review the papers
- Consider:
- how can we use MCMC + XCF to generate useful examples for debugging our model.
References
Footnotes
Reuse
Citation
@online{bochman2023,
author = {Bochman, Oren},
title = {4 {Counterfactual} {Explanations} - {Explaining} and
{Debugging}},
date = {2023-03-23},
url = {https://orenbochman.github.io/notes/XAI/l04/Counterfactual-Explanations.html},
langid = {en}
}