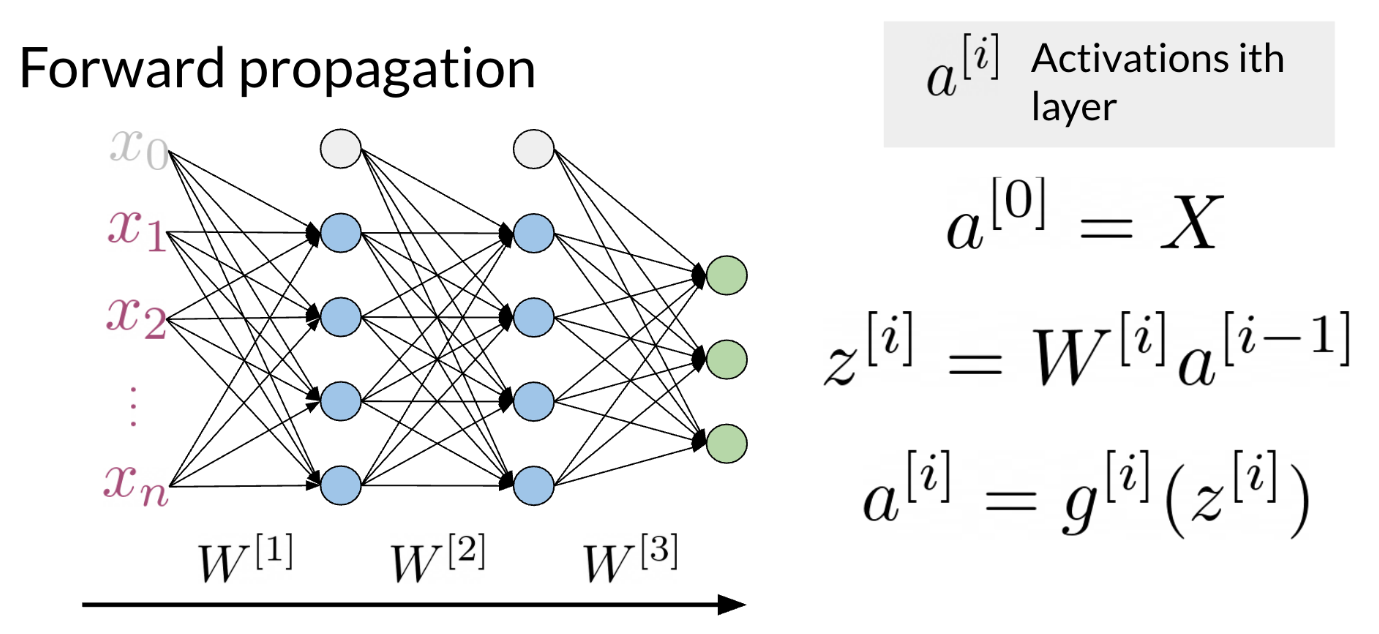
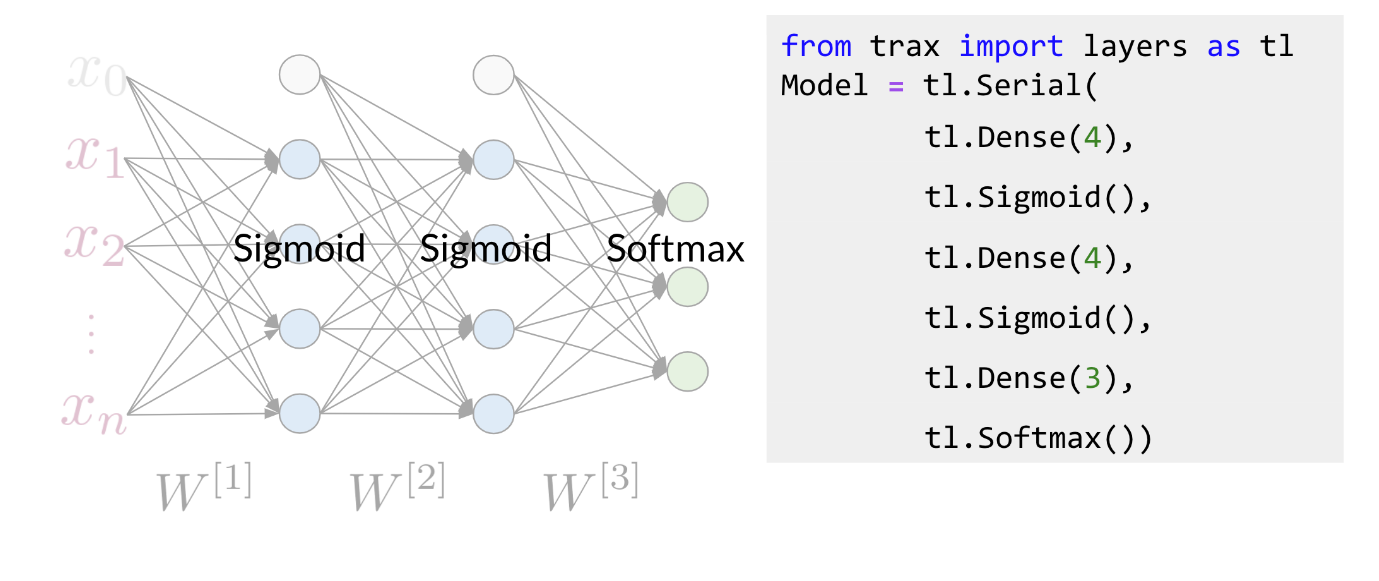
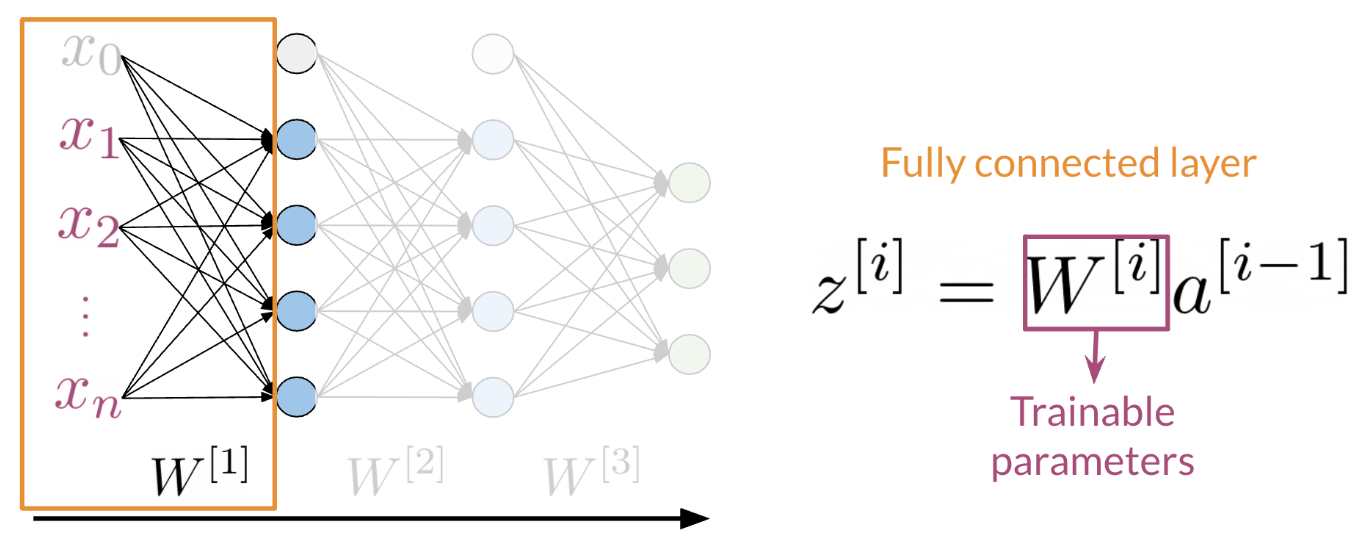
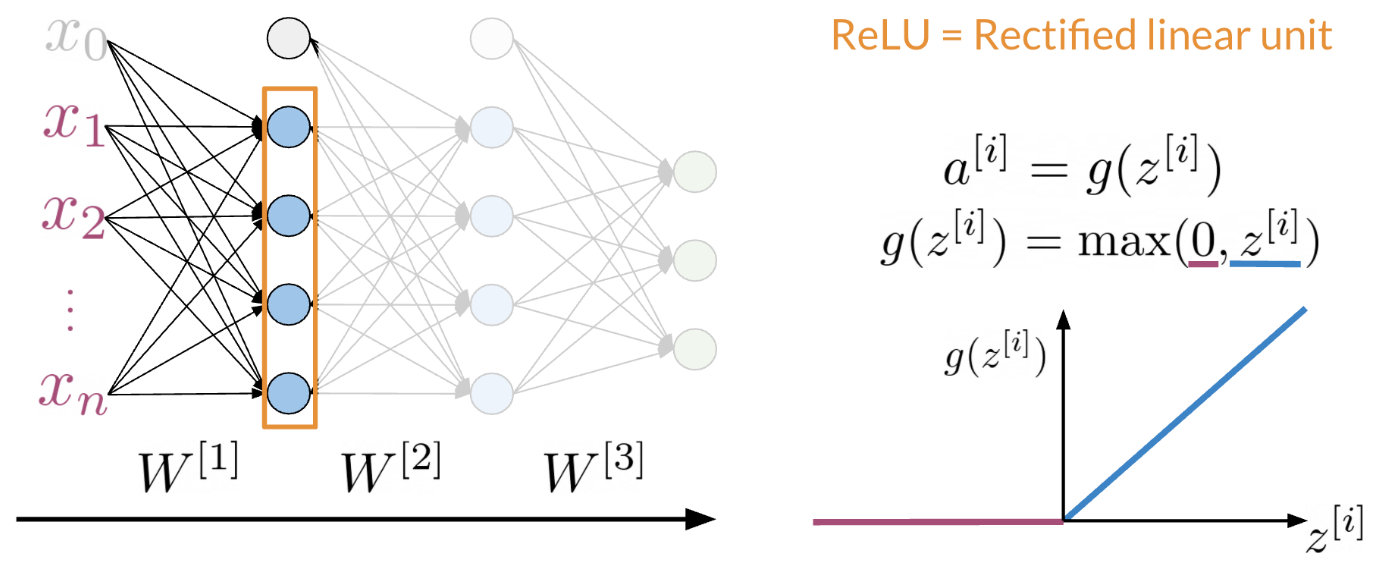
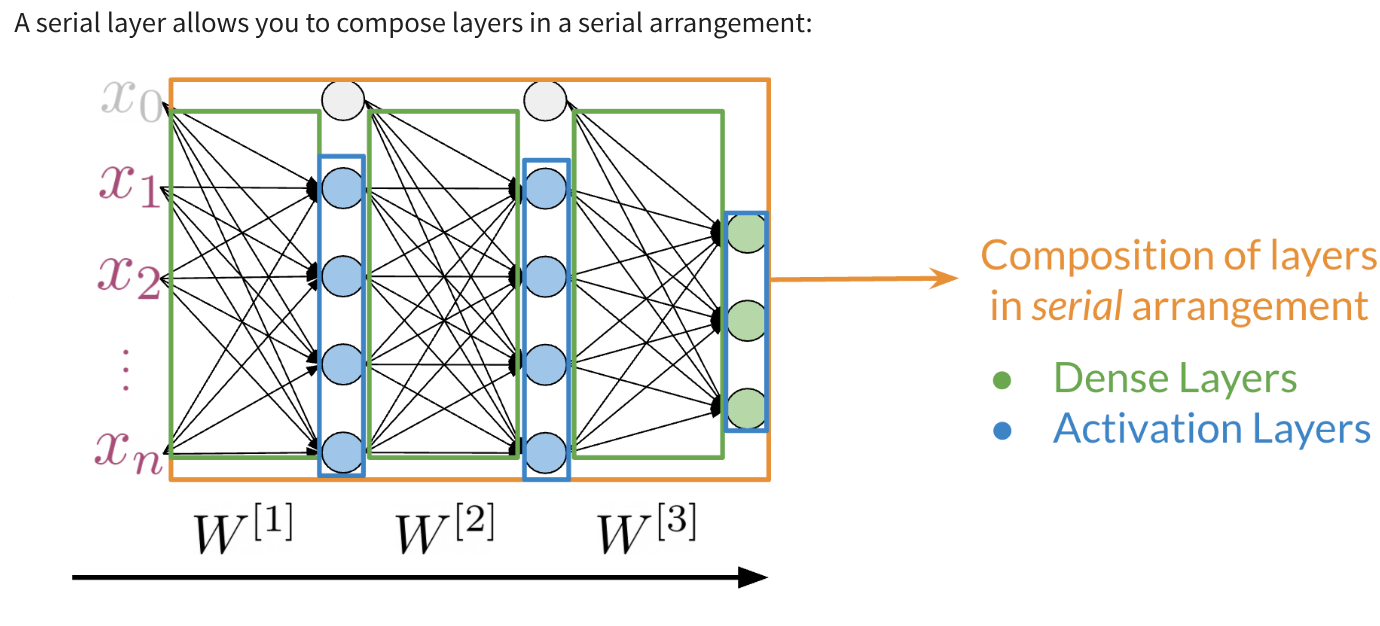
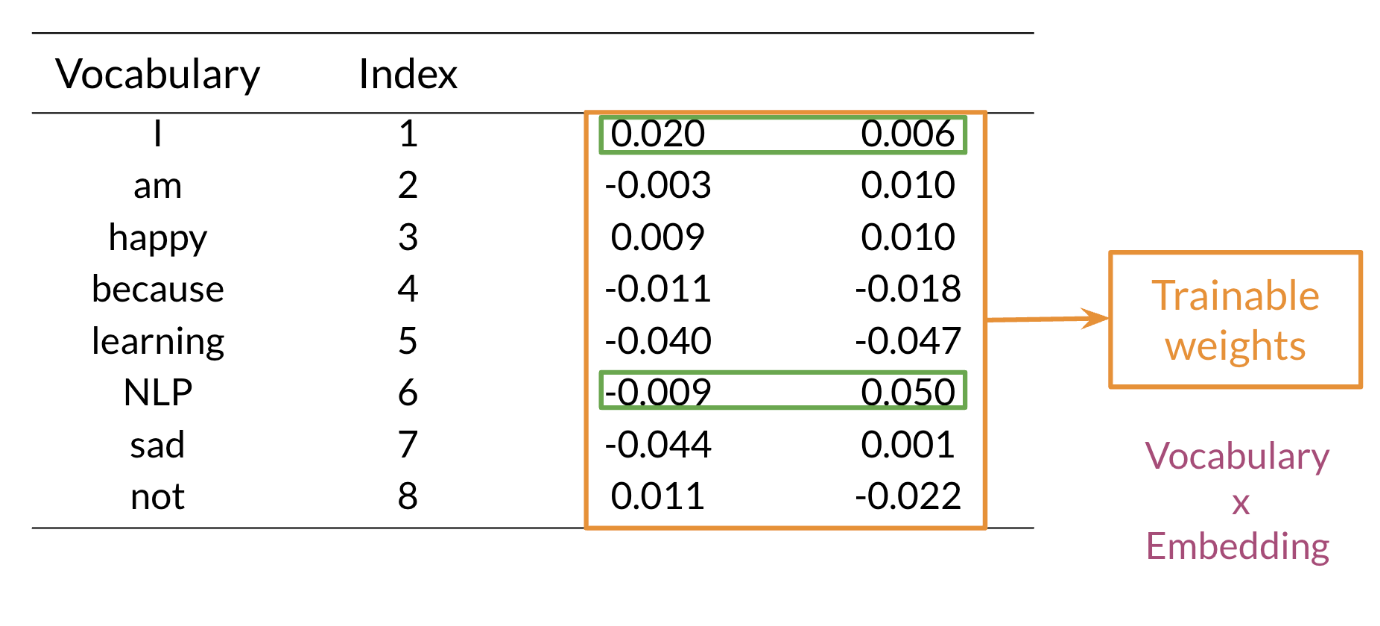
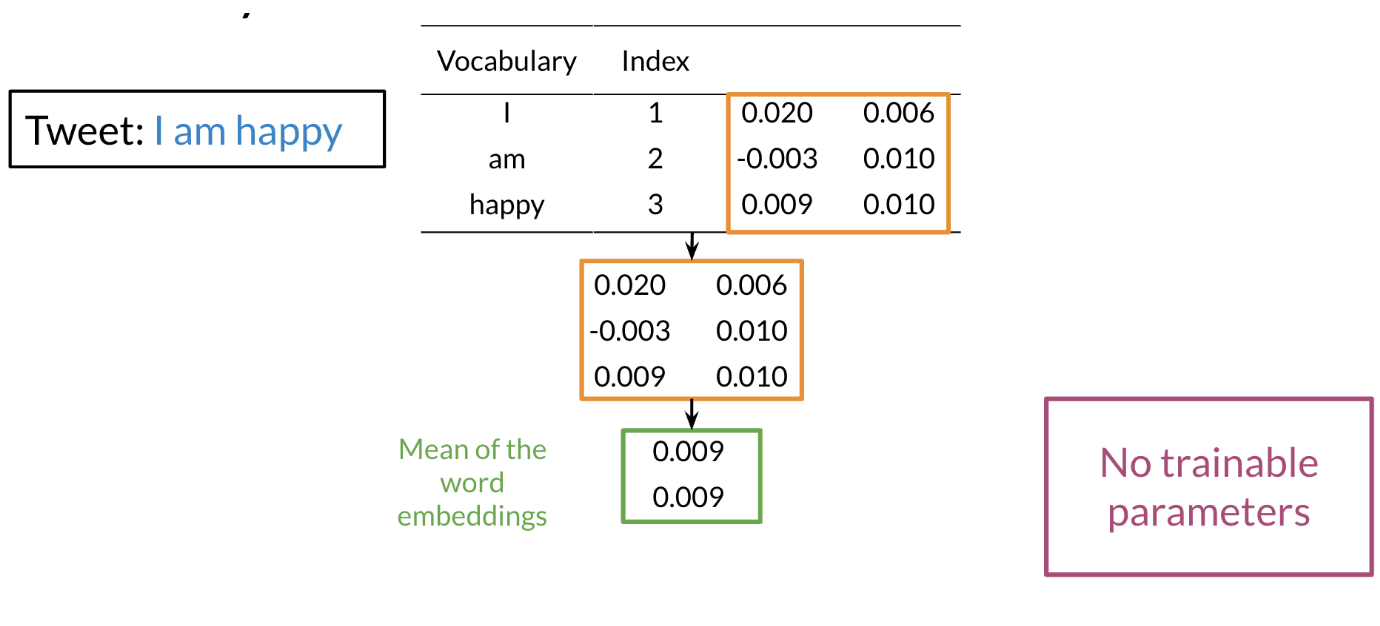
Hi. My name is Lukasz, and I want to tell you in this video why we made the machine learning library Trax. This is a little bit of a personal story for me. I’ve been at Google for about seven years now. I’m a researcher in the Google Brain Team. But before I was a researcher, I was a software engineer. I worked on a lot of machine learning projects and frameworks. This journey for me ended in the Trax library. I believe Trax is currently the best library to learn and to productionize machine learning research and machine learning models, especially sequenced models, models like transformer and models that are used in natural language processing. The reasons I believe that come from a personal journey that I took that led me here. I will tell you a little bit about myself and how I came here, and then I’ll tell you why I think Trax is the best thing to use currently for machine learning, especially in natural language processing. My journey with machine learning and machine learning frameworks started around 2014-15 when we were making TensorFlow. TensorFlow is, you probably know, is a big machine learning systems, it has about 100 million downloads by now. It was released in November 2015. It was a very emotional moment for all of us when we were releasing it. At that point, we were not sure if deep learning will become as big as it did. We were not sure how many users there will be. What we wanted to do was a system that’s primarily very fast, that can run distributed machine learning systems, large-scale fast training. The main focus was speed. A secondary focus was to make it easy to program the systems that wasn’t a reader, but it was not the most important thing. After releasing TensorFlow, I worked on machine translation and especially on the Google’s Neural Machine Translation System. This was the first system using deep sequence models that was used by the Google Translate team that was actually released as a product. It’s handling all of Google translations these days. Every language that we have has a neural model. It started with LSTMs and RNN models, and now it’s a lot of transformers. We released that in 2016 based on the TensorFlow framework. These models, they’re amazing. They’re much better than the previous phrase-based translation models, but they took a long time to train. They were training for days on clusters of GPUs at that time. This was not practical for anyone else to do rather than Google. This was only because we had this TensorFlow system, a large group of engineers who would ferry very well, and we were training for days and days. That was great. But I felt like this is not satisfactory because no one else can do that. It’s not possible to be done at the university. You cannot launch a startup doing that, because it was impossible if you were not Google, or maybe from Microsoft, but no one else. I wanted to change that. To do that, we created the Tensor2Tensor Library. The Tensor2Tensor Library, which was released in 2017, started with the thought that we should make this deep learning research, especially for sequence models, widely accessible. This was not working with these large RNN models, but while writing the library, we created this transformer model. This transformer has taken NLP by storm because it allows you to train much faster. At that time within a few days, now, it’s less than a day in a matter of hours on an 8 GPU system. You can create translation models that surpass any RNN models. The Tensor2Tensor library has become already widely used. It’s used in production Google systems. It’s used by some very large companies in the world and it has led to a number of startups that they know about that basically exists thanks to this library. You can say, well, this is done and this is good, but, the problem is, it’s become complicated and it’s not nice to learn and it’s become very hard to do new researcher. Around 2018, we decided it’s time to improve. As time moves on, we need to do even better, and this is how we created Trax. Trax is a deep-learning library that’s focused on clear code and speed. Let me tell you why, so, if you think carefully what you want from a deep-learning library, there are really two things that matters. You want the the programmers to be efficient and you want the code to run fast, and this is because what costs you is the time of the programmer, and the money you need to pay for running your training code. Programmer’s time is very important. You need to use it efficiently, but in deep learning you’re training big models and these costs money too. For example, using eight GPUs on-demand from the Cloud, can cost $20 an hour almost. But using the preemptible eight could TPU costs only $1.40. In Trax, you can use one or the other without changing a single character in your code. How does Trax make programmers sufficient? Well, it was redesigned from the bottom-up to be easy to debug and understand. You can literally read Trax code and understand what’s going to come. This is not the case in some other libraries, this is unluckily of the case anymore in TensorFlow. But, you can say, well it used to be the case, but nowadays TensorFlow, even when we clean up the code, it needs to be backwards compatible. It carries the weight of these years of development, and this is crazy errors of Machine Learning. There is a lot of baggage that it just has to carry because it’s backward compatible. What we do in Trax is we break the backwards compatibility. This means you need to learn new things. This carries some price. But what you get for that price, is that it’s a newly cleanly designed library which has four models, not just primitives to build them, but also four models with dataset bindings, we regression test these models daily because we use these libraries, so we know every day these monster running. It’s like a new programming language. It costs a little bit to learn, this is a new thing, but it makes your life much more efficient. To make this point point clear, the Adam Optimizer, the most popular optimizer in machine learning timesteps. On the left, you see a screenshot from the paper that introduced data, and you see it has like about seven lines. Next is just a part of the Adam implementation and patronage, which is one of the cleanest ones actually and you need to know way more, you need to know what are parameter groups, you need to know secret keys into these groups that key parameters by some means, you need to do seven stick initialization and some conditional to introduce either and other things. On the right, you see the Adam optimizer in TensorFlow and Keras and as you’ll see it’s even longer. You need to apply it to resource variables and two non-research variables and you need to know what these are. The reason they exist is historical. Currently we only use resource variables, but we have to support people who used the old non-research variables too. There are a lot of things that in 2020 you actually don’t need anymore, but they have to be there and painted and in TensorFlow code. While if you go to Trax code, this is the full code of Adam and Trax. It’s very similar for the paper. That’s the whole point. Because if you’re implementing a new paper or if you’re learning and you want to find, in the code of the framework, where are the equations from the paper, you can really do with this here. So that is the benefit of Trax. The price of this benefit is that you’re using a new thing. But there is a huge gain that comes to you when you’re actually debugging your code. When you’re debugging your code, you will hit lines that are in the framework. So you will actually need to understand these lines, which means you need to understand all of these PyTorch and all of these TensorFlow if you use those. But in Trax, you only need to understand these Trax lines. It’s much easier to debug, which makes programmers more efficient. Now this efficiency would not be worth that much if the code is running slow. Hey, there’s a lot of beautiful things where you can program things in a few line, but the run so slowly that it’s actually useless. Not so in Trax because we use the just-in-time compiler technology that was built in the last six years of TensorFlow. It’s called XLA, and we use it on top of Trax. These teams have put tremendous effort to make this coat the fastest code on the planet. There is an industry competition called MLPerf. In 2020, JAX actually won this competition, being the fastest transformer to ever be benchmarked independently. So JAX transformer ran in 0.26 of a minute, so in about 16 seconds, I think, while the fastest TensorFlow transformer on the same hardware took 0.35 minutes. So you see, it’s almost 50 percent slower. The fastest PyTorch, but this was not on TPU, took 0.62. So being two times faster is significant game. It’s not clear you’ll get the same gain in any model on other hardware. There was a lot of work to tune it for this particular model hardware. But in general, Trax runs fast. This means, you’ll pay less for the TPUs and GPUs you’ll be running on Cloud. It’s also tested with TPUs on Colab. Colabs are the IPython notebooks that Google gives you for free. You can select a hardware accelerator, you can select TPU and run the same code with no changes. It’s GPU, TPU, or CPU, on this Colab, where you’re getting an eight-code TPU for free. So you can test your code there and then run it on Cloud for much cheaper than other frameworks, and it really runs fast. So these are the reasons to use Trax, and for me, Trax is also super fun. It’s super fun to learn, it’s super fun to use, because we had the liberty to do things from scratch using many years of experience now. You can write model using combinators. This is a whole transformer language model on the left. On the right, you can see it’s from a README. This is everything you need to run a pre-trained model and get your translations. So this gave us the opportunity to clean up the framework, clean up the code, make sure it runs really fast. It’s a lot of fun to use. So I encourage you come check it out. See how you can use Trax for your own machine learning endeavors, both for research. If you want to start a startup or if you want to run it for a big company, I think Trax will be there for you.