![]()
Introduction
- The course instructors, Adam and Martha White, are world class researches researchers.
- The University of Alberta is by far the strongest university for RL.
- RL builds on the foundations of Markov Decision Processes, Dynamic Programming, and Monte Carlo methods as well as Machine Learning and Deep Neural Networks.
- I found that learning these topics is better motivated and there fore easier to grasp when presented in the context of RL.
- I read reviews by a number of people have taken this specialization. A few have had some background in RL and breezed through the material. The rest suggested that the material can be challenging particularly the last two courses.
- Some of the assignments appear in RL textbooks, but instead of a few lines of code for the main assignment, in the capstone we get to implement both Parts of the environment, the RL algorithm, the replay buffer, the neural net and the optimizer from scratch. This is a blessing in disguise as it really gives one more opportunity to get to grips with these complex subjects.
- A big chunk of the programming assignments have to handle the environment rather than the RL algorithm - many students complain about this.
- My insight has repeatedly been that in RL the algorithms are often very general and that the key to success for solving a particular problem with RL is all about thinking the environment through.
- Many environments have different challenges and can reveal the weaknesses of many time tested algorithms.
- Real world problems are much more challenging but the more environments you work with, the better you will be able to find good features that can make solving them with RL very different.
- Another aspect of RL is called reward shaping which is defining a reward structure that can provide the algorithm with good signal so as to support better credit assignment to actions in the correct state. This is an integral part of environment design.
- Finally I found that when you try to implement RL algorithms for real world problems you will want to modify the algorithms to take advantage of some structure in the environment.
- Luckily there are today more environments available then I could list, it is easy to create new ones. The bottom line is that the challenges and algorithms of RL only make sense when considered in the context of environments.
- In my opinion many of the assignments are not very interesting - the coding problems often border on the trivial.
- If you want to work with RL professionally you will need to do a lot more coding.
- You should consider some of the extra coding assignments that ware included in the text book.
- You should also consider implementing additional algorithms on the environments from the assignments.
- There are tons of other more interesting environments to work with consider taking you implementation to the next level in these environments.
- In reality even many of the environments we use in the assignments have surprising challenges.
- The moon lander in the capstone for example tends to learn to hover for a long time to avoid crashing
- The solution comes from a paper which suggests adding a time limit to the episode. However the assignment uses the time limit without mentioning this.
- I thought that the time limit was there to speed up grading until I tried to dive deeper.
- We spend lots of time tinkering with RL-Glue a library that is no longer being maintained.
- Although my background is in Mathematics I found the videos rather terse.
- They often list goals at the start and at the end again, so all in all the instructional part can be very brief.
- It would be easier to recap not just reference equations, update rules, and algorithms that have been covered a while back or in a previous course.
- Many They frequently reference old material which you may not have fully digested yet.
- I discovered that I had worked though all the videos, quizzes and programming assignments scoring 100% but I hadn’t really digested the material.
- These notes are my attempt to do so.
- I try to make the material more accessible and to connect the dots.
- I don’t include the programming assignments in these notes.
- I may add simple agents with from different environments and using libraries other than RL-Glue to avoid any issues raised by the Coursera honor code.
- I don’t include the quizzes either
- I found that most can be aced by just reviewing the videos before taking them and then reviewing the answers.
- I’d like to build a question/answer bank
- But I think that coding is much better time investment.
- There are lots of good notes on the web on RL.
- Summaries of the text book
- Slides for the courses offered by Richard S. Sutton and Andrew G. Barto
- Slides for the course offered by David Silver
- Notes from more advanced courses
- Books & Notes from some of the Guest lectures in this course.
- So I was reluctant to add to the pile. I found out after completing the first two courses that I had not really digested the material.
- I had to go back and review the material and then write these notes.
- I found that the act of writing the notes helped me to understand some of the trickier bits from the book.
- I also wanted to see how I could connect the dots between the different parts of the course.
- I hope that you find these notes helpful.
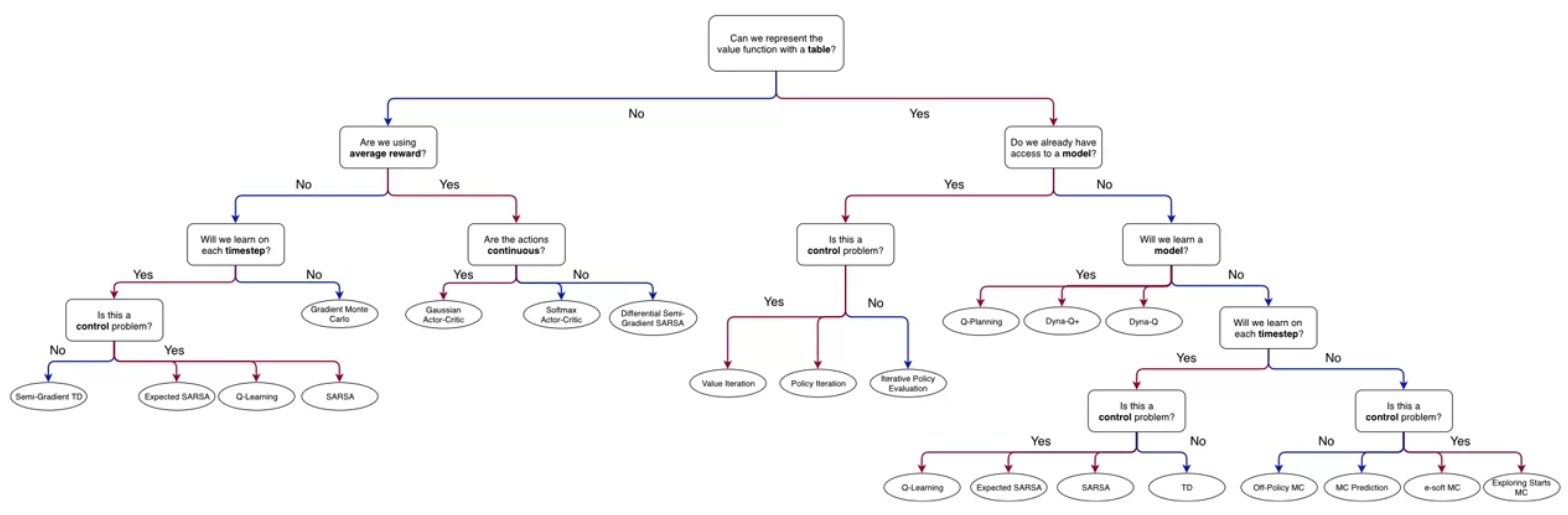
This course is deceptively simple - the chart in the margin provides a great summary of the material for the whole specialization. Only a handful of concepts are needed to master RL.
- This specialization is all about connecting the dots.
- We revisit the same ideas over and over improving them in small but significant ways by relaxing the assumptions. e.g. from bandits with one state we move to MDP with many states and get the ability to formulate plans. From Dynamic programming with a fully specified model we move to model free settings where we might not be able to efficiently learn a model. From tabular methods where we treat each state as a separate entity we we move to function approximation and deep learning where we can generalize from one state to many others.
- In this course and the more connections you make the better you will understand and remember material.
- And the greater you facility to apply RL to new problems.
The following are my tips for getting the most from this specialization
To connect the dots I ❤️ recommend:
- Annotate 🖊️ you e-copy of the book 📖
- Flash cards 🗂️ are your 🧑🤝🧑 friends.
- We don’t need too many but they can help you keep the essentials (algorithms, definitions, some formulas, a few diagrams) fresh in your mind.
- Keep reviewing these until you impress the folks at DeepMind in your interview. 😉
- Review 👁️ the videos/quizzes until nothing seems surprising/confusing 1.
- Review 👁️ your notes every time you complete a part of the specialization. Also a great idea if have an RL interview 💼
- Coding: If you have time do extra RL coding
- Start with developing more environments, simple and complex ⛩️
- Implement more algorithms - from the course, the books, papers.⛩️
- The notebooks also try to teach you experiments and analysis comparing algorithms performance. If you assimilate this part you are really going to shine. ⛩️
As a Mathematics major I can attest that Mathematics becomes 10x easier so long as you can recall 🧠 the basic definitions and their notation.
I have extracted the essentials from the text book below. Best to memorize these or at least keep a copy handy and you are well on your way to grokking this course
- G_t return at time t, for a (s_t, a_t, r_t...) sequence discounted by \gamma\in(0,1).
- r(s,a) - expected immediate rewards for action a in state s
- \pi policy - a decision making rule for every state.
- \pi_* optimal policy - which returns the maximum rewards.
- p(s',r \vert s,a) - transition probability to state s' with reward r from state s via action a AKA four valued dynamics function.
- p(s' \vert s,a) - transition probability to state s' from state s via action a AKA Markov process transition matrix
- v_\pi(s) - state’s value under policy \pi which is its expected return.
- q_\pi(s,a) - the action value in state s under policy \pi.
There are a number of guest lectures in this specialization - I think that about half are in the last course.
- These often provide a teaser into an area of research that extends the material in the course.
- Many are boring but
- almost all present papers and results that are worth some review.
- a few present too many papers, which suggests a triage approach
- sooner of later you might have a real problem that is similar to the one they are addressing.
- so I suggest you try and spend some time
- RL was more or less invented 4 times in different fields - Control Theory, Operations Research, Machine Learning and Psychology.
- The guest lectures often present the material from one of these fields.
A Long term plan to learning Deep RL
- do this specialization
- read the rest of the book - there are a number of important subjects and algorithms that are not covered in the course.
- solve more problems
- read more papers
- there are a zillion algorithms and a gazillion environments out there
- reading a few papers will get you up to speed on the state of the art.
- implement more algorithms
- this is what people are going to pay you for
- start with gradient bandit algorithms
- then Thompson Sampling using different distributions
- try and solve a real problem:
- I created a custom RL algorithm to solve the Lewis signaling game quickly and efficient - this allows agents to learn to communicate.
- I am now working on designing a multi-agent version of the game that should learn even faster.
- do the deep rl course from Hugging Face
- find RL challenges on Kaggle
Footnotes
The annotated book and flashcards will help here. This material is really logical - if you are surprised/confused you never assimilated some part of the material. Once you do it should become almost intuitive to reason about from scratch.↩︎