
- Automatic Speech Recognition
- ASR models
Today i’d like to talk about uh automatic speech recognition uh this is uh one of the uh most uh the active uh research area in speech processing and also very important application for multilingual energy and today i will first explain about the speech recognition demonstration uh and also talking about evaluation metrics and the i will a little bit use the mass to explain about the formulation of the speech recognition and they will move to the explanation about the standard a speech recognition pipeline so uh let me first try to work on the demonstration um which i just tried to kind of use speech recognition here i want to go to the cmu campus affect right the technology and the i also want to show how the current sr technology is robust i want to go to the cmu campus oh it doesn’t work if i can work speak slowly i want to go to the cma campus that’s the current technology next i mentioned that the speech recognition is not a good for the noisy environment so let’s try to make the noisy environment i want to go to the cmu campus they are cool right yeah they are very very cool um so i try to kind of uh make some kind of a mistake uh but the google guides are doing a great job so it’s actually not easy to find some kind of a significant mistake with them one of the easy mistake that i can uh that try to make could be the the other query okay right yeah they should you know study more about me i will talk to my colleagues in google and the the other difficulty would be let me try so i mentioned that the speech recognition is not very good under the uh the simple noise it’s actually quite strong but if there are some uh the other speakers are speaking it’s still very challenging so i try to make this kind of situation okay so do you have you have a long like it’s not not if there’s scabbards raised in new york but i guess up there you all don’t have too long where we’re going i want to go to the cmu campus i want to go to the cmu campus but it’s actually not working quite well in general so um this is a current technology uh with some more other essays with the controlled environment the speech recognition is quite working well and today’s talk uh i will talk about the introduce about the speech recognition technology insider okay so uh the the first example i already mentioned this is one of the mistake that i found when i use acidity uh and yeah sometimes very good but sometimes it’s not working and the uh what kind of errors the speech equation has would be today’s uh discussion so please discuss it in the rest of the class after my lecture and the the now the many of the speech recognition engines actually also support the the other languages and i also uh try the uh japanese and it’s working quite well uh it i tried several times and then i found this kind of uh the the mistaken mistake but in general uh other uh language are also working quite well now and now i will uh move to the uh evaluation as you can see sometimes it’s perfectly revoking but sometimes it’s not working right and then the uh how to evaluate the major uh in speech recognition is quite important and the first uh the uh most intuitive measure would be the sentence level error anyway you know the the sentence uh uh correct or not i think it is the most other important measure i would say uh however uh by measuring the performance of the system in this case it’s almost correct right it’s just there are a few words are uh the wrong so i we actually want to give some partial score uh if the half of the rods are correct so to do that uh instead of using the sentence error rate uh we usually use the water rate and whatever it is computed by considering the three types of the error one is the insertion errors in this case uh this uh word is actually uh the the extra word compared from the difference so this uh the word error correspond to the insertion error and then the rest of the uh the error is the correspond to the substitution errors by the way it’s it is not unique of course you know uh we can consider this substitution uh this one is a substitution and the decision that other insertion uh and so on and usually we uh consider all the possible other error and then taking the minimum by also considering the each other cost of each error and then compute the edit distance i think many people here would be familiar with the distance so i may not need to explain about it indeed so much detail but anyway this uh is our kind of unusual uh uh measure to uh check the performance of the speech recognition and the um so this is a quite well defined major when we have a wide boundary but as you can see we have a lot of work uh the languages which actually don’t have a word boundary right and how to compute it there are uh two ways one is just using some uh the uh the tools to segment uh to get the gun in the world are you need and then other computing the model rate but we should be very careful about that because this chunking may depend on the tool or dictionary and so on i had a very bad experience that i had compared my japanese system and other other institute other systems and i are actually quite bad and i was very disappointed but i couldn’t reach to their numbers and finally we asked them how to chunk their word and their tools are different from ours and we actually cannot compare right so it is the other issue when we using the tanking but still uh if we use the same chunking we can compare so this is widely used but the mostly used uh the metallic for such kind of languages is actually character uh error rate just consider the the each character and the other computer uh edit distance so this is uh the more widely used when we uh the compute measure for the languages that doesn’t have hardware what boundary so the uh the assignment three that first you guys speak the uh the language right and then do the asl and do the evaluation be careful about the uh the which measure are are you guys using if the that language has a good word boundary you guys can use what uh error rate but otherwise a character error is safe yes when you’re speaking in japanese do you expect the system to transcribe the world cmu enrollment yes actually yes yeah the since uh it’s a kind of our other already the training data and so are mixed so other it’s uh the appeared other other the roman character uh in the japanese cases yeah japanese cases we have a ton of data so actually this kind of mix mixture will be handled by data delivery manner however are they that i think in some sense you’re right uh for example this cmu which can be also are the written other uh the katakanas sim the script which is the other or the japanese script to the described the word from the foreign countries and this may also happen instead of this kind of roman character happens and then in this case uh the other letter or character both cases it was correct but it’s not regarded as the wrong a mistake so actually uh in this sense the uh is depend on the language but the in some languages the same the world can be uh represented as a different script and then the uh the water right or even characteristic is not the perfect measure but this is a very difficult problem and usually we the normalize to either of the symbols or we actually don’t care so much about that and there are a lot of other metrics um since the the uh the script has an issue like as i mentioned some people use their phoneme literally but this actually lose the semantic other information a lot so uh this is uh used uh to more to uh that check the whether this uh the uh speech is acoustically phonetically uh the correct but it’s not sure it is the semantically uh the correct so it’s not so much used but anyway this is also another major prime error rate is also sometimes used but i skipped the other explanation and the other metrics decently these two uh the metrics are quite important the airtime factor in the latency since uh many of the systems are now in the uh the on the device and so on and the speech uh is used at the interface whatever speech has another application you know the offline archive uh and so on we don’t care about the uh at least latency a real-time factor other smaller may be better but the latest is quite important if you’re using a speech interface and the it’s also depend on the downstream uh evaluation metrics for example uh the if we combine this one uh with the uh the understanding system or if we combine it with the translation system uh of course we should evaluate it with such kind of downstream uh the evaluation method so in the speech transformation cases of of course it can be better if specification performance is better but we just check the group and the uh for speech recognition are the this uh the especially the characteristic of what error rate i recommend you to use the nist speech recognition scoring toolkit how many people knows nist nist is uh the government institute to standardize uh our uh the daily life activities uh including the uh the for example the um atomic clock and that was also uh the uh the standardized by the nist and the nist is actually uh helping us our community to standardize uh such kind of evaluation metric uh in speech and energy processing so uh and then of course if you know we use a different evaluation tools measures and then if this kind of result is different we cannot compare your result with others right so due to this reason i actually recommend you to use the sctk or other standard added the standardized or are the widely used uh the evaluation error evaluation uh metric uh then you know some tools that they did someone just made it to avoid to hover some uh the confusions again if the uh variation metric tools are different it is disaster right okay so uh with this kind of a great help from the uh the nist and so on uh the speech recognition actually uh was well measured in terms of the uh the the water rate or crop uh the kerati so everyone can for example either compare the performance the others are difficult right and they in the other previous lectures graham also discussed about the uh the blue or other evaluation metrics emerging translation and there are some discussions whether patreon is better or not while they’re at the characteristic there’s not so much discussion mostly it’s correct i say there are some kind of exceptions that i mentioned before but it’s mostly correct and also nice part is that this has a very high correlation with the downstream tasks better weather are definitely better in the speech translation right so anyway due to that study and also they start their needs are providing such kind of toolkit so that everyone can compare the error rate uh strictly so uh this is the one reason that the the speech recognition uh that has been studied for a long time with a common benchmark so now that everyone every field we have our other common benchmark and then you know performance major and readable and so on right speech condition actually has a long history of uh other comparing the techniques based on the shared uh the data are the same other evaluation metric and this is a kind of uh the the figure that i often show in this lecture uh this is a switchboard task and as i as i mentioned every month since 1990s up to now 20 to 30 years we still using this data and we still using the same vibration metric so that we can track the performance uh the improvement so this is possibly the one reason that actually deep running uh has been applied to many areas but the speech is actually one of the first area that deep running is applied since uh we can easily uh also fairly show the performance improvement uh based on this other evaluation measure okay uh so yes this area right whether this area is the the what when other i started speed recognition this area is one of the core data so are the any techniques that cannot improve the performance we also cannot uh the the the other further uh the the scale the training data and so on and also the uh uh the the budget big project uh the the uh kind of the the uh in this era for speech recognition uh anyway uh this is the kind of one of the other cold uh age in speech recognition it’s some slight improvement happens like a discriminative training and so on but uh before deep learning and this i i’ll say my most kind of a speech equation history by the way but i when i went to the conference we always talking about you know the method of a get a 0.3 percent well there are the improvement wow that’s a very good psychic only 2.3 or something like that yeah but the uh due to the deep running that’s kind of our are the uh the how they say we saw that this is the strings there and they cannot release to the human performance but thanks to the deep running and the computational uh the the uh the breakthrough gpu uh gpgpu and the strobe uh and also their open source or other other people’s uh did uh the knowledge uh sharing uh the now uh makes the performance to be included better and better okay so one more thing some people say speech recognition this search is easy this is because we have evaluation metric so the other areas it’s not easy because we have to start to make a variation method by ourselves or you know there’s multiple evaluation metric and we have to pick or something like that so instead speech condition is actually regarded as an easy research topic in terms of that we have a fixed evaluation metric so if you guys have a fancy neural network and then get the improvement by one person you can write the paper okay so uh i will move to the uh the uh speech recognition uh uh the oh yeah i need to kind of swap that a little bit using a mathematical formulation of uh speech recognition so first uh speech recognition as i mentioned in the yeah the the several times uh it’s quite uh interesting combustion problem input is completely physical signal wave pressure sound pressure right that’s undergoes the linguistic symbol so physical one becomes the linguistic uh symbol it’s very different right and the input other characteristics is also very different the waveform is gesture other than one sentence it can be like a two to three seconds and if with a final at the 16 kilohertz sampling grade the length will be the the order of ten thousand if we you use a short term fourier transform and other speech features it goes to the hundred dollar but still the bit long hundreds of thousands that only goes to the uh the three lengths of the symbols so uh a word uh in the vocabulary so this other conversion uh the from input and output is the i’ll say quite different and this actually makes the problem quite difficult okay so now i try to kind of explain that how other the speech function is realized one by one so the google uh the demonstration you guys just see that this is a one box right but it’s actually inside there are several books first one is the feature extraction this is i think i don’t have to mention about that so much about it any of the pattern recognition machine learning problem we first have our study the the feature extraction right and in speech anyway a waveform is not easy to deal with so instead we’re using the feature extraction called the uh mhcc i have a two more slides explaining this each of the modules so i will a bit more detail about it but anyway from now on i will start from the feature which is you know continuous vector time series of the continuous vector and then add a mapping to the word sequence how to formulate it one way is we just add hopefully uh making it a regression problem but instead the uh the people uh actually uh the the the formulate this problem uh more mathematically rigorous other ways they started to uh formulate this problem as a map decision theory here the posterior is from pw given node so the posterior probability of the word sequence are given the observation and then among all the kind of word sequence we just try to pick up the most likely uh sequence that’s because it becomes a speech condition uh quite simple right and the the the problem issue is how to obtain this pw given row so this is the kind of others the the speed recognition uh problem that we usually use for the probabilistic formulation and the just couple of the rules that we usually use i yeah if i have time i will explain bit more carefully about this one but anyway i just want to mention that why people using a probabilistic formulation there are a lot of reason but one of the reason is that we don’t actually have to remember various kind of equations we just have a three equation product rule sum rule conditional independence assumption conditional independence assumption is not rule but maybe just including this vector as a rule but by only using these three uh basic uh uh probabilistic rules we can actually other make this uh p double given no problem bit more tractable so the first thing that the people may often see for the speech recognition is to use a base rule to change this pw given o to p o w put p or given w p w divided by p o and then since the p o is not uh the uh depending on the w we actually uh the uh use the p o dot given w and the w so uh the two uh do to derive this one uh which rule other did we use from here to here mainly so yeah product rule yes so by using the product rule uh we kind of changing the problem uh from the original posterior distribution to the right grip and the prior distribution uh this is uh the methodology is called noisy channel model and the people actually using this method but is that enough to solve the problem for me it doesn’t actually change the difficulty or even that looks like it’s more difficult right and then the uh the how to uh the the make this uh problem more productive we actually uh the using the additional information so speech to text anyway this is a very different uh the conversion we want to have something between what they we can introduce like our linguistic knowledge we can use phoneme right and then the uh this is you know a little bit easier right from all to directory uh predicting the words are kind of difficult but by using the phoneme intermediate representation uh each kind of conversion is a bit sub problem and this is easier so this kind of a methodology is quite important to solve the very difficult combining problem okay so now we will we have our phoneme seekers let’s use the following sentence how to introduce this phoneme sequence in this uh the probability distribution some people may answer if either they took my course in the speech question and understanding which one we use some rule product rule coordination independence assumption it’s actually summer right some rule is great we actually can introduce the additional variable right still this is doesn’t change anything it doesn’t change the difficulties so how do the further other changes at this problem we just using the product rule like i mentioned before it’s part of the base rule but by using the product rule we can further factorize this problem to the three distribution and one the the other distribution in the denominator but this is not related to the our other optimization problem so we can safely actually ignore it right is that everything it’s actually not this is just equivalent uh the conversion right it actually doesn’t change the difficulty how to make the program more simple we’re using the conditional independence assumption for this case it’s where we use the condition of some individual functions here these are reasonable assumptions right the the relationship of the obligation speech features only depend on the election through the lexicon volume than the one it’s uh it’s a difficult approximation but it’s reasonable i would say right so we actually using this conditional independence assumption everywhere to make the problem attractable for example the acoustic model we first apply the conditional independence function hidden markov model is one of the conditional independence assumptions to make it tractable and uh we use a innogram language model now we use the neural language model which actually doesn’t have that but they used to use the endogram language model this is also conditional independence assumption so by using that we actually making this problem uh attractable and this methodology is quite rather powerful actually it’s not only used for speech recognition by the way this is also used for the machine translation as well you know before neural machine translation comes so uh actually the ibm uh is uh the the same other data the group same division are the proposed both speech recognition uh and the machine translation in this kind of a statistical form okay so now uh i uh decompose this uh the problem to the three distribution right this is actually structure uh that we uh that are solving the speech recognition so the first part feature extraction again this is not included in the probabilistic representation the first one is acoustic modeling lexicon language model it sounds like we just combined some kind of uh other sub problems right but it’s actually mathematically uh well uh decomposed and then we make each of the sub program tractable and then finally combine it based on the uh this uh the the equation this is the mass of the speech recognition or other other the problem of solving the secant sequence model before neural model comes the important concept is factorization to make the kind of problem to be decomposed and the other is its factorization itself doesn’t change the difficulty we also have to have a conditional independence assumption to make the problem practicable so uh i don’t know how you guys feel when i first learned this one i saw that this is very elegant the first thing that i just learned the speech recognition is these four components oh my god it’s just a complicated you know there are some modules that are combined to make a speech equation sounds like you know very cool but but a bit necessary but it turns out that it has a quite beautiful theory to other the original target is the base decision theory and i introduced each of the sub modules uh based on the uh the probabilistic formulation and actually at the in the uh the following uh the slide i will talk about each of the modules a little bit more but usually i skip the details and if you guys want to know more about each of the module and so on uh or please also consider to take a speech operation and understanding courses in the full semester okay um maybe i can accept one of a few questions here if not i can move to the each of the pipeline uh quickly um the first part uh feature extraction this is before you know the goes to the probabilistic model the feature extraction we use our other signal processing techniques uh to convert the waveform to the male frequency capture question mscc or other other features and i just want to think uh the multilingual energy this process is mostly uh the the language independent process as you can imagine right this is just a signal processing to convert the waveform to more tractable other part other feature so uh this is actually the the result of the conversion from the waveform to the uh ms60 i think most of people could agree the the bottom figures have more patterns right any more patterns so this has been very important uh to make the uh the feature uh to be uh used for the background of the processing uh by the way this signal processing based approach is gradually replaced by the deep running this is also happening now so one is the people using actually other cnn instead of mscg or some other people also using the sales supervisor learning now this is very powerful but the drawback is that this is a learnable learning based approaches so then the probably language independence property will be kind of mitigated to do that next acoustic modeling which converting the speech features to the following the sequence and for this other acoustic modeling uh we using the combination of the hidden markov model with gaussian mixture model or deep neural network and this approach is also the mostly uh language independent because speech features are more likely independent and the phoneme is also if we design well it can be a luggage independent or at least you know not so much other we can make it not so much depend on the languages although it is actually very difficult okay so the hidden markov model is uh the other actually quite important part in this uh the modeling what hidden markov model is doing is actually uh the um quite important role uh in the entire speech definition so as i mentioned the speech recognition the one over the difficulty is the output the symbol and the input uh the languages are very different so we need to make some arrangement uh all of the uh the speech features and the corresponding the following uh the information so in this case you know we don’t know which boundary we should take for each of the funding and to do this kind of alignment problem uh we are the classically uh using the hidden markov model and the hidden markov model is more like a charging of this other making this kind of alignment and given this alignment to provide a data accurate likelihood based on the as gaussian used to be gaussian but now deep neural network that is a kind of acoustic model and by the way this acoustic model part is the most important to get the performance than the other components in general the third module is the english and so on and this part is heavily language dependent so to do that uh we actually need to first access to get the other addiction information and i actually uh the uh usually show you the uh the cmu dictionary uh this is one of the most well-known uh english dictionary uh maintained by here but unfortunately it’s the stava is down now so i cannot make a demonstration uh and so on uh but uh this uh cmu dictionary the english is very lucky because we have a same reaction and then we can build a speech principle system the other language is it’s actually not easy to get that we don’t have so much kind of structure and the accessible dictionary in the other languages however other probably that i use this we dictionary and the if using navigationally we can also somehow get to the information about the other phoneme it’s actually covered many languages like this right by the way it’s not recovered yet not yet okay this is unfortunate so okay so uh by using that we can also uh the uh the use the other maker kind of of this uh dexcom component for each languages and the last part uh is the language model and the language model that we use the engram or a recurrent neural network and usually the first language model will be the the built is that the uh we uh try to kind of uh get the uh the uh how possibly uh that word uh uh given the pronunciation we can hover are the authority that given the kind of other the word sequence uh how possibly we select each language depending on the context that is what language model is doing and this uh the example i actually have these three uh the uh word sequence this is by the way the same go to the in terms of the phoneme and it can be actually go to or go to or go to right and then if for example check if we check the other uh this works journal sentences and check whether this but how many times this button appeared and then we can get the the uh how likely this other phrase appeared right go to appeared 51 times but the others actually are do not appear so this means that this go to will be most likely selected based on the language model right however this uh actually also other has some kind of other issues uh actually uh this pattern still exists in our languages so i actually include the text size from the ten thousand order to the median order and then can’t go to still other the biggest to more than two thousand can you guess how many times go to appears go to appears in the worst journal sentences two times only two times this is a one example it’s not completely good sentence but yeah it’s appearance right and the goal too there how many you you guys can guess it’s actually quite a large number and yeah most cases go too far uh this is the other sentence that the uh the uh the overnight show i saw when i uh search this other two other phrases so if we using the small corpus it doesn’t cover but if using the large coppers we can cover it so this is a kind of power up if using a large purpose we can cover many of the various are the language patterns as much as possible and this part is also language dependent so uh this is the most uh the the the building block of the speech recognition and actually i’d say that it is not easy to build that for you guys each of the components is governed by the different model feature extraction signal processing model acoustic model other pattern recognition machine learning deep learning and so on next come moderate coming from the other computational linguistic or other linguistics language modeling is also come from the nlp or are they now deep learning but anyway the each of the other modules has a different models so it is very difficult to actually develop all of them and also connecting all of this kind of module is also not easy so instead now people are also working on the uh end-to-end speech definition which try to make entire pipeline as a single neural network google’s a demonstration it’s actually they already switched to the end-to-end neural network other companies as far as i know they still didn’t add a seat to the neural network and to the neural network but either by using this pipeline and the uh the so maybe yeah maybe that’s it i want to uh finish my talk so uh the these are summary uh of the speech recognition first feature condition is very well defined problem and also fortunately we have a large corpus so it is quite you often use other other measure for the for our new machine learning algorithm and the factorization and making the problem productive this is a kind of great methodology for us to tackle this problem and the but since uh the this methodology is a bit complicated recently people are also that are the uh they’re the interesting and actually having a lot of development in the end to end a speech equation feature recovered in my next lecture and then this is the main topic or the other assignment three so please uh enjoy the speech recognition and let’s move to the discussion um the uh the priests i think you guys already tried a speech recognition engine by yourself right and then talk about what kind of errors you happened and also apply to the other language and discuss about it and since we don’t have enough time we don’t have our final discussion time just split and then either discuss it and then finish it okay so let’s just
Outline
- Speech Recognition Demo and Evaluation Metrics
- Demonstration of speech recognition.
- Discussion of how well it works, and examples of when it fails.
- Evaluation metrics.
- Evaluation Metrics
- Sentence error rate.
- Discuss if the entire sentence is correct.
- Explain why this is too strict of a measure, and the need to consider local correctness.
- Word error rate (WER).
- Using edit distance word-by-word.
- Calculating error rate percentage.
- How to compute WER for languages without word boundaries.
- Other metrics.
- Phoneme error rate (requires a pronunciation dictionary).
- Frame error rate (requires an alignment).
- NIST Speech Recognition Scoring Toolkit (SCTK).
- Sentence error rate.
- (A bit) Mathematical Formulation of Speech Recognition
- Speech recognition as a conversion from a physical signal to a linguistic symbol.
- Explanation of probabilistic formulation.
- MAP decision theory to estimate the most probable word sequence.
- Noisy channel model.
- Factoring and conditional independence.
- Standard Speech Recognition Pipeline
- Feature extraction.
- Converting waveform to MFCC.
- Language-independent process.
- Desirable representations.
- Acoustic Modeling.
- Converting speech features to phoneme sequences.
- Using Hidden Markov Model (HMM) to align speech features and phoneme sequences.
- Language-independent.
- Lexicon.
- Pronunciation dictionary.
- CMU dictionary.
- Multilingual phone dictionary.
- Language Model.
- Using N-grams or recurrent neural networks.
- Word selection based on context.
- Language-dependent.
- Feature extraction.
- End-to-end Speech Recognition
- Using a single neural network.
- A simpler solution for multilingual ASR.
Papers
Warlpiri in 10 minutes
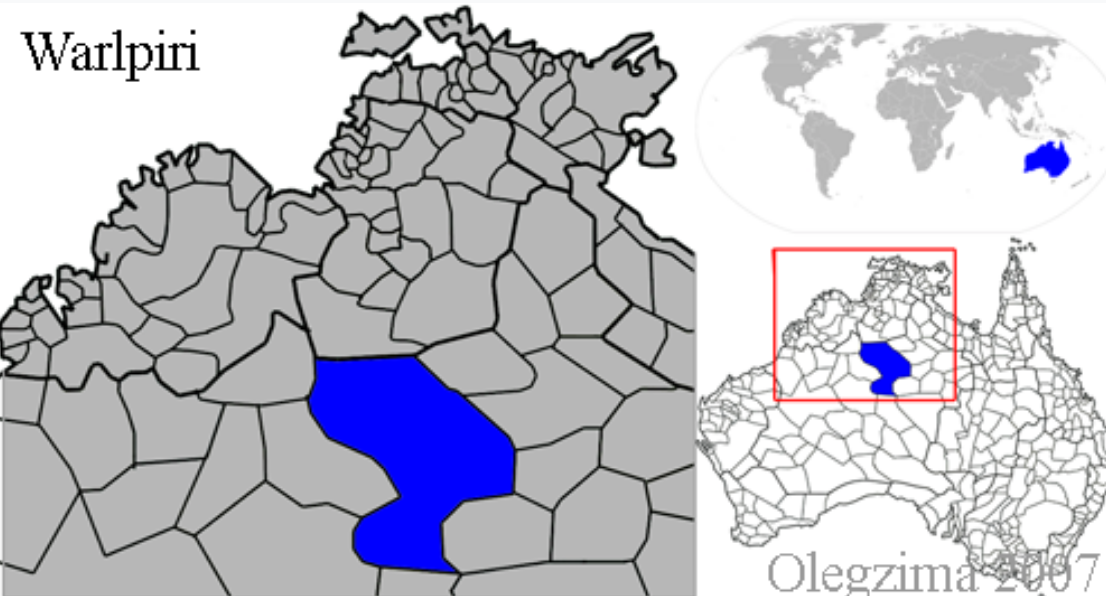

- Spoken in the Northern Territory of Australia by the Warlpiri people.
- Approximately 2,500-3,000 native speakers.
- One of the largest Aboriginal languages in Australia based on the number of speakers.
- One of only 13 indigenous languages in Australia still being passed down to children.
- Alternative names include Walbiri and Waljbiri.
Language Family & History
- Pama-Nyungan.
- Ngarrkic languages.
- The term Jukurrpa, referring to Aboriginal spiritual beliefs, comes from Warlpiri.
- A writing system was not developed until the 1970s when the language began to be taught in schools.
Grammar
- Free word order, but the auxiliary word is almost always the second word in a clause.
- Ergative marking. The actor takes a special ending called the ergative ending. The ergative ending marks the subject of a transitive sentence.
- Split ergativity. Nouns follow one set of rules, while pronouns and auxiliary verbs follow another.
- Suffixes indicate person and number of the subject and object.
- Vowel harmony.
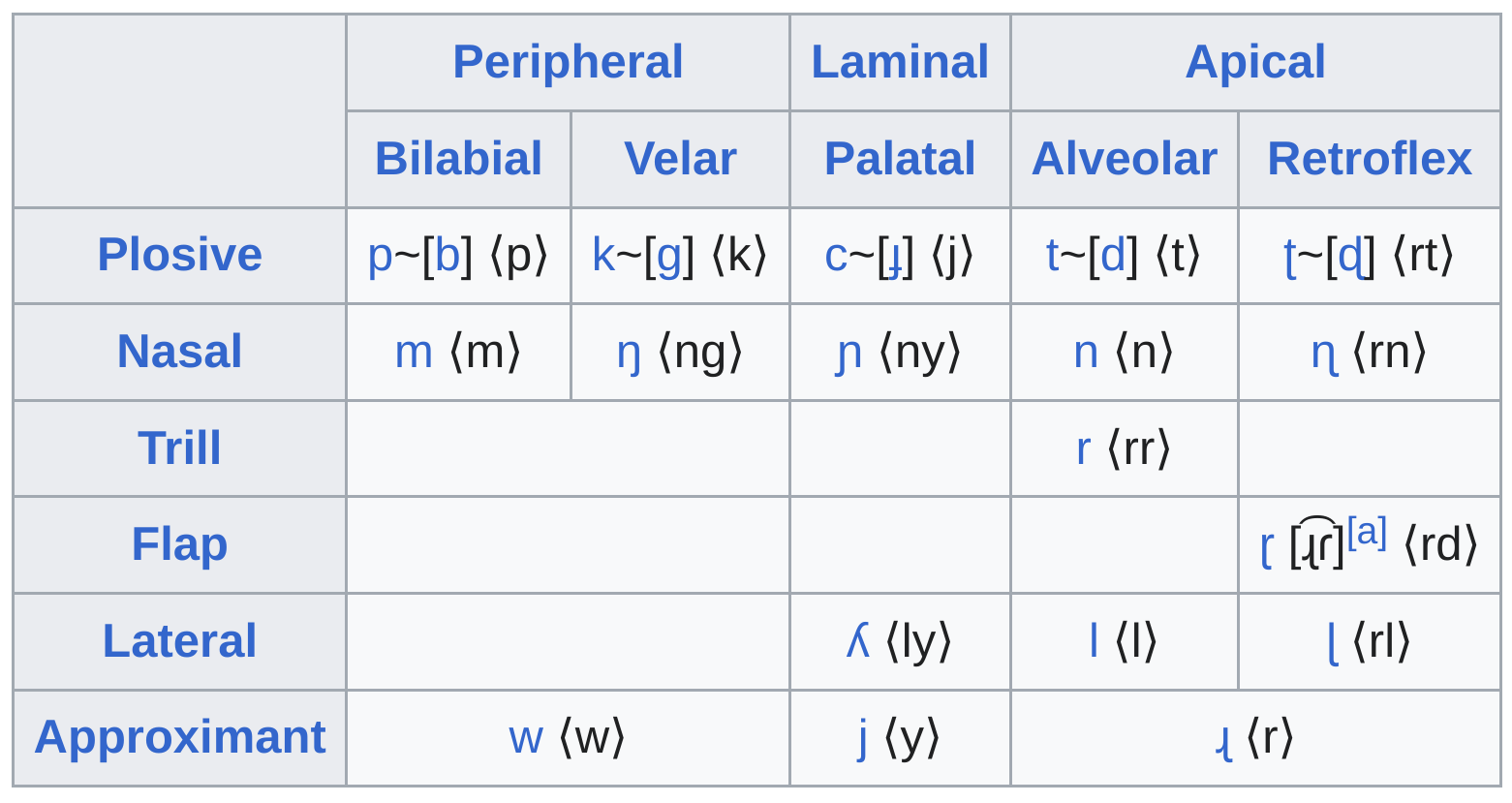
Phonology
- Most Warlpiri languages have only three vowels.
- No voicing contrast. Aboriginal languages have no contrast between voiced and voiceless consonants. A sound can sound like a ‘p’ or a ‘b’ depending on its position in the word.
- No fricative sounds.
- Love the ‘r’ sound. Warlpiri has three ‘r’ sounds.
Interesting Linguistic Features
- Avoidance register, a special style of language is used between certain family relations that have a drastically reduced lexicon.
- Warlpiri Sign Language also exists.
- Speakers are often multilingual, learning each other’s languages.
- A strong tradition exists of not saying the names or showing images of people who have passed away.
Present Status
- Warlpiri is considered a threatened language because children sometimes respond in English even when spoken to in Warlpiri.
- There are efforts to teach the language in schools and create modern terminology.
Citation
@online{bochman2022,
author = {Bochman, Oren},
title = {Automatic {Speech} {Recognition}},
date = {2022-03-03},
url = {https://orenbochman.github.io/notes-nlp/notes/cs11-737/cs11-737-w14-ASR/},
langid = {en}
}