
- Syntax, Major Word Order
- Dependency Parsing and Models
- Explanation and demo of AutoLex, a system for linguistic discovery
Introduction
This time we’re going to be talking about syntax in general but dependency parsing in particular. and when we talk about linguistic structure and syntax there’s two types of linguistic structure that we talk about.
The first one is dependency structure which focuses on the relations between words and it looks a little bit like this: For example we have the word saw and the word
sawas the root of the sentence and this is connected to other words likeiandwithand girl
We also have phrase structure which is focuses on the kind of structure of the sentence as opposed to the relationships between words Both of these are common expressions of syntax or common ways to represent syntax. In particular phrase structure was widely used in English and you know kind of developed by chomsky and other very influential linguists from 1950s 1960s until now However recently there’s been a big move towards dependency structure and the reason why is because they’re relatively straightforward to express. And in particularly relatively straightforward to express across a wide variety of languages. and so for example we can do things like say saw is the subject of the sentence so or saw is the root of the sentence and then it has a subject it has a direct object and it has a prepositional phrase and these kinds of things are relatively you know constant across languages maybe not prepositional phrases but you know a phrase like this and it’s particularly good for multilinguality because in some free word order languages it’s also possible to have basically words intervene into a phrase which makes it very difficult to say this is like a particular phrase and what i mean by this is if you have a dependency tree and words cross it’s very hard to come up with an example of this in English. I don’t know if anybody knows one of the top of your head like ellen okay it’s like i went i saw a movie yesterday that was good pt so this is a relatively natural English sentence but actually yesterday yesterday is a child of saw and movie that is a child of movie so you can see the dependency is crossing here basically the only place where we get this in in English is is with adverbs adverbs can be like are basically the only thing with really free word order in English but they break this kind of phrase structure representation because you can’t say that any there’s a consistent phrase here so basically that’s an issue and there are other languages where these are like extremely common where the word order is free for all different kinds of phrases so because of this a lot of syntactic analysis is kind of moving in the direction of using dependencies instead of phrase structure
Universal Dependencies
There is an amazing effort called the universal dependencies treebank that gives you a standard format for parse trees in many languages this started out of stanford dependencies and also universal part of speech tags and universal dependencies created by google and the basic motivation for this was they wanted to be able to build like one parser and use it for all of the languages instead of have having 400 parsers for 400 languages so if you come up with something in a unified format that you can that you can parse in process then that makes deploying to many different languages much easier the disadvantage of doing this is that in order to make something universal you have to give up on some language specific details so there are details that don’t easily fit within this universal dependencies format but in most cases they cover you know a lot of the major things that you see in different languages
Syntax vs Semantic
An other thing that you should know about if you’re considering dependencies or kind of like dependency structure is that there’s actually different types of dependencies – Syntactic and Semantic. And they look very different. Syntactic dependencies basically are trying to as closely as possible reflect the phrase structure of the sentence and how sentences are put together So for example in a prepositional phrase the head of the prepositional phrase will be a preposition. Whereas for semantic dependencies the head of a prepositional phrase will be like the main noun or verb in that prepositional phrase.
The idea being that syntactic dependencies are good for understanding the structure of the language whereas semantic dependencies might be good, for example, for Question Answering because if you ask a question if you have a sentence like the one i had here “I saw a movie yesterday that was good” or “I saw a movie yesterday at the movie theater” and you want to say where did the person watch the movie and the syntactic dependency movie would be connected to at so you would have to like jump down the tree several nodes wherein semantic dependencies movie would be connected to movie theater. It would have an appropriate label so you could just like look up the edge and connect the two together to answer that question in a single hop instead of multiple hops. This is really important! Aditi might talk about things related to this later and you need to choose which one you want based on which application you’re interested in
Semantics
One of the very interesting things about yeah sorry god the last play the the semantics how do we club all the nouns together like we need some external knowledge to understand the semantic of the norm do you mean like a noun phrase or no no just to know just a name of something so like it’s a concept right like so that’s a good question so how how do we understand the semantics of a noun or something so even semantic dependencies this is only talking about the relationship between words in the sentence it’s now telling you about the underlying semantics of the nouns so if you wanted to know about like underlying semantics of a noun you would have to have something else like a semantic like knowledge base or something like this the typical version of this is something like wordnet which basically says well let’s say we have chevrolet chevrolet is a type of car which is a type of vehicle which is a type of you know man-made object which is a type of object or something like this and i think some people might have used wordnet it’s now like lesson style than it was before but it’s it’s basically telling you this information and there’s actually since we’re in a multilingual class i can tell you about something like babelnet which is a multilingual like a multilingual version of wordnet so if i put in [Music] oh i’m sorry i was searching in English no wonder so if i search for this in japanese it can tell you that this word is a concept for like automobile and it’s it has is a has part part of relations and all of these are linked across languages so for example it’s in i can’t find the language link but here yeah here yeah so you can see that it links to car automobile other things like this so it’s all linked together so if you want to specifically talk about semantics of words on their own then you can either use things like this or you can use word embeddings also which give a concept so can’t you get a semantic graph so what word net tells you is it tells you about the semantics of words it doesn’t tell you about the semantics of like words relating to each other so it doesn’t tell you for example that challenge is the object of love it doesn’t tell you that a challenge is being loved which is what this this semantic dependency tells you and then if you go even a little bit farther there’s something called predicate argument analysis or frame semantic parsing or something that gives you an even more abstract version but semantic dependencies are kind of like something related to that so regular regular universal dependencies are semantic sud is syntactic so you should know the difference between them so there’s a lot of cross-lingual differences in structure so we’ve talked about this a lot before like word ordering so we have svo we have hindi which is a verb final and arabic which is verb initial and i got this actually from the pud tree bank which is the parallel universal dependencies treebank it has a whole bunch of translated sentences in different languages along with their dependency trees and the interesting thing is these sentences all i guess mean the same thing hindi speakers can confirm that’s actually the case yes nobody’s saying no so i’ll assume i’ll assume yes but you can see the structure is very different so we have like is and then in English we have we have is is in the middle of the sentence with the noun first and the verb second and then what i can what i can see is we in handy we have an auxiliary verb but then we have a verb here and then we have the object and i guess an oblique indirect object and stuff like this but these all come on the left side of the verb so we can tell that hindi is verb final and then for arabic we can tell that arabic is verb initial and we have a noun here at position sorry a subject and then an oblique here so you can tell the difference in the structure even though i i can’t even read the script in arabic and hindi i can still tell that just by looking at the dependency
Dependencies
so what can we do with dependencies so i actually previously they were used for feature engineering and systems and they’re still useful in some cases but now our default is just to you know pull up m mbert or xlmr and fine tune it and get reasonable accuracy on a lot of tasks that we care about and in fact you know dependencies are probably captured somewhat to some extent implicitly in these models so why care about syntax i would argue that these are more useful now in human-facing applications and a while ago june 3rd i think last year i actually asked a question on twitter what are convicts are i guess two years ago i asked a question on twitter what are convincing use cases in 2020 for dependencies and i got 39 answers and just to give some examples they still can be useful for incorporating inductive bias into neural models so biasing self-attention to follow syntax or other things like this i think in it still is useful to encourage models to be right for kind of like the right reasons instead of the wrong reasons because this improves model robustness especially out of domain and other things like this and syntactic conductive biases can provide you a way to do this another thing is understanding language structure and this is an example from the aditi’s work which he’s going to present in much more detail in a few minutes so i’ll let her talk to that another very interesting example is searching over parsed corpora so like i talked about before like let’s say we want to find examples with that are talking about x was the founder of y so we want to find it lots of examples of founders of something or other you could try to do this with a regular expression but it’d be pretty tough to come up with a regular expression that gives you this you know with high precision high recall but if instead you find where founder is the verb the subject and it has a subject and an object here then you can just search all examples of this and it actually highlights the appropriate ones here so this is from the spike system created by ai2 and another thing is analysis of other linguistic phenomena or like you know if you want to identify for example when this is coincidentally i actually one one of these is from Emma Strubell you know assistant professor here another one is from Martin Sap who will be an assistant professor here I actually made the slides before I knew he was going to be a professor here but but anyway this is examining whether film scripts demonstrate that people have power or agency and analyzing it along the gender of the participants in the film so whether male or female characters are you know like demonstrating more power agency and film scripts and this is used to answer like social and sociologically interesting questions for example and this is made a lot easier by analyzing the syntax because then you can do things like say who did what to whom more easily
Parsing
This is kind of a motivation for like what our dependency parses why would you want to be using dependency parts or syntax in general so to talk a little bit more about dependency parsing how would you get these especially in a multilingual fashion parsing is predicting linguistic structure from an input sentence and there’s a couple methods that we use to do this the first one is transition based models and basically the way they work is they step through some steps one by one until we we can turn those steps into a tree another one is graph based models and basically they calculate the probability for each edge in a dependency parse and perform some sort of dynamic programming over them and if you’re familiar with like part of speech tagging from the first assignment transition based models are kind of like a history based model for part of speech tagging and what this would look like is if you if you had like an encoder decoder model where the next tag was always conditioned on the previous tag for graph based models we didn’t really cover crfs here but if you’re familiar with CRFs the graph based models are a little bit like these they calculate some scores and then they have a dynamic program to get the best output so just to give a very brief flavor of what these look like
Shift Reduce
Shift reduce parsing basically it processes words one by one left to right and it maintains two data structures one is a queue of unprocessed words another is a stack of partially processed words and at each point we choose to either shift moving one word from the queue to the stack reduce left where the top word on the stack becomes the head of the second word or reduce right where the second word on the stack is becomes ahead of the top word and we learn how to choose each of these actions with a classifier so just to give an example we want to parse the sentence i saw a girl so what we do is we first shift and move something sorry this says buffer it’s the same thing as q there’s multiple ways to say this but just think buffer equals q we move one thing from the the queue to the stack we move another word from the queue to the stack and then sorry that’s another typo this should be reduced left and so we reduce left and we get a left arc here then we shift again and then we shift again then we reduce left we reduce right and then we reduce right and then we have a final basically parse tree here so basically what you can see is at each point we choose an action and based on the action we add we either move something from the queue to the stack or we add an arc between the top two things on the stack so you probably won’t need to implement this yourself there are plenty of good dependency parsers out there but just to get an idea of what the algorithm looks like in case you’re interested in doing that
Classification
so the way we do classification for any variety of shift-reduced parsing is basically we take in the stack and the buffer and we need to choose between one of the actions shift left and right so this is a regular classification problem three-way classification problem and we can encode the stack configuration with any variety of recurrent neural network or auto-regressive neural network so one example of this is where we encode basically the stack the previous history of actions and the buffer and feed them into the into the model an even simpler way of doing this is you just encode the words in the input sentence and then have a decoder that generates the actions for you so you could even just throw that into like a regular transformer model and train it as well it would just be you know input is the entire words in the the source sentence and then the output is the sequence of actions so that’s a basic like very quick overview of shift-reduce pricing are there any questions or yeah so you said that we use the dependency passing as an auxiliary fast increase of westminster’s products and inputs yeah so now we have some methods about like adding adapters into xlr to make them more robust for a given language so with adapters do we still need these to increase robustness or if you have a car first and find an adapter and yeah so that’s a really good question if we have something like adapters like multilingual adapters do we still need something like an auxiliary test like dependency parsing and i i would say it’s quite likely that those two things are kind of orthogonal in that adapters are allowing you to more effectively adapt to individual tasks whereas the supervision that you would get from a dependency parsing objective would essentially enforce the model to more strictly follow the syntax of the sentence as linguists kind of describe it so i think that both probably would stack together but i i don’t have empirical results or i i don’t know immediately off the top of my head about a paper that demonstrates maddox yeah so i know medics but i don’t remember if they used like dependency parsing it’s an auxiliary task but they show performance improvement on very low resource languages that xlr is failing and then they used access to improve the performance but i’m not sure whether it was one of the things and so basically the the comment to repeat it for other people who couldn’t hear the so there’s a paper called man x that basically does adapters we talked a little bit about adapters in class i think but basically they demonstrated that it improves on very low resource languages but i it’s not perfect still after using medx right and i think this and that could be combined together probably to improve a bit but as i said i think that’s not the main good use case of dependencies right now i think the better use cases of the dependencies are they give very like intuitive human facing interfaces if you want to do like analysis of corpora or extract detected phenomena on a more holistic level or other things like that so it was actually inspired by one of your tweets you had put a tweet i think a year back that when a person releases the model for 100 languages doesn’t mean it works languages so yeah that changed my perspective that okay it’s not perfect then i kind of searched for these people yeah so i to repeat in case people in the back couldn’t hear i i said something on twitter about a year ago where it’s like when somebody releases a model for 100 languages that doesn’t necessarily mean it works on 100 languages it means it does something on 100 languages probably and it’s probably better than nothing but it’s not perfect for sure so and i’m sure you guys all noticed this as you were implementing your various assignments as well cool.
Graph based
The other alternative is a graph based parsing and graph based parsing basically what it looks like is we express the sentence as a fully connected directed graph which means that we have all pairs of words as potential candidates for a dependency edge existing between them another way you can think of it is a matrix of scores for each for each edge where the rows are the head and the the columns are the children and the diagonal obviously something can’t be ahead of itself so it would it’s irrelevant but you predict all of the other things there and then after you do that you score each edge independently so you basically calculate the values of that that score matrix and then you have some algorithm that allows you to find the maximal spanning tree which is basically the highest scoring set of edges that form a tree in the form a tree with a root in it
Graphbased vs Transitionbased
and i have a comparison of graph based versus transition based one ex one advantage of transition based parsing is that it allows you to condition on infinite context basically so it allows you to condition on all of your previous actions so theoretically it has as much expressiveness as you want just like a regular encoder decoder model can do you know can condition on all your previous sections however for transition based parsing greedy search algorithms can cause short-term mistakes to propagate into damaging your long-term performance so you know if you accidentally connect an edge too early there’s no way to recover from it on the other hand graph based parsing you can find the exact best global solution via dynamic programming however you have to make some local independence assumptions so you can’t like necessarily easily condition you know the choice of one edge on whether you chose one edge or at another time so for the dynamic programming
Dynamic Programming
algorithm i’m not going to go into a lot of detail here because as i said like people are probably not going to be implementing this on your own you’re probably going to be using a parser but basically we have a graph and want to find it spanning trees so what we do is we greedily select the best incoming edge to each node and we subtract its score from all other incoming edges because we want a tree and not anything with any cycles in it what we do is we contract the cycles together into a single node and resolve the cycles within that node and basically we recursively call the algorithm on the graph with the contracted node and then we can expand the contracted node deleting at an edge from the root node there so if you’re more interested in exactly how this works you can look at jaravsky and martin’s textbook on dependency parsing or something like this but basically that’s the general idea for these models basically what we do is we extract features over the whole sequence so we feed in all of the you know all of the words in the input into a feature extractor in this particular in this particular example it says lstm but in reality now it’s xlmr or bert or you know whatever
Feature Extractor
Your favorite feature extractor is the classifier that you use to basically apply scores to each of the nodes of the input is a by affine classifier this looks a little bit scary if you look at the equations but it’s actually super simple what you do is you learn specific representations through an mllp for each head word in each dependent word so basically you feed the representations that you get from burke or whatever else into an mlp where you have a separate mlp when you’re considering the word as a head and when you’re considering the word as a child or a dependent and then you calculate the score of each arc where sorry i thought i had an animation here but basically the first part of this here is calculating how likely a child word is to connect to a head word so it’s calculating basically the congruence between a child word and a head word and of course you know this is optimized end to end but it will be considering things like how close together are the words how likely is a child to be a child of a head like so nouns tend to be children of verbs et cetera et cetera determines children of nouns and then in addition it also calculates the score saying how likely is this word to be a head word in the first place so for example determiners are almost never head words in in semantic dependencies and so they’ll get a very low score according to this thing down here whereas verbs are very often head words so we’ll get a high score
Difficulty
For multi-lingual dependency parsing,the difficulty in multilingual dependency parsing is, that actually syntactic analysis is a particularly hard multilingual task. I think it’s harder than named entity recognition; it’s probably harder than part of speech tagging and it might even be on the same level of difficulty as translation. Yeah maybe not maybe not on the same level of difficulty as translation but it’s hard it’s a hard task and the reason why is because it’s on a global level not just a word by word level so you need to consider long distance dependencies within the sentence and syntax varies widely across different languages so like English is very very different from Hindi and both are very very different from Arabic so you can’t like just say you know well like named entities look pretty similar in all languages they all have like low frequency words and is a key that always works for named entities but you can’t do something like that when deciding syntax is easily
Order insensitive encoder
so there’s a bunch of improvements that people have proposed i had some examples of these and the papers that i suggested for reading for the discussion one example is that people have shown that when you’re transferring to very very different languages you can remove the bias on ordering in encoders so for example if you’re using a transformer based model you can remove the positional encodings so you basically get an order insensitive encoder and that transfers much better to very very different languages so in this case they always use English as the source language and transferred to another language but can you think of any other examples where this might be useful can you think of it can you think of an example of a language where it would be very hard to get another language with similar syntax that’s included in your dependency treatment yeah i mean if you’re studying a low resource language that’s part of a language family that only has other low resource languages yeah exactly so if you’re studying a low resource language with a language family that only has other low research languages i could give an example what about navajo that’s probably the highest resource language in its language family but it’s extremely low resource and i think that’s i think it’s also useful because one of the or one of it’s also important because dependency parsing is particularly useful for things like linguistic inquiry or human facing interfaces when you can’t just train an end to end model easily so you know that’s a particularly salient use case another paper that i
Dependency parsing
this is one of my papers i like it a lot i i wish more people liked it a lot but but basically the i think it’s a really really cool paper so i i’m trying to sell it to everybody but basically we came up with a generative model for dependency parsing and the idea of the generative model for dependency parsing is that you have a model that jointly generates the dependency tree and the sentence and one of the nice things about generative models is that you can train them unsupervised as well so you can take the unsupervised model and learn the structure that’s used in the unsupervised model together with like generating the sentences on unlabeled data and the reason why i think this is cool is because you can take a model that was trained on English and then train it unsupervised on the language that you’re interested in parsing and it improves the performance by a lot especially if the languages are very unrelated so i think this is another cool tool if you have a language that is from like a different language family for example the input is the dependency tree and your model just generates a random sentence in the target so the input is it’s a generative it’s you can think of it like a language model but it calculates instead of just calculating the probability of the output sentence it calculates the joint probability of the dependency tree and the output sentence so if you’ve given a sentence like it reconstructs the sentence right and it can do other things like it can get the the highest probability dependency tree given a sentence that’s called like latent variable inference and other things like that basically in this case it’s initialization it can be initialization with regularization towards the original parameters as well does that imply supervised data for the chemistry it does not it only it only requires text and basically the way it works is it it you have a dynamic program that finds the dependency tree that iterates over the dependency trees and it optimizes the parameters of like the dependency parser and the output at the same time but the probability of the output will go up basically if you have a more coherent dependency tree for a completely different family yes yeah the different family could have a completely different type of synthetic structure yes exactly yes you read read the paper i’m not lying so that’s a good that’s a good question and that will link it to what aditi is going to talk about in a second too we didn’t we didn’t evaluate it that you know like that extensively so i think that would be a natural interesting next question for any of these improvements that i’m talking about here does do these improvements lead to a more coherent you know grammatical sketch for the language or something like that if we extract the grammatical sketch cool yeah so i’m i’m
Linguistic informed constraints
as i said i i’m excited about that so come talk to me if you if you want to hear more a final thing is linguistically informed constraints so there are big atlases of data about linguistic structures like the world atlas of language structures which i believe ellen or somebody talked about earlier and they they tell you things like is an adjective before a noun and so using this what this paper that i’m introducing here does is they use something called posterior regularization which basically says we’re going to parse our whole corpus we’re going to look at the proportion of the time that an adjective appears before a noun or after a noun and then if our big atlas of language structure says that adjectives should happen before nouns but our dependency parser is putting adjectives after nouns much more often then we are going to decrease the probability of it putting an adjective after the noun and increase the probability of it putting an adjective before the noun so this is a way to introduce basically prior knowledge into the predictor in order to make it work better so these are just three examples of cross-lingual dependency parsing but they demonstrate some you know ways to incorporate intuitions and stuff cool and any other things if not i’ll turn it over to aditi to talk in a bit of detail we might or might not have time for discussion formal discussion but we could have maybe all like class discussion and and it’s the keynote slides yes these are the keywords so can i open the demo on the google chrome this one yes thank you and then yeah that works cool and that’s the mind sure okay hi everyone i’m aditi i’m a phd student working with graham and today i’m going to show you a part of my research where i’ve used these dependency analysis okay so we just saw some because it’s kind of annoying okay so dependency analysis basically told us on a high level how words are related to each other so it’s information is useful but we also need to understand a more complex linguistic phenomena if you truly want to understand the language as a whole so some of these complex linguistic phenomena are like morphological agreement word order case marking suffix usage to name a few and these are important not just for like a language communication or understanding but also has some concrete applications so there are some human-centric or human-facing applications for instance like if you want to like learn the language then you need to know how to arrange these words when does the ordering of the word changes what kind of suffix to use when what happens gender is like for each gender you might have a different word ending and so on another important application which for navajo we also saw was language documentation because languages are getting extinct quite frequently and quite quickly also so language documentation is a way where linguists document the salient grammar points of a language not just for preservation but also as a way to like also create pedagogical resources maybe even create language technologies from that so another kind of application is from machine centric applications some examples that we saw where dependency analysis were used to give inductive bias into models another application is like we sort of used these rules that we extract automatically to evaluate a machine output so often across languages as we saw syntax is quite different so we want to have a way to automatically evaluate how grammatically correct let’s say a machine translation output is so basically to achieve both human centric application and machine centric applications we need to extract rules which explain this phenomena in a format which is both human readable and machine readable and i’m going to quickly explain like how we do this using a process of
Definition of required agreement
morphological agreement so agreement is a quite complex process wherein basically words in a sentence often change their forms or morphology based on some other words in the same sentence based on some category like gender number and person so i’ll give a quickly an example from number agreement in spanish so here you can see that girl is in singular and the word for verb has also been singular so now if i change the word for girl to be in a plural form then the words form also changes to the plural form so basically any change in the subjects number has to bring about a change in the verbs number so we call this as subject verb required agreement now if you look at the object and the word they are also both in the singular form in the first sentence and the second sentence when the form of the object dog has become plural the form of the word still remains in a singular form so essentially any change in the object’s number is not bringing a change in the verbs number so this is it’s not required agreement so any sort of agreement that we may observe between object and work is purely by chance so we call this as object work chance agreement so to basically understand what are the rules which govern subject agreement and orders or how to require agreement you basically formulate it into a classification task
Prediction task
so the task is here of predicting required agreement versus chance agreement and how do we extract these rules automatically just from the raw text so here i have an example of greek this is a greek sentence and we first automatically perform some syntactic analysis which basically gives us what is the part of speech of each word what is this morphological features what are the dependency links between them now from this syntactic analysis we basically create our training data for this prediction task so here’s an example so on this box here you basically have a dependency link between the determiner and the proper noun now the gender of the determinant and the proper noun are both matching they’re both in feminine gender so basically we can create a training data point saying that proper noun and determiner when they are in a relation then the gender is matching so the agreement value becomes yes now another dependency link here is between the noun and the proper noun now here the gender values are not matching so our data point here becomes that any relation between noun and proper noun in this example the agreement value is known so essentially we are basically creating a binary classification task from this example and we create this data set for all the sentences we then basically learn a model on top of this training data from which we extract rules where the rules are telling us which of these rules are actually leading to a required agreement and which are leading to a chance agreement so essentially this is an example of the model so again going back to the previous slide where i mentioned about human centric applications so we want to understand and extract these rules which are understandable to humans so we want to use a model which is more interpretable so here i have used the model of decision trees the decision trees can exactly tell you what are the features which led to one decision so once we have applied a decision tree style model on our training data it gives us a leaf node the leaf here is inducing a distribution of agreement over these examples the leaf 3 here is showing us that there are 58 000 examples where the gender values were matching and 778 but they were not matching but how do we know whether this distribution is leading to a required agreement or a chance agreement and to automatically extract this label we basically apply a statistical threshold i won’t go into the much details of it but essentially we apply a significance test which tells us whether the observed agreement distribution is significant or not and this can tell us whether the leaf is truly capturing a required agreement or not and this is like an example of the label decision tree where for spanish gender agreement this is the leaf or this is the tree after the leaf labeling stage and the leaf three here has been marked as required agreement so basically from this leaf three we can extract some discrete rules which says okay if determinant and noun are in the following relation then they need to agree on gender so basically from the raw text we started training data over which we train an interpretable model from which we then extracted some discrete and very simple rules and this is just a very basic pipeline and now we are trying to extract this
Linguistic questions
sort of or apply this pipeline for potentially any linguistic question so we saw this for agreement where our linguistic question was when do syntactic heads show agreement with their dependence on gender number and so on another interesting question was for case marking in case marking we’re interested to know when does a particular class of words like nouns take nominative case over the other so for example in this sentence anna has food anna is in the nominated case but if it becomes anna’s food then ani is a generative base so we want to basically if you are learning this language you need to know that when to add an apostrophe is when you are basically showing a possession another kind of interesting linguistic phenomena is of word order like you need to know how to arrange the words appropriately and even in English typically when we say about word order people just say it’s one word that English follows svo but it’s even within English there are multiple word orders so for instance if if i’m saying English is sorry anna is eating an apple then your word order is simply subject verb and object but if i’m asking a question what is anna eating then these order changes it now becomes object subject and work so if i’m learning English i need to know that when i’m asking a question what is the typical order but if i am just using or saying a decorative sentence what is the what order so essentially for any linguistic question we want to formulate it as a prediction task and learn and extract its rules and this is the final general framework which we have been working on from the raw text you basically extract some
General framework
features but in our case the features were part of speech tags dependency analysis from which we then extract rules for each of this phenomena and i’ll show you what the rules look like in a minute okay so now what are the kind of syntactic analysis which we can use so graham just showed you the universal dependencies project within that is also the sud tree banks so basically if for a language we have this kind of data available which more or less is annotated by language experts we can directly use these sud treatment as a starting point but for many more languages we even don’t have annotations so in that case your multilingual parsers come into the picture where you can take some raw text first parse it using these models and then apply the same approach okay so this is the toolkit
Toolkit
which we have developed and okay this basically this is an autolex framework where we have extracted such kind of rules for different linguistic behaviors for a bunch of languages sure so for each language we extract a bunch of features and i’ll just go through some of them here so let’s say we want to explore the spanish agreement features and let’s go into gender so okay so this is exactly the so if you look at the first thing here basically say that okay mostly in spanish gender usually agrees between the determiner and its head but there are some significant number of cases when this does not hold true and some of these cases we have highlighted here that if let’s say a determiner is governed by an adjective in some cases the gender did not agree so we basically extracts rules in a human readable format and further for each of these rules because rules alone can often get quite overwhelming we also show some illustrative examples so here basically if you look here so here the determiner gender is masculine and the adjective gender is feminine so here is one example where although the determiner is governed by an adjective the gender is not matching but then there are some other examples where the determiner’s gender is masculine and the adjectives gender is also masculine here the general values are matching so these are some sort of exceptions to the language general oriented and knowing these exceptions are also important because they do occur quite frequently in the language again we have some rules for word order also so let’s say we want to can go adjective noun so for instance so typically in spanish unlike English most adjectives come after the noun that’s the typical ordering of objectives but there are very specific cases or or very specific adjectives which come before the nouns and the model has correctly identified some of them for instance this rule is telling us that if the adjective has the lima primero then the adjectives come before the noun and again for each of the rules we also ex like show some this illustrative examples where indeed these adjective which has the lima primero is coming before the noun but again language is not that simple there are even exceptions to exceptions so there are again examples which show that even when the lima is primarily there are certain times when this rule is not followed so we are trying to show a more softer view of the rule also that this rule is not 100 applicable every time there are conditions where this rule is not followed so essentially here we have used dependencies as our feature base to explain the rules in a human readable format and i guess one another important aspect here is the quality of the rules also depend a lot on the quality of the underlying analysis so as we improve the multilingual dependency parsing the quality of the rules should also improve so we also applied this system for an endangered language variety called hmong so hmong is spoken in north america also china thailand vietnam and laos and one of its variety is close to endangered and we were trying to we simply had access to a bunch of monk sentences and we wanted to analyze some of his interests and linguistic properties and we had david in lti who also speaks more and knows a lot about it so we basically presented such kind of rules for mong to david and there were a couple of interesting observations first the quality of rules was not as good as what we were seeing for spanish but despite that the model had still been able to identify some cluster of examples which showed rules which david was not aware about so such kind of data-driven approaches is also able to capture or identify some rules which the linguist was not initially aware of so i think dependency analysis is a very useful tool which has a lot of applications especially for exploring a language because there’s so much data out there the dependency analysis helps us find the key components to it so i can go into more detail but these are the main features sure so right now we basically i showed you grammar rules and how it was
Summary
useful from let’s say a linguist or language documentation point of view we’re also now using these tools to actually teach languages to a more less linguistically aware audience because often learners or teachers they don’t go into the linguistic jargon that much but they’re still interested in knowing the grammar rules and especially we are focusing on two languages marathi and kanada these are both indian languages and there are schools in north america where they are teaching these languages to English speakers so a lot of the times there are immigrants who are settled here and they want their children to learn these languages so that so there are English native speakers here and the schools here are interested in teaching them these languages from English so here we basically extract a lot of interesting features so for example for example here we have basically extracted some of the most common words observed in kannada what is the transliteration in English and what are the different kind of forms they are like what are the different forms these lemma have been observed across different genders so this lemma do here i don’t know i’m pronouncing it correctly but you can see here how this lima is used for a masculine gender or how this lima is used in the feminine gender and such kind of tables are pretty common when you are teaching how a word should be used in a language so we are automatically again performing syntactic analysis on these languages extracting such kind of useful insights and then presenting them to actual teachers so that they can check if this material is useful for their teaching process so we are trying to ease the teachers job so that they can focus on the creative aspect of teaching and yeah i guess those are the main points great thank you thank you aditi yeah so i’m sorry we’re right up against the the time so i don’t think we’re gonna have time for discussion this time i really apologize i try not to do this but i packed too much stuff in but i also invited the dt and didn’t want to ever prepare for nothing because of this if you took time to like prepare for the discussion today and read the things if you want to send like a short summary of the things that you prepared we can give like extra credit it won’t be required but we i’ll give like one discussion worth of extra credit for that are there any questions for about the stuff that you was talking about here yeah obviously mentioned like different regions and different species like america are there any like grammatical differences region-wise or are they like that’s a good question so there are these different varieties so we worked so the question was about because hmong is spread across so many different regions are there any difference in the grammatical properties so there are because there are different hmong varieties and we worked on one of the variety which is predominantly spoken in north america so we didn’t have the chance to investigate how the grammar rules changes across these different varieties but the interesting thing so we did another sort of a separate set of experiments where the universal dependencies project they have a lot of free bang for the same language for different domains so there are data from grammar books they have data from news articles and even within the same language across these domains the grammar structure varies quite a lot so in this tool we are basically also offering linguists to like check okay these are the do’s extracted from one domain how do they change in another domain is their model able to account for instances of agreement where there’s not exact matching values for instance if the subject is marked as duo so that would be considered as that if the agreement is not happening because the value is not matching i’m not sure if the universal dependency tree bank actually has that level of detail it might i maybe you have experience with that but i think the universal dependency annotations are actually quite i don’t know coarse so that my level of detail might not show up in the first place but it might yeah that is like an important point that this analysis has been done on one schema the schema used here is the ud schema or the sud schema which is the the we purposefully chose sud or ud because first of all it’s available for a lot more languages and it has a consistent annotation format so the kind of rules we extract now they’re also consistent across languages but that being said it might not consider the language the system is that well that is like a drawback for that but potentially you can apply this pipeline or this model to any other annotation statement it will give you rules according to that schema okay great thanks a lot everyone we can answer other other questions
Outline
- Introduction to Syntax and Linguistic Structure
- Syntax focuses on the structure of sentences and the relationships between words.
- Two main types of linguistic structure:
- Dependency structure: Focuses on the relations between words.
- Phrase structure: Focuses on the structure of the sentence.
- Dependency structures are often more straightforward to express across various languages and are thus useful in multilingual applications.
- Dependency Parsing
- Dependency parsing involves predicting linguistic structure from an input sentence.
- Different types of dependencies:
- Syntactic dependencies: Reflect the phrase structure of the sentence.
- Semantic dependencies: Useful for applications like question answering by connecting semantically related words.
- Universal Dependencies Treebank
- A standard format for parse trees across many languages, facilitating the development of parsers that can be used for multiple languages.
- Allows for a unified format that simplifies processing across different languages.
- To achieve universality, it sometimes requires sacrificing language-specific details.
- Cross-Lingual Differences in Structure
- Languages can vary significantly in word order (e.g., SVO, verb-final, verb-initial).
- Dependency trees can visually highlight these structural differences, even without understanding the specific language.
- Dependency Parsing Methods
- Transition-based models: Step through actions to build a tree. They use a queue of unprocessed words and a stack of partially processed words, choosing actions like shift and reduce.
- Graph-based models: Calculate the probability of each edge and use dynamic programming to find the best tree. They express a sentence as a fully connected directed graph and find the maximal spanning tree.
- Applications of Dependency Parsing
- Human-facing applications: Useful for analyzing corpora, understanding language structure, and other linguistic phenomena.
- Adding inductive bias to neural models: Improving model robustness and encouraging models to be correct for the right reasons.
- Searching parsed corpora: Finding examples based on syntactic relationships.
- Analysis of linguistic phenomena: Examining power dynamics or other sociological questions in film scripts.
- Language learning and documentation: Extracting morphological agreement rules and documenting salient grammar points.
- Evaluating machine output: Assessing the grammatical correctness of machine translation outputs.
- Multilingual Dependency Parsing
- Syntactic analysis is a challenging multilingual task due to global-level considerations and wide syntax variations.
- Techniques to improve cross-lingual transfer:
- Removing bias on ordering in encoders.
- Using generative models for unsupervised training.
- Applying linguistically informed constraints.
- Extracting Linguistic Insights Automatically
- Goal: To extract rules that explain linguistic phenomena in a human-readable and machine-readable format.
- Method: Formulate linguistic questions as prediction tasks and extract rules from raw text using syntactic analysis.
- Example: Extracting morphological agreement rules by predicting required agreement versus chance agreement.
- General Framework: Extract features (POS tags, dependency parses) from raw text, then extract rules for agreement, case marking, word order, etc..
- Practical uses of automatically extracted rules
- Language documentation and preservation.
- Creating pedagogical resources and language technologies.
- Aiding language learners and teachers by presenting grammar rules and common word usages.
- Evaluating and correcting machine-generated text.
Reflection
Morphological agreements discussion by Aditi is of particular interest.
It seems that understanding agreement is central to ‘second order’ model that need to beat the baseline. To get this to happen in an interpretable form we may want to train an attention head that is looking at thing that are in agreement and responding to the feature of agreement and disagreement as both are signals of some value.
I belief that we can learn a probabilistic model of agreement between different cases but that they may be affected by all sorts of constraints like clause and phrase boundaries and the degree of morphological markings. So this is why attention seems so appropriate as it can learn what to focus on. And what we want is to make it interpretable so we can also extract the rules that it has learned!
Aditi talks about require agreement v.s. chance agreement for verb-subject and verb-object. I think that we may want to have a theory that looks at agreement in winder context and create a model that can predict agreement in a wider context so that we can consider the entropy of a sentence once agreement has been accounted for. In fact my thinking is that we may want to go further and determine the functional load of the agreement and have a more redined metric that can be used to evaluate the entropy of a sentence accounting to agreement in a functional context. (Error correction ambiguity, Reducing cognitive load, Reducing ambiguity, Parsing)
Navajo in 10
Language Name and Classification:
- Navajo (also known as Navaho).
- Navajo: Diné bizaad [tìnépìz̥ɑ̀ːt] or Naabeehó bizaad [nɑ̀ːpèːhópìz̥ɑ̀ːt].
- It is a Southern Athabaskan language of the Na-Dené family.
Speakers and Location:
- Spoken primarily in the Southwestern United States, especially in the Navajo Nation.
- One of the most widely spoken Native American languages.
- The most widely spoken Native American language north of the Mexico–United States border.
- Almost 170,000 Americans speaking Navajo at home as of 2011.
Nomenclature:
- The word Navajo is an exonym from the Tewa word Navahu, meaning ‘large field’.
- The Navajo refer to themselves as the Diné (‘People’), with their language known as Diné bizaad (‘People’s language’) or Naabeehó bizaad.
Official Status:
- Official language in Navajo Nation.
History and Development:
- The Apachean languages, of which Navajo is one, are thought to have arrived in the American Southwest from the north by 1500.
- Speakers of the Navajo language were employed as Navajo code talkers during World Wars I and II.
- Orthography developed in the late 1930s and is based on the Latin script.
Writing System:
- Based on the Latin script.
- Developed between 1935 and 1940.
- Uses an apostrophe to mark ejective consonants and mid-word or final glottal stops.
- Represents nasalized vowels with an ogonek and the voiceless alveolar lateral fricative with a barred L.
Phonology:
- Has a fairly large consonant inventory.
- Stop consonants exist in three laryngeal forms: aspirated, unaspirated, and ejective.
- Has a simple glottal stop used after vowels.
- Four vowel qualities: /a/, /e/, /i/, and /o/.
- Each vowel exists in both oral and nasalized forms and can be either short or long.
- Distinguishes for tone between high and low.
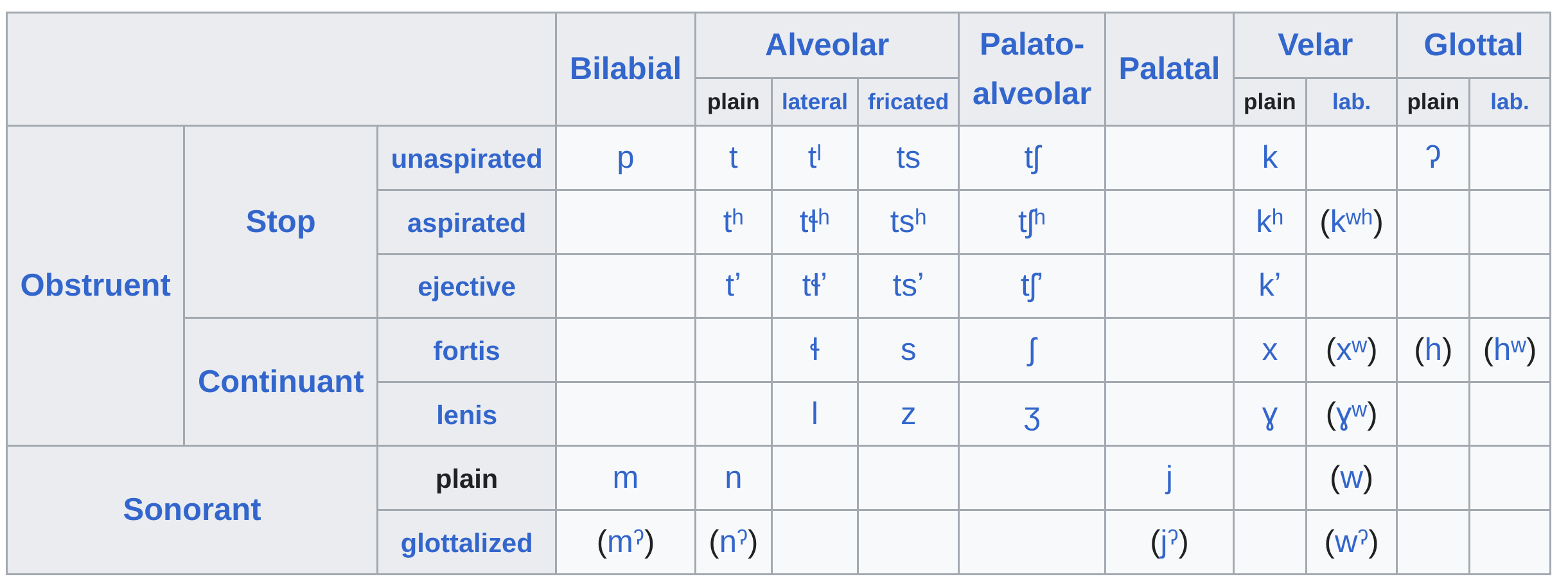
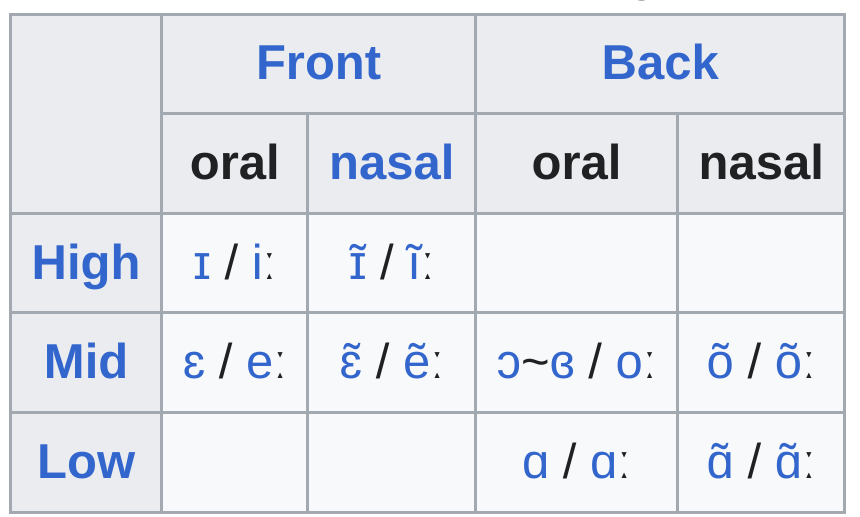
Grammar:
- Relies heavily on affixes, mainly prefixes.
- Affixes are joined in unpredictable, overlapping ways that make them difficult to segment.
- Basic word order is subject–object–verb.
- Verbs are conjugated for aspect and mood.
Vocabulary:
- Most Navajo vocabulary is of Athabaskan origin.
- Has been conservative with loanwords due to its highly complex noun morphology.
- Expanded its vocabulary to include Western technological and cultural terms through calques and Navajo descriptive terms.
Revitalization and Current Status:
- Bilingual Education Act in 1968 provided funds for educating young students who are not native English speakers.
- Navajo Nation Council decreed in 1984 that the Navajo language would be available and comprehensive for students of all grade levels in schools of the Navajo Nation.
- Navajo-immersion programs have cropped up across the Navajo Nation.
- Diné College offers an associate degree in the subject of Navajo.
- In December 2024, Navajo Nation President made Navajo language the official language of Navajo Nation.
Hard to parse in English
Alice drove down the street in her car
– prepositional phrase attachment ambiguity
time flies like an arrow. Fruit flies like bananas
– polysemic ambiguity & garden path sentences
I drove my car to the hospital in town on Saturday
– Linear projection in English
You cannot add flavour to a bean that isn’t there
– Non-linear projection in English
Alex went to Sam’s house, where he told her that they would miss his show.
– Coreference resolution ambiguity
I saw an elephant yesterday in my pajamas
– Non Projectives in English
Bill loves and mary hates soccer
– Non Projectives in English
Papers
-
- This paper is related to extracting morphological agreement rules using dependency relations.
- On difficulties of cross-lingual transfer with order differences: A case study on dependency parsing
- This paper discusses challenges in cross-lingual transfer due to word order differences.
-
- This paper is about cross-lingual syntactic transfer using unsupervised adaptation of invertible projections.
-
- This paper focuses on target language-aware constrained inference for cross-lingual dependency parsing.
-
- These papers are related to the Chu-Liu-Edmonds algorithm.
- Kiperwasser and Goldberg (2016) Simple and Accurate Dependency Parsing Using Bidirectional LSTM Feature Representations
- This paper concerns Sequence Model Feature Extractors.
-
- This paper discusses the BiAffine Classifier.
- Yamada and Matsumoto (2003) Statistical Dependency Analysis with Support Vector Machines
- These paper describes Arc Standard Shift-Reduce Parsing.
- An Efficient Algorithm for Projective Dependency Parsing
- These paper describes Arc Standard Shift-Reduce Parsing.
- An Efficient Algorithm for Projective Dependency Parsing
References
Citation
@online{bochman2022,
author = {Bochman, Oren},
title = {Syntax and {Parsing}},
date = {2022-03-29},
url = {https://orenbochman.github.io/notes-nlp/notes/cs11-737/cs11-737-w19-syntax-and-parsing/},
langid = {en}
}