
- What is a Word, What is Morphology
- UD Treebank Morphology Annotations
- Morphological Analysis
So now we’re going to move on to the main part where we’re going to talk about words which sort of seems really fairly appropriate for any any nlp class because words are pretty important okay and this is going to give you a little bit more definition of what we mean by words and how that’s not always as well defined as it might be in languages like English so let’s try and count the words in this sentence bob’s handyman is a do-it-yourself kind of guy isn’t he okay so that’s a fairly standard sentence although I have selected it to be particularly interesting for this case but the question is where are the words okay so what I’ve done is I’ve tried to highlight what people might think the words actually are now if you grew up in europe and maybe other places as well you probably think that white space separated tokens is a good approximation for words and it is a good approximation for words but from a linguistic point of view it’s actually a little bit more complex than that and that’s what we’re actually going to talk about and when we actually look at other languages that’s the thing we want to highlight that the notion of what a word boundary actually is might not be as trivial as what you hope it’s going to be okay
Whitespace
Let’s have a look at the first word of the white speak white space identified token is Bob’s the apostrophe s is what’s called a clitic it’s not isolated word on its own it can’t stand on its own it only appears when it’s actually bound to some other word but in some sense it’s independent of the word that it’s bound to so what you can have is actually it can go into whole noun phrases rather than just single words so we talk about jack and jill’s bucket we’re not talking about Jack and Jill’s bucket we’re talking about Jack and Jill in the bucket belonging to Jack and Jill so that apostrophe s isn’t just going on the immediate token before but a bunch of tokens before that okay so be aware that that apostrophe s is a somewhat special thing in English and sometimes it’s a good idea to actually separate that apostrophe off and treat it as an independent token than actually just putting it together as bob’s let’s look at the next one handyman is really a now known compound okay we put a space in it because we’re not German but but some compounds in English, don’t get a space between them and it’s sort of really quite complex to know which ones are which and it’s really sort of up to the speaker and to decide how to do that but sorry the writer from the speaking point of view it’s even harder to distinguish between these but handyman really here is being used as a single word and it would be useful to keep them together even though they have a ascii white space between them is is a word as a word now let’s have a look at do it yourself it’s hyphenated and it really is a sort of set phrase it can be shortened to diy and we’d like to treat that as a single word but sometimes hyphenated forms should be separated and we have to make interesting decisions about that now we’ve got words like kinda and isn’t it that are fairly standard contractions in English we could write them out as kind space off and we could write isn’t it as is not but often when people are speaking they don’t do that and they actually do reduce form and sometimes when writing they may actually do that simplified form as well and do use these contractions and we have to make some decision about how these actually might appear and whether we want to separate them out many of these are sort of closed class they can only be applied to a number of words and they’re not general to anything but some of them are not apostrophe s can clearly go into anything and apostrophe ll can sort of go into any noun as well so that’s a hard it’s a decision that we actually have to make and it will affect all of our downstream tasks once we decide how to token these tokenize these into what we’re going to term words how we’re going to have word embeddings how we’re actually going to do parsing or whatever our next task is going to be.
Other Languages
In other languages it can be way more complex and sometimes way more simple. It could be that we actually have no spaces whatsoever and everything is joined together agglutinated and there has to be some process to try to separate these individual parts out if we don’t separate these things out what you’re going to have in a language is an awful lot of words so if you look at turkish for example which is an agglutinate language there’s an awful lot of compounding in it an awful lot of interesting morphology in it what you end up with is the number of words number of white space separated tokens and in the language is much bigger than English for because what we maybe think about as being phrases in English are actually whole single words with no white space between them there also can be ambiguity in those particular words about how we actually decompose them and on the right here we actually have a hebrew example where I’m sorry I can’t read that this where it can mean depending on how you separate that out into individual morphemes and her saturday and that in t and that her daughter all of those are potential meanings given the rest of the context but they’re all written as the same single word
Linguistics
Now let’s go back to our knowledge of linguistics and see how we might be able to use our knowledge of linguistics to be able to answer these questions about what words actually are.
Because we’re going to look at each of those and see how they we might be able to use that as a definition of a useful way of splitting things into little bits words so there could be phonetics so there could be something about the way things are being said that could actually tell us something about that we could say it’s got to have a of every word has to have a vowel in it although I don’t know where apostle vs which sometimes is a violent and sometimes doesn’t sometimes and it’s sometimes just phonology and it could be something about there’s some structure that’s actually required in syllables and so everything has to be at least one syllable if it has to be a word it could be morphology if we’re looking at the actual atoms that are in the morphemes that are in the word we could talk about the individual morphemes in there and make some definition based on that we could talk about syntax we could talk about whether we could exchange that for another word in the same class and treat those as being words if they have classes over them we could talk about semantics of whether it changes meaning and we could talk about pragmatics about realistically new york is used as a single word even though we happen to put a space in it but it’s treated basically as a fundamental a word because although it maybe historically has some relationship to the word new and the word york it really has nothing to do with that anymore let’s have a look at the orthographic
Orthography
Definition so this is where white space comes into mind and be aware that even in English white space is quite complex So you know we’ve got spaces we’ve got tabs we’ve got new lines we’ve got carriage returns we’ve got vertical tabs are all within the standard ascii set but beyond that we actually have a lot more if we look at unicode and we want to make definitions of that and we also have things like non-breakable space and a non-breakable space can be used and may appear on on on the web in html and we may or may not want to decide that as being a word boundary or not depending on our definitions okay and remember we’re talking here about orthography we are pretending that the whole world writes everything down and that when they write everything down it’s the same as what speech is most languages are not written we write an awful lot and most people on the planet are actually literate but they may speak languages that they’re not literate in and when you speak you don’t put any spaces between words okay you don’t say a space between each word and we don’t do that at all okay and so when you’re wondering how chinese people can understand chinese text when there’s no species in it think about how well you can understand speech which has got no species in it and yet you can still deal with it and the notion of a word has been around for a lot longer than the notion of writing so in other words we’ve had that notion and we need a definition of words that are actually independent of the written form
Prosodic
There can be a prosodic definition a prosodic definition is something to do with international phrases they can be hard to define but they’ll still have some reasonable definition and things which are actually grouped together in the single international phrase are often written as a single word in other languages so for example in the park in English the way I just said it is as a single international phrase in the park and many other languages would have the same concepts of location and determiners and park all in the single word that would have no spaces between it so in the park could be treated as a single word depending on what your definitions are going to be
Semantic
Semantic definitions these are word units that got some something like the same idea and so it might be useful to be able to treat these in a reasonable way we can think about colors that might have multiple names we can think about navy blue is is a color and but when written it would have probably have a space in it but we may want to treat that as a color which is the same as blue or red or yellow or any other single word color because navy blue is still a color okay and although technically maybe has something to do with glue and something to do with navy it might not be a reasonable thing to actually separate it out we can have a syntactic definition where we’re looking at blocks in these sentences so again new york is a good example here where it really is being used in the same sense as the word pittsburgh is it’s referring to a particular city in north america and just because it’s got a space in it doesn’t mean that we want to treat it as two different cities a new city and a york city which is elsewhere in there’s almost certainly places called york in north america but I can’t. Well there’s a one just outside toronto now this comes to the notion of how can we identify classes of words and I’m currently really talking about syntactic classes of words rather than semantic classes so so colors are sort of a semantic class but I’m interested in what words have got the same class that I could exchange them without what it might change the meaning but you know they get used in the same way now we’ve all been talking talk about these standard open classes which appear in most languages not all languages but most languages nouns verbs and adjectives and adverbs there’s almost an infinite number of those new ones can come along that didn’t exist before but they all fall into these particular classes. This is in contrast with closed classes where there’s a finite set in the language they’re sometimes called function words. It might be a difficult class to list absolutely everything but you rarely very rarely find new things moving into that class so things like prepositions so in above behind there’s a sort of finite set of those determiners the and ah this and that and pronouns I are somewhat finite in English conjunctions and or but not an exclusive or if you’re a computer scientist and other auxiliary verbs like is was have etc and these are sort of closed class they’re very common in the language they’re often short in a language and in most languages have something like them they might be something to do with morphemes but they don’t have random new ones appearing every day so if we think about what happens with the open class think about words which you know exist today that didn’t exist five years ago and think about some can you type them in the chat words which we have today that we didn’t have five years ago and you’ll find out that they’re all nouns verbs adjectives and adverbs and not closed classes because can anybody think of any words which we have now that we didn’t have five years ago covid excellent example I’m sorry to disappoint you, but if you have a look at wikipedia in 2015 there’s an article on coveted okay but it was dull and boring and uninteresting and the covered self-help group decided that they wanted to do something and become more popular but you’re right that covert was incredibly rare okay and probably was only used in occasional circumstances doom scrolling excellent quarantine yeah wfh all of these things are very very common now and sort of didn’t exist at all before and language is like that but all of these words for the most part are coming in to be nouns and verbs okay occasionally they’re going to be adjectives and maybe adverbs but for the most part these do change over time so you can’t list them all but for the close class ones you can sort of do it I mean there’s some really rare conjunctions that people don’t use nowadays like not withstanding okay apart from used as examples of really rare conjunctions that’s about the only time I use that word
Tag Sets
There’s a bunch of classes that define what part of speech tag sets the tags that are actually there and in English and many other languages they’re often based on the tag set that was used in the pen tree bank which was one of the first large data sets that was labeled consistently with nouns verbs etc and there’s 43 in total I don’t know if there’s 43 there but I know from other things and there’s some that are relatively rare and maybe questionable and there’s some compound ones where sometimes things get joined together it does make distinctions between different types of nouns singular plural and and proper nouns and it it’s quite useful in many tag sets that are now used in in NLP are derived from this tag set because that was decided mostly by the group at U-pen at the time people were doing a part of speech tagging before that. I mean even before computers they were doing it but coming up with a finite computational tag set was something that really started in the 80s and depending on the language that you’re dealing with you may want to have different tags because there are some tags that are really only relevant in some languages and not in others okay importantly there actually is a definition of a small number of tags which is in some sense a reduction of the number of tags that were in the pen tree bank that has been used in the universal dependency m sets that originally came out of google and it’s now an independent project but it’s still quite google influenced because of the original data sets and this covers somebody’s going to tell me the number of languages but I think it’s about 40 or 50 languages where they’re all labeled with the same tag set and produces a universal dependency grammar which is also very use useful from a syntactic point of view that over a bunch of fairly major important languages okay so getting this tag set is useful and you might say why should I care about getting a tag set I can train from words and the answer is yes if you have lots of data but as usual in trying to do machine learning if you can give more information in a structured way or in a reduced standardized way you can typically get by with less data and try to train better and training should happen faster so often being able to get a part of speech for a language would be quite useful and of course this is going to be hard in the low resource language because you sort of need labeled data to start off with but there are unsupervised ways to try to find out what these tags actually are now I’m naively talking about words here and words having part of speech tag because I’m one of these English speakers where actually for the most part that’s pretty easy in English for the most part you know white space separated tokens or words and for the most part each token has got one a tag one proper tag and the context mostly defines what it is but in most languages most languages and we really have to introduce the notion of morpheme which is sort of the single smallest atomic part of a word
Morphology
Here for example in English we do have interesting morphology especially in what’s called derivational morphology which is not like the ing eds plurals where we’re changing some syntactic property the tense or the number of a language but we’re actually changing the meaning and we’re often changing the class the part of the speech class so if we take a verb like establish we can have another verb that’s disestablished we can then make that into a noun by say disestablishment.
We can make it another noun putting anti- in front of it and saying anti-disestablishment. We can make it into an adjective by saying anti-disestablishmentary. We can make it a noun into anti-disestablishmentarian. We can then make that in a further noun by saying anti-disestablishmentarianism Now these things are a little bit extended, but actually we do this all the time. So it’s actually quite hard to really list all of the words that are in English because although some of these don’t appear very often. There will be new and novel words, and you’ll see a number per day of new words that you’ll understand. Where they’re actually morphologically variants of something that you can work out what the meaning actually is.
Now so it would be useful if we could get these words and decompose them into their roots and morphemes so that we can actually work out what the important classes are. So we’d like to be able to get some notion of these decomposed forms in from a word if we can do it. Now some of these forms are what we call stems or roots they’re often words on their own. And we’ll have prefixes and suffixes.
In English we rarely have anything that inserts in the middle of a word we’re usually putting things at the beginning and end. In some languages you actually get sort of bracketed things that you have to put them at the beginning and the end some of the gaelics have got that. There are some things where you can actually put infixes and so there are some plural things that actually happen in interesting languages in southeast asia where they’re basically plural things where syllables or partial syllables will get duplicated and and therefore you have to deal with that.In English the only example of being able to do that is the infix form of putting swear words in the middle of a word so for example if you have the words pittsburgh and you want to put a swear word in the middle. I can only get away with this because I’m British. I’m going to use the word bloody as a swear word, although actually, usually in linguistics we use the f-word but we can use the word bloody and if I want to put the word bloody in Pittsburgh, it’s going to be pit’s— bloody—berg and I could do that and it could be compounded and possibly but it’s a little bit of a stretch and maybe you would put species in in there to do that in other languages. Infects will happen in some languages. You’ll actually even change things in Templatic morphology in things like Hebrew and Arabic, and Tagalog is an example.
This is one of the examples from the Philippines where we’ve got interesting morphology going on and we’ve got much more interesting morphology going on than what’s in English and we’d like to be able to decompose these things so that we’ve got finite sets of morphemes when we’re doing processing so when we’re doing tokenization when before you give it to your word embedding system you’d like to have a standardized tokenizer that’s going to give you meaningful the most meaningful atomic parts when you actually do it.
Arabic
Arabic’s very interesting, because things actually are done within the consonants so you have a backbone of consonants and the vowels will change before and after after them. This changes meaning both semantically and inflectional so syntactic information about tense etc there’s a number of Semitic languages that actually do templatic morphology and it always breaks a lot of our systems from doing it but we are not allowed to define what natural language actually is we still need to be able to deal with it Chinese has a relatively small amount of morphology but it still has derivational morphology so you can take words and join them together in interesting compounds which are not necessarily directly to do with the meaning of the individual character that you’re joining together so a number of things of for example if you take fire and wheel and put it together it doesn’t mean a wheel that’s on fire it actually means a steam train and so or maybe that’s only in Japanese I always get that one wrong which varies between the different languages but there’s often a relationship but the compound might be different and so sometimes you want to be able to decompose it and sometimes you don’t so there’s two types of morphology which are identified as what’s called derivational morphology and derivational morphology you’re mostly changing the part of speech class when you’re doing things English is a rich derivational morphology and we can write it out and it’s mostly productive by productively means we’re allowed to construct new words without explaining to people what the meaning is inflectional morphology is usually syntactic class changes or some classic feature changing so this is things like changing the tense changing the plurality and the number and other languages it may do things like used in agreement used in tense and aspect and verbs and these are usually treated as different classes and they’re usually quite different they don’t overlap they’re sometimes maybe a little bit confusing and for the most part inflectional morphology happens after derivational morphology in almost all languages we can talk about morphosyntax about how these phonemes join together and which ones are allowed to join to each other and we can talk about a lower level thing that we call it morphofunnymix or morphographymix where things are changing at the boundaries when we join them together so an example of morphophony thin morphography mix because it happens in the graphene form but the pronunciation is affected as well when you take apostrophe s okay or the plural s when we add it onto things sometimes we insert an e when we add e d to the end of things if it already ends in an we don’t double the e and so this is I’ve got the e d and I’m going to join it on if the previous one is an e I’m just going to do it so move plus e d this is m-o-v-e-d okay while walked plus e-d is walk plus e-d joined together there’s different classes of
Types of Morphology
morphology and typography and typology of these so that we can put these into different groups and to be able to identify what they’re all about we have isolating or analytic m1s where there’s very little morphological changes in Vietnamese many of the Chinese dialects English are good examples of that we have synthetic ones where things are being created all the time they’re sometimes called fusional or flectional so german greek russian and templatic where we’ve got some form of often consonants and the vowels are changed and interspersed between those and we have a glutenatif where there’s lots of things joining together japanese finnish turkish are really good examples of that and we have polysynthetic which are really complexly joining things together where almost every phrase is actually ends up in a single word many of the north american native american languages are that the reason the word snow is there is because you can often have lots of variations of the word snow in inuit that’s actually not true well it is sort of true but it’s notable that in Scottish English we have lots of words for rain and for some reason I have no idea why that would be
Morphology Analyzers
People have worked on morphology for a long time so often when you’re working a new language there already is a morphological analyzer is there and if you look at the project unimorph and they’ve actually collected together these in a fairly standardized way so you might just be able to use it from python and all of a sudden you get morphological decomposition for your language or maybe you could use a nearby language and it would almost work and that might make your life a lot easier often when we’re doing novel languages especially when we’re caring about things under time we will look for one of those or we might even spend a couple of hours writing something because we’ll get something better than trying to do it fully automatically there are fully automatic ways but it might be better if there’s already something that allows us to do that okay there’s actually a competition
Morphology Competition
every year sigmar phone has been running for at least 10 years and it gets harder and harder every year as they find harder and harder tasks from both supervised and unsupervised m techniques so it’s worthwhile looking at these and using that as a resource
Finite State Morphology
Finite state morphology is often used for morphemes actually morphology is never very complex there’s probably something to do with a human brain it can’t really deal with something as complex as say syntax within morphology and therefore it’s often quite localized and therefore finite state machines are quite good at being able to cover everything and there’s good toolkits out there that help you to be able to write these things there’s also completely unsupervised techniques there’s more fessor just a python thing you give it examples and it will try to find out the prefixes and suffixes that actually might allow you to be able to do analysis it does assume a certain segmental and view of phonology and therefore it can get confused sometimes and it might treat the different types of ed or just d in different forms in English and separate them out and maybe you want to join them together or maybe you don’t there’s a sort of related thing called stemming which is often quite useful especially when you’re doing things like information retrieval where you’d like to say look I i just I just want the root of the word and I don’t want all these other variations especially when you’re in a limited domain or when you’ve got limited amount of data and so maybe if you removed all of the morphological variants the plurals the eds it might be easier to do comparisons later especially if you don’t have good data in order to be able to do good word embedding there’s also purely completely automatic techniques and bpe is a good example of that byte pair encoding you can’t really work it out from the name where what we do is we look at the string of the actual letters that are there and try to find and optimize the sequence of letters together and the overall predictability of the group of letters that we actually find and this originally came out of work in machine translation to try and find the best segmentation for doing translation but we end up using it for lots of lots of things it’s often worth trying if you don’t have anything else because it does sort of work but you really want to know about for your particular language is it likely to work before you actually do all of your bpe you get a tokenization representation you build all your word embedding that you learn from it and then learn oh no you could have downloaded the morphological analyzer that would have given a better result and a more consistent result and therefore you would have been able to learn back
Tokenization
Tokenization is also something that we get this often gets called where you’re actually just trying to split these things into words and you’ve got to care about what the tokenization actually is because if you have a different tokenization that won’t be the same lemmetization or stemming is somewhat similar but limit hydration is really talking about the linguistic root of the word which may or may not be well well defined and it’s usually after morphological and decomposition you find the root of the word a we can also do this across languages you may want to care about characters rather than words and looking inside characters that can actually help and caring about things that are happening over long boundaries somewhat related to this is word segmentation in languages like japanese and chinese and in fact they end up using something similar to bpe to be able to segment things there’s a couple of related things
Text normalization
Text normalization where you actually are trying to replace everything as words we know that there’s an infinite number of numbers and would be nice if we could change them into words maybe or maybe just change them into the word number or maybe classes of numbers and this is something that’s been studied in a in text-to-speech and there’s various machine learning techniques to try to do well on this you might want to also care about spelling correction and do be aware that tokenization this mismatch can really break everything so if you’re using bert you sort of have to use their tokenization because they’ve assumed that and it can be quite hard if you do something else okay that’s everything about works and morphology we will be talking about morphology again later on in more detail but now we’re going to care about splitting out up out into groups and what we want you to do today is we want you to take one of these languages language families often morphology and or aspect of writing and orthography are similar within language families and I’d like you to identify something that you would need to care about if you were trying to do some form of tokenization
Discussion Prompt
Pick a language in one of the following branches of language families: Bantu, Dravidian, Finno-Ugric, Japonic, Papuan, Semitic, Slavic, Turkic. Tell us about some interesting aspects of morphology of that language, following examples from the assigned reading. Cite your sources.
If you would need to implement a tokenizer for that language, what language specific knowledge would need to be incorporated into the tokenizer?
Outline
- Introduction to Words in NLP
- Words are fundamental in NLP, yet defining them can be non-trivial.
- The notion of a word boundary is not always straightforward, especially when moving beyond English.
- White space separated tokens are a good approximation for words in some languages, but this isn’t a universal rule.
- Challenges in Defining Words
- Clitics: Apostrophe-s (’s) is a clitic, not an isolated word, and it can attach to whole noun phrases.
- Compounds: Some compounds (like “handyman”) are treated as single words, even with spaces, while others are hyphenated (“do-it-yourself”), and these distinctions are not always consistent.
- Contractions: Contractions like “kinda” and “isn’t it” can be written in reduced forms and require decisions about tokenization.
- Agglutination: Some languages (e.g., Turkish) join words together with no spaces, resulting in what might be considered phrases in English being single words.
- Ambiguity: In some languages, a single written word can have multiple meanings depending on how it is separated into morphemes (e.g., Hebrew example given).
- Linguistic Approaches to Defining Words
- Phonetics: Word definitions could be based on pronunciation, such as every word containing a vowel or having a certain syllable structure.
- Morphology: Word definitions could be based on the individual morphemes within the word.
- Syntax: Words can be defined by their class and interchangeability with other words of the same class.
- Semantics: Word definitions could relate to the meaning they convey, including multi-word units with a single idea like “navy blue”.
- Pragmatics: Some phrases like “New York” may be used as single words even though they have white space within them.
- Orthographic Definitions
- White Space: Even in English, white space is complex (spaces, tabs, new lines, etc.) and includes non-breakable spaces which may or may not be considered word boundaries.
- Written vs. Spoken: Most languages are not written, and in spoken language, there are no spaces between words. A definition of words is needed that is independent of the written form.
- Prosodic Definitions
- Intonation: Phrases grouped together in a single intonational phrase (like “in the park”) can be treated as a single word in some languages.
- Syntactic Definitions
- Words can be grouped into syntactic classes; for example “New York” is a particular city in the same way that “Pittsburgh” is.
- Open Classes (Nouns, verbs, adjectives, adverbs): These classes are vast and can easily accommodate new words.
- Closed Classes (Prepositions, determiners, pronouns, conjunctions, auxiliary verbs): These classes have a finite set of words, and new words rarely enter these classes.
- Part-of-Speech Tagging
- Tag Sets: Tag sets, like those based on the Penn Treebank (with 43 tags), are used to categorize words into parts of speech.
- Universal Dependency Tag Sets: A smaller set of tags is used across many languages for universal dependency grammar.
- Importance of Tagging: Tagging provides structured information, which can improve machine learning models, especially with limited data.
- Morphology
- Morphemes: Morphemes are the smallest atomic parts of a word.
- Derivational Morphology: This changes the meaning and part of speech class of a word. English is rich in derivational morphology.
- Inflectional Morphology: This changes syntactic properties such as tense or number, and usually occurs after derivational morphology.
- Morphosyntax: How stems and affixes combine.
- Morphophonemics: Pronunciation and orthographic changes at morpheme boundaries. This can make morphology non-segmental.
- Morphological Decomposition
- Stems/Roots, Prefixes, and Suffixes: Words can be broken into their root forms, prefixes, and suffixes. English usually adds prefixes and suffixes but some languages have infixes.
- Infixes: Some languages have infixes (elements inserted within the word, with examples from Southeast Asia) and even change the consonants and vowels, as in templatic morphology in Semitic languages.
- Need for Decomposition: Decomposing words into morphemes allows for a more finite set of meaningful units for processing and tokenization.
- Types of Morphology
- Isolating/Analytic: Very little morphological change (e.g. Vietnamese, Chinese dialects, English).
- Synthetic/Fusional/Flectional: Things are constantly being created (e.g. German, Greek, Russian).
- Templatic: Often consonants are the basis, and the vowels change around them.
- Agglutinative: Lots of things joining together (e.g. Japanese, Finnish, Turkish).
- Polysynthetic: Complex joining of many parts, often with a whole phrase in one word (e.g. some Native American languages).
- Tools for Morphological Analysis
- Morphological Analyzers: Existing tools, including those from the UniMorph project, can provide morphological decomposition for many languages.
- Finite State Morphology: Finite state machines are useful for modeling morphology because of its localized nature.
- Unsupervised Methods: Tools like Morfessor can identify prefixes and suffixes.
- Stemming: Removing word endings to find the root, useful for information retrieval.
- Byte Pair Encoding (BPE): Finds optimal letter sequences for segmentation, also helpful in tokenization.
- Related Problems
- Tokenization: The process of splitting text into words or tokens.
- Lemmatization: Finding the linguistic root of a word after morphological decomposition.
- Text Normalization: Replacing numbers, symbols, and abbreviations with standard words.
- Spelling Correction: Addressing spelling errors and social media language.
- Tokenization Mismatch: Different tokenization methods can lead to issues, for example when using models like BERT.
- Word Segmentation: In languages without spaces, segmenting words is necessary.
- Practical Applications
- The need to consider different language families when developing tokenization methods because morphology and orthography are often similar within a family.
- Tokenization decisions impact all downstream tasks, including word embeddings and parsing.
Papers
-
- is referenced in the context of text normalization. It deals with the expansion of non-standard words.
Kannada in 10 minutes
Okay, here is an overview of Kannada, drawing from the provided Wikipedia article.
- Language Name and Classification:
- Kannada (ಕನ್ನಡ) is a classical Dravidian language.
- It belongs to the South Dravidian language family.
- It evolved from Tamil-Kannada.
- It was formerly known as Canarese.
- Speakers and Location:
- Approximately 44 million native speakers.
- Around 15 million second-language speakers.
- Primarily spoken in the state of Karnataka in southwestern India.
- Spoken by minority populations in neighboring states, such as Tamil Nadu, Maharashtra, Andhra Pradesh, Telangana, Kerala, and Goa.
- Kannada speaking communities also exist in countries like the United States, Canada, Australia, Singapore, and Malaysia.
- Official Status:
- Official and administrative language of Karnataka.
- It has scheduled status in India.
- Recognized as one of India’s classical languages.
- History and Development:
- The language’s history is divided into: Old Kannada (450-1200 AD), Middle Kannada (1200-1700 AD), and Modern Kannada (1700-present).
- Influenced by Sanskrit and Prakrit.
- Some scholars suggest a spoken tradition existed as early as the 3rd century BC.
- The earliest Kannada inscriptions date back to the 5th century AD.
- The language has an unbroken literary history of approximately 1200 years.
- Writing System:
- Uses the Kannada script.
- The script evolved from the 5th-century Kadamba script.
- It is a syllabic script.
- It contains 49 phonemic letters.
- Phonology:
- Vowels include front, central, and back vowels, with variations in length.
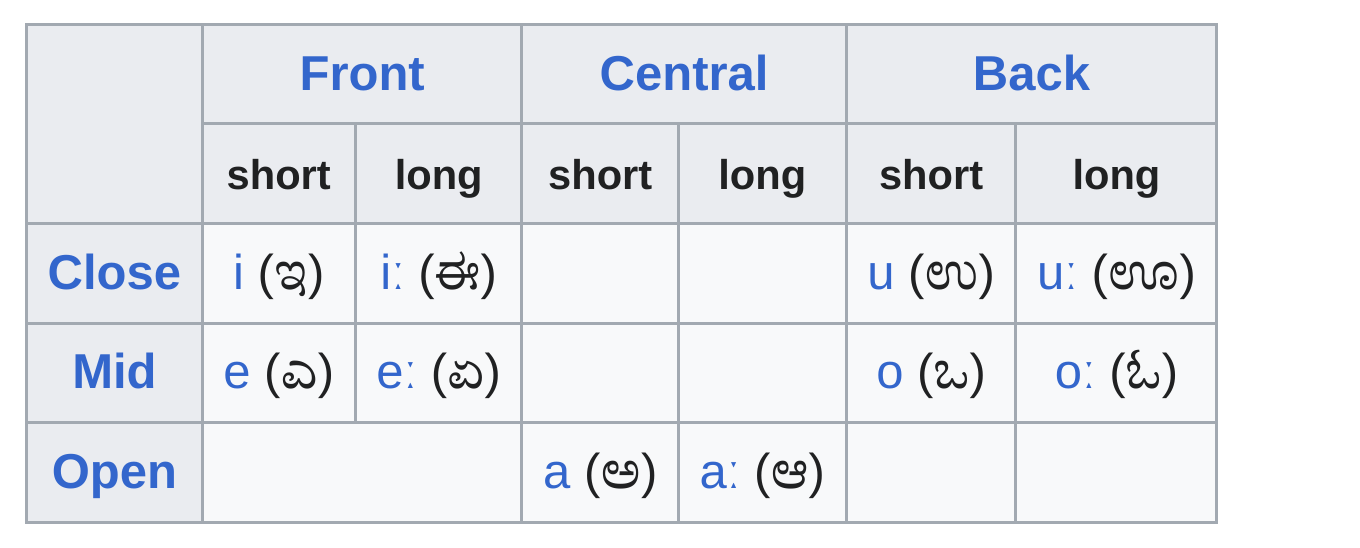
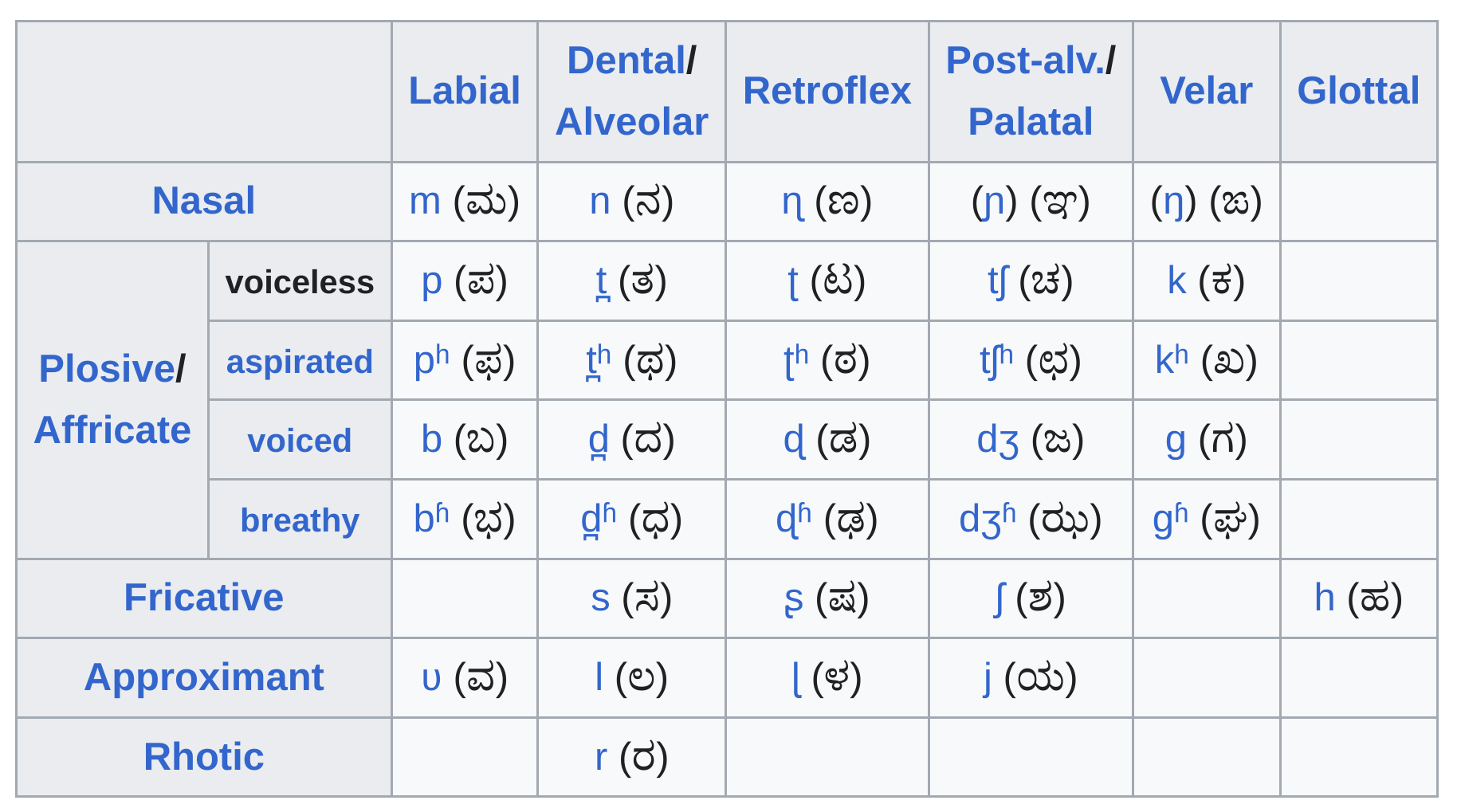
- Consonants include labial, dental, retroflex, palatal, velar, and glottal sounds.
- Most consonants can be geminated.
- Aspirated consonants are rare in native vocabulary.
- Grammar:
- Word order is typically subject-object-verb (SOV).
- It is a highly inflected language with three genders and two numbers.
- Compound bases (samāsa) combine two or more words.
- Dialects:
- Approximately 20 dialects of Kannada exist, including Kundagannada, Havigannada, and Are Bhashe.
- Dialects are influenced by regional and cultural backgrounds.
- Related languages include Badaga, Holiya, Kurumba, and Urali.
- Significance to Modern Linguistics:
- Kannada’s syntactic properties, particularly regarding causative morphemes and negation, have been significant in studies of language acquisition and innateness.
Citation
@online{bochman2022,
author = {Bochman, Oren},
title = {Words, {Parts} of {Speech,} {Morphology}},
date = {2022-01-24},
url = {https://orenbochman.github.io/notes-nlp/notes/cs11-737/cs11-737-w04-words/},
langid = {en}
}