![]()
Lesson 1: Introduction to Markov Decision Processes
Before I started this course I viewed (Silver 2015) online course by David Silver who in many ways is the face of RL. He is also the lead of the AlphaGo project, a principal researcher at DeepMind and a lecturer at University College London. Silver is also featured in one of the Lectures in this specialization. In his course he develops the MDP constructively starting with simpler structures as is often done in mathematics. I find this is a good way to learn how to think about how we generalize and specialize from more abstract to more concrete structures.
Many students of probability theory will be familiar with Markov Chains. And Markov Decision Processes are a generalization of Markov Chains.
In (Silver 2015) he begins with a Markov Process, with states and transitions probabilities, by adding rewards he constructs a Markov reward process. Then by adding actions he constructs a Markov decision process. He explains these and in the notes covers three additional extensions. In the the notes he also add the following MDP extensions:
- Infinite and continuous MDPs - the case of optimal control
- Partially observable MDPs.
- Undiscounted, average reward MDPs.
- David Silver’s 2015 UCL Course Video and Slides.
Markov Process
Silver goes into some detail on what we mean by state in RL:
- In th abstract state can be any function of the history.
- The state should summarize the information on the previous actions, and rewards.
- He points out that the history in RL can be very long, for Atari games it can include actions plus all the pixels for every screen in many plays of the game. In contrast the state tries to capture the bare essentials of the history for decision making at each time step. For Atari games they used the last 4 screens as the state.
- A second point is that there is always a state. The full history is also a state, but not a very useful one. The internal representation of the ram in the Atari game is also a state, much smaller but this is the representation used by the environment and contains more information than is available to the agent. Ideally the agent would want to model this state, but again it contains lots more information than is available would need to male a decision.
- Another useful property of the state is that it should have the Markov Property for a state space which is when the future is independent of the past given the present.
A state S_t is Markov if and only if:
\mathbb{P}[S_{t+1} \vert S_{t}] = \mathbb{P}[S_{t+1} \vert S_1,...,S_t] \qquad \text{(Markov Property)} \tag{1}
The state captures all relevant information from the history Once the state is known, the history may be thrown away i.e. The state is a sufficient statistic of the future
Recall:
a statistic satisfies the criterion for sufficency when no other statistic that can be calculated from the same sample provides any additional information as to the value of the parameter”. — (Fisher and Russell 1922)
For a Markov state s and successor state s', the state transition probability is defined by:
\mathbb{P}_{ss'} = \mathbb{P}[S_{t+1}=s' \vert S_t=s]
- A Markov Process is
-
a tuple ⟨S,P⟩
where:
- S is a (finite) set of states
- P is a state transition probability matrix, P_{ss'} = P[S_{t+1} = s' \vert S_t=s] State transition matrix P_{ss'} defines transition probabilities from all states s to all successor states s',
\begin{align*} P=\left( \begin{array}{cc} p_{11} & \cdots & p_{1n} \newline \vdots & \ddots & \vdots \newline p_{n1} & \cdots & p_{nn} \end{array} \right) \end{align*} \tag{2}
Markov Reward Process
A Markov Reward Process (MRP) is a Markov chain with values.
- A Markov Reward Process is
-
a tuple ⟨S, P, R, \gamma⟩
where:
- S is a finite set of states
- P is a state transition probability matrix, where P_{ss'} = \mathbb{P}[S_{t+1} = s' \vert S_t = s]
- R is a reward function, R_s = \mathbb{E}[R_{t+1} \vert S_t = s]
- \gamma is a discount factor, \gamma \in [0, 1]
- The return G_t
-
is the total discounted reward from time-step t.
G_t =R_{t+1}+\gamma R_{t+2}+...=\sum_{k=0}^{\infty} \gamma^k R_{t+k+1} \tag{3}
where:
- R_t is the reward at time-step t
- \gamma the discount factor \gamma \in [0, 1] is the present value of future rewards.
- The value of receiving reward R after k+1 time-steps is \gamma^k R
- This values immediate reward above delayed reward.
- \gamma = 0 makes the agent short-sighted.
- \gamma = 1 makes the agent far-sighted.
- The value function:
-
The state value function v(s) of an MRP is the expected return starting from state s
v(s) =\mathbb{E} [G_t \vert S_t = s]
Bellman equations for MRP
The value function can be decomposed into two parts:
- an immediate reward R_{t+1} and
- a discounted value of successor state \gamma v(S_{t+1})
The Bellman equation for MRPs expresses this relationship:
\begin{align*} v(s) &= \mathbb{E}[G_t \vert S_t=s] \newline & = \mathbb{E}[R_{t+1} + \gamma R_{t+2}+\gamma^2 R_{t+3} + ... \vert S_t = s] \newline & = \mathbb{E}[R_{t+1} + \gamma( R_{t+2}+\gamma^2 R_{t+3} + ... ) \vert S_t = s] \newline & = \mathbb{E}[R_{t+1} + \gamma G_{t+1} \vert S_t = s] \newline & = \mathbb{E}[R_{t+1} + \gamma v(S_{t+1}) \vert S_t = s] \end{align*} \qquad \text{(Bellman Equation)} \tag{4}
The Bellman equation can also be expressed in terms of the dynamics matrix for state transitions:
v(s) = R_s + γ \sum_{s'\in S} P_{ss'}v(s) \qquad \text{value with dynamics} \tag{5}
where we use the dynamics matrix P to express the expected value of the successor state.
Markov Decision Processes
- The k-Armed Bandit problem does not account for the fact that different situations call for different actions.
- Because it the problem is limited to a single state agents can only make decisions based on immediate reward so they fail to consider the long-term impact of their decisions - this is an inability to make plan.
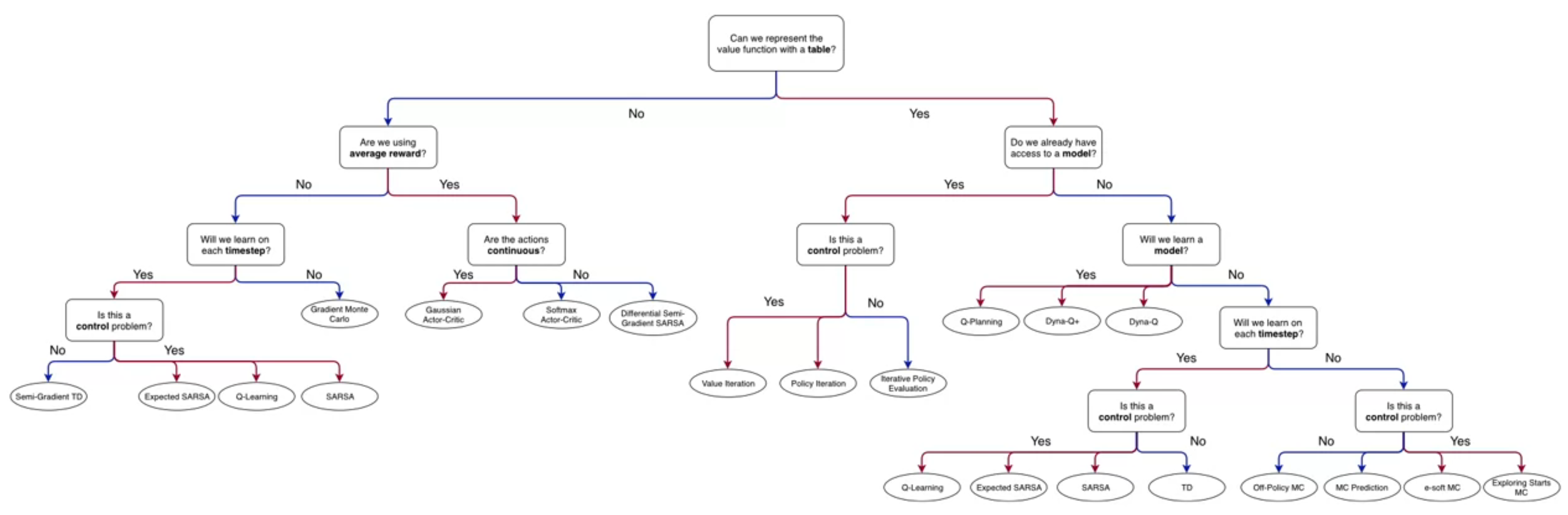
- A Markov Decision Process is a Markov Reward Process with decisions.
-
a tuple ⟨S, A, P, R, \gamma⟩
where:
- S is a finite set of states
- A is a finite set of actions
- P is a state transition probability matrix, P_{ss'}^a = \mathbb{P}[S_{t+1} = s' \vert S_t = s, A_t = a]
- R is a reward function, R_s^a = \mathbb{E}[R_{t+1} \vert S_t = s, A_t = a]
- \gamma is a discount factor, \gamma \in [0, 1]
The dynamics of an MDP
In a finite MDP, the sets of states, actions, and rewards (S, A and R) all have a finite number of elements. In this case, the random variables S_t and R_t have well defined discrete probability distributions dependent only on the preceding state and action.
The dynamics of an MDP are defined by the four argument dynamics function:
p(s',r \vert s,a)\ \dot =\ Pr\{S_t = s', R_t = r \vert S_{t-1} = s, A_{t-1} = a\}\qquad \forall s',s \in S\ \forall r\in R\ \forall a\in A \tag{6}
where the sum of the probabilities over fixed set of s,a is 1:
\sum_{s' \in S} \sum_{r \in R} p(s',r \vert s,a) = 1 \qquad \forall s \in S, \forall a \in A \qquad \text{(Dynamics function)} \tag{7}
This is just a regular function that takes a state and action and returns a probability distribution over the next state and reward.
In a tabular setting, we can also express this function as a table. Here is my solution for ex 3.4, a table for the recycling robot
| s | a | s' | r | p(s',r \mid s,a) |
|---|---|---|---|---|
| high | search | high | r_{search} | \alpha |
| high | search | low | r_{search} | 1-\alpha |
| low | search | high | -3 | 1-\beta |
| low | search | low | r_{search} | \beta |
| high | wait | high | r_{wait} | 1 |
| low | wait | low | r_{wait} | 1 |
| low | recharge | high | 0 | 1 |
a couple of takeaways from this exercise are:
rewards are uniquely assigned for action at s resulting in s’ so we don’t need to make r another factor (i.e. list all possible rewards for (s,a,s’) tuple.
there are (s,a,s’,r) tuples for which we don’t have a non-zero probabilities - since there are no transition possible.
e.g. the robot wont charge when high, so there isn’t a transition from that state, nor a reward, nor a probability.
Graphical representation of an MDP
The graphical representation of an MDP is a directed graph where the nodes represent states and the edges represent actions. The graph is labeled with the probabilities of transitioning from one state to another given an action.
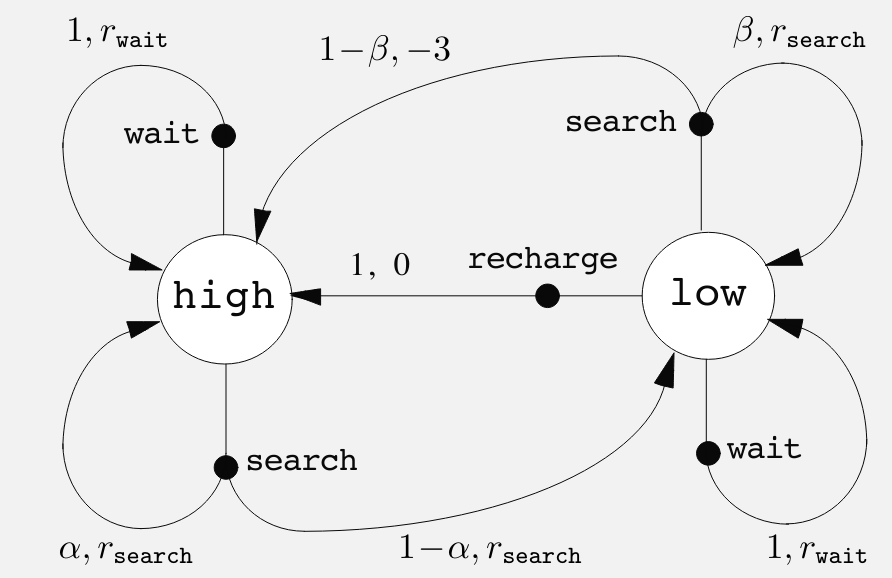
In an MDP, the probabilities given by four part dynamics function completely characterize the environment’s dynamics.
That is, the probability of each possible value for S_{t+1} and R_{t+1} depends only on the immediately preceding state S_t and action A_t.
This is best viewed a restriction not on the decision process, but on the state.
The state must include information about all aspects of the past agent–environment interaction that make a difference for the future.
If it does, then the state is said to have the Markov property.
We can use the four-part dynamics function to compute the state transition probabilities for a given state and action:
\begin{align} p(s' \vert s,a) &= \mathbb{P}[S_t = s'\vert S_{t-1} = s, A_{t-1} = a] \newline &= \sum_{r \in R} p(s',r \vert s,a) \qquad \text{(state transition p)} \end{align} \tag{8}
where we summed over all possible rewards to get the state transition probability.
We can use the four-part dynamics function to compute the expected rewards for a given state and action:
\begin{align} r(s,a) &= \mathbb{E}[R_t \vert S_{t-1} = s, A_{t-1} = a] \newline &= \sum_{r \in R} r \times \sum_{s' \in S} p(s', r, \vert s, a) \end{align} \tag{9}
where we summed over all possible rewards and all successor state to get the expected reward.
We can also get the expected reward for a given state, action, and successor state using the four-part dynamics function:
\begin{align} r(s,a,s') &= \mathbb{E}[R_t \vert S_{t-1} = s, A_{t-1} = a, S_t = s'] \newline &= \sum_{r \in R} r \times \frac { p(s', r \vert s, a) } { p(s' \vert s, a) } \end{align} \tag{10}
where we summed over all possible rewards to get the expected reward.
Note: perhaps implementing these in python might be further clarify the math for a given state transition graph.
Lesson 2: Goal of Reinforcement Learning
Rewards and the Goal of an Agent
The agent interacts with the environment by taking actions and receiving rewards.
In the bandit setting, it is enough to maximize immediate rewards. In the MDP setting, the agent must consider the long-term consequences of its actions.
return G_t is the total future reward from time-step t.
G_t \dot= R_{t+1} + R_{t+2} + R_{t+3} + \ldots
- G_t is a random variable because both transition and the rewards can be stochastic.
The goal of an agent is to maximize the expected cumulative reward.
That all of what we mean by goals and purposes can be well thought of as the maximization of the expected value of the cumulative sum of a received scalar signal (called reward).
see (Silver et al. 2021)
some basic formulations of the goal of an agent:
- Maze runner: -1 for each time step until the goal is reached, then 0.
- Recycling robot: +1 per can, 0 otherwise.
- Chess: 1 for a win, 0 for a draw, -1 for a loss.
Note there is more material on this subject in the guest lecture by Michael Littman.
Episodes and Episodic Tasks
An episode is a sequence of states, actions, and rewards that ends in a terminal state. An episodic task is a task with a well-defined terminal state.
An example of an episodic task is a game of chess, where the game ends when one player wins or the game is a draw. The opposite setting of an episodic task is a continuing task, where the agent interacts with the environment indefinitely.
Guest Lecture: Michael Littman: The Reward Hypothesis
Littman is a professor at Brown University and a leading researcher in reinforcement learning. He is known for his work on the reward hypothesis and the exploration-exploitation trade-off. He motivates the reward hypothesis with a humorous take on the old adage:
- Give a man a fish and he’ll eat for a day - traditional programming
- Teach a man to fish and he’ll eat for a lifetime - supervised learning
- Give a man a need for fish and he’ll figure it out - reinforcement learning
I felt that the guest lecture was a bit of a let down. I was expecting more from a leading researcher in the field. The reward hypothesis is a fundamental concept and the lecture seemed all over the place. It raised many questions but didn’t answer them.
If we accept the hypothesis, then there are two areas need to be addressed:
- What rewards should agents optimize?
- Designing algorithms to maximize them.
Some rewards are easy to define, like winning a game, but others are more complex, like driving a car. His example was of air conditioning in a car, where the reward is not just the temperature but also the comfort of the passengers. Running the air conditioning has a cost in terms of fuel, but the comfort of the passengers is much harder to quantify, particularly since each passenger may have different preferences.
Next he covered the two main approaches to setting up rewards in RL:
- Rewards can be expressed as a final goal, or no goal yet:
- The goal based representation: Goal achieved = +1, and everything else is 0. This has a downside of not signaling, to the agent, the urgency of getting to the goal.
- The action-penalty representation: a -1 could be awarded every step that the goal is not yet achieved. This can cause problems if there is a small probability of getting stuck and never reaching the goal.
- It seems that there are many ways to set up rewards. If we take a lesson from game theory, we can see that the value of rewards might be important or the relative value or order of rewards might be important. In rl values are often more important than the ‘order’ of rewards. However it might be interesting to consider if we can encode preferences into the rewards and if this formulation would still make sense in the context of the reward hypothesis and the bellman equations.
Littleman then asked “Where do rewards come from?” and answered that they can come from - Programming - Human feedback - Examples - Mimic the rewards a human would give - Inverse reinforcement learning - learn the reward function from examples - Optimization - Evolutionary optimization like population dynamics. - The reward is the objective function - The reward is the gradient of the objective function
Next he discusses some challenges to the reward hypothesis:
- Target is something other than cumulative reward:
- cannot capture risk averse behavior
- cannot capture diversity of behavior
- is it a good match for a high level human behavior?
- single minded pursuit of a goal isn’t characteristic of good people.
- The goals we “should” be pursuing may not be immediately evident to us - we might need time to understand making good decisions.
The big elephant in the room is that we can reject the reward hypothesis and have agents that peruse multiple goals. The main challenge is that it becomes harder to decide when there is a conflict between goals. However, the field of multi-objective optimization has been around for a long time and there are many ways to deal with this problem. Some are more similar to the reward hypothesis but others can lead to more complex behavior based on preferences and pareto optimality.
Lesson 3: Continuing Tasks
Returns for Continuing Tasks
- In continuing tasks, the agent interacts with the environment indefinitely.
- The return at time t is the sum of the rewards from time t to the end of the episode.
- The return can be formulated using discounting, where the rewards are discounted by a factor \gamma.
\begin{align} G_t&=R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + \ldots \newline &= \sum_{k=0}^{\infty} \gamma^k R_{t+k+1} \end{align} \tag{11}
- returns have a recursive structure, where the return at time t is related to the return at time t+1 by the discount factor \gamma.
\begin{align} G_t &= R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + \ldots \newline &= R_{t+1} + \gamma ( R_{t+2} + \gamma R_{t+3} + \ldots ) \newline &= R_{t+1} + \gamma G_{t+1} \end{align} \tag{12}
this form of the return is called the recursive form of the return and is usefull in developing algorithms for reinforcement learning.
Returns at Successive Time Steps
- The return at time t is related to the return at time t+1 by the discount factor \gamma.
- The return at time t is the sum of the reward at time t and the discounted return at time $t+1.
Episodic vs. Continuing Tasks
- An episodic task has a well-defined terminal state, and the episode ends when the terminal state is reached.
- A continuing task does not have a terminal state, and the agent interacts with the environment indefinitely.
- To avoid infinite returns in continuing tasks, we use discounting to ensure that the return is finite.
- The discount factor \gamma\in(0,1) is the present value of future rewards.
Sutton and Barto (2018) emphasizes that we can use the discount factor of [0,1] to unify both episodic and continuing tasks Here = 0 corresponds to myopic view of optimizing immediate rewards like in the k-armed bandit problem. The discount factor = 1 corresponds to the long-term view of optimizing undiscounted expected cumulative reward. into a single framework. This is a powerful idea that allows us to use the same algorithms for both types of tasks.
I think it is a good place to consider a couple of ideas raised by Littman in the guest lecture:
The first is hyperbolic discounting and the second risk aversion.
Behavioral economics has considered a notion of hyperbolic discounting where the discount factor is not constant but changes over time. This is a more realistic model of human behavior but is harder to work with mathematically. This idea is not covered in the course perhaps because it is a departure from the more rational exponential discounting model which we use.
two forms of hyperbolic discounting are:
G(D) = \frac{1}{1 + \gamma D}
φh(τ) = (1+ ατ)−γ/α \tag{13} where:
- φh(τ) is the hyperbolic discount factor at time τ
- α is the rate of discounting
- γ is the delay parameter
there is also quasi-hyperbolic discounting which is a combination of exponential and hyperbolic discounting.
G(D) = \begin{cases} 1 & \text{if } t = 0 \newline \beta^k \delta^{D} & \text{if } t > 0 \end{cases}
The notation for both terminal and non-terminal states is S^+
Exercise 2.10 proof of Equation 3.10
\begin{align*} G_t &= \sum_{k=0}^\infty \gamma^k = lim_{n \rightarrow \infty} (1 + \gamma + \gamma^2 + ... + \gamma^n) \newline &= lim_{n \rightarrow \infty} \frac{(1 + \gamma + \gamma^2 + ... + \gamma^n) (1 - \gamma)}{(1 - \gamma)} \newline &= lim_{n \rightarrow \infty} \frac{1 - \gamma^{n+1}}{1 - \gamma} \newline &= \frac{1}{1 - \gamma} \end{align*}
References
Reuse
Citation
@online{bochman2022,
author = {Bochman, Oren},
title = {Markov {Decision} {Processes}},
date = {2022-05-03},
url = {https://orenbochman.github.io/notes/RL/c1-w2.html},
langid = {en}
}