![]()
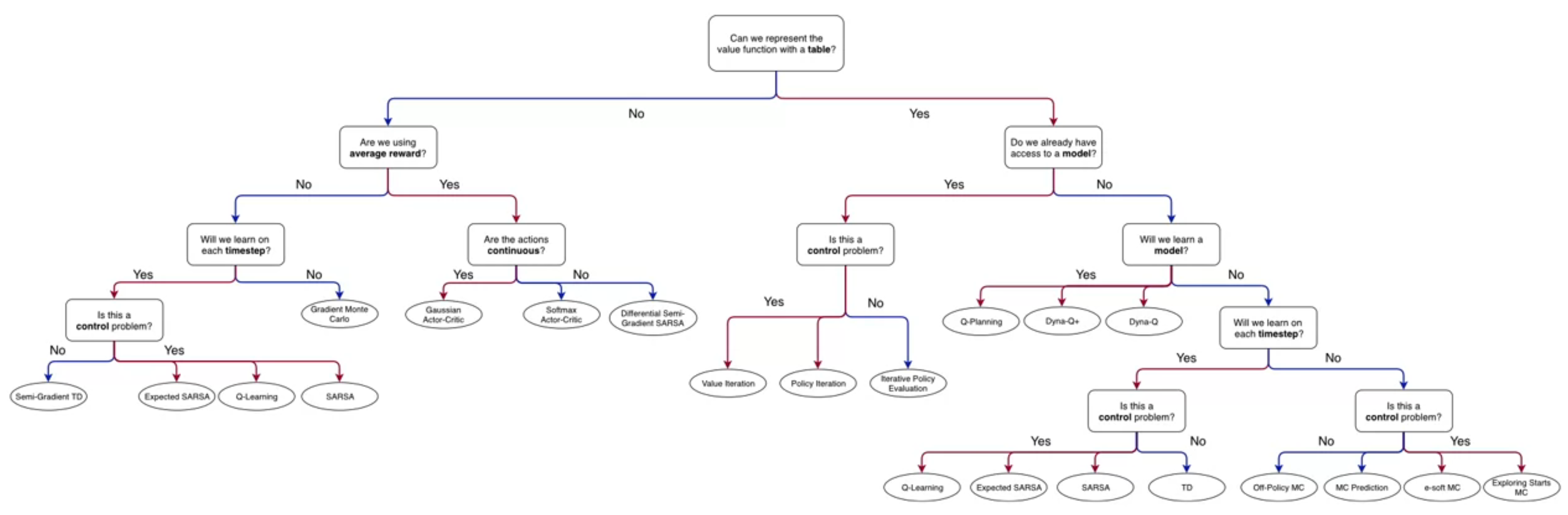
Some of the notes I made in this course became a bit too long. Rather than break the flow of the lesson I decided to move them to a separate file. This is one of those notes.
A few Thought on Generalization and discrimination in RL
There are a couple of issues on generalization.
Human like to use Heuristic, which are are:
- A minimal sub-optimal policy that is suffiecnt to get the agent to its goal with high probability.
- In an MDP with lots of sub-goals, we may have benefit in learning learning heuristic style policy for each sub-goal and then compose them into a policy for the goal.
- Composing heuristics is vague so let try make it clear.
- We want to follow the heuristic policy until we reach a sub-goal.
- We then switch to the policy for the next sub-goal.
- If we have well established entry and exit points for each heuristic we can have two benefits one is generalization and the other is discrimination.
- Generalization is due to using the same heuristic from different starting points.
- Discrimination is due to having different heuristics for different sub-goals.
- A third advantage is that the heuristic policy is for a smaller state space and can be learned faster.
- Third advantage is may be that of mapping different sub-problem to the same heuristic may allow us to discard some of the features of the state space that are not required for the heuristic to work.
- Thus composing heuristics in this case is just about switching between heuristics at the right time.
- Another direction is to use the heuristics as a form of priors for the policy we want to learn.
- Simple models are often a good fit for more problems than complex models.
- If we are good at learning to decompose problems into simpler sub problems and then we might be able to leverage the power of heuristics.
- Heuristics don't always work but overall they capture the essence of the solution to the problem.
- Heuristics are usually more general than an optimal policy.
- A heuristic might be a very good behavior policy for off policy learning the optimal policy.
- I don't see RL algorithms for heuristics.Models in RL try to approximate MDP dynamics using its transition and rewards
- In ML we often use boosting and bagging to aggregate very simple models.
- In RL we often replace the model by sampling from a replay buffer of the agent's past experiences. The problem for a general ai is very much the problem of transfer learning in RL.
- agents learn a very specific policy for a very specific task - the learned representation cannot be mapped to other tasks or even other states in the same task.
- if agents learning was decomposed into
- learning very general policies that solved more abstract problems and then
- learning a good composition of these policies to solve the specific problem.
- only after getting to this point would the agent try to optimize the policy for the specific task.
- e.g. chess
- learn the basic moves and average value of pieces
- learning tactics - short term goals
- learning about end game
- update the value of pieces based on the ending
- learning about strategy
- positional play
- learn about pawn formations and weak square
- value of pawn formations
- how they can be used with learned tactics.
- the center
- add value to pieces based on their position on the board
- open files and diagonals
- learn about pawn formations and weak square
- long term plans
- minority attack, king side attack, central breakthrough
- creating a passed pawn
- exchanging to win in the end game
- sacrificing material to get a better position
- attacking the king
- castling
- piece development and the center
- tempo
- positional play
- localize value of pieces in different positions on the board using the learned tactics and strategy.
Bayesian models and hierarchical model encode knowledge using priors which can pool or bias beliefs towards a certain outcome.
- learning in Bayesian models is about updating the initial beliefs based on incoming evidence.CI may be useful here
- Is in a big way about mapping knowledge into
- Statistical joint probabilities,
- Casual concepts that are not in the joint distributions like interventions and Contrafactuals, latent, missing, mediators, confounders, etc.
- Hypothesizing a causal structural model, deriving a statistical model and Testing it against the data.
- Interventions in the form of actions and options -
- Many key ideas in RL are counterfactual reasoning
- Off-policy learning is about learning from data generated by a different policy.
- Options are like do operations (interventions)
- Choosing between actions and options is like contrafactual reasoning.
- Using and verifying CI models could be the way to unify the spatial and temporal abstraction in RL.
Reuse
CC SA BY-NC-ND
Citation
BibTeX citation:
@online{bochman2024,
author = {Bochman, Oren},
title = {On-Policy {Prediction} with {Approximation}},
date = {2024-04-01},
url = {https://orenbochman.github.io/notes/RL/c3-w1.1.html},
langid = {en}
}
For attribution, please cite this work as:
Bochman, Oren. 2024. “On-Policy Prediction with
Approximation.” April 1, 2024. https://orenbochman.github.io/notes/RL/c3-w1.1.html.