import gymnasium as gym
from gymnasium import spaces
import numpy as np
class RandomWalk1000(gym.Env):
def __init__(self, num_states=1000, neighborhood_size=100, seed=None):
super().__init__()
self.num_states = num_states
self.neighborhood_size = neighborhood_size
self.observation_space = spaces.Discrete(num_states + 2) # add two states 0 and num_states + 1 as terminal states
self.action_space = spaces.Discrete(2) # 0 for left, 1 for right
self.current_state = 500 # start in the middle
self.np_random, seed = gym.utils.seeding.np_random(seed)
self.trajectory = [500]
def reset(self, *, seed=None, options=None):
super().reset(seed=seed)
self.current_state = 500
self.trajectory = [500]
return self.current_state, {}
def step(self, action):
if action == 0: # move left
# left neighbours
left_start = max(1, self.current_state - self.neighborhood_size)
left_end = self.current_state
num_left = left_end - left_start
if left_start == 1:
prob_terminate_left = (self.neighborhood_size - num_left) / self.neighborhood_size
else:
prob_terminate_left = 0
if self.np_random.random() < prob_terminate_left:
return 0, -1, True, False, {} # terminate left
next_state = self.np_random.integers(low=left_start, high=left_end)
elif action == 1: # move right
# right neighbours
right_start = self.current_state + 1
right_end = min(self.num_states + 1, self.current_state + self.neighborhood_size + 1)
num_right = right_end - right_start
if right_end == self.num_states + 1:
prob_terminate_right = (self.neighborhood_size - num_right) / self.neighborhood_size
else:
prob_terminate_right = 0
if self.np_random.random() < prob_terminate_right:
return self.num_states + 1, 1, True, False, {} # terminate right
next_state = self.np_random.integers(low=right_start, high=right_end)
else:
raise ValueError("Invalid action")
self.current_state = next_state
self.trajectory.append(self.current_state)
return self.current_state, 0, False, False, {} # not terminated or truncated
import matplotlib.pyplot as plt
def plot_trajectory(trajectory, num_states):
"""Plots the trajectory of the random walk."""
x = np.arange(len(trajectory))
y = np.array(trajectory)
plt.figure(figsize=(12, 4))
plt.plot(x, y, marker='o', linestyle='-', markersize=3)
plt.xlabel('Time Step')
plt.ylabel('State')
plt.title('Random Walk Trajectory')
plt.yticks(np.arange(0, num_states+2, 100))
plt.grid(axis='y')
plt.tight_layout()
plt.show()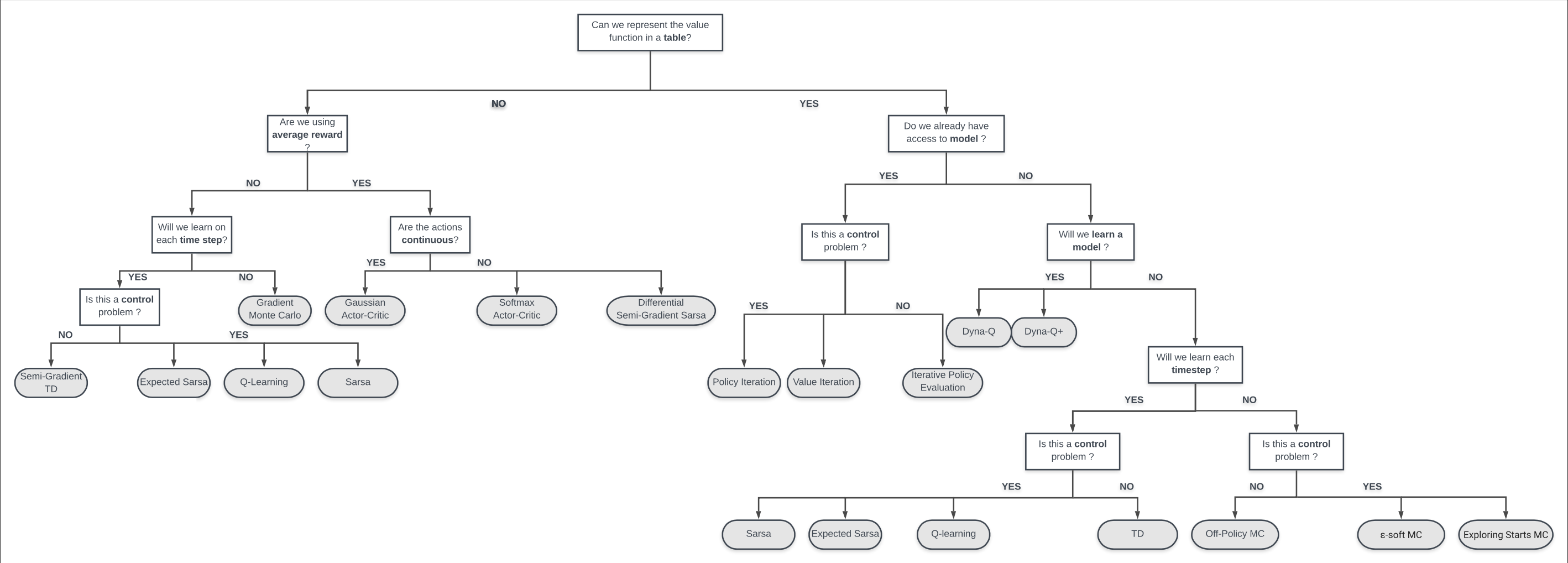
Introduction
Readings
This is not a video lecture or notes for a learning goal. This is however my attempts to cover some material from the readings from chapter 9 of (Sutton and Barto 2018) mentioned above.
I’ve added this material about a year after completing the specialization as I have been taking a course on deep reinforcement learning. I had felt that the material in this course had been both challenging on occasion and rather basic on others.
What I felt was that I was not happy about the basics in this chapter. This includes the parameterization of the value function, the convergence results regarding linear function approximation. The ideas about why TD is a semi-gradient method etc.
I am also having many idea about both creating algorithms for creating features for RL environments. As I get familiar with gridwolds, atari games, sokoban etc I had many good ideas for making progress in both these environments and for improving algorithms for more general cases.
For example it appears that in many papers it turns out the agents are not learning very basic abilities. My DQN agent for space invaders was very poor at shooting bullets. I had an few ideas that should make a big difference. Like adding features for bullets, the invaders and so on. This are kind of challenging to implement in the current gymnasium environments. However I soon had a much more interesting idea that seems to be good for many of the atari environments and quite possibly even more broadly to most cnn based agents.
- In brief this would combine
- a multiframe YOLO,
- a generelised value function to replace YOLO’s supervision
- a ‘robust’ causal attention mechanism to decide which pixels are more or less important
- dropping them would not impact performance. e.g. bullets
- which affect survival e.g. certain bullets
- for scoring e.g. mother ship
- which ones we can influence e.g. standing under an invader gets it to shoot at us.
Note this is not the causal attention mechanism from NLP where one censored the future inputs but rather a mechanism that decides which pixels represent features that are potentialy the cause of the future states.
Clearly this Algorithm and its parts need to be worked out in a very simple environment. The YOLO part is all about modeling features using bounding boxes via a single pass. The GVFs are to replace yolo supervision loss with a RL compatible loss and the causal attention to reduce the overfitting and speed up learning.
I decided that converting some of these simple environments to gymnasium environments would be a good way to kick start some of these ideas, more so as reviewing papers and talks by Adam and Martha White shows that most experiments in RL environments turn out to be too complicated and access to simple environments turns out to be the way to get the experiments started.
In this chapter we use a simple environment called the 1000 state Random walk. I implemented this independently in Python.
We also learned the MC prediction algorithm and the TD(0) algorithms for function approximation.
We will use these algorithms to learn the value function of the Random Walk 1000 environment. We will also use tile coding and coarse coding to create features for the Random Walk 1000 environment.
Feature Construction & linear Function approximation
Learning Objectives
In this module we consider environments that allow to consider simple state aggregationI’d like to cover the following topics:
-
- This will allow to use it with many RL agents built using many libraries.
-
- This environment can be a basis for looking at how Temporal Abstraction aggregation play with function approximation in a highly simplified form.
- This is a fundamental issue that Doina Precup has raised in her talks as an ongoing area of research.
- So such an environment might be useful in testing how different approaches can handle these issues in an environment that is very close to supervised learning.
- implement Gradient MC agent
- implement Semi Gradient TD(0) agent
- use these agents with and without state aggregation to learn the value function of the Random Walk 1000 environment.
- implement coarse coding via tile coding to create features for the Random Walk 1000 environment.
- implement use of polynomial features to create features for the Random Walk 1000 environment.
- implement use of radial basis functions to create features for the Random Walk 1000 environment.
- implement use of Fourier basis functions to create features for the Random Walk 1000 environment.
The 1000 Step Random Walk Environment
In this lesson we implement the 1000 Random Walk example as an environment. This is good to demonstrate how to construct features for linear methods. We will use tile coding and coarse coding to create features for the Random Walk 1000 environment.
#import gymnasium as gym
#from random_walk_gym import RandomWalk1000
env = RandomWalk1000()
# Reset the env
obs, info = env.reset()
terminated = False
while not terminated:
# For this environment, an action is not needed.
# Here we pass in a dummy value
obs, reward, terminated, truncated, info = env.step(0)
print(f"State: {obs + 1}, Reward: {reward}, Terminated: {terminated}")
env.close()
plot_trajectory(env.trajectory, num_states=env.num_states)State: 444, Reward: 0, Terminated: False
State: 379, Reward: 0, Terminated: False
State: 287, Reward: 0, Terminated: False
State: 265, Reward: 0, Terminated: False
State: 251, Reward: 0, Terminated: False
State: 187, Reward: 0, Terminated: False
State: 95, Reward: 0, Terminated: False
State: 62, Reward: 0, Terminated: False
State: 1, Reward: -1, Terminated: True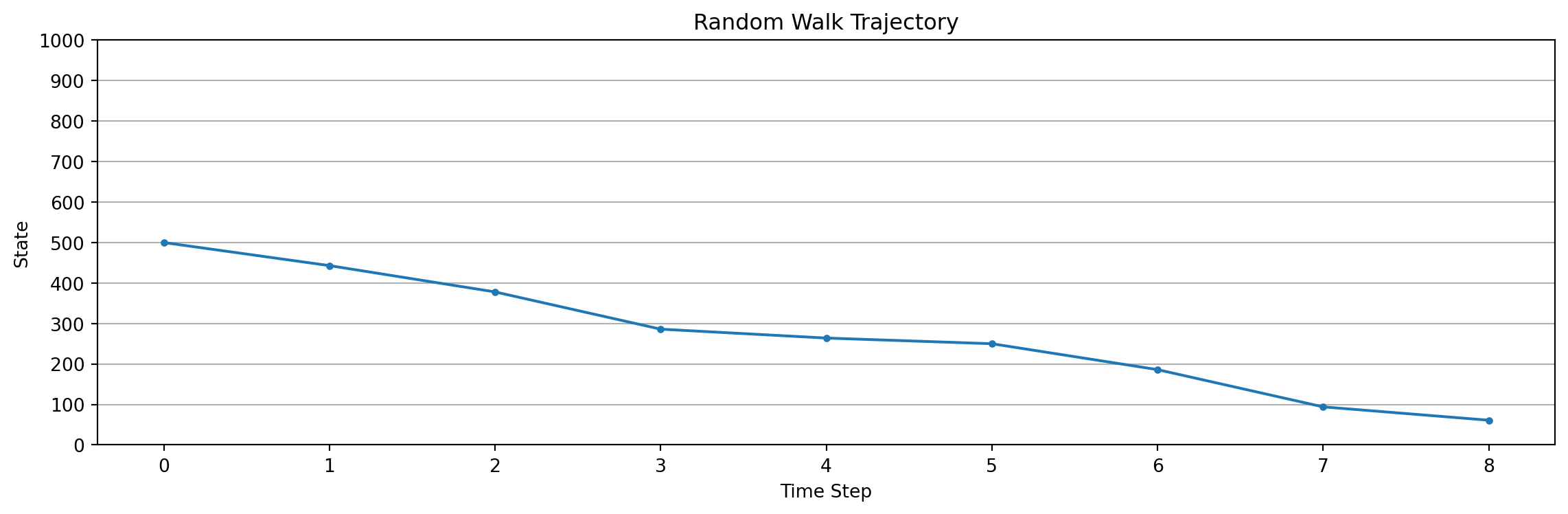
env = RandomWalk1000(num_states=1000, neighborhood_size=100)
obs, info = env.reset()
terminated = False
truncated = False
trajectory = []
while not terminated and not truncated:
action = env.action_space.sample() # Replace with your policy
obs, reward, terminated, truncated, info = env.step(action)
print(f'{obs=}, {action=}, {reward=}, {terminated=}')
plot_trajectory(env.trajectory, num_states=env.num_states)obs=440, action=0, reward=0, terminated=False
obs=503, action=1, reward=0, terminated=False
obs=521, action=1, reward=0, terminated=False
obs=448, action=0, reward=0, terminated=False
obs=435, action=0, reward=0, terminated=False
obs=531, action=1, reward=0, terminated=False
obs=512, action=0, reward=0, terminated=False
obs=474, action=0, reward=0, terminated=False
obs=556, action=1, reward=0, terminated=False
obs=507, action=0, reward=0, terminated=False
obs=433, action=0, reward=0, terminated=False
obs=469, action=1, reward=0, terminated=False
obs=410, action=0, reward=0, terminated=False
obs=311, action=0, reward=0, terminated=False
obs=299, action=0, reward=0, terminated=False
obs=358, action=1, reward=0, terminated=False
obs=385, action=1, reward=0, terminated=False
obs=390, action=1, reward=0, terminated=False
obs=485, action=1, reward=0, terminated=False
obs=492, action=1, reward=0, terminated=False
obs=556, action=1, reward=0, terminated=False
obs=631, action=1, reward=0, terminated=False
obs=627, action=0, reward=0, terminated=False
obs=652, action=1, reward=0, terminated=False
obs=696, action=1, reward=0, terminated=False
obs=756, action=1, reward=0, terminated=False
obs=828, action=1, reward=0, terminated=False
obs=846, action=1, reward=0, terminated=False
obs=772, action=0, reward=0, terminated=False
obs=693, action=0, reward=0, terminated=False
obs=680, action=0, reward=0, terminated=False
obs=748, action=1, reward=0, terminated=False
obs=756, action=1, reward=0, terminated=False
obs=755, action=0, reward=0, terminated=False
obs=793, action=1, reward=0, terminated=False
obs=798, action=1, reward=0, terminated=False
obs=871, action=1, reward=0, terminated=False
obs=945, action=1, reward=0, terminated=False
obs=849, action=0, reward=0, terminated=False
obs=891, action=1, reward=0, terminated=False
obs=850, action=0, reward=0, terminated=False
obs=778, action=0, reward=0, terminated=False
obs=720, action=0, reward=0, terminated=False
obs=773, action=1, reward=0, terminated=False
obs=856, action=1, reward=0, terminated=False
obs=937, action=1, reward=0, terminated=False
obs=984, action=1, reward=0, terminated=False
obs=947, action=0, reward=0, terminated=False
obs=983, action=1, reward=0, terminated=False
obs=971, action=0, reward=0, terminated=False
obs=946, action=0, reward=0, terminated=False
obs=1001, action=1, reward=1, terminated=True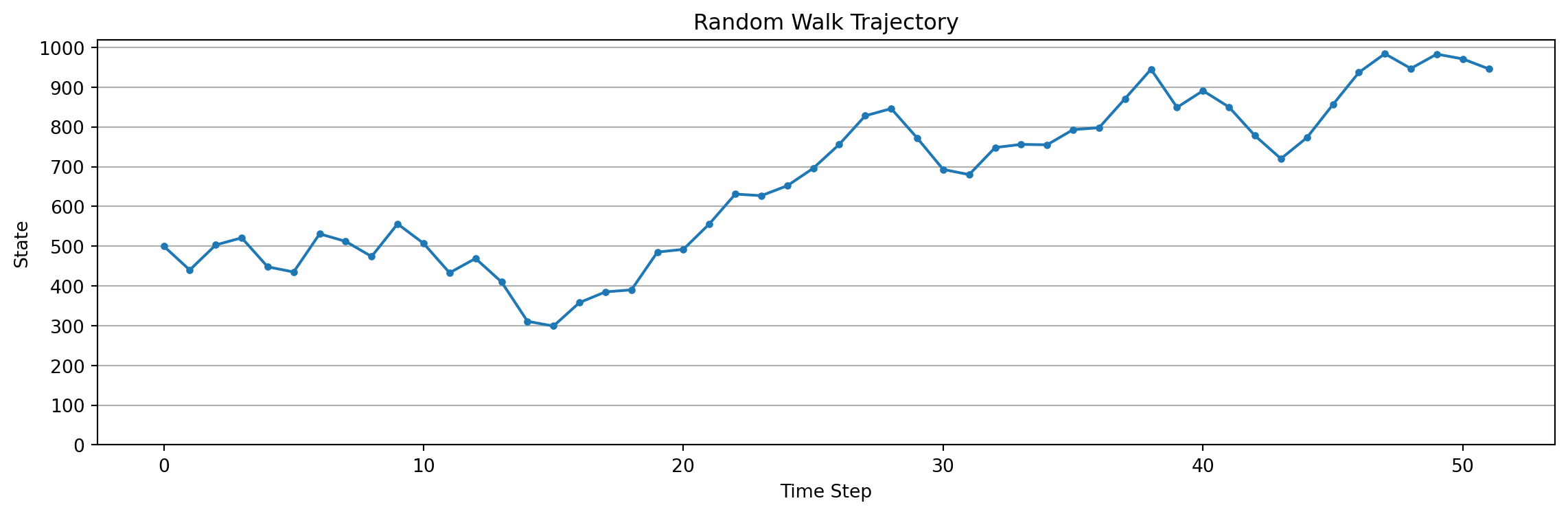
Lets simulate the random walk till success and plot its trajectory.
env = RandomWalk1000(num_states=1000, neighborhood_size=100)
obs, info = env.reset()
terminated = False
truncated = False
while not terminated and not truncated:
action = env.action_space.sample() # Replace with your policy
obs, reward, terminated, truncated, info = env.step(action)
plot_trajectory(env.trajectory, num_states=env.num_states)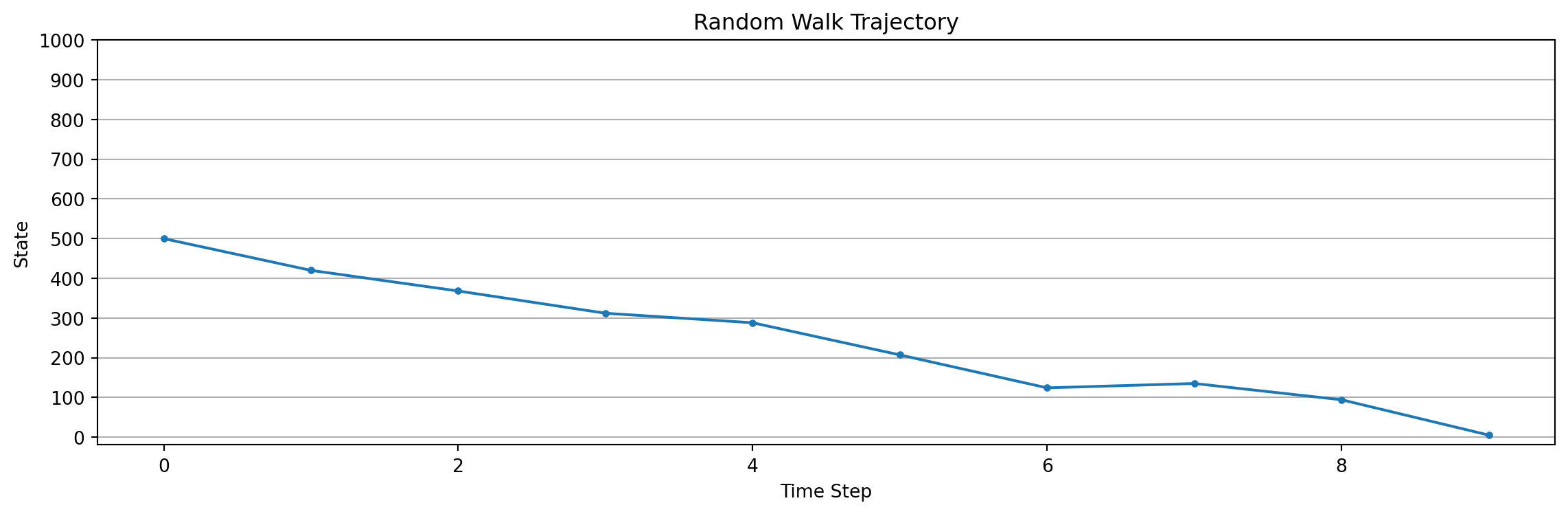
References
Sutton, R. S., and A. G. Barto. 2018. Reinforcement Learning, Second Edition: An Introduction. Adaptive Computation and Machine Learning Series. MIT Press. http://incompleteideas.net/book/RLbook2020.pdf.
Reuse
CC SA BY-NC-ND
Citation
BibTeX citation:
@online{bochman2024,
author = {Bochman, Oren},
title = {Constructing {Features} for {Prediction}},
date = {2024-04-02},
url = {https://orenbochman.github.io/notes/RL/c3-w2.1.html},
langid = {en}
}
For attribution, please cite this work as:
Bochman, Oren. 2024. “Constructing Features for
Prediction.” April 2, 2024. https://orenbochman.github.io/notes/RL/c3-w2.1.html.