Assignment 3 Ungraded Sections - Part 2: T5 SQuAD Model
NLP with Attention Models
NLP
Coursera
Lab
NLP with Attention Models
Author
Oren Bochman
Published
Tuesday, April 13, 2021
course banner
Welcome to the part 2 of testing the models for this week’s assignment. This time we will perform decoding using the T5 SQuAD model. In this notebook we’ll perform Question Answering by providing a “Question”, its “Context” and see how well we get the “Target” answer.
Colab
Since this ungraded lab takes a lot of time to run on coursera, as an alternative we have a colab prepared for you.
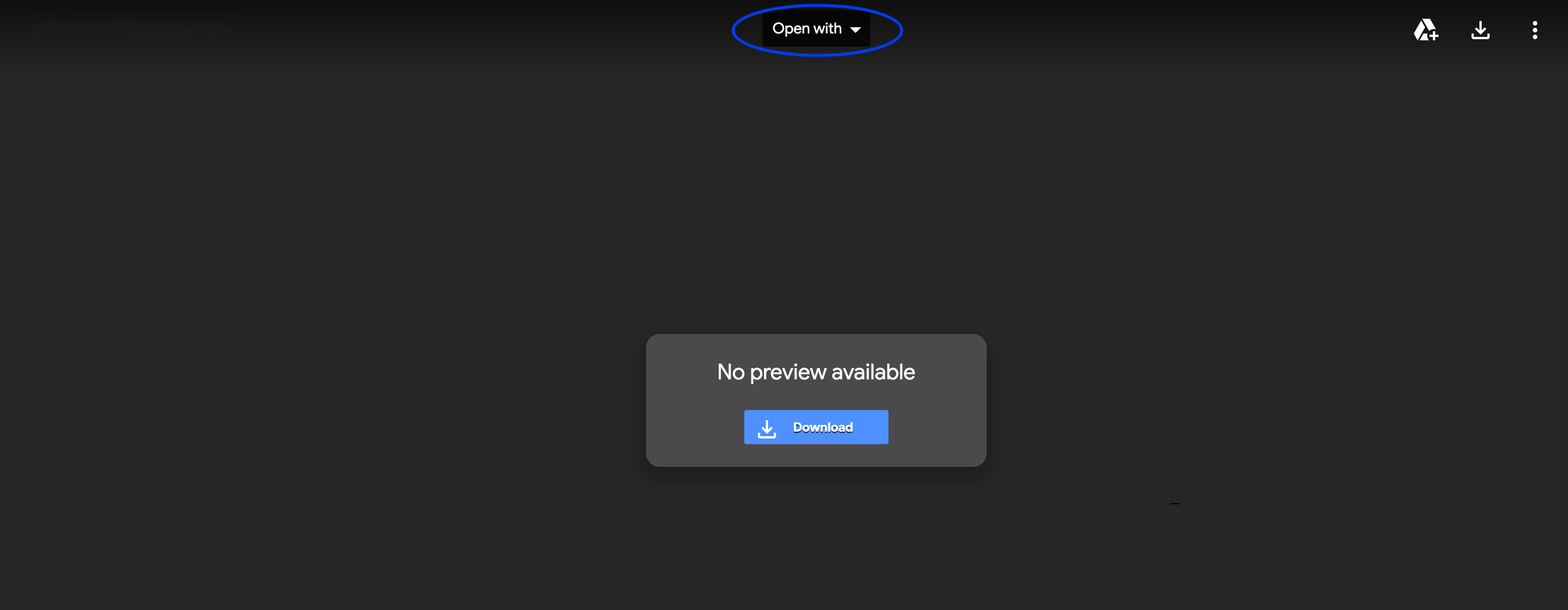
If you run into a page that looks similar to the one below, with the option Open with, this would mean you need to download the Colaboratory app. You can do so by Open with -> Connect more apps -> in the search bar write "Colaboratory" -> install
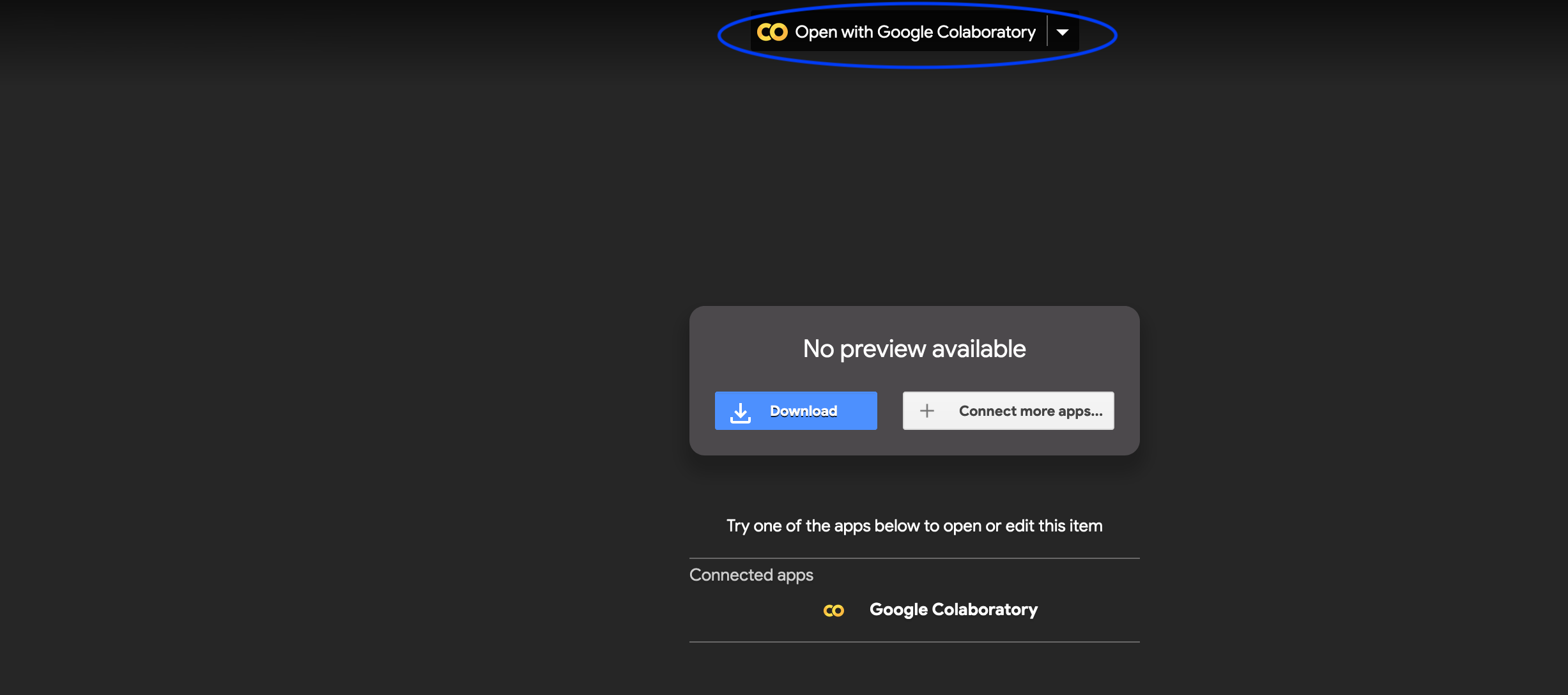
After installation it should look like this. Click on Open with Google Colaboratory
Implement the Bidirectional Encoder Representation from Transformer (BERT) loss.
Use a pretrained version of the model you created in the assignment for inference.
Part 1: Getting ready
Run the code cells below to import the necessary libraries and to define some functions which will be useful for decoding. The code and the functions are the same as the ones you previsouly ran on the graded assignment.
import stringimport t5import numpy as npimport trax from trax.supervised import decodingimport textwrap wrapper = textwrap.TextWrapper(width=70)
---------------------------------------------------------------------------ImportError Traceback (most recent call last)
Cell In[1], line 2 1importstring----> 2importt5 3importnumpyasnp 4importtrax
File ~/work/notes/notes-nlp/.venv/lib/python3.10/site-packages/t5/__init__.py:17 1# Copyright 2023 The T5 Authors. 2# 3# Licensed under the Apache License, Version 2.0 (the "License"); (...) 12# See the License for the specific language governing permissions and 13# limitations under the License. 15"""Import API modules."""---> 17importt5.data 18importt5.evaluation 20# Version number.
File ~/work/notes/notes-nlp/.venv/lib/python3.10/site-packages/t5/data/__init__.py:17 15"""Import data modules.""" 16# pylint:disable=wildcard-import,g-bad-import-order---> 17fromt5.data.dataset_providersimport* 18fromt5.data.glue_utilsimport* 19importt5.data.postprocessors
File ~/work/notes/notes-nlp/.venv/lib/python3.10/site-packages/t5/data/dataset_providers.py:28 25fromcollections.abcimport Mapping
26importre---> 28importseqio 29fromt5.dataimport utils
30importtensorflow.compat.v2astf
File ~/work/notes/notes-nlp/.venv/lib/python3.10/site-packages/seqio/__init__.py:19 15"""Import to top-level API.""" 17# pylint:disable=wildcard-import,g-bad-import-order,g-import-not-at-top---> 19fromseqio.dataset_providersimport* 20fromseqioimport evaluation
21fromseqioimport experimental
File ~/work/notes/notes-nlp/.venv/lib/python3.10/site-packages/seqio/dataset_providers.py:36 33fromtypingimport Any, Callable, Iterable, List, Mapping, MutableMapping, Optional, Sequence, Set, Tuple, Type, Union
35fromabslimport logging
---> 36importclu.metrics 37importeditdistance 38importnumpyasnp
File ~/work/notes/notes-nlp/.venv/lib/python3.10/site-packages/clu/metrics.py:66 64fromclu.internalimport utils
65importclu.values---> 66importflax 67importjax 68importjax.numpyasjnp
File ~/work/notes/notes-nlp/.venv/lib/python3.10/site-packages/flax/__init__.py:19 1# Copyright 2022 The Flax Authors. 2# 3# Licensed under the Apache License, Version 2.0 (the "License"); (...) 14 15# Lint as: python 3 17"""Flax API."""---> 19from.import core
20from.import linen
21from.import optim
File ~/work/notes/notes-nlp/.venv/lib/python3.10/site-packages/flax/core/__init__.py:15 1# Copyright 2022 The Flax Authors. 2# 3# Licensed under the Apache License, Version 2.0 (the "License"); (...) 12# See the License for the specific language governing permissions and 13# limitations under the License.---> 15from.axes_scanimport broadcast
16from.frozen_dictimport FrozenDict, freeze, unfreeze
17from.tracersimport current_trace, trace_level, check_trace_level
File ~/work/notes/notes-nlp/.venv/lib/python3.10/site-packages/flax/core/axes_scan.py:22 19fromjaximport lax
21fromjax.interpretersimport partial_eval as pe
---> 22fromjaximport linear_util as lu
24fromtypingimport Union, Optional, Callable, Any
26importnumpyasnpImportError: cannot import name 'linear_util' from 'jax' (/home/oren/work/notes/notes-nlp/.venv/lib/python3.10/site-packages/jax/__init__.py)
PAD, EOS, UNK =0, 1, 2def detokenize(np_array):return trax.data.detokenize( np_array, vocab_type='sentencepiece', vocab_file='sentencepiece.model', vocab_dir='.')def tokenize(s):returnnext(trax.data.tokenize(iter([s]), vocab_type='sentencepiece', vocab_file='sentencepiece.model', vocab_dir='.'))vocab_size = trax.data.vocab_size( vocab_type='sentencepiece', vocab_file='sentencepiece.model', vocab_dir='.')def get_sentinels(vocab_size, display=False): sentinels = {}for i, char inenumerate(reversed(string.ascii_letters), 1): decoded_text = detokenize([vocab_size - i]) # Sentinels, ex: <Z> - <a> sentinels[decoded_text] =f'<{char}>'if display:print(f'The sentinel is <{char}> and the decoded token is:', decoded_text)return sentinelssentinels = get_sentinels(vocab_size, display=False) def pretty_decode(encoded_str_list, sentinels=sentinels):# If already a string, just do the replacements.ifisinstance(encoded_str_list, (str, bytes)):for token, char in sentinels.items(): encoded_str_list = encoded_str_list.replace(token, char)return encoded_str_list# We need to decode and then prettyfy it.return pretty_decode(detokenize(encoded_str_list))
---------------------------------------------------------------------------NameError Traceback (most recent call last)
Cell In[2], line 20 12deftokenize(s):
13returnnext(trax.data.tokenize(
14iter([s]),
15 vocab_type='sentencepiece',
16 vocab_file='sentencepiece.model',
17 vocab_dir='.'))
---> 20 vocab_size =trax.data.vocab_size(
21 vocab_type='sentencepiece',
22 vocab_file='sentencepiece.model',
23 vocab_dir='.')
26defget_sentinels(vocab_size, display=False):
27 sentinels = {}
NameError: name 'trax' is not defined
Part 2: Fine-tuning on SQuAD
Now let’s try to fine tune on SQuAD and see what becomes of the model.For this, we need to write a function that will create and process the SQuAD tf.data.Dataset. Below is how T5 pre-processes SQuAD dataset as a text2text example. Before we jump in, we will have to first load in the data.
2.1 Loading in the data and preprocessing
You first start by loading in the dataset. The text2text example for a SQuAD example looks like:
The squad pre-processing function takes in the dataset and processes it using the sentencePiece vocabulary you have seen above. It generates the features from the vocab and encodes the string features. It takes on question, context, and answer, and returns “question: Q context: C” as input and “A” as target.
# Retrieve Question, C, A and return "question: Q context: C" as input and "A" as target.def squad_preprocess_fn(dataset, mode='train'):return t5.data.preprocessors.squad(dataset)
# train generator, this takes about 1 minutetrain_generator_fn, eval_generator_fn = trax.data.tf_inputs.data_streams('squad/plain_text:1.0.0', data_dir='data/', bare_preprocess_fn=squad_preprocess_fn, input_name='inputs', target_name='targets')train_generator = train_generator_fn()next(train_generator)
---------------------------------------------------------------------------NameError Traceback (most recent call last)
Cell In[4], line 2 1# train generator, this takes about 1 minute----> 2 train_generator_fn, eval_generator_fn =trax.data.tf_inputs.data_streams(
3'squad/plain_text:1.0.0',
4 data_dir='data/',
5 bare_preprocess_fn=squad_preprocess_fn,
6 input_name='inputs',
7 target_name='targets' 8 )
10 train_generator = train_generator_fn()
11next(train_generator)
NameError: name 'trax' is not defined
#print example from train_generator(inp, out) =next(train_generator)print(inp.decode('utf8').split('context:')[0])print()print('context:', inp.decode('utf8').split('context:')[1])print()print('target:', out.decode('utf8'))
---------------------------------------------------------------------------NameError Traceback (most recent call last)
Cell In[5], line 2 1#print example from train_generator----> 2 (inp, out) =next(train_generator)
3print(inp.decode('utf8').split('context:')[0])
4print()
NameError: name 'train_generator' is not defined
2.2 Decoding from a fine-tuned model
You will now use an existing model that we trained for you. You will initialize, then load in your model, and then try with your own input.
# Initialize the model model = trax.models.Transformer( d_ff =4096, d_model =1024, max_len =2048, n_heads =16, dropout =0.1, input_vocab_size =32000, n_encoder_layers =24, n_decoder_layers =24, mode='predict') # Change to 'eval' for slow decoding.
---------------------------------------------------------------------------NameError Traceback (most recent call last)
Cell In[6], line 2 1# Initialize the model ----> 2 model =trax.models.Transformer(
3 d_ff =4096,
4 d_model =1024,
5 max_len =2048,
6 n_heads =16,
7 dropout =0.1,
8 input_vocab_size =32000,
9 n_encoder_layers =24,
10 n_decoder_layers =24,
11 mode='predict') # Change to 'eval' for slow decoding.NameError: name 'trax' is not defined
# load in the model# this will take a minuteshape11 = trax.shapes.ShapeDtype((1, 1), dtype=np.int32)model.init_from_file('model_squad.pkl.gz', weights_only=True, input_signature=(shape11, shape11))
---------------------------------------------------------------------------NameError Traceback (most recent call last)
Cell In[7], line 3 1# load in the model 2# this will take a minute----> 3 shape11 =trax.shapes.ShapeDtype((1, 1), dtype=np.int32)
4 model.init_from_file('model_squad.pkl.gz',
5 weights_only=True, input_signature=(shape11, shape11))
NameError: name 'trax' is not defined
# create inputs# a simple example # inputs = 'question: She asked him where is john? context: John was at the game'# an extensive exampleinputs ='question: What are some of the colours of a rose? context: A rose is a woody perennial flowering plant of the genus Rosa, in the family Rosaceae, or the flower it bears.There are over three hundred species and tens of thousands of cultivars. They form a group of plants that can be erect shrubs, climbing, or trailing, with stems that are often armed with sharp prickles. Flowers vary in size and shape and are usually large and showy, in colours ranging from white through yellows and reds. Most species are native to Asia, with smaller numbers native to Europe, North America, and northwestern Africa. Species, cultivars and hybrids are all widely grown for their beauty and often are fragrant.'
# tokenizing the input so we could feed it for decodingprint(tokenize(inputs))test_inputs = tokenize(inputs)
---------------------------------------------------------------------------NameError Traceback (most recent call last)
Cell In[9], line 2 1# tokenizing the input so we could feed it for decoding----> 2print(tokenize(inputs))
3 test_inputs = tokenize(inputs)
Cell In[2], line 13, in tokenize(s) 12deftokenize(s):
---> 13returnnext(trax.data.tokenize(
14iter([s]),
15 vocab_type='sentencepiece',
16 vocab_file='sentencepiece.model',
17 vocab_dir='.'))
NameError: name 'trax' is not defined
Run the cell below to decode.
Note: This will take some time to run
# Temperature is a parameter for sampling.# # * 0.0: same as argmax, always pick the most probable token# # * 1.0: sampling from the distribution (can sometimes say random things)# # * values inbetween can trade off diversity and quality, try it out!output = decoding.autoregressive_sample(model, inputs=np.array(test_inputs)[None, :], temperature=0.0, max_length=5) # originally max_length=10print(wrapper.fill(pretty_decode(output[0])))
---------------------------------------------------------------------------NameError Traceback (most recent call last)
Cell In[10], line 5 1# Temperature is a parameter for sampling. 2# # * 0.0: same as argmax, always pick the most probable token 3# # * 1.0: sampling from the distribution (can sometimes say random things) 4# # * values inbetween can trade off diversity and quality, try it out!----> 5 output =decoding.autoregressive_sample(model, inputs=np.array(test_inputs)[None, :],
6 temperature=0.0, max_length=5) # originally max_length=10 7print(wrapper.fill(pretty_decode(output[0])))
NameError: name 'decoding' is not defined
You should also be aware that the quality of the decoding is not very good because max_length was downsized from 10 to 5 so that this runs faster within this environment. The colab version uses the original max_length so check that one for the actual decoding.