Learning to Bid with AuctionGym
Paper Review
Counterfactual inference, Off-policy learning, Doubly Robust Estimator

So I don’t have much time for this today so here is a quick note on: (Jeunen et al. 2022)

- Advertising auctions are rarely incentive compatible.
- Formulate the policy in terms of a utility AKA loss function.
- They use a doubly robust estimation method. This is something I learned about from Emma Brunskill’s guest lecture in the Alberta Coursera course. And ever since I’ve been looking on how to do this in RL. Unforetunatly all I could find was work that used it in offline RL settings. So I was stoked to see it used as a central part of this paper. Using a doubly robust estimator is a sound technique for reducing variance without introducing a bias. And variance is the gratest impediment to learning quickly in RL. Also unlike some other ideas I’ve come accross it seems to align very well with Causal Inference.
- The talk mentions a dataset the authors used for doing this work. Is this dataset available? I would like to try this out
ABSTRACT
Online advertising opportunities are sold through auctions, billions of times every day across the web. Advertisers who participate in those auctions need to decide on a bidding strategy: how much they are willing to bid for a given impression opportunity. Deciding on such a strategy is not a straightforward task, because of the interactive and reactive nature of the repeated auction mechanism. Indeed, an advertiser does not observe counterfactual outcomes of bid amounts that were not submitted, and successful advertisers will adapt their own strategies based on bids placed by competitors. These characteristics complicate effective learning and evaluation of bidding strategies based on logged data alone.
The interactive and reactive nature of the bidding problem lends itself to a bandit or reinforcement learning formulation, where a bidding strategy can be optimised to maximise cumulative rewards. Several design choices then need to be made regarding parameterisation, model-based or model-free approaches, and the formulation of the objective function. This work provides a unified framework for such “learning to bid” methods, showing how many existing approaches fall under the value-based paradigm. We then introduce novel policy-based and doubly robust formulations of the bidding problem. To allow for reliable and reproducible offline validation of such methods without relying on sensitive proprietary data, we introduce AuctionGym: a simulation environment that enables the use of bandit learning for bidding strategies in online advertising auctions. We present results from a suite of experiments under varying environmental conditions, unveiling insights that can guide practitioners who need to decide on a model class. Empirical observations highlight the effectiveness of our newly proposed methods. AuctionGym is released under an open-source license, and we expect the research community to benefit from this tool.
The bidding Objective
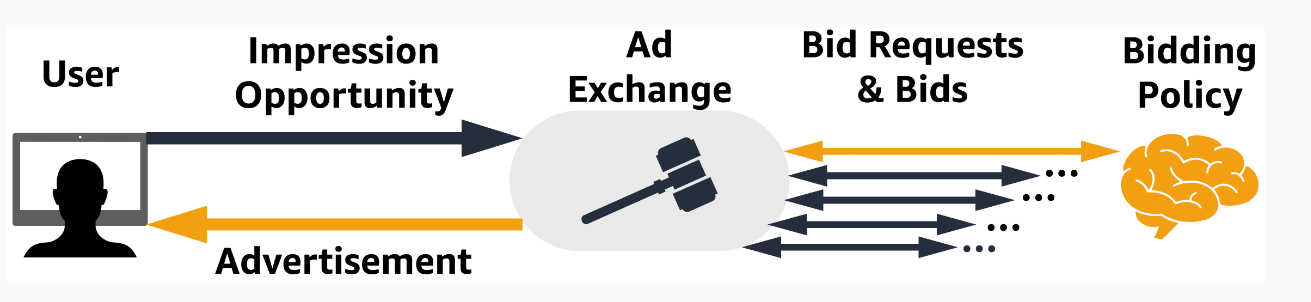
High-level overview of a real-time-bidding flow in computational advertising
U = W(V − P) \tag{1}
where U is the utility, W is the weight, V is the value, and P is the price. The value V is the expected value of the impression, and the price P is the bid amount.
The utility U is the loss function. The goal is to maximize the utility U according to some contextual policy \pi(B\mid A; X).
Choosing a Counterfactual Estimator
- Value-based Estimation (The “Direct Method”) High Bias model P(win|bid)
- Policy-based Estimation (IPS) High Variance
- Doubly Robust Estimation Unbiased, lower variance
How do you evaluate this?
- Offline: use counterfactual estimators . . . > “When a measure becomes a target, it ceases to be a good measure” (Goodhart’s Law)
- Online: A/B-tests span weeks, require production-level prototypes, …
- Simulate
- What do they mean that “auctions are not incentive compatible”?
- Marketing are the worst POMDPs. Testing real stuff is very hard so a good environment might help.
- Simulation is very powerfull as it allows to know the ground truth.
- However its not easy to simulate the real world and any discrepency may lead to unrealistic results.
The Paper
