from matplotlib.pyplot import subplots
import numpy as np
import pandas as pd
from ISLP.models import ModelSpec as MS
from ISLP import load_data
from lifelines import KaplanMeierFitter, CoxPHFitter
from lifelines.statistics import logrank_test, multivariate_logrank_test
from ISLP.survival import sim_time
km = KaplanMeierFitter()
coxph = CoxPHFitterSurvival Analysis
We begin by importing some of our libraries at this top level.
Call Center Data
In this section, we will simulate survival data using the relationship between cumulative hazard and the survival function explored in Exercise . Our simulated data will represent the observed wait times (in seconds) for 2,000 customers who have phoned a call center. In this context, censoring occurs if a customer hangs up before his or her call is answered.
There are three covariates: Operators (the number of call center operators available at the time of the call, which can range from 5 to 15), Center (either A, B, or C), and Time of day (Morning, Afternoon, or Evening). We generate data for these covariates so that all possibilities are equally likely: for instance, morning, afternoon and evening calls are equally likely, and any number of operators from 5 to 15 is equally likely.
rng = np.random.default_rng(10)
N = 2000
Operators = rng.choice(np.arange(5, 16), N,replace=True)
Center = rng.choice(['A', 'B', 'C'],N,replace=True)
Time = rng.choice(['Morn.', 'After.', 'Even.'],N,replace=True)
D = pd.DataFrame({'Operators': Operators, 'Center': pd.Categorical(Center), 'Time': pd.Categorical(Time)})We then build a model matrix (omitting the intercept)
model = MS(['Operators', 'Center', 'Time'], intercept=False)
X = model.fit_transform(D)It is worthwhile to take a peek at the model matrix X, so that we can be sure that we understand how the variables have been coded. By default, the levels of categorical variables are sorted and, as usual, the first column of the one-hot encoding of the variable is dropped.
X[:5]| Operators | Center[B] | Center[C] | Time[Even.] | Time[Morn.] | |
|---|---|---|---|---|---|
| 0 | 13 | 0.0 | 1.0 | 0.0 | 0.0 |
| 1 | 15 | 0.0 | 0.0 | 1.0 | 0.0 |
| 2 | 7 | 1.0 | 0.0 | 0.0 | 1.0 |
| 3 | 7 | 0.0 | 1.0 | 0.0 | 1.0 |
| 4 | 13 | 0.0 | 1.0 | 1.0 | 0.0 |
Next, we specify the coefficients and the hazard function.
true_beta = np.array([0.04, -0.3, 0, 0.2, -0.2])
true_linpred = X.dot(true_beta)
hazard = lambda t: 1e-5 * tHere, we have set the coefficient associated with Operators to equal 0.04; in other words, each additional operator leads to a e^{0.04}=1.041-fold increase in the “risk” that the call will be answered, given the Center and Time covariates. This makes sense: the greater the number of operators at hand, the shorter the wait time! The coefficient associated with Center == B is -0.3, and Center == A is treated as the baseline. This means that the risk of a call being answered at Center B is 0.74 times the risk that it will be answered at Center A; in other words, the wait times are a bit longer at Center B.
Recall from Section~ the use of lambda for creating short functions on the fly. We use the function sim_time() from the ISLP.survival package. This function uses the relationship between the survival function and cumulative hazard S(t) = \exp(-H(t)) and the specific form of the cumulative hazard function in the Cox model to simulate data based on values of the linear predictor true_linpred and the cumulative hazard.
We need to provide the cumulative hazard function, which we do here.
cum_hazard = lambda t: 1e-5 * t**2 / 2We are now ready to generate data under the Cox proportional hazards model. We truncate the maximum time to 1000 seconds to keep simulated wait times reasonable. The function sim_time() takes a linear predictor, a cumulative hazard function and a random number generator.
W = np.array([sim_time(l, cum_hazard, rng)
for l in true_linpred])
D['Wait time'] = np.clip(W, 0, 1000)We now simulate our censoring variable, for which we assume 90% of calls were answered (Failed==1) before the customer hung up (Failed==0).
D['Failed'] = rng.choice([1, 0],
N,
p=[0.9, 0.1])
D[:5]| Operators | Center | Time | Wait time | Failed | |
|---|---|---|---|---|---|
| 0 | 13 | C | After. | 525.064979 | 1 |
| 1 | 15 | A | Even. | 254.677835 | 1 |
| 2 | 7 | B | Morn. | 487.739224 | 1 |
| 3 | 7 | C | Morn. | 308.580292 | 1 |
| 4 | 13 | C | Even. | 154.174608 | 1 |
D['Failed'].mean()0.9075We now plot Kaplan-Meier survival curves. First, we stratify by Center.
fig, ax = subplots(figsize=(8,8))
by_center = {}
for center, df in D.groupby('Center',observed=False):
by_center[center] = df
km_center = km.fit(df['Wait time'], df['Failed'])
km_center.plot(label='Center=%s' % center, ax=ax)
ax.set_title("Probability of Still Being on Hold")Text(0.5, 1.0, 'Probability of Still Being on Hold')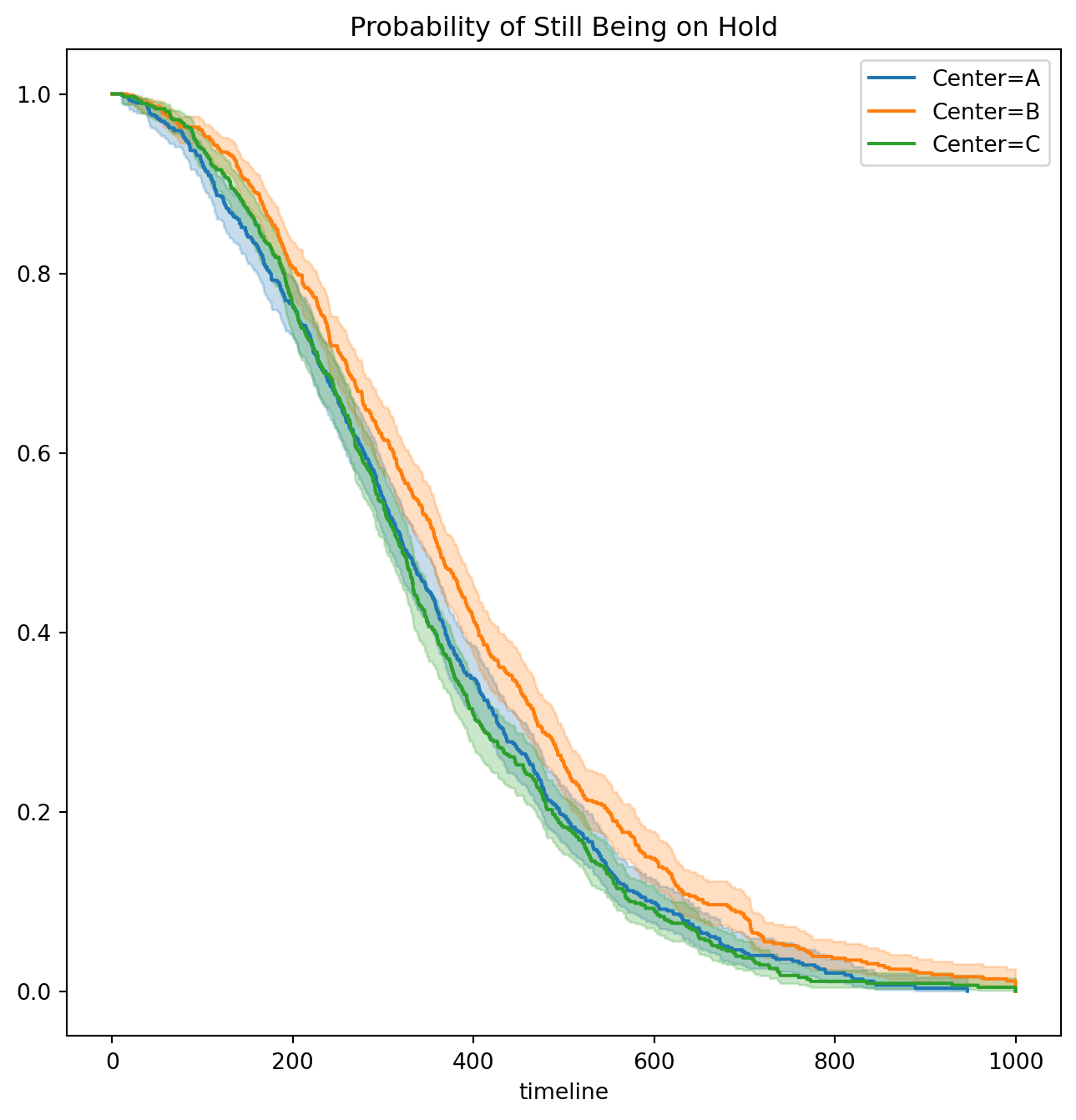
Next, we stratify by Time.
fig, ax = subplots(figsize=(8,8))
by_time = {}
for time, df in D.groupby('Time',observed=False):
by_time[time] = df
km_time = km.fit(df['Wait time'], df['Failed'])
km_time.plot(label='Time=%s' % time, ax=ax)
ax.set_title("Probability of Still Being on Hold")Text(0.5, 1.0, 'Probability of Still Being on Hold')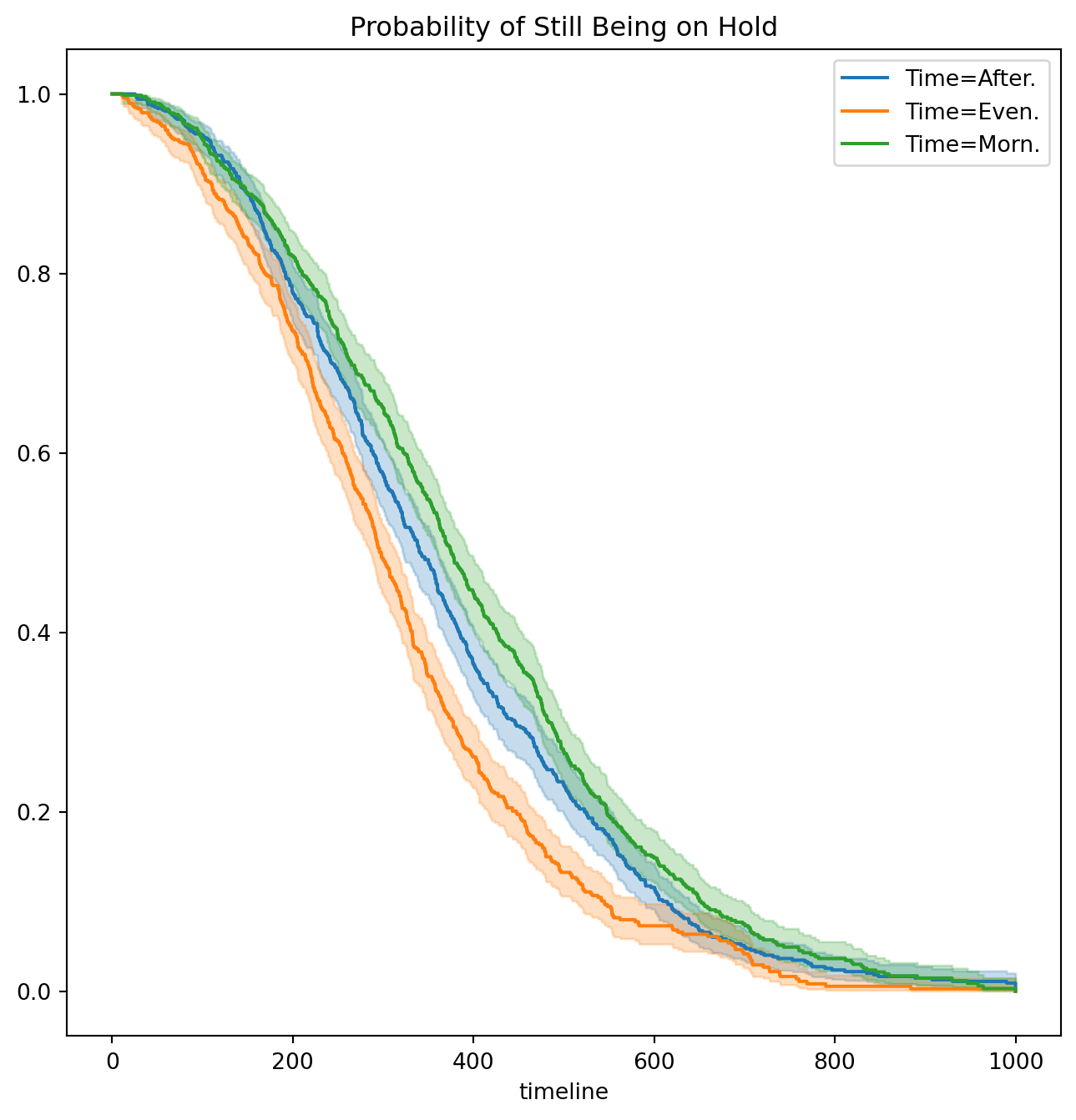
It seems that calls at Call Center B take longer to be answered than calls at Centers A and C. Similarly, it appears that wait times are longest in the morning and shortest in the evening hours. We can use a log-rank test to determine whether these differences are statistically significant using the function multivariate_logrank_test().
multivariate_logrank_test(D['Wait time'],
D['Center'],
D['Failed'])| t_0 | -1 |
| null_distribution | chi squared |
| degrees_of_freedom | 2 |
| test_name | multivariate_logrank_test |
| test_statistic | p | -log2(p) | |
|---|---|---|---|
| 0 | 20.30 | <0.005 | 14.65 |
Next, we consider the effect of Time.
multivariate_logrank_test(D['Wait time'],
D['Time'],
D['Failed'])| t_0 | -1 |
| null_distribution | chi squared |
| degrees_of_freedom | 2 |
| test_name | multivariate_logrank_test |
| test_statistic | p | -log2(p) | |
|---|---|---|---|
| 0 | 49.90 | <0.005 | 35.99 |
As in the case of a categorical variable with 2 levels, these results are similar to the likelihood ratio test from the Cox proportional hazards model. First, we look at the results for Center.
X = MS(['Wait time',
'Failed',
'Center'],
intercept=False).fit_transform(D)
F = coxph().fit(X, 'Wait time', 'Failed')
F.log_likelihood_ratio_test()| null_distribution | chi squared |
| degrees_freedom | 2 |
| test_name | log-likelihood ratio test |
| test_statistic | p | -log2(p) | |
|---|---|---|---|
| 0 | 20.58 | <0.005 | 14.85 |
Next, we look at the results for Time.
X = MS(['Wait time',
'Failed',
'Time'],
intercept=False).fit_transform(D)
F = coxph().fit(X, 'Wait time', 'Failed')
F.log_likelihood_ratio_test()| null_distribution | chi squared |
| degrees_freedom | 2 |
| test_name | log-likelihood ratio test |
| test_statistic | p | -log2(p) | |
|---|---|---|---|
| 0 | 48.12 | <0.005 | 34.71 |
We find that differences between centers are highly significant, as are differences between times of day.
Finally, we fit Cox’s proportional hazards model to the data.
X = MS(D.columns,
intercept=False).fit_transform(D)
fit_queuing = coxph().fit(
X,
'Wait time',
'Failed')
fit_queuing.summary[['coef', 'se(coef)', 'p']]| coef | se(coef) | p | |
|---|---|---|---|
| covariate | |||
| Operators | 0.043934 | 0.007520 | 5.143589e-09 |
| Center[B] | -0.236060 | 0.058113 | 4.864162e-05 |
| Center[C] | 0.012231 | 0.057518 | 8.316096e-01 |
| Time[Even.] | 0.268845 | 0.057797 | 3.294956e-06 |
| Time[Morn.] | -0.148217 | 0.057334 | 9.733557e-03 |
The p-values for Center B and evening time are very small. It is also clear that the hazard — that is, the instantaneous risk that a call will be answered — increases with the number of operators. Since we generated the data ourselves, we know that the true coefficients for Operators, Center = B, Center = C, Time = Even. and Time = Morn. are 0.04, -0.3, 0, 0.2, and -0.2, respectively. The coefficient estimates from the fitted Cox model are fairly accurate.
Reuse
CC SA BY-NC-ND
Citation
BibTeX citation:
@online{bochman2024,
author = {Bochman, Oren},
title = {Chapter 11: {Survival} {Analysis} - {Lab} {Part} 3},
date = {2024-09-04},
url = {https://orenbochman.github.io/notes-islr/posts/ch11/Ch11-surv-lab-3.html},
langid = {en}
}
For attribution, please cite this work as:
Bochman, Oren. 2024. “Chapter 11: Survival Analysis - Lab Part
3.” September 4, 2024. https://orenbochman.github.io/notes-islr/posts/ch11/Ch11-surv-lab-3.html.