Very Deep Convolutional Networks for Large-Scale Image Recognition
paper review
convolutional neural networks, deep learning, image recognition, computer vision
The abstract
In this work we investigate the effect of the convolutional network depth on its accuracy in the large-scale image recognition setting. Our main contribution is a thorough evaluation of networks of increasing depth using an architecture with very small (3x3) convolution filters, which shows that a significant improvement on the prior-art configurations can be achieved by pushing the depth to 16-19 weight layers. These findings were the basis of our ImageNet Challenge 2014 submission, where our team secured the first and the second places in the localisation and classification tracks respectively. We also show that our representations generalise well to other datasets, where they achieve state-of-the-art results. We have made our two best-performing ConvNet models publicly available to facilitate further research on the use of deep visual representations in computer vision. — (Simonyan and Zisserman 2015)
TL;DR
The primary aim of this paper is to investigate the effect of the convolutional network depth on its accuracy in the large-scale image recognition setting. The authors show that a significant improvement on the prior-art configurations can be achieved by pushing the depth to 16-19 weight layers.
Review
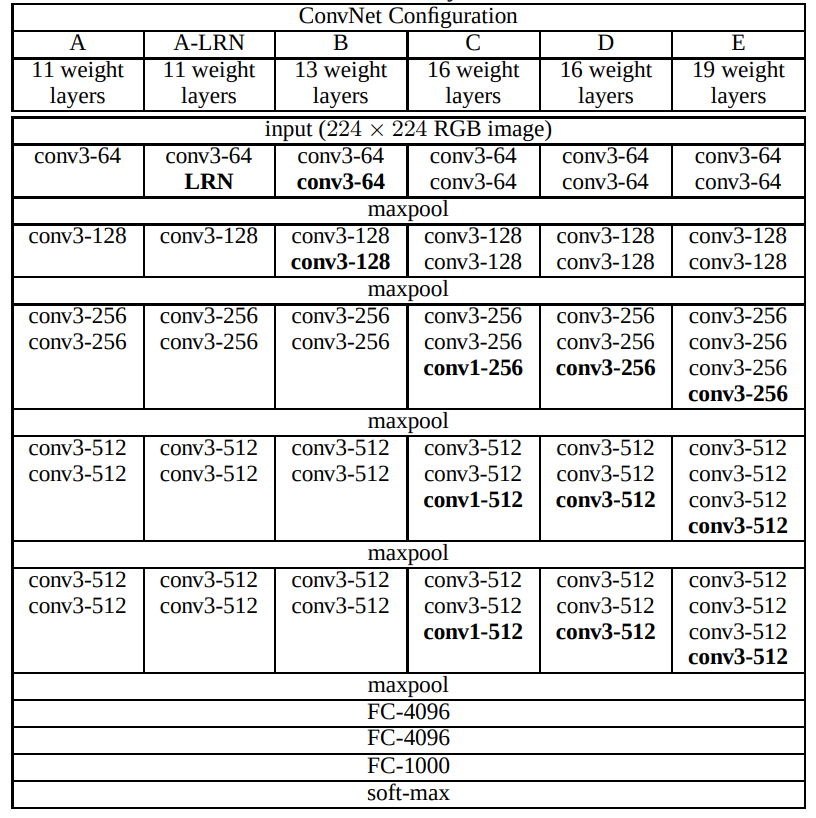
The paper has a table with some network architectures and their performance on the ImageNet dataset. In many cases data scientist etc. like to copy the architectures of well known models and use them in their own work. So this paper is a good reference for giving a few more options for architectures to use.
The paper uses 3x3 convolution filters which is a common practice in modern CNN architectures.
We use very small 3 × 3 receptive fields throughout the whole net, which are convolved with the input at every pixel (with stride 1). It is easy to see that a stack of two 3 × 3 conv. layers (without spatial pooling in between) has an effective receptive field of 5 × 5; three such layers have a 7 × 7 effective receptive field. So what have we gained by using, for instance, a stack of three 3 × 3 conv. layers instead of a single 7 × 7 layer? First, we incorporate three non-linear rectification layers instead of a single one, which makes the decision function more discriminative. Second, we decrease the number of parameters: assuming that both the input and the output of a three-layer 3 × 3 convolution stack has C channels, the stack is parametrised by 3 (32C2) = 27C^2 weights; at the same time, a single 7 × 7 conv. layer would require 72C2 = 49C2 parameters, i.e. 81% more. This can be seen as imposing a regularisation on the 7 × 7 conv. filters, forcing them to have a decomposition through the 3 × 3 filters (with non-linearity injected in between).
The authors also reference 1 × 1 convolutions from [NiN] paper but don’t seem to understood the NIN architecture as they did not use 1 × 1 in their models, which also have large FC layers at the end.
The result were state of the art but by 2018 (Goyal et al. 2017) it would be possible to train a ResNet-50 imagenet classifier in under an hour of compute with just using 256 GPUs. There is little novelty in the methods. The authors simply increased the depth of the network and increase the umber of parameters.(but they also used them more efficiently).
At (Appalapuri 2016) I found a Pytorch implementation of this paper.
This is essentially a brute force result - not a deep insight one would expect from an organization called “deep mind.”
More interesting are methods that can achieve the better performance with fewer parameters and at a lower costs in training and inference etc.
It’s little surprise that this is work from a cloud provider with a vested interest of people using more compute and where such fairly unlimited resources can be throws at this type of research.
They even point out that while methods for speeding up training were available they did not bother with them as using 4 GPUs gave them the results in 2-3 weeks.

“Captain Obvious by stuartmcghee on DeviantArt” (2024)
More layers \implies more parameters
more parameters \implies more capacity
more capacity \implies better fit.
BaZinga! 🚀